
LRU, или LRU cache (Least Recently Used) — алгоритм для хранения ограниченного объема данных: из хранилища вытесняется информация, которая не использовалась дольше всего. Его применяют при организации кэша.

Кэш — это, например, данные приложений, которые те «держат под рукой», чтобы не загружать каждый раз при открытии. В таких хранилищах обычно находится информация, которую часто используют. Алгоритм LRU оставляет в кэше данные, которые использовались недавно, а те, к которым обращались давно, вытесняет.
LRU — не единственный алгоритм для организации кэша. Есть похожая модель FIFO (First-In/First-Out). Она удаляет самые старые элементы. В отличие от нее, LRU смотрит не на время добавления, а на то, когда информацию использовали в последний раз.
Кто и когда пользуется LRU
LRU может использовать любой разработчик при решении прикладных задач. Кэш хранят приложения, сайты, иногда небольшие программы. Он бывает нужен для сохранения промежуточных результатов работы.
Выбор алгоритма при построении кэша зависит от того, как будет использоваться память. LRU применяется, если данные, к которым недавно обращались, скорее всего, вскоре понадобятся повторно. Это, например, недавно открытые документы в текстовом редакторе. В ситуациях, когда к файлам обращаются раз в запланированный период времени, например при циклическом сканировании, LRU не подойдет.

Как работает алгоритм
Реализовать алгоритм можно на любом языке программирования: C и C++, Java, Python и других. В популярных языках для LRU и других востребованных алгоритмов есть свои библиотеки и функции.
Для использования алгоритма нужно хранить данные в кэше вместе с временной меткой — она показывает, когда информацию запрашивали в последний раз. Алгоритм работает так:
- когда программа обращается к данным, она проверяет, есть ли они в кэше;
- если данные есть, их временная метка обновляется;
- если данных нет, они добавляются в кэш;
- пока в кэше есть место, новые данные добавляются туда без вытеснения имеющихся;
- когда место заканчивается, перед добавлением новых данных алгоритм проверяет временные метки;
- он находит элемент с самой старой временной меткой;
- этот элемент удаляется из кэша, а на его место добавляется новая информация.
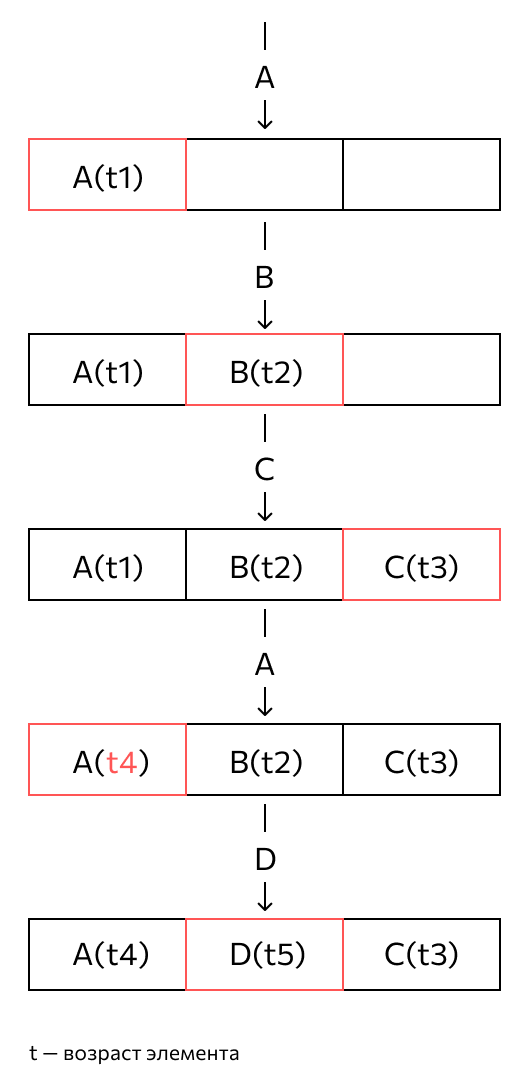
Размер кэша фиксирован одним из двух способов: или в нем может храниться определенное количество элементов, или ограничен объем памяти.

Преимущества и недостатки
Преимущества:
- фиксированный размер кэша;
- ограниченный расход памяти;
- высокая скорость работы приложений и пр.
Недостатки:
- алгоритм не учитывает ситуации, когда к данным обращаются раз в определенный промежуток времени. Для них нельзя сделать исключение;
- нужно хранить и постоянно обновлять временную метку.
Как реализовать алгоритм
Обычно реализация включает две структуры: хеш-таблицу с данными и список, где хранятся временные метки. Каждому элементу в таблице соответствует метка в списке — она определяет приоритет. Когда программа обращается к кэшу, чтобы добавить туда данные, алгоритм сверяется со списком приоритетов. А если к данным, которые есть в кэше, нужно обратиться, алгоритм не просто сверяется, а перезаписывает временную метку.

0 комментариев