

Компьютерное зрение, или CV, — общее название для множества технологий распознавания изображений: выделения объектов, сравнения лиц или оценки того, что происходит на снимке. Эти технологии используются не только в графических редакторах и «умных» камерах. Все чаще CV применяют в более сложных и ответственных сферах, например медицинских исследованиях.
Вместе с Кириллом Симоновым, ML-разработчиком с экспертизой в компьютерном зрении, разбираемся в принципах работы CV и рассказываем, какие задачи технология решает в медицине.
Какие подходы используются в компьютерном зрении
Компьютерное зрение существует намного дольше, чем современные нейросети. CV-инженеры использовали алгоритмы, которые выделяли ключевые признаки на изображениях с помощью математики, например линейной алгебры и аналитической геометрии.
С развитием технологий, ростом вычислительных мощностей и объемов данных многие задачи начали решать с помощью нейросетей. Сейчас два подхода — классическое CV и нейросетевое — существуют одновременно. Рассказываем подробнее, чем они различаются и для каких медицинских задач можно применить каждый из них.

Классическое CV. Это набор алгоритмов, которые обрабатывают изображения с точки зрения математики. Картинку можно воспринимать как сигнал, двумерную или трехмерную матрицу чисел — а значит, применять к ней математические преобразования. Благодаря этому можно изменять изображение или выделять из него полезную информацию. Например:
- с помощью операции взятия градиента можно обнаружить резкий перепад цвета и таким образом выделить границы объекта;
- обработка амплитудной составляющей помогает найти и отфильтровать шумы;
- преобразование изображений в векторное представление позволяет сравнивать их — похожие векторы означают, что объекты на картинках тоже схожи.
В качестве примера классического метода CV можно назвать HOG — гистограмму направленных градиентов. Она помогает построить векторное представление изображения с информацией о перепадах цвета и границах объектов. Если, например, скомбинировать HOG с алгоритмом классификации SVM (Support Vector Machine), можно получить простейший детектор объектов на изображении. В свое время он был прорывным, хотя сейчас уступил нейросетям.
Классические методы CV требуют меньше вычислительных ресурсов и с высокой точностью решают простые задачи. В медицине их используют чаще как вспомогательный инструмент: для обнаружения объектов, предварительного выделения интересующих областей и т. д.
Иногда выгоднее использовать именно классические методы, например для поиска ключевых точек на изображении или фильтрации картинок. Хотя нейросети могут справиться с этими задачами, традиционные алгоритмы работают быстрее.
Для классического компьютерного зрения часто используют библиотеку OpenCV — она содержит множество алгоритмов и поддерживает разные языки программирования. Инженеры, работающие с классическими методами, также применяют Python-библиотеки вроде NumPy, SciPy или Scikit-image, которые содержат необходимые математические функции для обработки данных.
Нейросетевое CV. Первые нейронные сети появились еще несколько десятилетий назад, но были достаточно примитивными и не могли работать с n-мерными пространствами. Они не справлялись с точной обработкой изображений.
Ситуация изменилась с появлением сверточной архитектуры, которая хорошо подходит для задач компьютерного зрения. Специальные слои анализируют пиксели, которые находятся близко друг к другу и содержат непрерывную визуальную информацию. Благодаря этому они могут понимать контекст изображения.
Большинство современных CV-инструментов используют сверточные нейросети, которые детально анализируют, сегментируют изображения и находят сложные объекты, в том числе в медицинских целях.
Для работы с нейросетевым CV обычно используют Python и одну из библиотек: PyTorch или TensorFlow. Обе предназначены для создания и обучения моделей, а выбор между ними зависит от предпочтений инженера.
Для чего используют компьютерное зрение
Традиционно CV применяется для трех основных типов задач: классификации, детекции и сегментации.

Классификация
Это самая простая из задач — понять, относится ли картинка к определенному классу. Результат всегда бинарный: «да» (1), если изображение относится к этому классу, или «нет» (0), если не относится. Существует также «мультиклассификация», когда одна картинка может относиться к нескольким классам.
В медицине классификация в чистом виде встречается не так часто. Например, для задачи — узнать, есть ли подозрительные участки на рентгеновском снимке, ответа формата «да» или «нет» недостаточно, и к нему нужны уточнения. С ними как раз справляются следующие задачи: детекция и сегментация.
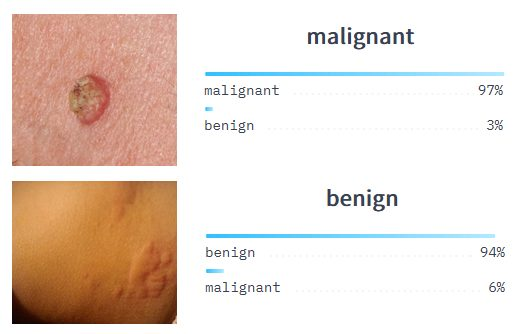
Детекция
При решении этой задачи модель не только отвечает, присутствует ли объект на изображении, но и детектирует его — определяет примерные границы.
Если картинка двумерная, модель находит четыре угловые точки, которые образуют прямоугольник вокруг объекта. Для трехмерных изображений вместо прямоугольника строится параллелепипед, поэтому точек нужно уже восемь. При работе с видео детекция может преобразоваться в задачу трекинга: модель должна не только обнаружить объект, но и отслеживать его перемещение в кадре.
Если продолжить пример с рентгеновским снимком, задача детекции — определить, где именно находится подозрительный участок. Позже найденную область можно отправить в классификатор, например чтобы ответить на вопрос, опухоль это или нет.
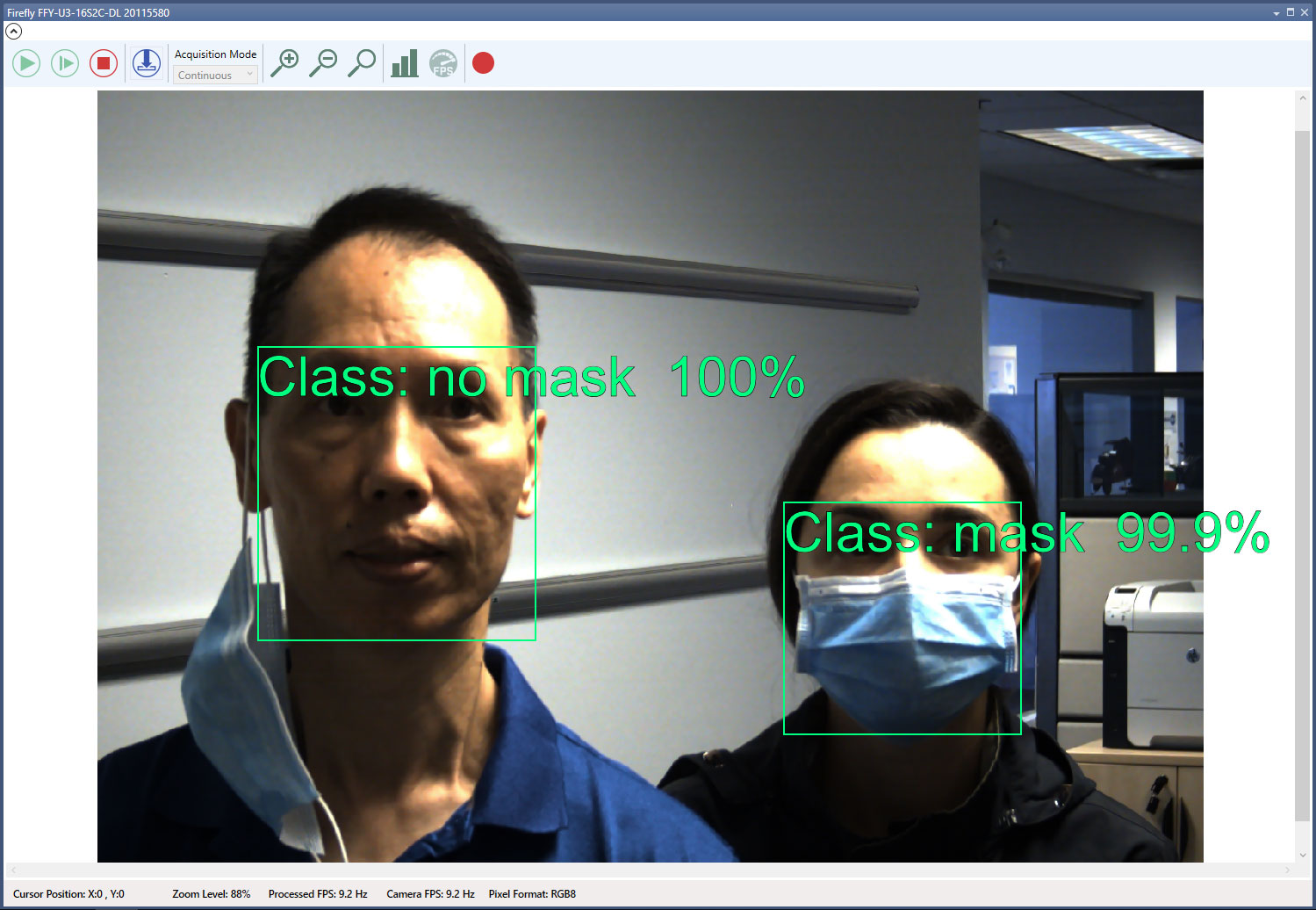
Сегментация
Это более сложная задача — модель классифицирует каждый пиксель и определяет точные границы объекта. Существует два типа сегментации:
- семантическая — выделяет разные классы объектов. Например, на изображении с несколькими кистами модель распознает их все и отнесет к общему классу «киста»;
- инстанс — выделяет конкретные объекты. На том же снимке модель присвоит каждой кисте свой номер или условное обозначение.
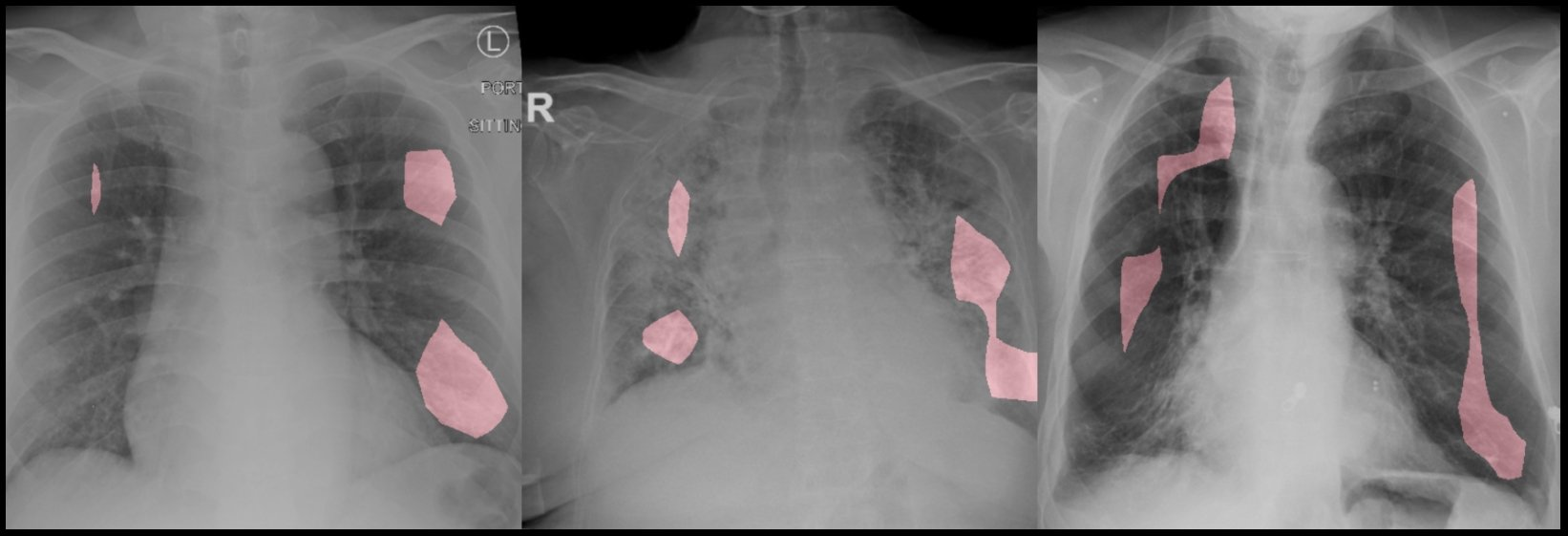
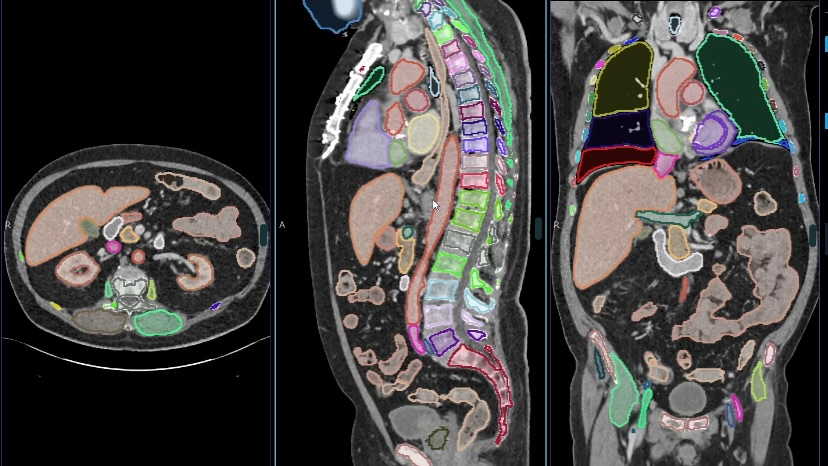
Кроме основных трех, в CV есть и другие задачи, например распознавание и генерация. Распознавание — это сравнение изображения с уже известными образцами, например для определения человека на фотографии. А генерация — создание новых картинок на основе существующих.
Задача генерации используется и в медицине, в основном для обучения новых моделей. Качественных медицинских данных, на которых можно обучать алгоритмы, мало, а их подготовка занимает много времени. Поэтому данные искусственно создают на основе существующих с помощью генеративных алгоритмов.
Все перечисленные задачи часто решаются в комбинации, а не по отдельности. Для этого несколько моделей объединяют в каскад — цепочку, которая последовательно выполняет заданный набор действий. Например, сначала детектирует объект, а потом классифицирует или распознает его:
- детекция показывает, где на снимке находится опухоль, и выделяет этот участок изображения;
- классификация определяет, похожа ли опухоль на злокачественную;
- сегментация находит ее точные границы;
- распознавание с определенной точностью сопоставляет тип опухоли с теми, которые известны модели.
Какие задачи CV может решать в медицине
Диагностика
Это основная сфера, где используют компьютерное зрение. Среди задач, например, обнаружение и локализация опухоли или другого новообразования, оценка активности мозга, изучение плотностей тканей и т. д. С помощью CV можно найти закономерности и аномалии на снимках, таких как рентген, КТ, МРТ, — это помогает быстрее и точнее ставить диагноз.
CV-алгоритмы применяли во время пандемии коронавируса: они помогали оценить результаты КТ больных и тем самым снижали нагрузку на врачей. За 30 секунд такой алгоритм мог обработать до 400 снимков — это намного больше, чем успел бы человек.
Наблюдение
Здесь речь идет о пациентах с уже подтвержденной болезнью. Компьютерное зрение помогает вовремя отследить изменения в их состоянии: рост или уменьшение опухоли, скорость процесса восстановления тканей после травмы и т. д. Например, CV могут применять, чтобы предотвратить пролежни у лежачих пациентов. Такие алгоритмы отслеживают позу больного, оценивают риск появления пролежней и анализируют повреждения.

Анализ лекарств
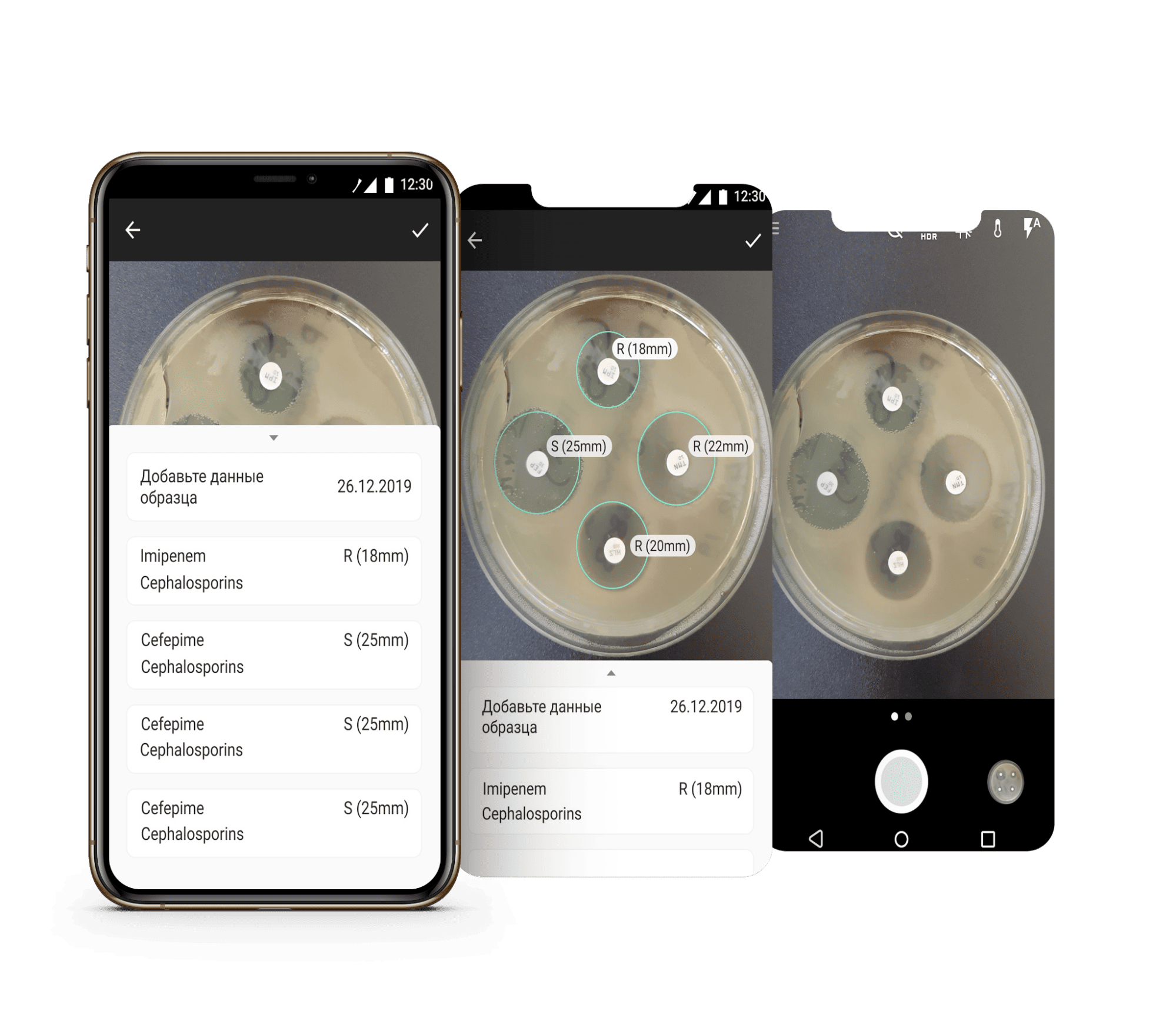
В этой области обычно применяют другие алгоритмы машинного обучения, которые работают не с изображениями, а например, с химическими формулами. При этом компьютерное зрение тоже используют — для специфических задач. Например, оценки, с какой скоростью антибиотик уничтожает клеточные культуры бактерий. CV-алгоритм детектирует зоны в чашке Петри, где замедление роста активнее всего, и помогает подобрать антибиотик для лечения.
Производство
Еще одна область применения CV в медицине — создание препаратов. Алгоритмы контролируют качество на фармацевтических заводах: например, проверяют, все ли таблетки в блистере на месте, не нарушена ли целостность упаковки и правильно ли промаркирован продукт.

Почему медицина — особенная сфера для CV?
У компьютерного зрения в медицине свои особенности, которые отличают его от других задач машинного обучения. Это связано с тем, что медицинские снимки — громоздкие и объемные типы изображений, которые содержат большое количество данных и требуют более сложных методов обработки.
Разберем подробнее эти особенности.
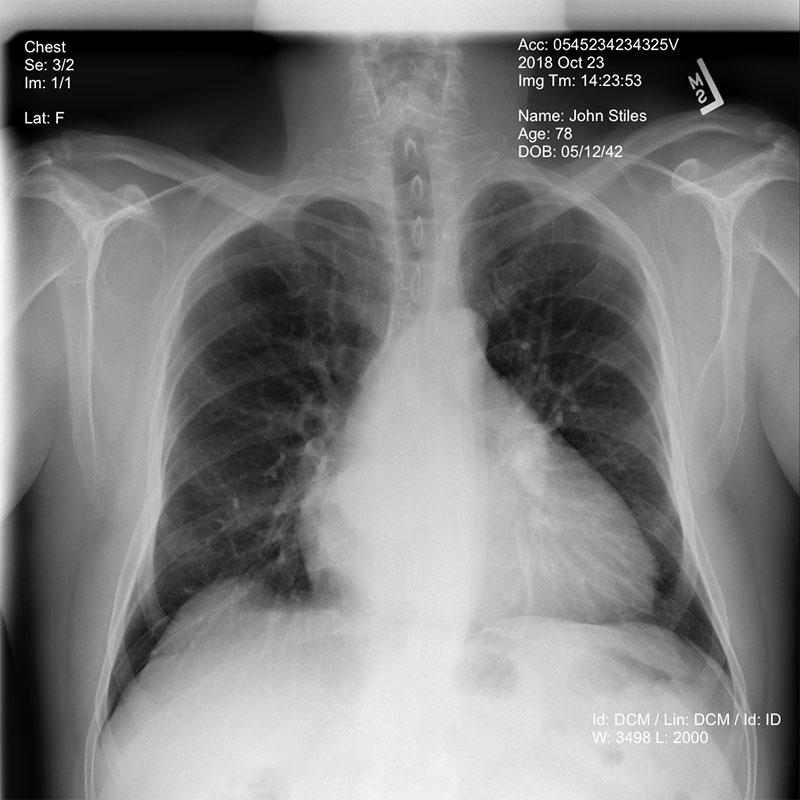
Медицинские данные чаще всего трехмерные. Для полноценной диагностики двумерного изображения недостаточно. Рентген делают в нескольких проекциях, а более сложные исследования, такие как КТ или МРТ, создают детализированные 3D-модели. Они могут быть очень большими, включать тысячи элементов и содержать метаданные, такие как информация о пациенте и процедуре.
Поэтому для обработки таких данных используют n-мерные сверточные нейронные сети. Они анализируют изображения в трех измерениях, а иногда и в четырех — когда важно учитывать изменение данных во времени, как при сканировании активности мозга. Эти сети требуют много вычислительных ресурсов, поэтому на обычных компьютерах они не работают — нужны специальные серверы или облачные сервисы.
Результаты сканирования — это не обычные картинки. 3D-изображения содержат данные в виде вокселей (трехмерных пикселей) или векторов. Рентген, КТ и МРТ хранят их в специфических форматах, которые отличаются от привычных картинок. Вот несколько примеров:
- DICOM — файл, где кроме изображения есть множество метаданных, например информация о пациенте и самом исследовании;
- NIfTI — стандарт для нейровизуализации, например при сканированиях головного мозга. Файл содержит информацию об ориентации объектов и изменениях снимков во времени. То есть такой формат ближе к видео или сигналу, чем к фото;
- NrrD — формат для n-мерных растровых данных, которые почти не обработаны и близки к исходным, что помогает упростить компьютерную обработку.
Таких форматов десятки, и перед загрузкой в модель каждый нужно перевести в понятный алгоритму вид. Это создает дополнительную задачу для специалистов — как правильно преобразовать данные без потери важной информации.
Данные сложнее подготовить. Перед использованием модели в реальных задачах ее нужно обучить на большом объеме тестовых данных. Например, это могут быть трехмерные снимки с разметкой опухолей по вокселям. Разметкой занимается врач, который умеет читать такие изображения. Это занимает много времени: представьте, что нужно вручную выделить каждую точку опухоли на снимке размером 1000 × 1000 × 1000. Кроме того, помимо основной работы, специалист должен научиться пользоваться программой для разметки.
Из-за этого в медицинском CV в медицине часто не хватает качественных датасетов для обучения. В таких случаях используют генеративный искусственный интеллект, который на основе существующих данных создает «синтетические» наборы. Это быстрее, чем ручная разметка, и позволяет снять часть нагрузки с врачей.
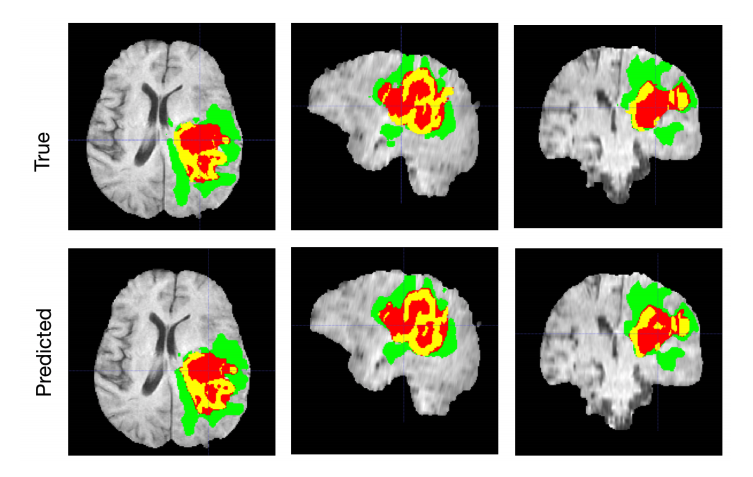
Точность интерпретации имеет большое значение. В медицине даже небольшая ошибка в расчетах может стать критичной, потому что речь идет о вопросах жизни и здоровья. При этом сканы содержат огромные объемы данных, которые могут усложнить работу модели.
Часто возникает проблема переобучения. Это ситуация, когда модель слишком точно подстраивается под обучающие данные и теряет способность правильно обобщать новые. В этом случае алгоритм дает уверенные, но иногда неправильные ответы. Возникает отдельная задача — откалибровать модель так, чтобы повысить точность и снизить чрезмерную уверенность в прогнозах.
Как развивается CV в медицине
Одна из важных задач — справиться со сложностями, о которых мы рассказали в прошлом разделе. То есть получить больше качественных данных и сохранить высокую степень точности при исследованиях. А еще — расширить применение CV и нейросетей в медицине. Например:
- Развивать комплексные решения. Алгоритмы смогут анализировать не только одно заболевание. Например, при диагностике порока сердца модель одновременно выявит признаки остеопороза.
- Повышать уровень автоматизации. Свести участие врача к минимуму при использовании алгоритмов в диагностике. Это сложная задача, потому что, кроме точных технологий, нужна юридическая база. Однако такие решения уже существуют: например, система «Кибернож» для радиохирургии сама определяет, куда подать излучение, а ткани пациента осматривает с помощью непрерывного рентгеновского сканирования в реальном времени.
- Внедрять CV-решения в больницы. Пока что компьютерное зрение в основном используется в высокотехнологичных центрах. Важно сделать его доступным для обычных медучреждений. Так компьютерное зрение централизованно внедряют в медучреждения Москвы — с его помощью провели больше 11 млн исследований.
Компьютерное зрение уже меняет медицину, и с развитием технологий его роль будет расти. В будущем диагностика и лечение могут стать быстрее и проще, потому что часть задач возьмет на себя компьютер.