

Популярный способ организации клиент-серверного взаимодействия — REST API. Но у инструмента есть альтернативы. Одна из них — GraphQL. Разберемся в неочевидных преимуществах, посмотрим на недостатки, развенчаем несколько мифов и попытаемся ответить на основной вопрос — стоит ли переходить на GraphQL.
Немного теории
В интернете много детальных обзоров и сравнений. Попробую не повторяться, но подчеркну основные отличия на примере сравнения с REST.
GraphQL — язык, в отличие от REST. С его помощью разработчик описывает взаимодействие клиента и сервера.
В отличие от REST, в GraphQL всего одна точка взаимодействия (endpoint) с бэкендом. Т. е. неважно, что вы хотите запросить или изменить: клиент будет взаимодействовать с одной конечной точкой, одним URL.
Основная часть GraphQL — схема (schema), которая описывает все типы, запросы и их взаимодействие, которые вы можете использовать в рамках текущего endpoint. Схема — не удобное дополнение, как, например, Swagger, а обязательная начальная точка проектирования любого GraphQL API.

Есть два типа операций: запросы (query) и мутации (mutation). Первые отвечают за получение данных, вторые — за их изменение. Еще есть подписки (subscriptions), но в этой статье мы не будем их рассматривать.
Доступны базовые типы:
- ID: уникальный идентификатор объекта, реализован как String;
- String: строки, например, имя пользователя;
- Boolean: булевое значение (true / false);
- Int: целочисленное (1, 2, 3, …);
- Float: число с плавающей точкой (1.5);
- Enum: перечисления.
Также можно описать собственные типы на основе базовых, пометить значения как обязательные или нет (знак «!» после указания типа), а также указать, что ожидается список, а не единичное значение (помечается скобками «[]», как в примере ниже).
Рассмотрим пример схемы:
type Query {
user(id: ID!): User
users: [User]
}
type Mutation {
updateUser(id: ID!, name: String, age: Int): User
}
type User {
id: ID!
name: String!
age: Int!
}Здесь говорится, что существует запрос (query) user, который принимает id типа ID и возвращает объект типа User, состоящий из трех полей: id типа ID, name типа String и age типа Int.
Запрос users вернет список всех User.
А мутация updateUser обновляет поля существующего пользователя по его id.
Клиент может запросить данные, например, по пользователю с ID 42, следующим запросом на языке GraphQL:
query {
user(id: 42) {
id
name
}
}В запросе мы не указали age, а следовательно, эти данные не будут возвращены на клиент, т.е. если они нам не нужны, мы сохраним немного байт и времени на пересылке данных между клиентом и сервером.
Базовый пример работы
Я подготовил тестовое приложение, которое можно скачать и собрать из исходников: https://github.com/NevRA/skillfactory-graphql.
Приложение состоит из демо-сервера, песочницы и нескольких примеров на React, которые мы рассмотрим далее.
Запустите в корне проекта npm install && npm start и откройте песочницу по адресу http://localhost:4000/.
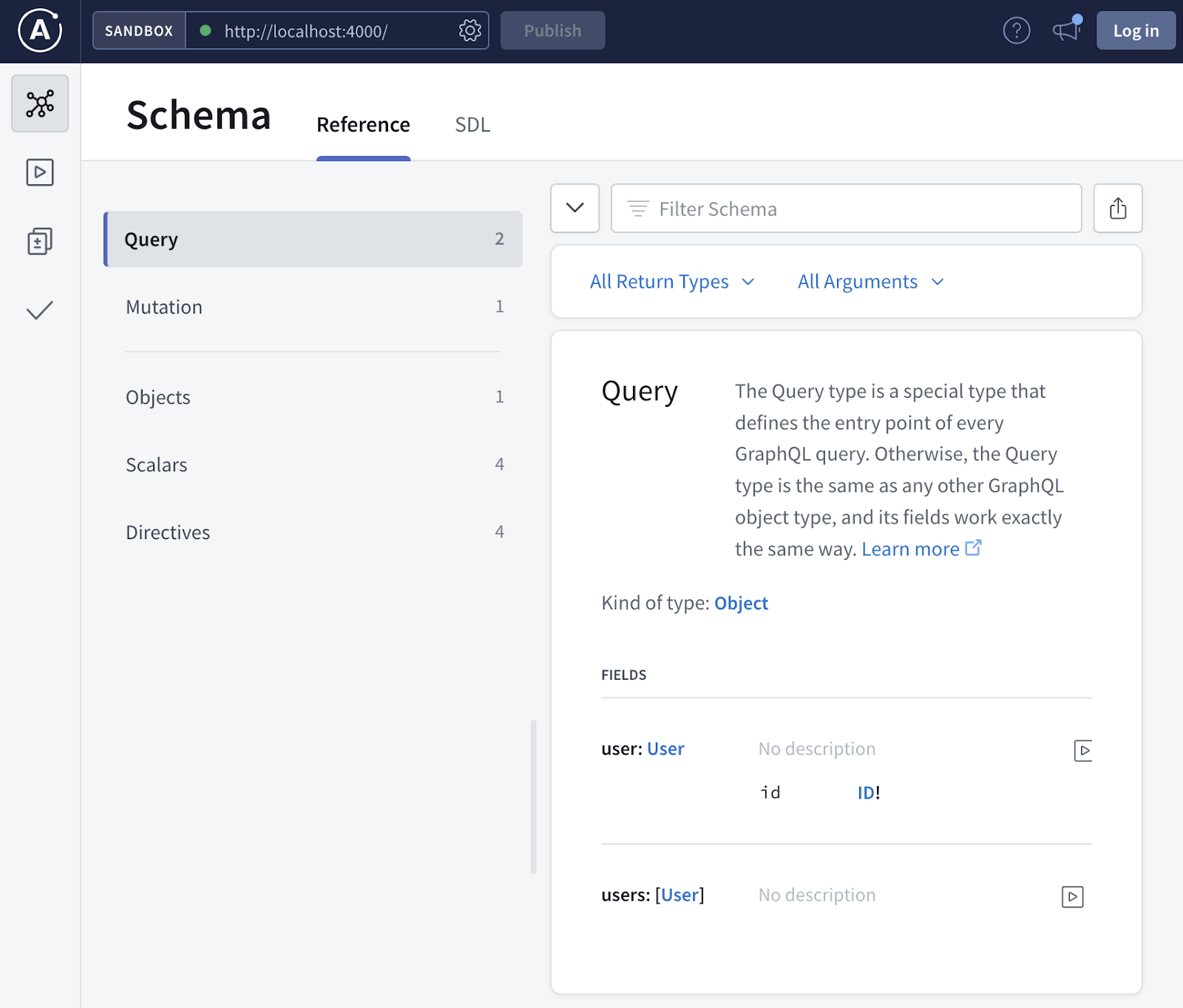
Вы сможете посмотреть описание схемы (по факту — документация нашего API):
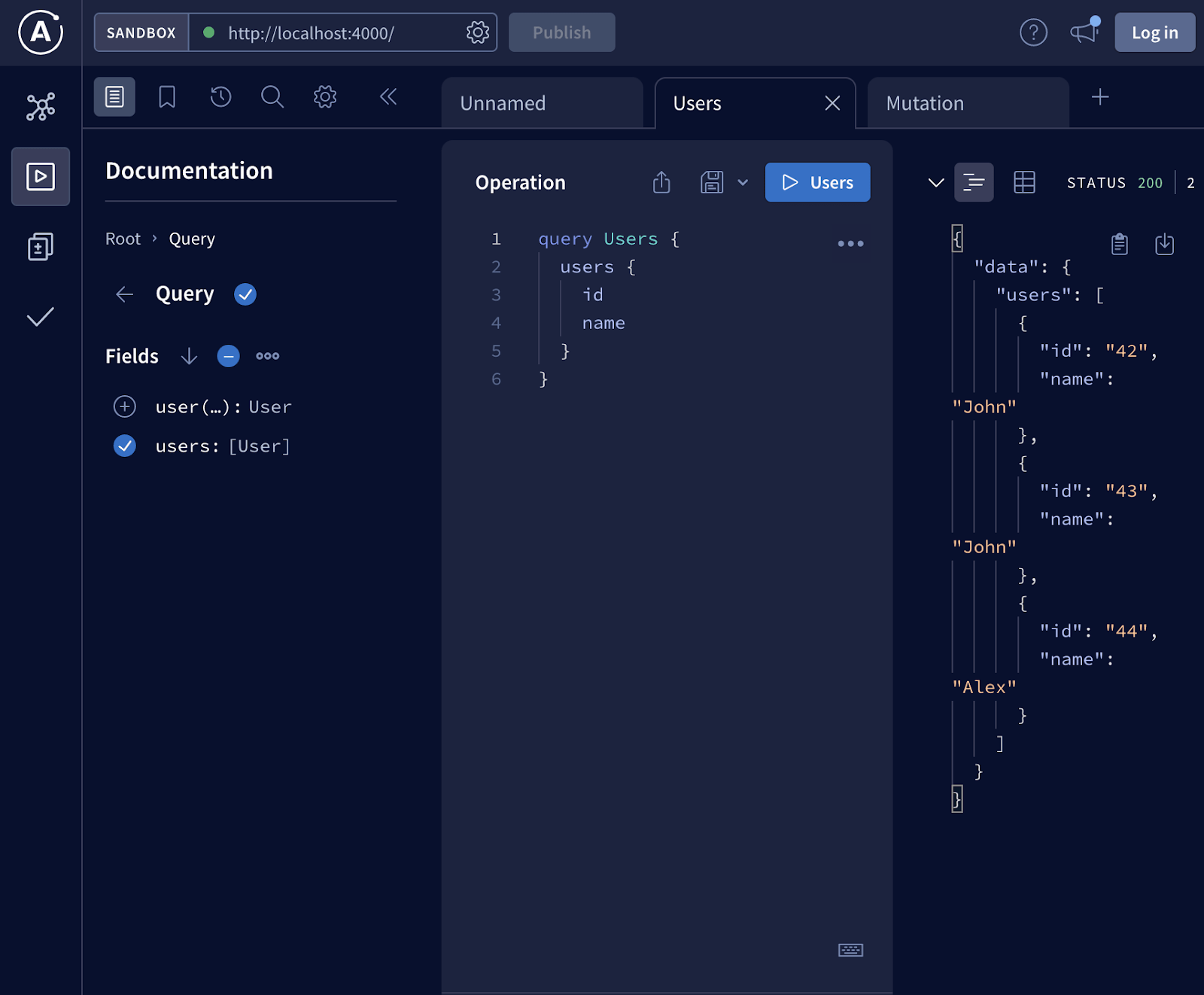
Важно поэкспериментировать с самими запросами, например, получить всех пользователей, доступных в системе:
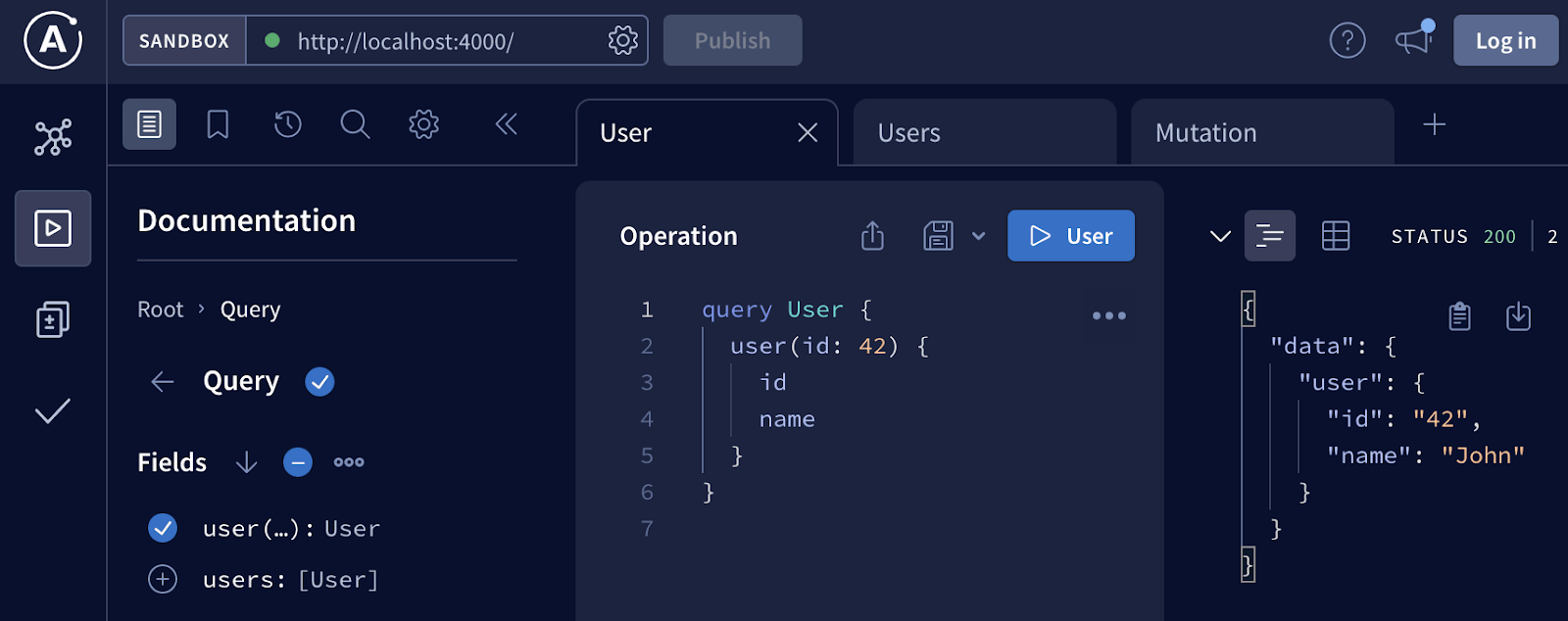
Или конкретного:
Или обновить пользовательские данные:
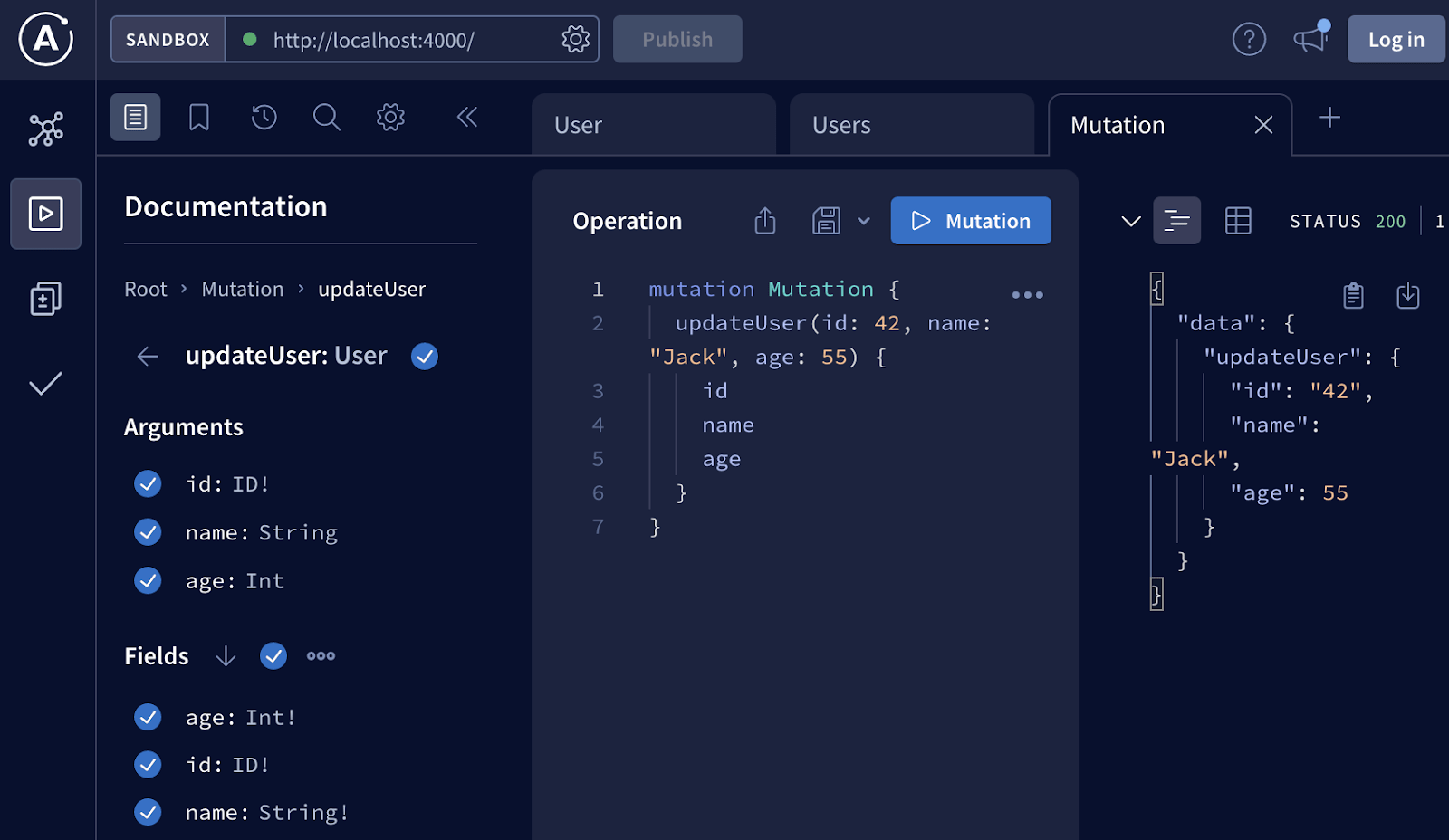
Важный вывод, который мы должны сделать в роли фронтенд-разработчика — это то, что мы не написали ни строчки кода, а уже смогли поработать с бэкендом, увидеть доступные запросы, их параметры, выполнить их, проанализировать ответы и т. п.
На языке GraphQL мы описали контракт, а так как все типы известны заранее, то неважно, кто именно взаимодействует с бэкендом (наш клиент на react/vue/angular/…, песочница, другой бэкенд или любое другое приложение). Важно, чтобы клиент понимал язык. С GraphQL endpoint мы можем отлаживать API и экспериментировать с запросами при наличии любого клиента, понимающего GraphQL.
Песочница из примера выше делает специальный запрос на бэкенд для получения схемы. На ее основании она сгенерировала все доступные пользователю методы и типы. Обычно схема открыта для чтения, но при желании авторы сервиса могут отключить эту возможность.

Генерация данных в приложении
Реализуем это же в React-приложении. Будем использовать TypeScript и библиотеку Apollo Client — продвинутое решение для работы с GraphQL и управления состоянием.
Пример можно посмотреть в папке examples/1-SimpleReact. В нем мы хотим загрузить список всех пользователей. Для этого используем информацию о схеме и сгенерируем необходимые данные и методы.
В файле codegen.yml указываем endpoint (schema). Т. е. мы подсказываем генератору, откуда брать схему (наш сервер, который мы запустили в предыдущем разделе):
overwrite: true
generates:
src/generated/graphql.d.ts:
documents: './src/**/*.graphql'
schema:
- http://localhost:4000
plugins:
- typescript
- typescript-operations
- typescript-react-apolloСоздаем файл users.graphql с нашим запросом, который мы использовали в песочнице:
query Users {
users {
id
age
name
}
}После того как мы запустим npm run compile, будут сгенерированы не только все нужные типы, но и хуки (React Hooks) для нашего приложения. Поэтому весь код приложения может выглядеть лаконично:
import { useUsersQuery } from "./generated/graphql.d";
const App = () => {
const { data } = useUsersQuery();
return (
<div className="App">
{data &&
data.users?.map((user) => (
<div className="card" key={user?.id}>
<div className="user-id">{user?.id}</div>
<div className="user-name">{user?.name} {`${user?.age} y/o`}</div>
</div>
))}
</div>
);
};Где useUsersQuery — это хук, который был для нас сгенерирован, а data содержит информацию о пользователях, причем типизированную (мы сгенерировали все типы в TypeScript).
Мы получили:
- Очень простой код с нужными типами при минимуме ручной работы. Описываем, что нужно, подключаем хук, обрабатываем данные.
- Если часть по генерации типов будет частью CI/CD-процесса, то у нас будут те же типы, что и на бэкенде. Если на бэкенде что-то поменяется, например, кто-то переименует поле name, мы узнаем об этом не на продакшене, а при билде, т. к. типы не совпадут, и мы получим ошибку TS.
Миф №1: Загружаем только нужные данные
Когда говорят про преимущества GraphQL, один из основных аргументов — загрузка только запрашиваемых данных без изменения бэкенда. Т. е. на примере выше мы могли не загружать, например, age.
Это больше миф, т. к. функционал легко реализуется и с REST, например, так: /users/42?fields=name,age. Подобный подход используют разные компании, в том числе Facebook*. Т. е. иногда это удобно, но не является killer feature GraphQL.
Управление состоянием в приложении
Killer feature здесь может быть работа с состоянием. Я подготовил пример: examples/2-StateReact. В нем за счет мутации updateUser попробуем изменить состояние пользователя и посмотреть, что произойдет со списком, загруженным ранее.
Для этого обновим предыдущее приложение, добавим новую мутацию updateUser.graphql и обновим основной компонент:
import { useState } from "react";
import { useUsersQuery, useUpdateUserMutation } from "./generated/graphql.d";
const App = () => {
const [id, setId] = useState("");
const [name, setName] = useState("");
const [age, setAge] = useState(0);
const { data } = useUsersQuery();
const [updateUser] = useUpdateUserMutation();
const handleUpdate = () => {
updateUser({
variables: {
id,
name,
age,
},
});
};
return (
<div className="App">
<div className="container">
{data &&
data.users?.map((user) => (
<div className="card" key={user?.id}>
<div className="user-id">{user?.id}</div>
<div className="user-name">
{user?.name} {`${user?.age} y/o`}
</div>
</div>
))}
</div>
<div className="card-edit">
<input onChange={(e) => setId(e.target.value)} />
<input onChange={(e) => setName(e.target.value)} />
<input type="number" onChange={(e) => setAge(Number(e.target.value))} />
<button onClick={handleUpdate}>update</button>
</div>
</div>
);
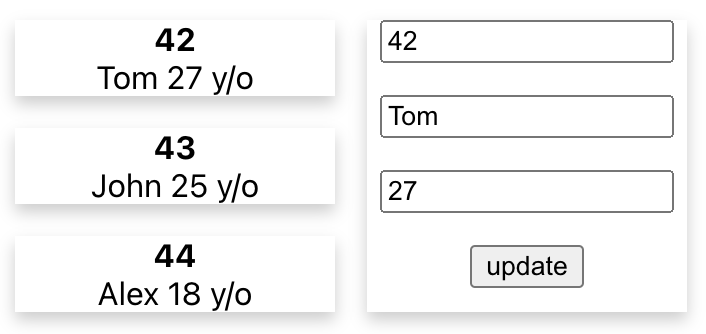
};У нас появился новый хук, который обновляет заданного пользователя. Все вместе это выглядит вот так:
Список слева загружен хуком из предыдущего примера. Что произойдет, когда мы нажмем кнопку update и попытаемся обновить пользователя с ID 42?
Получим обновленное состояние:
Все дело в том, что у Apollo есть нормализованный кэш данных. Так как GraphQL передает дополнительную информацию о типе объекта, Apollo может связать ответ мутации (возвращаем обновленного пользователя и его ID) и самостоятельно обновить кэш.
Это очень мощная фича, которая при использовании GraphQL может заменить state management в вашем приложении. Почитать о том, как устроен кэш, можно здесь. Там же есть продвинутые техники использования.
Для отладки или чтобы посмотреть, как это устроено внутри, советую родное расширение для Google Chrome. Вот так хранится объект в кэше: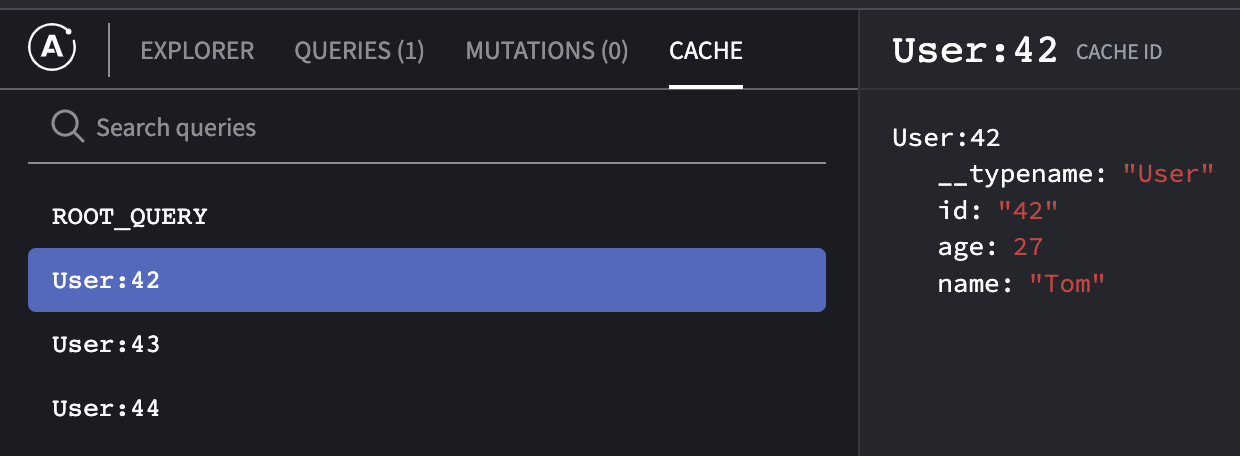
Миф №2: GraphQL — приемник REST, поэтому он во всем лучше
GraphQL — это не преемник REST, а одна из альтернатив, у которой есть свои недостатки.
- Реализация бэкенда может быть затратнее. Это зависит от специфики, но, например, GitHub рекомендует использовать REST для некоторых операций. Я часто слышал мнение, что GraphQL сложнее в оптимизации, т. к. один запрос может содержать любое число подзапросов и полей. Оптимизация всех комбинаций — головная боль.
- Некоторые операции, например, загрузку файлов или обработку ошибок реализовать сложнее.
- Правильная архитектура схемы — отдельная нетривиальная задача. В REST можно создавать новые типы под каждый запрос. В GraphQL, если многое завязано на кэше, это неэффективно.
Что дает GraphQL
Ускоряет разработку на фронтенде. Это связано с несколькими факторами, упомянутыми выше:
- Самодокументированный API. Вы всегда знаете, что доступно на бэкенде, и можете сгенерировать нужные типы и методы (например, хуки в случае React).
- Возможность работать с бэкендом из песочницы.
- Так как есть вся информация о типах и их взаимосвязях, легко организовать работу с состоянием (например, кэш в Apollo). В более сложных сценариях использования подписок это позволит получать изменения через WebSocket без дополнительных запросов. Будет проще реализовать, например, многопользовательскую работу, когда важно получать измененные данные в ответ на чью-то активность.
- Продвинутый инструментарий. Есть полезные техники работы с запросами. Например, повторный запрос (refetching) данных в ответ на мутацию, возможность переиспользовать части схемы (fragments), возможность написания кастомных модификаторов кэша, тонкие настройки политик-запросов и т. п.
- Можно реализовать SSR (Server Side Rendering) и вшивать данные на сервере, чтобы потом не запрашивать их при старте приложения. Полезно для оптимизации начальной загрузки.
Также GraphQL хорошо «ложится» на микросервсиную архитектуру или serverless. Потому что у вас уже распределенная система, и серверные resolvers просто направляют запросы к ответственным сервисам или функциям в случае serverless. Для монолитных систем это работает хуже.
Стоит ли переходить на GraphQL
Все зависит от конкретного кейса и даже от типа мышления. GraphQL не решит все ваши проблемы. Но это очень популярная технология с растущим комьюнити, развитым тулингом и бесконечным списком примеров успешного применения.
Чтобы попробовать, можно взять примеры из моего репозитория, реализовать более сложные кейсы.
*Принадлежит компании Meta, признанной в России экстремистской организацией.
