


Когда мы открываем сайт, мы видим готовый интерфейс — текст, изображения, кнопки и анимации. Но за этой визуальной оболочкой скрывается техническая структура, которую браузер получает и обрабатывает каждую секунду.
Исходный код страницы — это набор инструкций, определяющих, как именно сайт будет выглядеть и работать. Разобраться в нем может любой пользователь: для этого не нужны специальные программы или доступ к серверу.

В этом материале — о том, как открыть код страницы, что в нем можно найти и почему это полезно не только разработчикам.
Что такое исходный код страницы
Любая веб-страница, которую мы видим в браузере, на самом деле представляет собой набор инструкций. Эти инструкции написаны на языках разметки и программирования и называются исходным кодом страницы. Браузер «читает» этот код и на его основе отображает текст, изображения, кнопки, формы и другие элементы интерфейса.
В основе лежит HTML — он отвечает за структуру страницы: где находится заголовок, где абзац, где ссылка или картинка. За внешний вид отвечает CSS — стили определяют цвета, шрифты, отступы и расположение блоков. А интерактивность — выпадающие меню, анимации, отправка форм без перезагрузки — обеспечивается с помощью JavaScript. Вместе эти три компонента формируют то, что пользователь воспринимает как «сайт».
Просмотр исходного кода — это не взлом и не доступ к скрытой информации. Это стандартная функция любого браузера. Код страницы по определению открыт: иначе браузер не смог бы его обработать. Поэтому любой пользователь может посмотреть, из чего состоит сайт.
Зачем это нужно? Причины могут быть разными. Начинающие разработчики изучают код, чтобы понять, как устроены страницы и как реализованы те или иные элементы. SEO-специалисты проверяют метатеги и технические параметры. Маркетологи могут посмотреть, какие аналитические сервисы подключены. Редакторы — убедиться, что заголовки размечены корректно. Даже обычному пользователю иногда полезно заглянуть в код, чтобы разобраться, почему страница отображается некорректно или какие технологии используются на сайте.
Как открыть исходный код страницы
Посмотреть исходный код можно в любом современном браузере — для этого не нужны специальные программы или дополнительные навыки.
Самый простой способ — открыть полную версию кода страницы. Для этого достаточно кликнуть правой кнопкой мыши в любом месте сайта и выбрать пункт «Просмотреть код страницы» (или View Page Source). Быстрый вариант — использовать сочетание клавиш: Ctrl + U на Windows или Cmd + Option + U на macOS. В отдельной вкладке откроется HTML-документ в том виде, в каком браузер получил его от сервера.
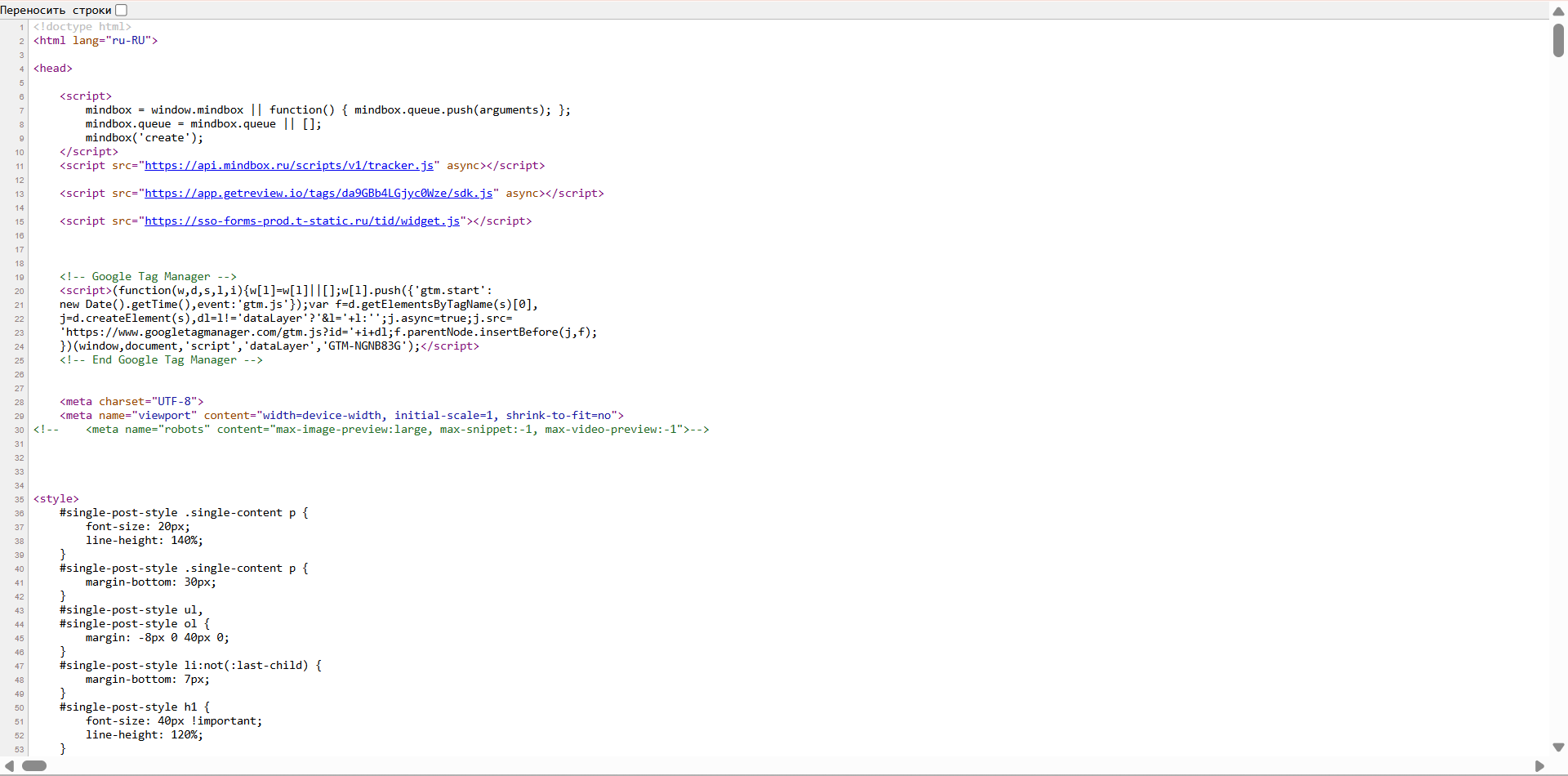
Этот способ удобен, если нужно быстро посмотреть структуру страницы, найти метатеги, проверить заголовки или убедиться, что нужный текст действительно присутствует в разметке.
Второй способ — открыть инструменты разработчика (DevTools). Это более продвинутый режим просмотра. Он запускается через клавишу F12 или сочетание Ctrl + Shift + I (Windows) / Cmd + Option + I (macOS).
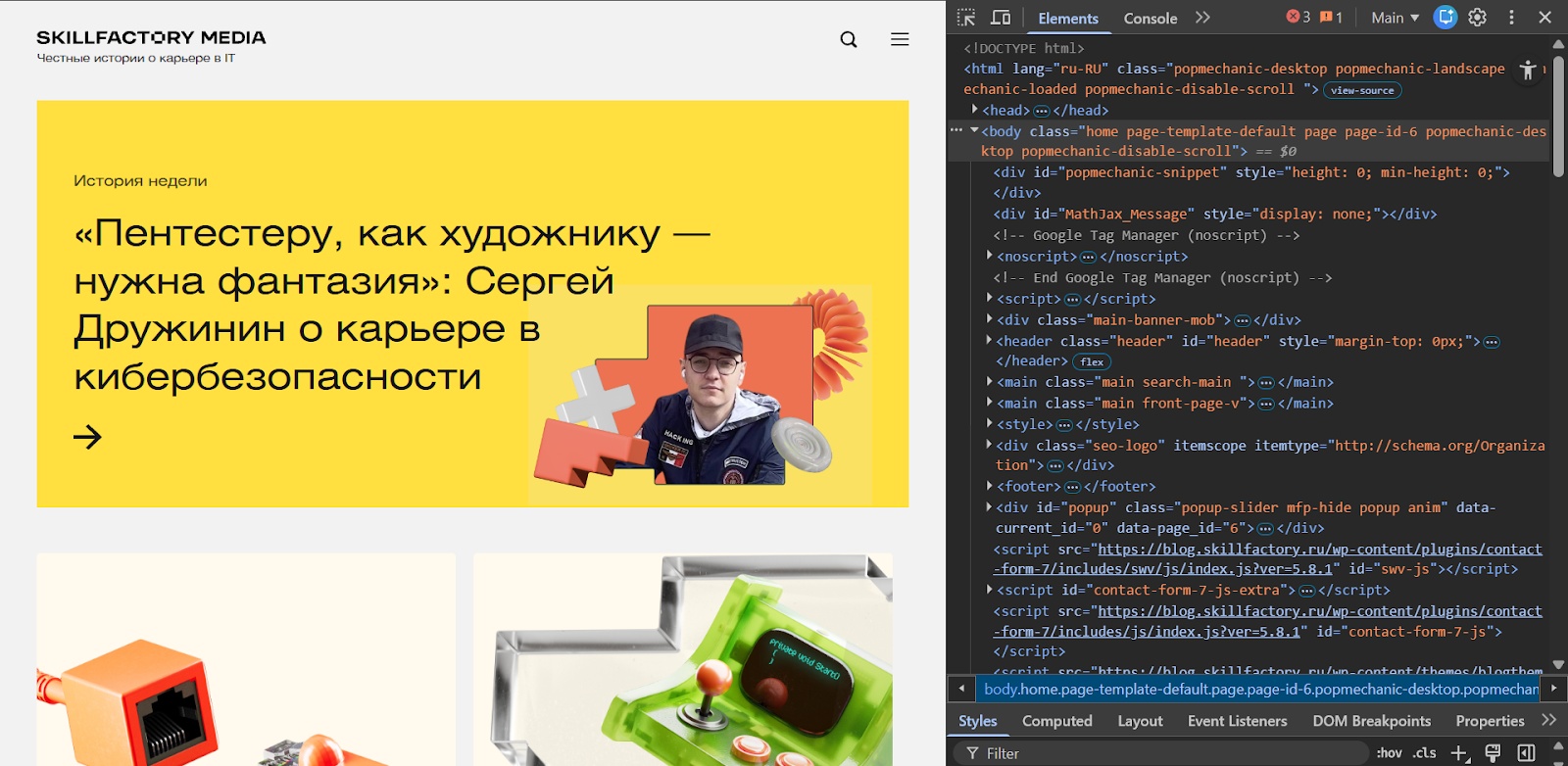
В DevTools можно не только видеть HTML-структуру, но и анализировать стили, изменять элементы в реальном времени, отслеживать загрузку скриптов и сетевые запросы. Например, вкладка Elements показывает текущую структуру DOM, а вкладка Network — какие файлы загружаются и сколько времени это занимает.
Важно понимать разницу: «Просмотреть код страницы» показывает исходный HTML-документ, тогда как DevTools отображает уже измененную версию страницы — с учетом работы JavaScript. Поэтому в инструментах разработчика часто можно увидеть больше информации, чем в исходном HTML-файле.

Что можно увидеть в исходном коде и как это анализировать
Исходный код позволяет увидеть, как страница устроена «изнутри» — без визуальной оболочки.
В первую очередь — структуру страницы. В HTML можно найти заголовки (<h1>–<h6>), абзацы (<p>), списки, ссылки (<a>), изображения (<img>), кнопки и формы. Это помогает понять логику построения материала: какой заголовок главный, как выстроена иерархия блоков, корректно ли размечен текст.
Далее — метатеги, которые размещаются в разделе <head>. Здесь можно увидеть:
- <title> — заголовок страницы во вкладке браузера;
- <meta name=»description»> — описание для поисковых систем;
- canonical — указание на основную версию страницы;
- Open Graph — данные для отображения ссылки в соцсетях.
Это особенно важно для SEO и контент-анализа.
В коде также видны подключенные стили и скрипты. По ссылкам на CSS- и JS-файлы можно понять, какие библиотеки или фреймворки используются. Иногда по названиям файлов можно определить CMS или конструктор сайта.
Отдельный блок — аналитические и сторонние сервисы. В коде часто присутствуют скрипты систем веб-аналитики, рекламные пиксели, виджеты чатов, карты и другие внешние инструменты. Их можно найти через поиск по странице (Ctrl + F), введя, например, часть названия сервиса.
Важно учитывать, что не весь контент обязательно присутствует в исходном HTML. Если страница активно использует JavaScript, часть данных может подгружаться динамически — в этом случае удобнее анализировать ее через инструменты разработчика.
Чего в коде нет
Несмотря на то что исходный код открыт для просмотра, он не содержит всего, что связано с работой сайта.
Во-первых, в нем нет паролей, баз данных и внутренней бизнес-логики. Браузер получает только ту часть информации, которая необходима для отображения страницы. Данные пользователей, механизмы авторизации, алгоритмы обработки заказов или рекомендаций работают на сервере и остаются недоступными извне.
Во-вторых, в коде нельзя увидеть серверные скрипты. Например, если сайт написан на PHP, Python или другом серверном языке, браузер получает уже результат их выполнения — готовый HTML. Сам исходный серверный код остается на стороне хостинга и не передается пользователю.
В-третьих, в исходном коде нет «секретных алгоритмов» в полном виде. Даже если на странице используется сложная логика на JavaScript, это только клиентская часть. Ключевые вычисления и механизмы защиты обычно реализуются на сервере.
Иногда можно встретить комментарии разработчиков или технические подсказки, но это не уязвимость, а скорее следствие невнимательности. В целом просмотр кода — это доступ к публичной части сайта, а не к его внутренней инфраструктуре.
Главное о работе с исходным кодом сайта
Исходный код страницы — это техническая основа любого сайта, доступная каждому пользователю. Его просмотр не требует специальных прав и не нарушает никаких правил: браузер в любом случае загружает эти данные, чтобы отобразить страницу.
Код позволяет увидеть структуру контента, метатеги, подключенные стили и скрипты, аналитические сервисы и используемые технологии. При этом он показывает только клиентскую часть — то, что необходимо для работы интерфейса. Серверная логика, базы данных и внутренние алгоритмы остаются за пределами видимой части.
