


На хакатоне Skillfactory с бизнес-партнерами студентам направления «Компьютерное зрение» поставили нетривиальную задачу: разработать систему распознавания актеров и разделения видео на отрезки по смыслу для онлайн-кинотеатра KION. О том, как они организовали работу, с какими сложностями столкнулись и какой выдали результат — рассказываем в статье.
«Мы рассчитывали на свежий взгляд на проблему»: с каким брифом пришли партнеры

KION — онлайн-кинотеатр с собственными сериалами, фильмами и спортивными трансляциями. Платформа делает упор на цельный пользовательский опыт: от визуального стиля до технических решений, которые помогают быстро ориентироваться в контенте.
Видео в KION — это динамичный многокамерный материал: диалоги, сцены действия, постоянная смена темпа, ракурсов и освещения. В таком потоке важно понимать не только где меняется картинка, но и где заканчивается сюжетный фрагмент. Отсюда возник вопрос — как автоматически разбивать видео на логически завершенные сцены, а не просто фиксировать монтажные склейки. Второй вопрос связан с персонажами: как надежно находить и отслеживать героев или объекты по всему видео, даже если меняется камера, ракурс, свет или внешний вид.
Партнеры хотели получить решение, которое делит часовое видео на осмысленные сюжетные блоки и одновременно определяет людей и другие объекты, удерживая их треки на протяжении всего ролика. Сцена в таком подходе — это не смена кадров, а завершенный момент истории, например диалог или действие. Один сюжетный фрагмент может включать кадры с разных камер, от крупных планов до общих.

«Мы распределили задачи, опираясь на возможности команды»
За реализацию проекта взялись несколько команд, но победила команда №3. Она состоит из шести студентов онлайн-магистратуры Skillfactory и ТГУ по нейросетям и компьютерному зрению. В нее вошли тимлид Алексей Дюков (инженер-схемотехник), Екатерина Жилина (ученый), Глеб Плотников (сервисный инженер по радиооборудованию), Наталия Малышкина (ведущий инженер ОАО РЖД), Георгий Понкратов (веб-маркетолог) и Сергей Корюкалов (маркетолог-аналитик). Преимуществом команды было то, что они уже работали вместе на другом хакатоне.
Совместную работу они координировали в групповом чате в Telegram. Чтобы распределить задачи, тимлид собрал информацию о каждом: чем занимается, какой опыт в программировании есть, интересуется ли компьютерным зрением и сколько времени готов уделять проекту.
Кейс разбили на 11 задач: разметка видео, детекция и трекинг людей, распознавание лиц, поиск переключений камер, анализ звука, классификация фона, работа с субтитрами (включая генерацию через распознавание речи и LLM), модель для обнаружения смены сцен, сборка и докеризация проекта, подготовка материалов для презентации и доклада.

В процессе работы были ежедневные встречи, больничные, сложности с интеграцией решений и авралы из-за нагрузки по учебе. Но в конечном итоге студенты сформировали и презентовали решение.

«Сложнее всего было с субтитрами»: каким получился результат
Команда разделила решение кейса на две независимые ветки: дробление видео на сцены и распознавание и трекинг актеров.
Разбиение видео на сцены
Чтобы выделить сцены, нужно было решить несколько подзадач:
— разбить видео на шоты (короткие отрезки с одной камеры);
— выделить сцены по характеристикам звука;
— выделить сцены по анализу субтитров.
Затем — объединить результаты всех алгоритмов.
Параллельно шла работа со звуком. Студенты анализировали громкость и спектральную плотность. Сменой сцены считали резкие изменения этих параметров и одновременную смену фонового звучания в течение нескольких секунд.
Алгоритм по субтитрам строился на языковой модели, которая отслеживала смену смысла в тексте.
Трекинг актеров
Задача трекинга оказалась сложнее, чем просто распознать лица. Нужно было находить людей в кадре, отслеживать их внутри каждого шота и определять актеров по лицам. На выходе команда формировала размеченные шоты с треками и именами актеров, а также таблицу, показывающую, кто присутствует в каждом кадре.
Для трекинга сначала использовали алгоритм YOLO, но он часто «ронял» треки и присваивал одному и тому же актеру разные ID внутри одного шота. Это портило статистику. Поэтому студенты разработали собственный алгоритм трекинга: он использовал YOLO как детектор, но опирался на кастомно разработанную логику сопоставления треков.
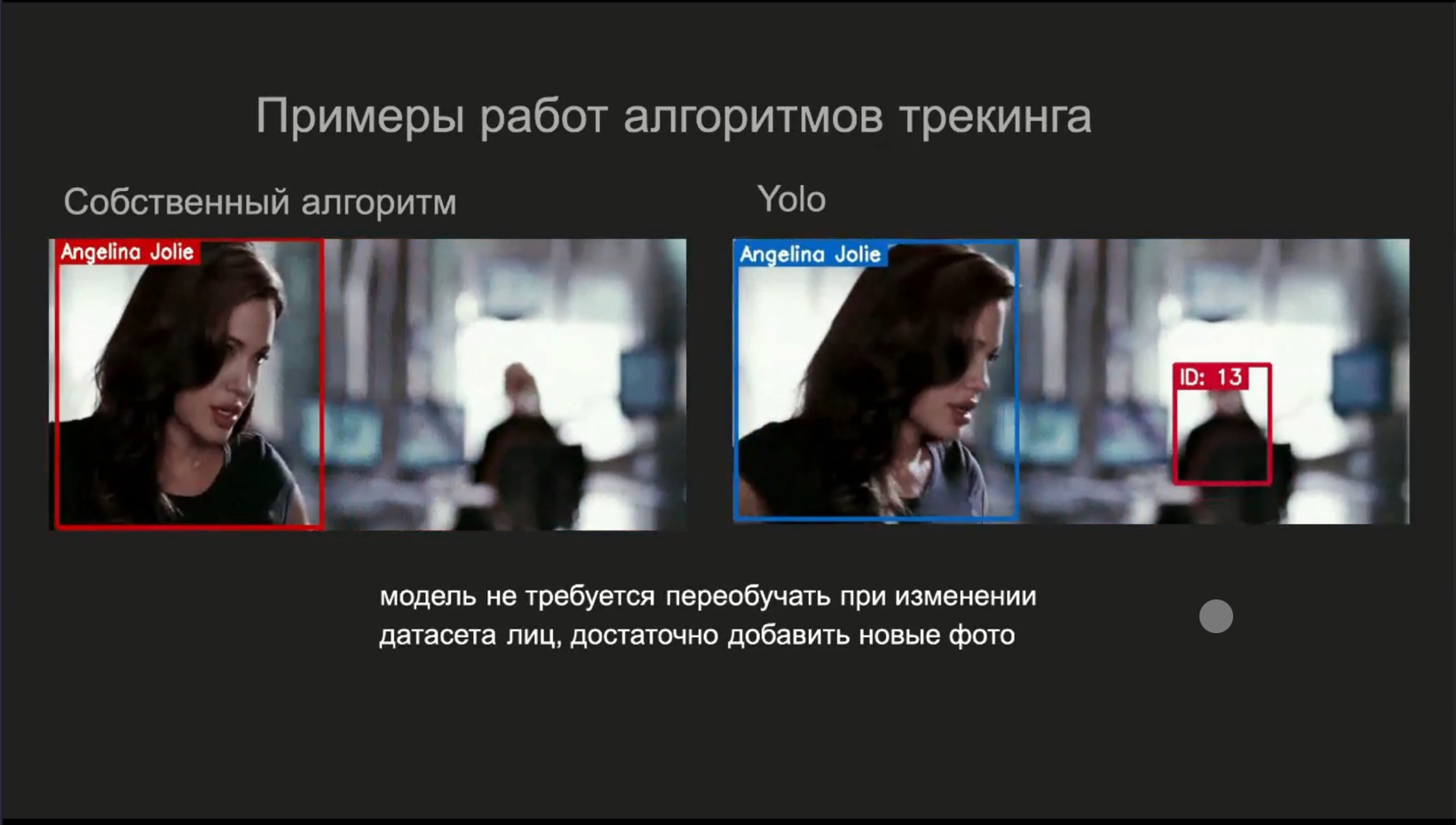
Для распознавания лиц применили библиотеку dlib. Команда собрала базу изображений нескольких десятков актеров — в разном возрасте и в разных условиях, чтобы повысить точность.
Когда отдельные алгоритмы начали давать стабильный результат, проект собрали и упаковали его в Docker.
С хакатона — в R&D: что будет дальше с проектом студентов
Партнеры высоко оценили решение, которое предложили студенты. Они отметили, что команда не только хорошо поработала с алгоритмами, но и сформировала комплексное инженерное воплощение. Потенциал внедрения наработок студентов оценят в R&D отделе ИИ-команды KION.
Хакатон позволил студентам отточить свои навыки на практике и поработать с реальной задачей от бизнес-партнера. Узнайте больше о хакатонах и песочницах от Skillfactory и принимайте участие!