

Искусственный интеллект умеет создавать завязки историй, логичные цепочки событий и диалоги. Правда, произведения часто получаются сюрреалистичными: медсестры пекут пироги из пациентов, а женские персонажи жалуются на отросшие усы. В статье разберемся, понимают ли машины смысл созданных историй и стоит ли сценаристам переживать, что они останутся без работы. Бонус в конце: мы попытались сгенерировать сценарий с помощью ИИ. Посмотрите, что получилось.
Первые тексты нейросетей
Создание текстов с помощью искусственного интеллекта относится к направлению Natural Language Processing (NLP), которое занимается обработкой естественного языка. Это одна из областей машинного обучения, и кроме генерации текстов в него входит распознавание и синтез речи, которые используются в голосовых помощниках, машинный перевод и анализ текстов.

Первые языковые генераторы, которые составляли новостные заметки на основе данных, появились в 2014 году. Агентство Associated Press начало публиковать корпоративные отчеты о доходах, полностью написанные компьютерными программами, а Yahoo Sports выпускали автоматизированную аналитику футбольных матчей. Тексты генерировались с помощью ПО, разработанного стартапом Automated Insights, но это были сухие справки, без намека на художественность.
В 2015 году ученые Технологического университета Джорджии презентовали нейросеть Scheherazade-IF (interactive fiction), которая могла генерировать собственные рассказы на основе загруженных в нее текстов. В качестве эксперимента искусственному интеллекту предложили проанализировать около 200 историй об ограблениях и походах в кино, а затем составить собственную историю на эту тему.
Нейросеть выявляла в предложенных примерах повторяющиеся ключевые события, отмечала их, как важные для истории, и запоминала. Например, при ограблении это были угрозы, страх, наличие оружия, а при походе в кино — покупка билетов и попкорна. Также Scheherazade-IF анализировала последовательность и взаимосвязь событий (сначала нужно купить билет, а потом зайти в кинозал), поэтому ее собственные истории получались логичными.
Проблемой оставалось то, что ИИ не может использовать средства художественной выразительности, например метафоры или сравнения. Кроме того, Scheherazade-IF не понимала смысла составляемых предложений. Кстати, эта задача остается нерешенной до сих пор.
Как компании начали запускать собственные нейросети?
В конце 2015 года Илон Маск и Сэм Альтман запустили проект OpenAI — коммерческую платформу, которая занимается разработками в сфере искусственного интеллекта. Главным принципом компании стала открытость, так как создатели не хотели допустить, чтобы AI-разработки были сосредоточены в руках конкретной страны или правительства. Одним из проектов компании стала нейросеть GPT, которая училась генерировать тексты, предугадывая каждое слово.
На основе разработок OpenAI в 2018 году компания Google запустила нейронную сеть Bidirectional Encoder Representations from Transformers (BERT), которая сначала проходит этап pre-training — это долгий процесс тренировки на огромном количестве текстов, содержащих миллиарды слов. Кроме словарных значений, в pre-training входит работа с синтаксисом и контекстом предложений.

Когда нейросеть получает базовые навыки распознавания языка, то ее можно быстро дообучить под разные задачи, одной из которых как раз является языковое моделирование. Для решения задачи нейросеть изучает миллиарды слов и их расположение в грамматически правильных предложениях, после чего может предсказывать следующее слово в тексте самостоятельно.
В 2018 году OpenAI выпустила версию GPT-2 (а в 2019 году — GPT-3), которая сейчас является самой большой нейросетью для работы с естественными языками. Она имеет более 1,5 млрд параметров, с помощью которых обрабатываются входные данные, и способна создавать целые страницы связного текста, причем для этого ей требуется всего один этап обучения, в отличие от BERT.
Как искусственный интеллект генерирует текст?
Олег Седухин, специалист по NLP, рассказал, как работает такая нейросеть:
«На самом деле система по архитектуре не такая сложная, как может показаться, просто она обучается на огромном объеме данных. В среднем для обучения используют около 600 Гб текстов.
Сейчас используется разновидность нейронных сетей, называемых трансформерами. Каждое слово в тексте трансформер представляет как набор чисел. Затем эти наборы чисел определенным образом обмениваются информацией друг с другом несколько десятков раз. Полученные с помощью этих вычислений результаты нейросеть может использовать для разных задач, в том числе генерации текстов на разные темы.
Входными данными при этом является “затравка” — начало текста, которое нужно продолжить, например: “Каков ответ на главный вопрос жизни, Вселенной и всего такого?” Сеть попытается продолжить этот текст и дать ответ. При этом она не высказывает собственное мнение, просто воспринимает затравку как начало какого-то текста, уже написанного человеком, и пытается предугадать, что будет дальше».
Механизм предугадывания слов в предложении можно увидеть при наборе письма в Яндекс.Почте. Сервис обучается в ходе использования и предлагает варианты автозаполнения в реальном времени на основе паттернов, которые чаще всего использует владелец аккаунта:
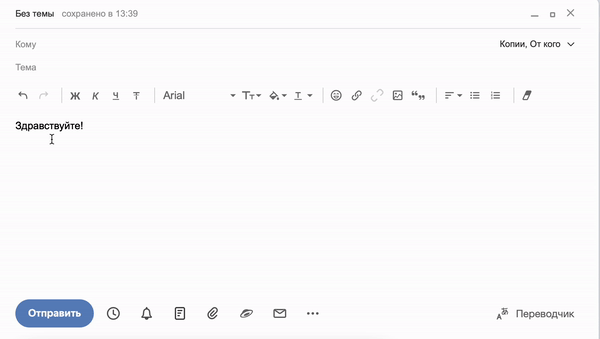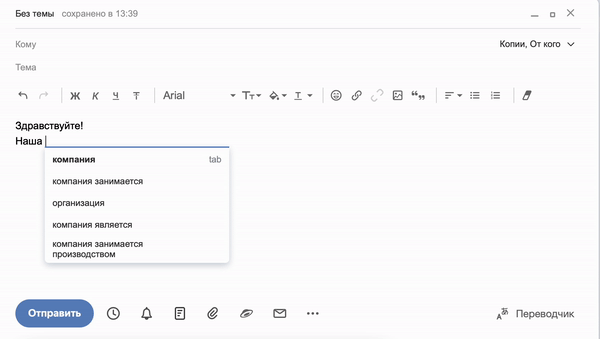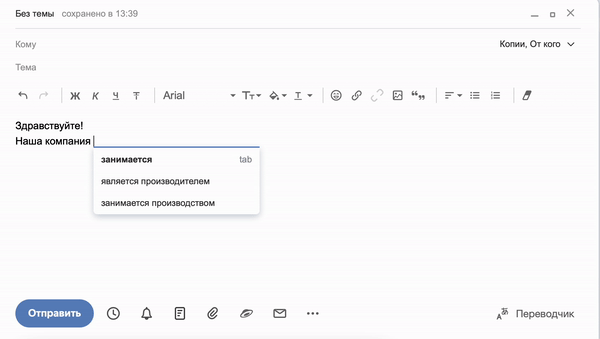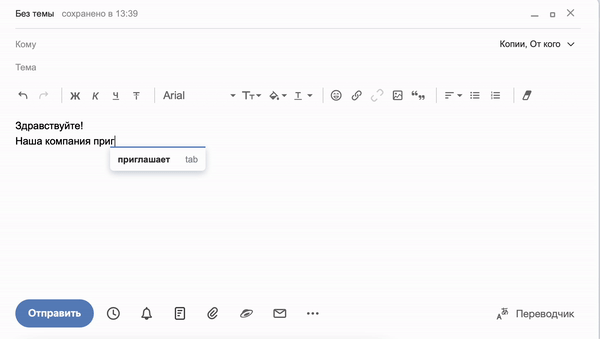
Точно также работает генерация слов в сервисе «Балабоба», только в гораздо большем масштабе. Команда Яндекса создала собственную языковую модель YaLM (Yet another Language Model), вдохновляясь примером GPT-3 от компании OpenAI. Она обучается на множестве страниц рунета, включая Википедию, новости, книги и открытые записи пользователей в соцсетях. Единственная задача сервиса — предсказывать каждое следующее слово таким образом, чтобы получалось логичное и грамматически правильное предложение.
«Балабоба» тоже умеет составлять сценарии, но в небольшом объеме. Например, она в собственном стиле смогла продолжить начало оригинального сценария фильма «Криминальное чтиво»:

Если сравнить результат с оригинальным диалогом, который происходит между персонажами, то можно заметить, что в целом нейросети удалось уловить суть тарантиновских диалогов:

И в том и в другом варианте непредсказуемые и абсолютно несвязные на первый взгляд высказывания складываются в абсурдный, но увлекательный диалог. Именно эту особенность искусственного интеллекта чаще всего используют при создании сценариев для короткометражек.
Фильмы, снятые по сценариям ИИ
Benjamin
Режиссер Оскар Шарп и разработчик из Google Гудвин Росс создали нейросеть по имени Benjamin. Она относится к типу искусственного интеллекта, который используется для распознавания текста. Чтобы обучить Benjamin, Росс Гудвин загрузил в него десятки научно-фантастических сценариев из интернета: в основном это были фильмы 1980-х и 1990-х годов.
Первый фильм, снятый по сценарию Benjamin, — это «Sunspring», научно-фантастическая короткометражка для фестиваля Sci-Fi London 2016 года:

В сценарии были бессвязные диалоги: например, главная героиня жаловалась, что у нее отрастают усы. Но некоторое время спустя Benjamin научился создавать более логичные истории и сам стал генерировать фильмы. Нейросеть выбирала актеров, сюжет и спецэффекты. На фестиваль Sci-Fi London 2018 года Шарп и Росс представили черно-белую короткометражку «Zone Out», которую полностью создал искусственный интеллект:
GPT-3
На YouTube-канале Calamity AI студенты Университета Чапмана Джейкоб Ваус и Эли Вайсс выложили несколько короткометражек, сценарии к которым написаны с помощью ИИ. Например, «Solicitors» — история о девушке, которая встретила на пороге дома свидетеля Иеговы с необычной историей:

Или «Date Night» — короткометражка о странном свидании парня и девушки, которые обсуждают, реальны ли они или находятся внутри фильма:

Авторы использовали Shortly Read, программное обеспечение на основе GPT-3. Джейкоб Ваус сочинял короткие истории или придумывал безумные завязки, а остальное дописывала нейросеть. Автору оставалось наблюдать, как будет развиваться эта история.
Сценарист и комик Китон Пэтти сгенерировал с помощью искусственного интеллекта сценарий эпизода «Черного зеркала». Нейросети пришлось посмотреть 1 тыс. часов сериала, чтобы сгенерировать результат:

Заменит ли искусственный интеллект сценаристов?
Блейк Снайдер в своей книге о сценарном мастерстве «Спасите котика» советует авторам задавать при написании сценария правильные вопросы: «Когда начинается каждая новая сцена, вы должны знать, в чем заключается ее конфликт и кто выступает противоборствующими сторонами. У каждого персонажа есть собственные задачи. В чем они заключаются? Как они могут вступать в противоречие с интересами других персонажей?»
Кроме интересного сюжета и диалогов, в хорошей истории есть конфликт, характеры, эмоциональный багаж и развитие персонажей. Искусственный интеллект пока не способен анализировать такие категории и вряд ли вообще когда-нибудь сможет. Чтобы создать сложного персонажа, необходимо понимать смысл создаваемого текста, но со времен Scheherazade-IF нейросети так и не научились это делать.
Олег Седухин, специалист по NLP
«Это открытая, еще не решенная проблема в машинном обучении, и на текущем этапе развития технологий понимание нейросетями текста все еще очень поверхностно. В основном нейросети создают лишь видимость понимания, запоминая, какие слова чаще всего встречались в каком контексте. Поэтому машинный ответ совпадает с тем, чего хочет от нейросети человек. Эта видимость рушится, когда современным нейросетям задают каверзные вопросы, потому что с таким они пока плохо справляются.
Сам вопрос “Понимает машина смыслы или не понимает?” — философский и очень сложный. Есть гипотеза, что на основе одних текстов не получится добиться понимания, нужно дополнять их контекстом — например, для обучения загружать еще и видео. Этот вопрос — передний край науки, и над ним работает уже нынешнее поколение разработчиков».
С этим согласен Владлен Максимов, сценарист проектов «Такая работа», «Пятая стража», «Женская версия»
«Помните киновселенную Marvel, вышедшую из комиксов, где сценарии созданы по определенным алгоритмам? Потом появился фильм “Джокер”, похожий на Marvel, но в сценарии все алгоритмы были сломаны, потому что зло сражается со злом, и это все равно притягивает зрителей. Никакой искусственный интеллект не справится с рождением сложных эмоциональных сценариев».
Как создать собственный сценарий с помощью ИИ?
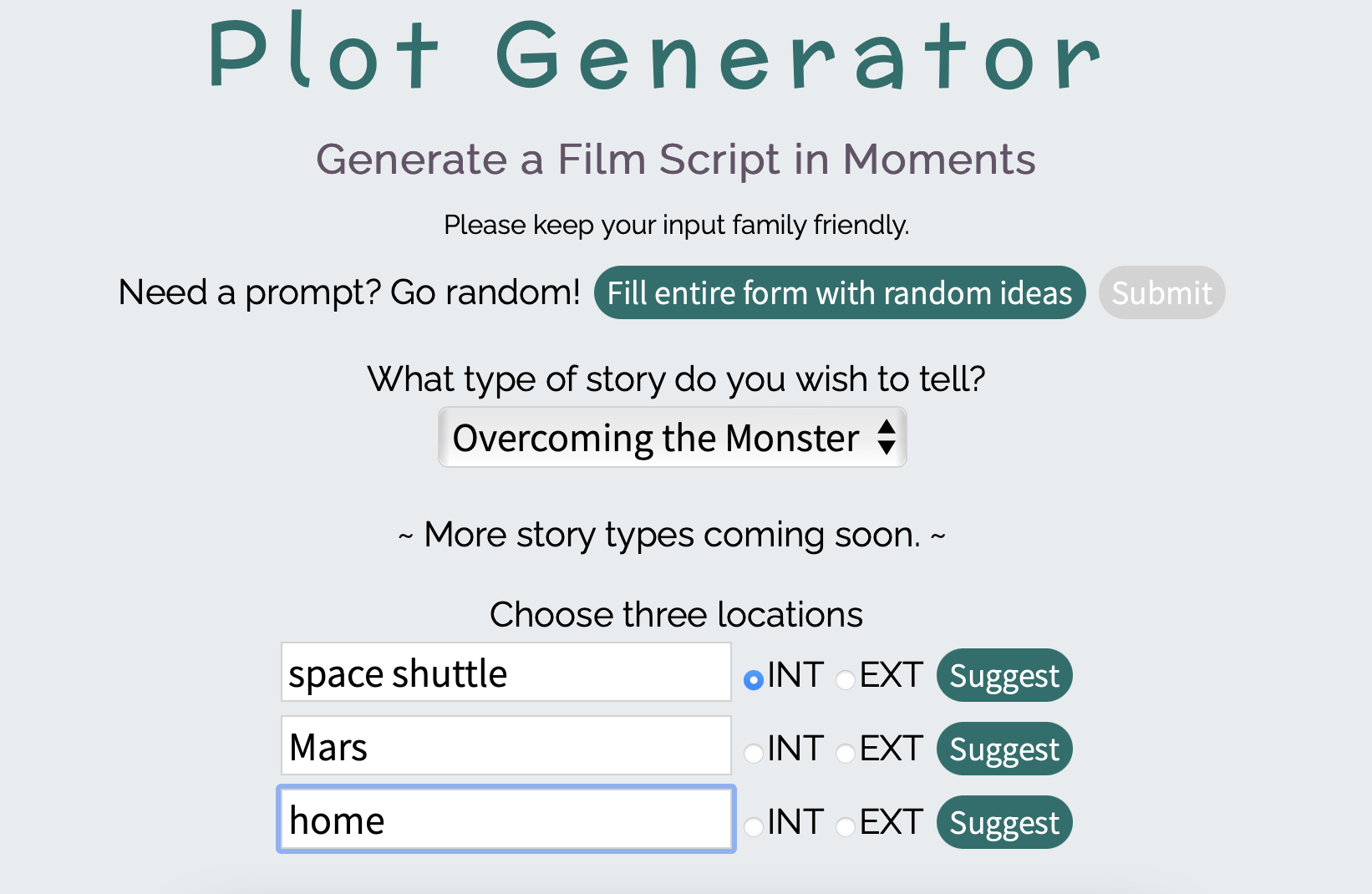
Придумать и сгенерировать свою историю можно с помощью сервиса Plot Generator. Он предлагает выбрать три локации для истории — пусть это будет дом, Марс и космический шаттл:
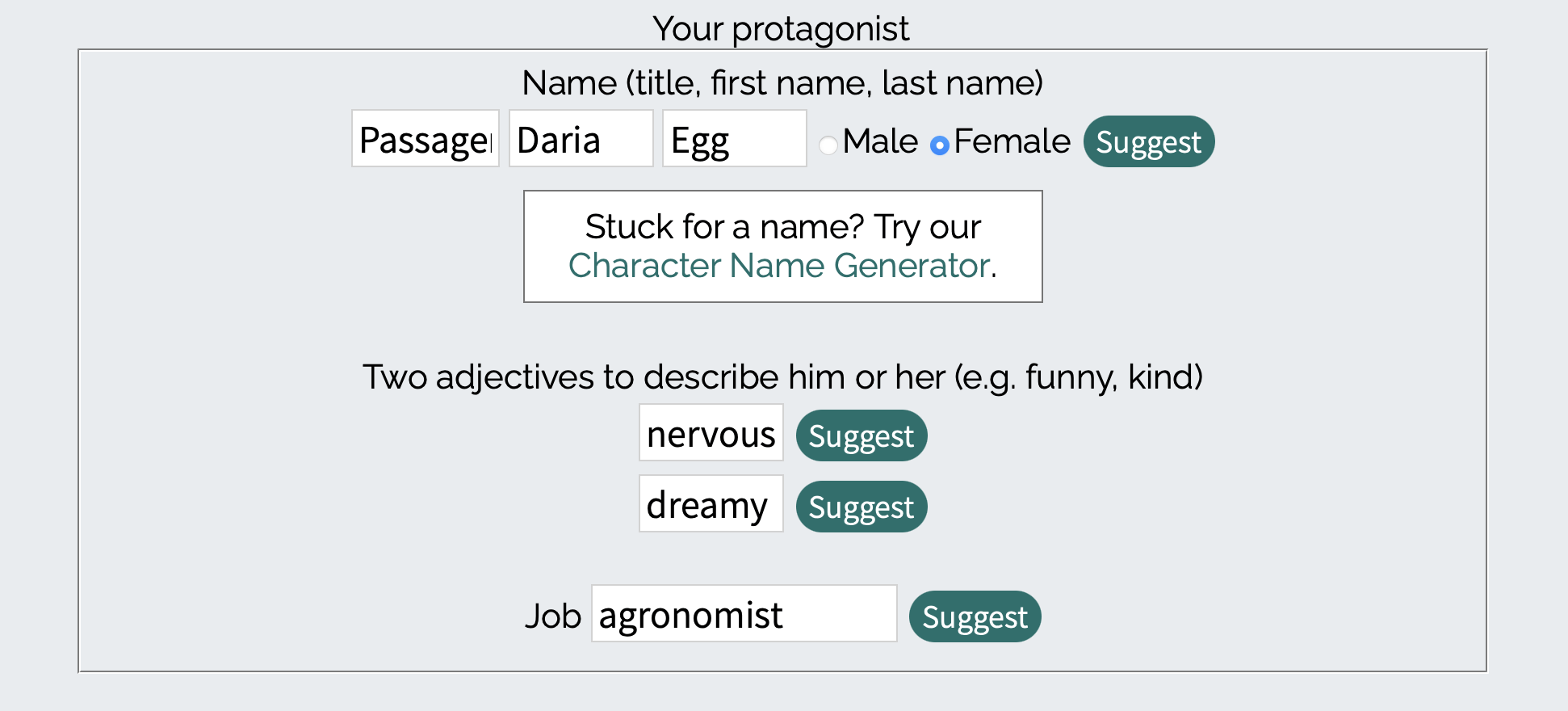
Дальше нужно придумать имя главного героя, указать два прилагательных, которые характеризуют его, и профессию. Эта история будет о пассажире шаттла по имени Daria Egg, которая очень нервная, мечтательная и работает агрономом:
По такой же форме можно придумать главному герою друга, врага или любовный интерес:

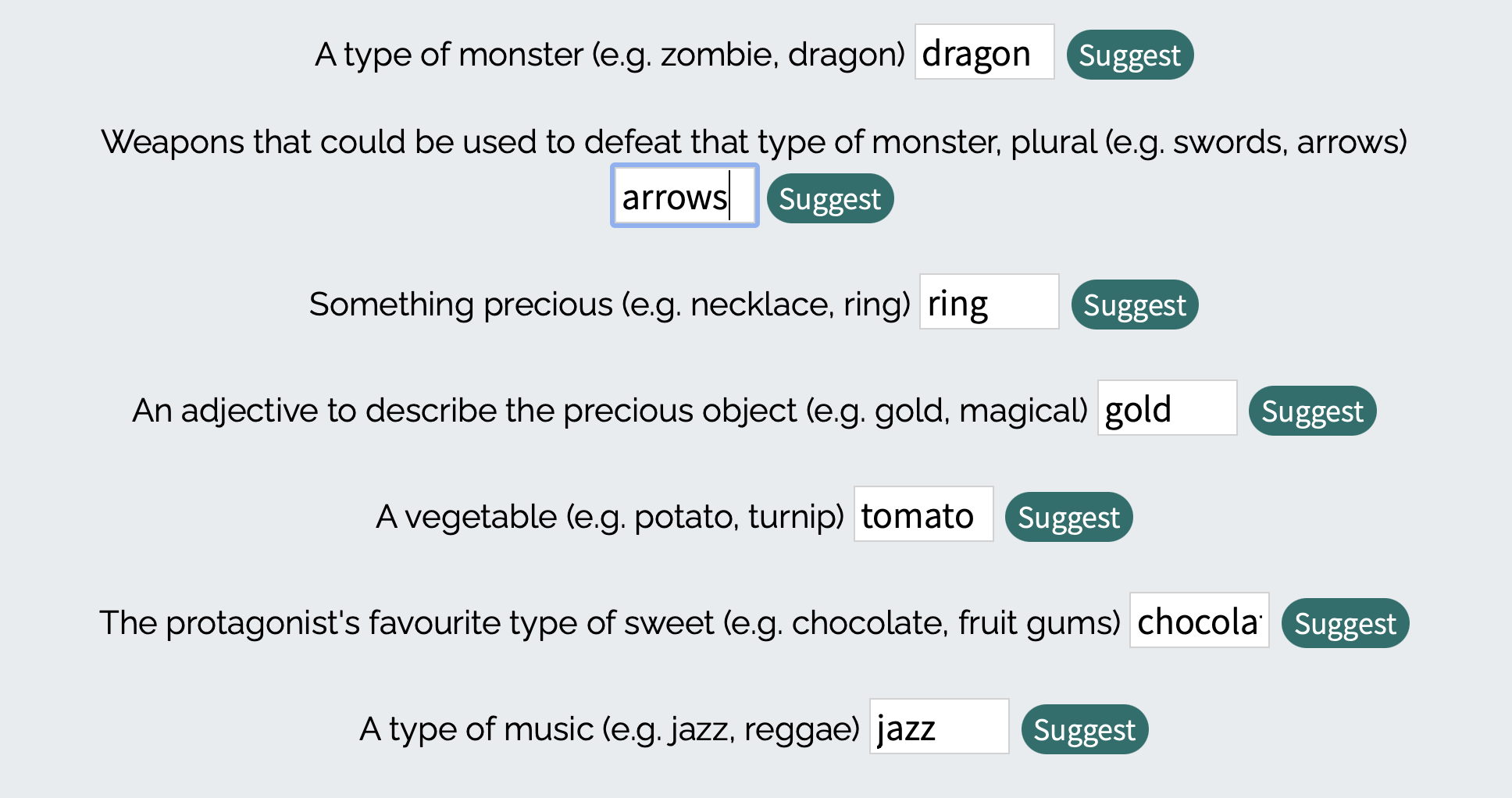
В детали можно добавить монстров, драгоценности, любимые сладости героев, любимую музыку и страшную тайну:
По этому скрипту генератор предлагает нам сценарий фильма «Calm Dragon», то есть «Спокойный дракон». Действие начинается на борту космического шаттла, на котором спорят Дарья и ее любовный интерес — второй пассажир Джон:

Перевод:
ДАРЬЯ
Пожалуйста, Джон, не оставляй меня.
ДЖОН
Прости, Дарья, но я ищу кого-нибудь посмелее. Кто-то, кто сталкивается со своими страхами лицом к лицу, а не убегает.
ДАРЬЯ
Я такой человек!
ДЖОН хмурится.
Выглядит как вполне приличный диалог для мелодрамы, но дальше врывается подруга Дарьи Анна и рассказывает, что она видела, как на Марсе дракон съел кучу детей:

Чтобы создать текстовую нейросеть с нуля нужны те же знания, что требуются для создания других нейросетей. Во-первых, нужно знать математику:
- линейную алгебру: матрицы, векторы, их свойства и операции с ними
- математический анализ: производные, поиск экстремумов функции, функции многих переменных
- теория вероятности и статистика: случайные величины, распределения и т.д.
При отсутствии профильного высшего образования могут возникнуть сложности. Большинство из теорем и доказательств, которые изучаются в университете, не пригодятся на практике, но университет формирует математическую интуицию, которая очень важна. Важно не просто помнить формулы, а понимать почему они именно такие.
Конечно, нужно иметь знания в области программирования. В первую очередь это:
- Python – язык программирования, который особенно популярен в направлении машинного обучения и работы с большими данными.
- NumPy – библиотек на Python, которую применяют для математических вычислений.
Также понадобится базовое понимание истории и устройства ИИ. Есть книга «Deep Learning», в которой излагается теория, достаточная (и даже чуть больше чем достаточная), чтобы заниматься машинным обучением.
На курсе по машинном обучению и нейронным сетям в SkillFactory вы разберетесь с алгоритмами и узнаете необходимые библиотеки. Фокус курса – понимание задач и практическое применение решений.
