

Если вы анализируете поведение пользователей, выстраиваете сети или решаете другие динамические задачи, вам не обойтись без структур, которые специально созданы для визуализации взаимоотношений между различными объектами. Речь, разумеется, о графах. Рассказываем про пять разных типов графов: как они применяются в Data Science и как реализованы в Python.
Графы в Python
Граф состоит из отдельных точек (вершин) и соединяющих их линий (ребер). Вершины могут обозначать любые объекты: пользователей сайта, компьютеры корпоративной сети, населенные пункты на карте. Ребра отображают связи между этими объектами: каких пользователей тот или иной человек добавил в друзья, какие компьютеры объединяются прямым подключением, между какими городами проложены дороги. Такая схема позволяет решать множество прикладных задач, и для каждой из них есть много подходящих графов.

Такие структуры гораздо сложнее привычных таблиц баз данных. Представьте себе, что вам нужно создать карту значимых объектов обычного городского района, чтобы понять, где чаще всего бывают его жители. Вам нужно отметить все магазины, школы, МФЦ, и определить вес каждой из точки. Такой код непросто написать с нуля, а полученный результат очень сложно визуализировать в пригодном для работы формате — хаос повседневности формирует очень запутанные связи, даже если мы говорим про район, а не про город или страну.
К счастью, Python-программистам не приходится заниматься подготовительной работой. Они могут воспользоваться специальной библиотекой, которая объединяет все необходимые инструменты для создания и анализа графов — NetworkX. Мы также используем этот пакет в следующих примерах.

Разбивка вершин на группы
Анализ связных компонентов (connected components) позволяет вам определить внутренние множества внутри вашего графа. Например, вы можете разбить посетителей интернет-магазина на группы по их предпочтениям или географической принадлежности. Или связать между собой подозрительные транзакции в банковской системе, чтобы предположить, что все эти действия провела одна группа мошенников.
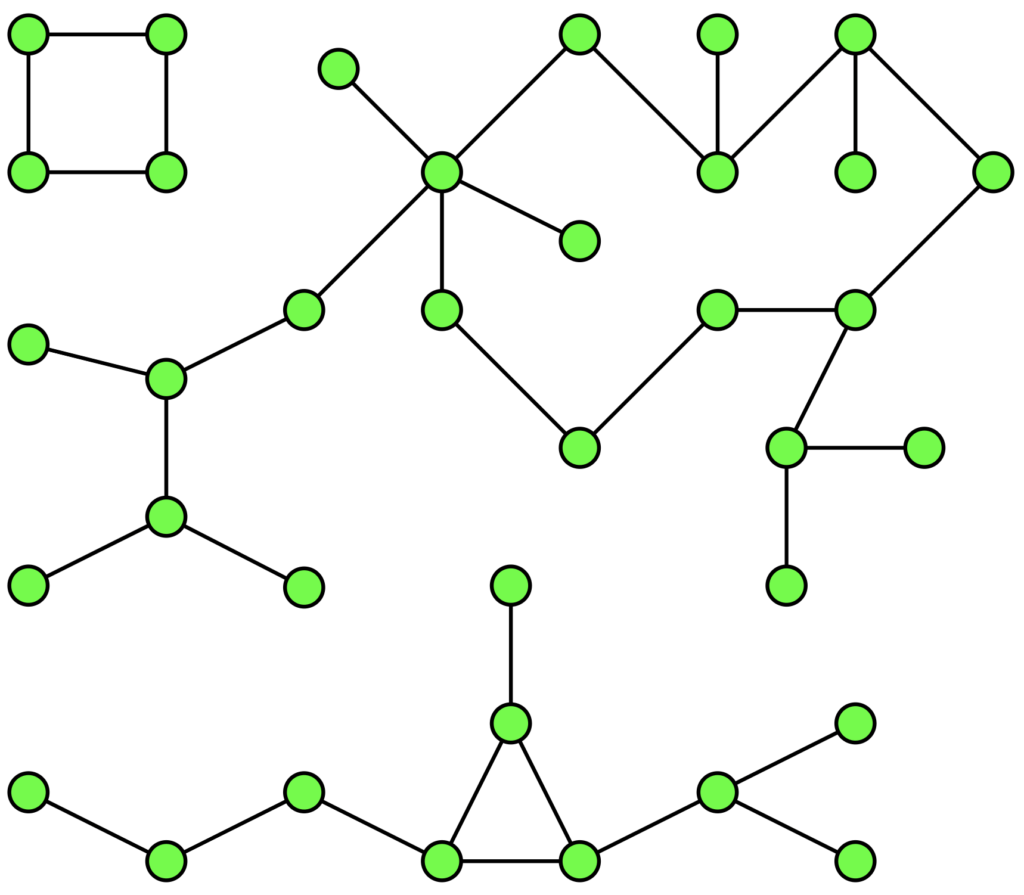
Технически алгоритм объединяет в себе два метода, с помощью которых можно найти кратчайший путь между вершинами графа: поиск по ширине (Breadth First Search, BFS) и поиск по глубине (Depth First Search, DFS). Самые старательные ученики Data Science могут подробнее прочитать о них здесь, а мы сразу перейдем к коду.
Допустим, вам нужно распределить города по континентам, используя информацию о расстоянии между ними. Исходный граф выглядит следующим образом:
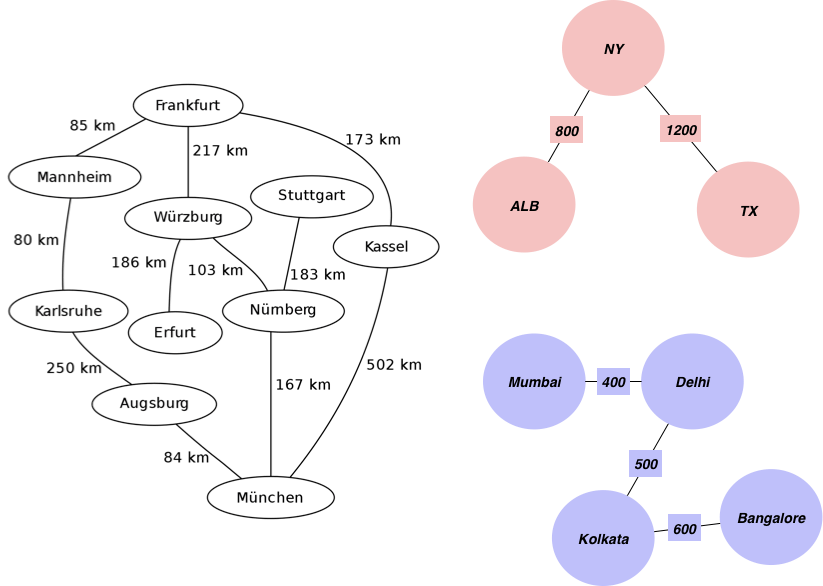
Сначала мы создаем список граней графа, где расстояния будут использоваться в качестве весов:
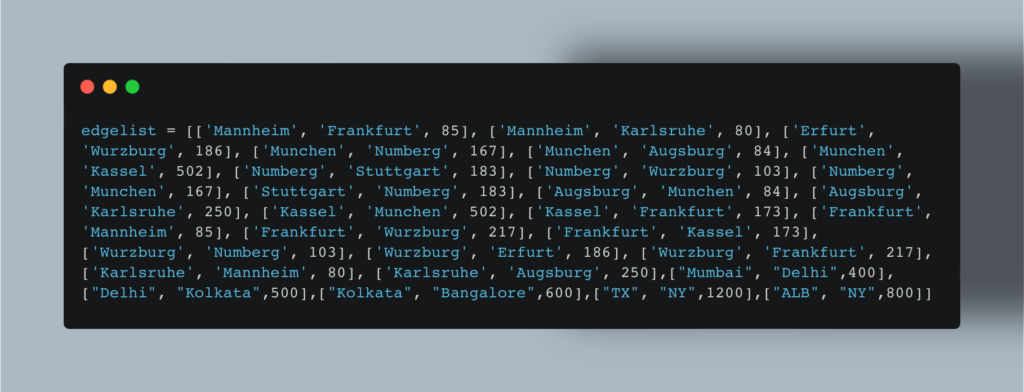
Теперь строим граф с помощью Networkx:

Остается применить к полученной структуре алгоритм связных компонент:

Готово — мы получили три группы городов, объединенных по континентальному принципу. Эту модель можно применять для самых разных целей. Если бы вместо городов у нас были, например, идентификаторы пользователей, а вместо расстояний — их траты в разных товарных категориях, алгоритм сгруппировал бы их по предпочтениям.
Поиск кратчайшего пути
Вычисление наименьшего расстояния между двумя точками — одна из старейших задач программирования. Один из наилучших алгоритмов для ее решения еще в конце 50-х разработал нидерландский математик Эдсгер Дейкстра (Edsger Dijkstra), причем человечество может благодарить за это открытие… его невесту.
Как рассказывал сам Дейкстра, однажды его так утомили походы по магазинам вместе с молодой женой, что во время краткой передышки он задумался — как оптимизировать этот процесс? Буквально за 20 минут он разработал метод, который теперь называется алгоритмом Дейкстры.
Метод прост, как все гениальное. Для начала Data Scientist узнает расстояния от начальной точки до каждой точки в пути. Эти значения присваиваются граням графа. Далее алгоритм поочередно проходит по каждой вершине, на каждом шаге определяя наименьшее расстояние до очередной точки. Когда все точки посещены, вы получаете наименьший маршрут.
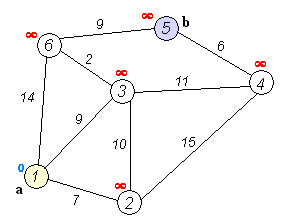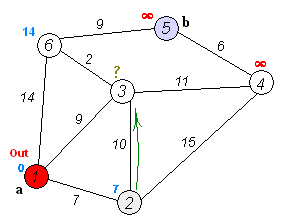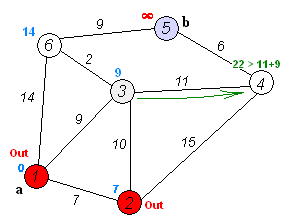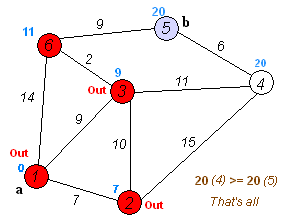
По словам самого математика, метод оказался так прост потому, что у него под рукой не было ни клочка бумаги — все калькуляции приходилось вести в голове. Такой способ не дает углубиться в вычисления, поэтому итоговое решение настолько просто, насколько это вообще возможно.
Теперь о том, как алгоритм Дейкстры реализован в Python. Для решения задачи достаточно двух строчек кода:
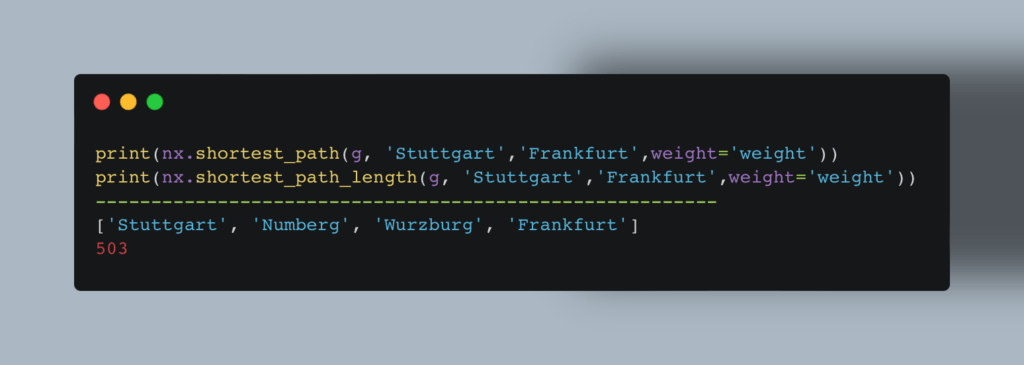
Мы также можем найти кратчайшее расстояние между всеми парами:
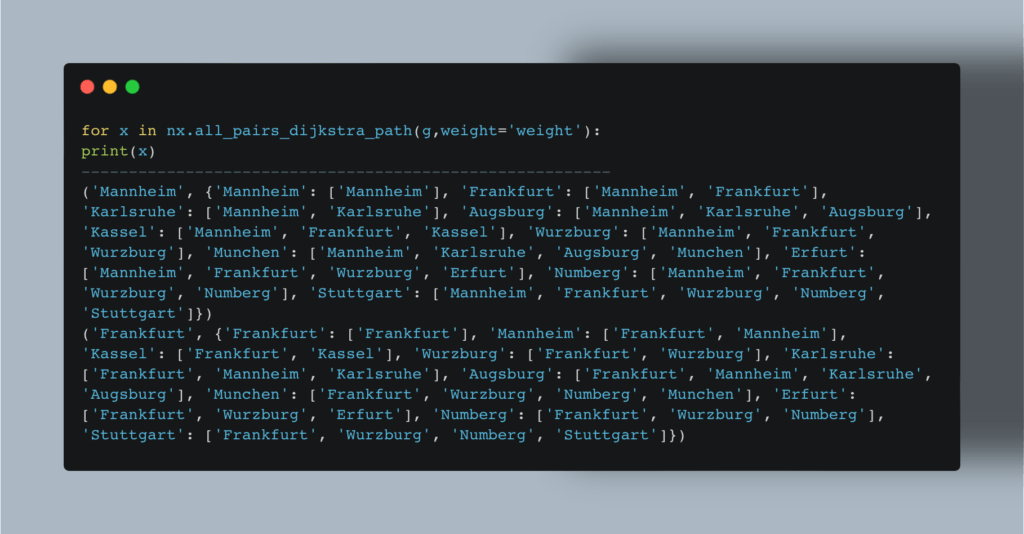
В нашем примере мы определили маршруты между городами, но этот же метод можно использовать и для выстраивания связей между пользователями соцсети, и для планирования оптимального маршрута покупателя в торговом зале, и для любых прочих подобных проблем.
Поиск оптимального пути
Всем знакомы головоломки, в которых нужно начертить какую-либо фигуру, не проходя дважды через одну точку. В профессии Data Scientist такие задачи возникают, когда нужно проложить оптимальный путь для кабеля, помочь торговым представителям или мастерам по обслуживанию банкоматов спланировать маршрут, и так далее.
В каждом случае помогает алгоритм минимального остовного дерева (Minimum Spanning Tree). Этот термин обозначает подграф, который объединяет ребра с минимально возможной суммой весов. Это не всегда означает, что одна вершина не может иметь больше двух ребер — главное значение имеет итоговая сумма их значений.
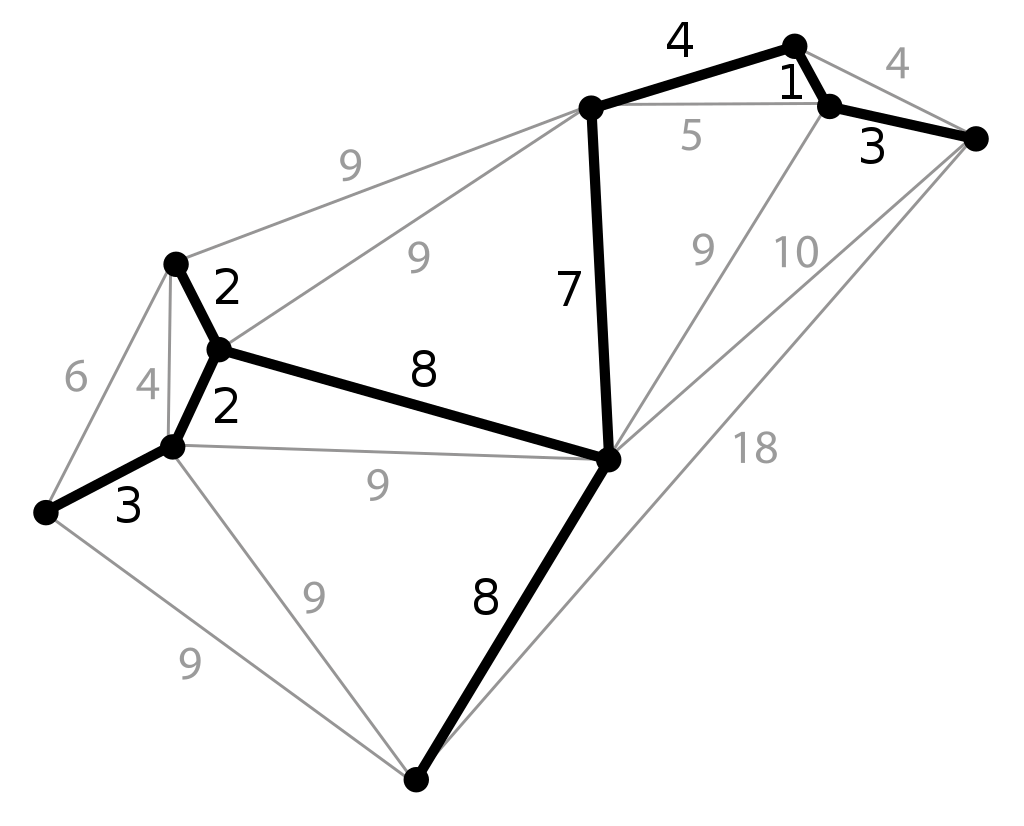
Чтобы построить такую структуру, используйте команду:

Рейтинг вершин графа
Еще одна нередкая задача — найти, какие вершины имеют самое важное значение в рамках того или иного явления. Например, поисковики определяют вес разных интернет-страниц, академики считают, какие научные работы чаще всего ссылаются исследователи, социальные сети отслеживают пользователей с наибольшим количеством подписок.
На примере социальных сетей мы и рассмотрим метод. Достаем из хранилища данных список пользователей Фейсбук*:

И построим граф:

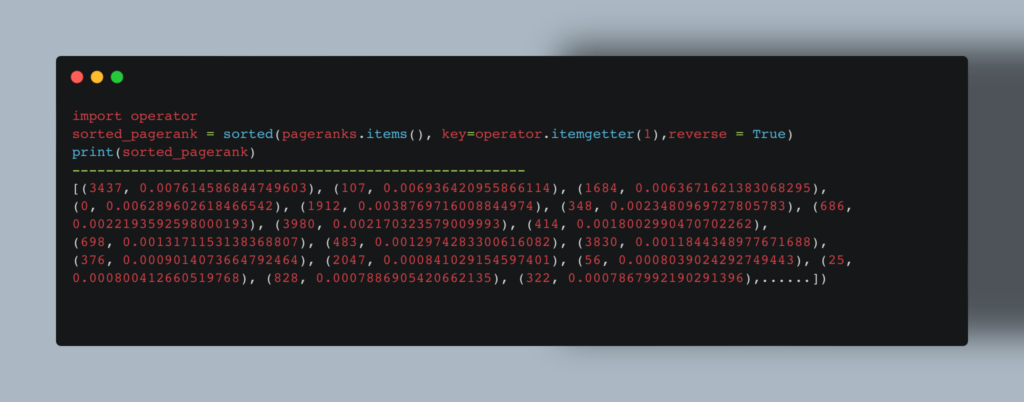
Теперь посмотрим, у каких пользователей наибольшее влияние. Алгоритм Pagerank умеет сам это делать, опираясь на количество онлайн-друзей:
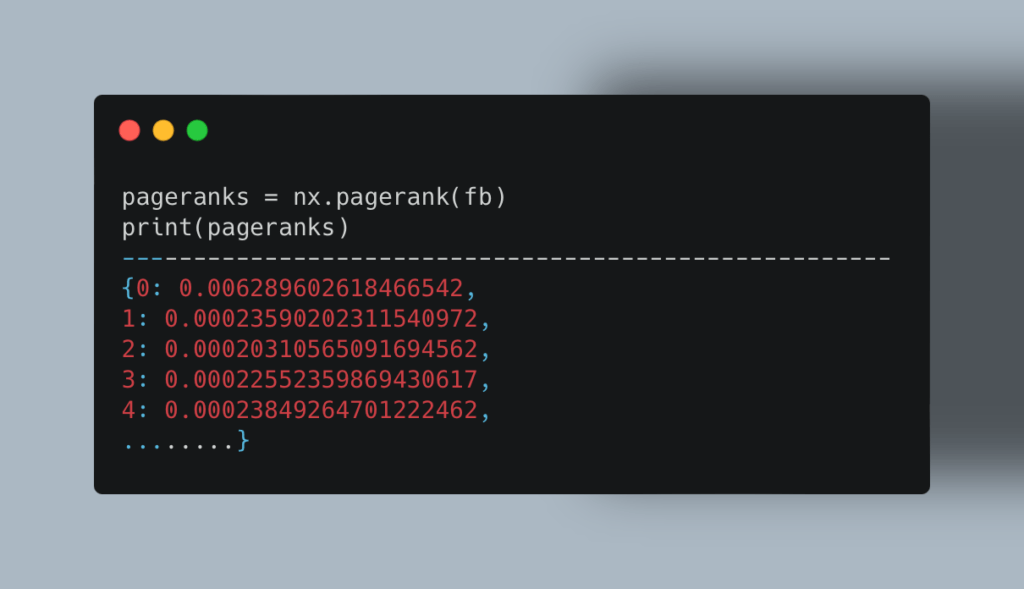
Чтобы узнать пользователей с наибольшим весом, мы используем этот код:
А чтобы определить «самого крутого парня», можно построить подграф:

*деятельность компании Meta Platforms Inc., которой принадлежит Инстаграм / Фейсбук, запрещена на территории РФ в части реализации данной (-ых) социальной (-ых) сети (-ей) на основании осуществления ею экстремистской деятельности
Центральность вершин
Понятие центральности обозначает расстояние какой-либо вершины графа до его центра. Измерение центральности — это еще один способ определить влияние разных участников базы данных.
В отличие от предыдущего метода, определение центральности направлено на выявление не самой главной вершины, а локальных «лидеров», которых может быть и пять, и десять. Таким образом Data Scientist может изучать распространение информации в сообществе (определять изначальное сообщение и следить за его распространением через несколько точек входа), отслеживать развитие болезней (строить карту заражений с нулевыми пациентами), контролировать телекоммуникационные и прочие сети.
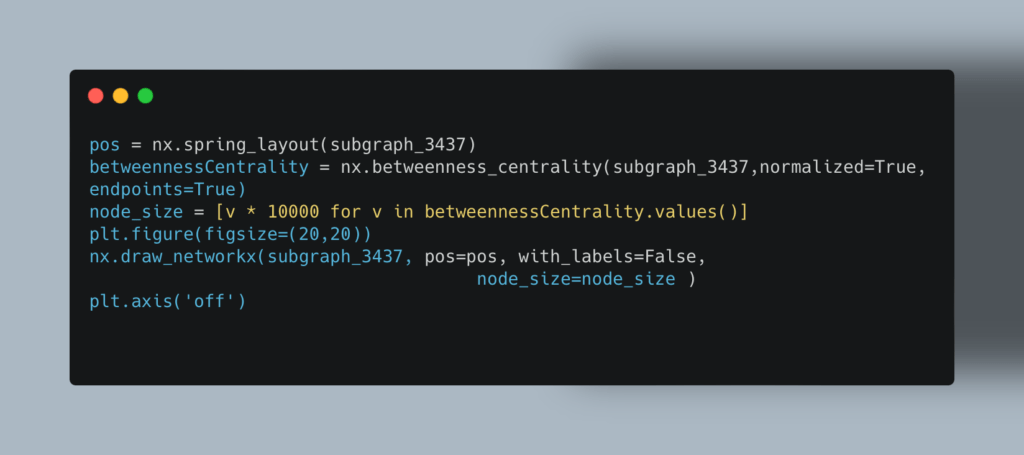
Существует множество метрик центральности. В нашем примере мы расскажем, как найти на графе вершины, которые чаще всего связывают между собой разрозненные группы точек. На практике это может быть перевалочный пункт на географическом маршруте, «бутылочное горлышко» в каких-либо процессах, человек-посредник, который знакомит между собой других людей. В теории графов это и называется степенью посредничества (Betweenness Centrality).
Чтобы найти такие вершины, используйте следующий код:
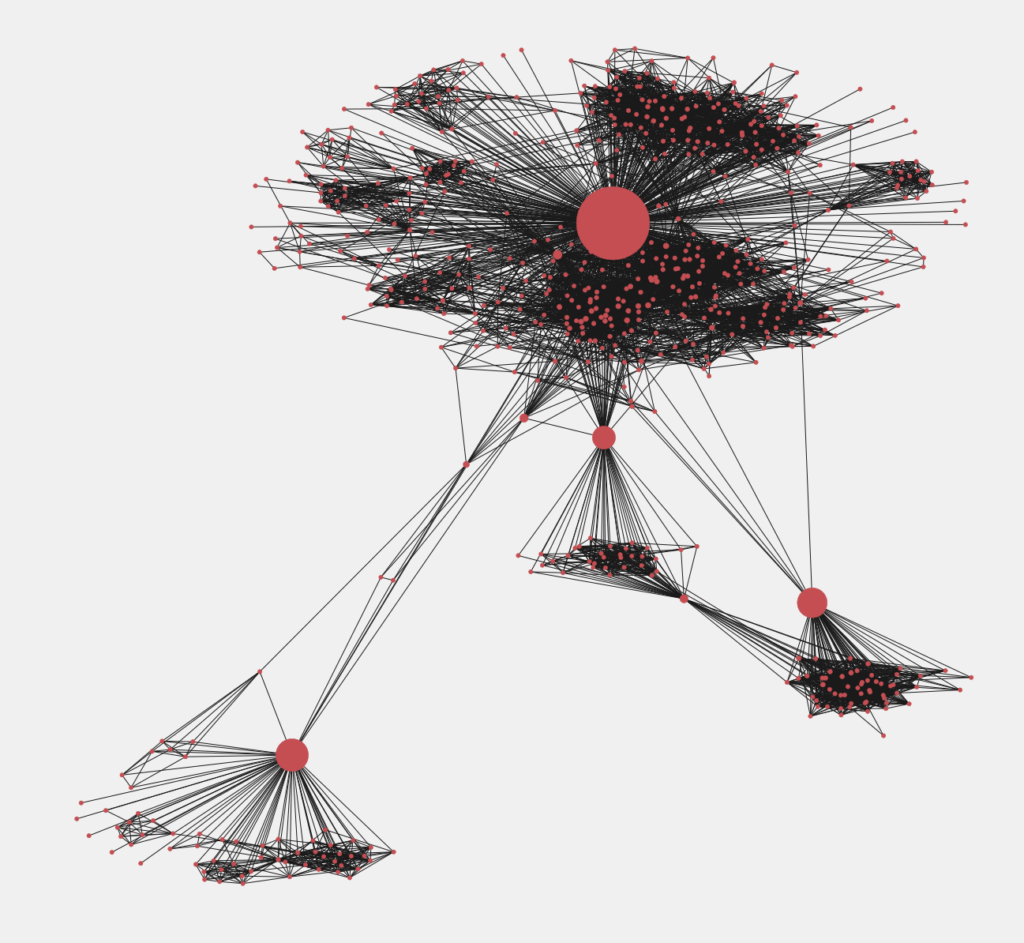
Чем больше диаметр круга, тем больше его степень посредничества. Если устранить эти узлы из системы, большой граф разобьется на несколько малых.
Мы рассмотрели всего пять графов, но даже такой краткий экскурс дает представление о том, какой это мощный инструмент Data Science. Изучайте графы, используйте их в своих проектах, и вы получите множество инсайтов о том, как работает наш постоянно меняющийся мир.
