


Нейросеть — это компьютерная система, которая учится решать задачи, имитируя работу человеческого мозга. Она состоит из множества связанных нейронов, которые обрабатывают информацию и находят закономерности в данных. Как и любую систему, нейросеть можно запрограммировать, и в этой статье мы посмотрим, как это сделать.

В первом и втором разделах у нас будет теория, где мы разберемся, что необходимо для создания нейросети и как проходит ее процесс обучения. А в третьем разделе мы перейдем к практике и создадим простую модель, которая распознает рукописные цифры от 0 до 9.
Материал рассчитан на новичков, поэтому не переживайте, если до этого вы никогда не программировали и не знакомы с языком Python.
Как работает нейросеть и что нужно для ее создания
Основа нейросети — нейрон. Он получает входные сигналы (числа), обрабатывает их и передает результат дальше. Представьте нейрон как маленький калькулятор: он берет каждое входное значение, умножает его на коэффициент важности (вес), складывает все взвешенные результаты, добавляет смещение (bias) и через функцию активации определяет, насколько сильный сигнал нужно отправить дальше.
Когда нейроны соединяются в цепочку, они образуют слои. Входной слой принимает исходные данные, скрытые слои последовательно извлекают из них закономерности и признаки, а выходной слой формирует итоговый результат — предсказание или классификацию.
Например, при распознавании изображений входной слой получает пиксели, скрытые слои сначала выделяют простые элементы (линии, края), затем более сложные (формы, текстуры), а выходной слой определяет, что изображено на фото — кошка, собака или другой объект.

Для создания нейросети нужно несколько ключевых компонентов:
- данные для обучения — набор примеров с правильными ответами. Это могут быть картинки кошек и собак с подписями «кот» или «собака», фото цифр с метками от 0 до 9 и так далее;
- архитектура — то, как организованы слои и связи между ними. Так, сеть для распознавания цифр может состоять из входного слоя на 784 нейрона для изображения 28×28 пикселей, скрытых слоев и выходного слоя на 10 нейронов для цифр от 0 до 9;
- функция потерь — метрика, которая измеряет разницу между предсказанием нейросети и правильным ответом. Чем меньше значение функции потерь, тем точнее работает модель;
- оптимизатор — алгоритм, который корректирует веса нейронов в процессе обучения, чтобы постепенно уменьшать функцию потерь. Он определяет направление и величину изменения весов после каждой итерации. Вот примеры алгоритмов: SGD — стохастический градиентный спуск, Adam — адаптивная оценка моментов и RMSprop — среднеквадратичное распространение;
- эпохи — полные проходы по всему обучающему датасету. Одна эпоха означает, что нейросеть увидела все примеры из набора данных один раз. Обычно для обучения нужно несколько десятков или сотен эпох, чтобы модель скорректировала свои веса и научилась распознавать закономерности в данных.
Перечисленные компоненты — основа любой нейросети, от небольших моделей до современных систем искусственного интеллекта. Главное отличие между ними только в сложности выбранной архитектуры, объеме данных для обучения и требуемой вычислительной мощности.
Простые нейросети состоят из нескольких слоев и решают конкретные задачи — например, распознавание цифр. Большие модели вроде ChatGPT или Midjourney содержат миллиарды параметров и обрабатывают огромные объемы данных. Для их обучения требуются мощные вычислительные кластеры и целые команды инженеров.
Как проходит процесс обучения нейронной сети
Обучение нейросети похоже на обучение человека: она многократно повторяет задачу, анализирует свои ошибки и постепенно улучшает результат. Этот процесс состоит из нескольких этапов, каждый из которых повышает точность модели. Рассмотрим каждый из них.
Предсказание. Сначала сеть получает входные данные и делает прогноз. Затем полученный результат сравнивается с правильным ответом, чтобы вычислить ошибку. Например, сеть видит изображение цифры «3», но предсказывает «8». Разница между предсказанием и правильным ответом — это и есть ошибка, которую нужно исправить.
Корректировка весов. После предсказания запускается механизм обратного распространения ошибки, который корректирует веса связей между нейронами, чтобы в следующий раз ошибка стала меньше.
Если сеть ошибочно приняла «3» за «8», то алгоритм обратного распространения определяет, какие связи между нейронами привели к ошибке. Веса этих связей уменьшаются, чтобы ослабить их влияние. А веса, которые способствовали правильному ответу, наоборот, увеличиваются — это усиливает их роль в следующих предсказаниях.
Для корректировки весов можно применить разные механизмы, и один из популярных — обратное распространение ошибки (backpropagation). Он вычисляет градиент функции потерь для каждого веса и определяет, насколько нужно изменить каждую связь. Так сеть понимает, какие веса увеличить или уменьшить и насколько, чтобы минимизировать ошибку и улучшить результат на очередной итерации.
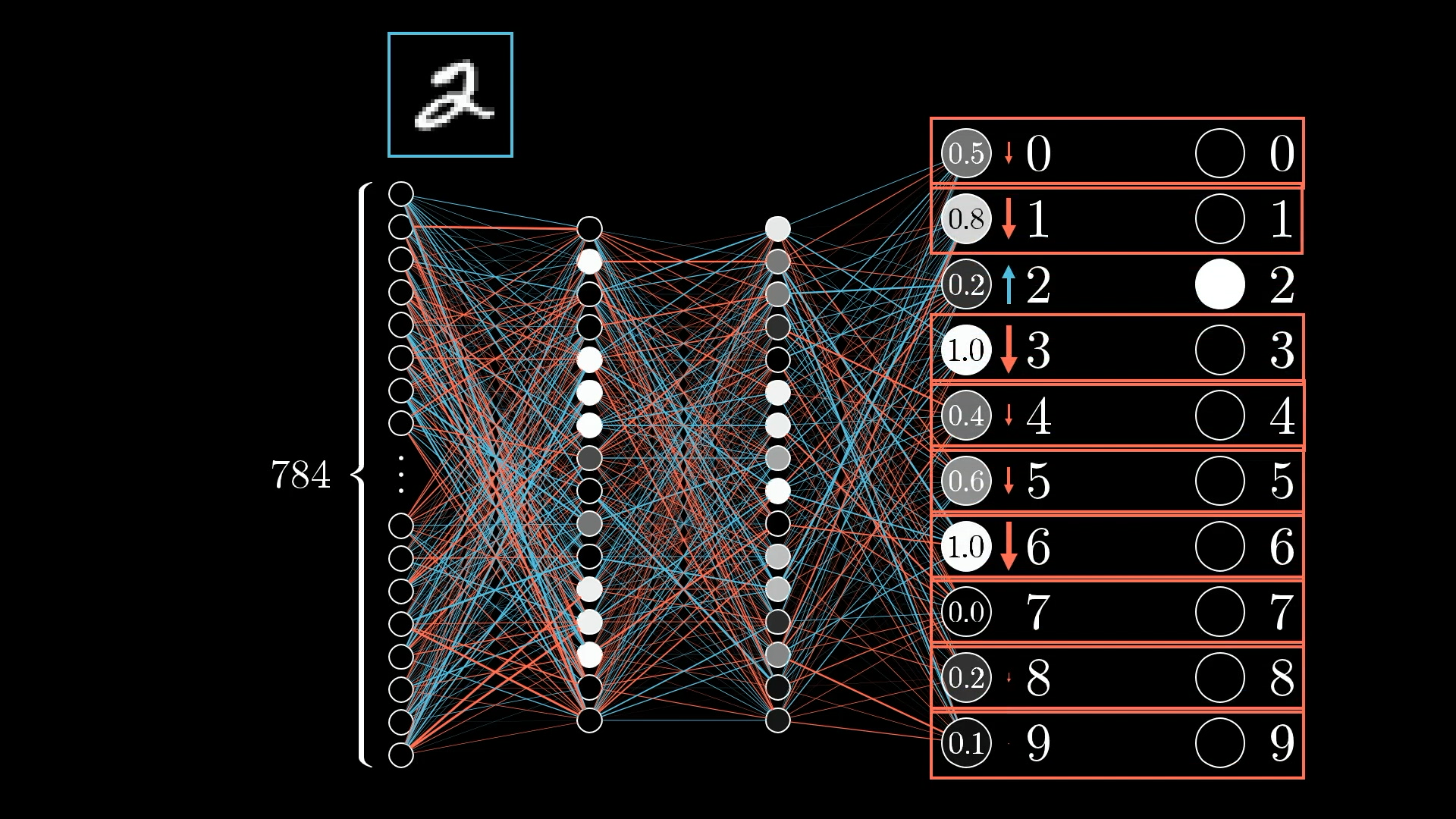
Повторение по эпохам. Процесс предсказания и корректировки весов повторяется на всем датасете множество раз. С каждой эпохой нейросеть точнее определяет закономерности в данных и улучшает предсказания, постепенно обучаясь распознавать формы, звуки, цифры или слова. Например, в первой эпохе сеть может правильно распознать только 60% цифр, после 10 эпох — уже 95%, а после 50 — более 98%.
Здесь важен баланс: если обучать слишком мало эпох, сеть не успеет выучить закономерности и будет давать неточные прогнозы. Если обучать слишком долго — модель запомнит конкретные примеры из тренировочного набора, вместо того чтобы научиться обобщать.
Проверка на новых данных. После завершения обучения модель тестируют на примерах, которые она раньше не видела. Если сеть справляется с ними хорошо — значит, она научилась обобщать, а не просто запоминать конкретные ответы из тренировочного набора.
К примеру, если нейросеть обучалась на 60 000 изображений цифр, ее можно протестировать на отдельном наборе из 10 000 изображений. Если точность распознавания по-прежнему останется на уровне 98–99%, значит, модель действительно научилась распознавать цифры.
Практика: учим нейросеть распознавать цифры
Нейросеть можно написать полностью самостоятельно — реализовать всю математику и алгоритмы с нуля. Такой подход требует глубокого понимания линейной алгебры, градиентного спуска и архитектуры нейронных сетей. Кроме того, он отнимает много времени на кодинг.
Другой подход — использовать готовые библиотеки машинного обучения, которые берут на себя всю сложную математику. Это гораздо быстрее и проще, особенно для новичков. Именно так мы и поступим.
Мы воспользуемся библиотеками TensorFlow и Keras, а также сервисом Google Colab для запуска кода. TensorFlow и Keras предоставляют готовые инструменты для создания и обучения нейросетей. Google Colab — это бесплатная облачная среда, которая позволяет выполнять Python-код прямо в браузере без установки программ на компьютер.
Также вы знаете, что для создания нейросети нужны данные — это первый из важнейших компонентов. В реальных проектах их собирают, очищают и размечают — это требует времени и ресурсов. Но для обучения можно использовать готовые датасеты — наборы данных, которые уже подготовлены и применяются в машинном обучении.
Мы воспользуемся набором MNIST — 70 000 изображений рукописных цифр от 0 до 9, каждое размером 28×28 пикселей в оттенках серого. Мы создадим три версии одной модели с разным количеством эпох, чтобы посмотреть, как она «умнеет» и улучшает точность распознавания.

Уровень 1 — базовое обучение на 3 эпохах
На этом уровне нейросеть проходит минимальное обучение, после которого она сможет различать некоторые цифры — например, отличит «0» от «8». Однако высокой точности ждать не стоит — готовьтесь к большому числу ошибок, особенно на неаккуратно написанных цифрах.
Для построения нейросети мы используем архитектуру из двух сверточных слоев (Conv2D) с подвыборкой (MaxPooling2D), слоя выравнивания (Flatten), одного скрытого слоя (Dense(128)) и выходного слоя из 10 нейронов — по одному на каждую цифру. В качестве функции потерь используется sparse_categorical_crossentropy, а оптимизацию весов выполняет алгоритм Adam. Ниже — готовый код, который вам нужно скопировать и запустить в новом блокноте Google Colab:
# === Нейросеть для распознавания цифр (3 эпохи) ===
import os, random, numpy as np, re
from PIL import Image, ImageOps
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import gradio as gr
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
SEED = 42
random.seed(SEED); np.random.seed(SEED); tf.random.set_seed(SEED)
print("TensorFlow:", tf.__version__, "| Gradio:", gr.__version__)
# --- Проверяем версию Gradio ---
def _vtuple(v):
nums = re.findall(r"\d+", v)
nums = [int(x) for x in nums[:3]]
while len(nums) < 3: nums.append(0)
return tuple(nums)
GRV = _vtuple(gr.__version__)
# --- Загружаем и подготавливаем данные ---
print("Загрузка MNIST...")
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = (x_train.astype("float32") / 255.0)[..., None]
x_test = (x_test.astype("float32") / 255.0)[..., None]
# --- Создаем простую сверточную нейросеть ---
def build_model():
inp = keras.Input(shape=(28, 28, 1))
x = layers.Conv2D(32, 3, activation="relu")(inp)
x = layers.MaxPooling2D()(x)
x = layers.Conv2D(64, 3, activation="relu")(x)
x = layers.MaxPooling2D()(x)
x = layers.Flatten()(x)
x = layers.Dropout(0.25)(x)
x = layers.Dense(128, activation="relu")(x)
out = layers.Dense(10, activation="softmax")(x)
m = keras.Model(inp, out)
m.compile(optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
return m
# --- Обучаем модель ---
print("Обучение модели...")
model = build_model()
model.fit(x_train, y_train, epochs=3, batch_size=128,
validation_split=0.1, verbose=1)
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print(f"\nТочность на тесте: {test_acc:.4f} | loss: {test_loss:.4f}")
# --- Подготавливаем изображение из холста ---
def _extract_array_from_input(img_in):
"""Извлекаем массив пикселей из разных форматов Gradio"""
if img_in is None:
return None
if isinstance(img_in, dict):
arr = img_in.get("composite", img_in.get("image", None))
return arr
return img_in
def preprocess(img_in):
"""Преобразуем рисунок в формат, подходящий для MNIST"""
img_np = _extract_array_from_input(img_in)
if img_np is None:
return None, None
pil = Image.fromarray(img_np.astype('uint8'))
if pil.mode == "RGBA":
bg = Image.new("RGB", pil.size, (255, 255, 255))
bg.paste(pil, mask=pil.split()[3])
pil = bg
pil = pil.convert("L")
pil = ImageOps.invert(pil)
# Проверяем, что на картинке есть цифра
arr = np.array(pil)
if arr.max() < 30:
return None, None
# Находим границы рисунка
mask = (arr > 30).astype(np.uint8)
ys, xs = np.where(mask > 0)
if len(ys) == 0:
return None, None
y1, y2 = ys.min(), ys.max()
x1, x2 = xs.min(), xs.max()
# Обрезаем и добавляем небольшой отступ
pad = 5
y1, x1 = max(0, y1-pad), max(0, x1-pad)
y2, x2 = min(arr.shape[0], y2+pad), min(arr.shape[1], x2+pad)
cropped = pil.crop((x1, y1, x2, y2))
# Делаем квадрат и уменьшаем до 28×28
w, h = cropped.size
side = max(w, h)
square = Image.new("L", (side, side), color=0)
square.paste(cropped, ((side - w)//2, (side - h)//2))
square = square.resize((28, 28), Image.LANCZOS)
# Нормализуем значения и добавляем размерность (1,28,28,1)
x = np.array(square).astype("float32") / 255.0
vis = (x * 255).astype("uint8")
x = x[..., None][None, ...]
return x, vis
# --- Делаем предсказание ---
def predict(img_in):
"""Определяем, какую цифру нарисовали"""
print("Вызвана функция predict")
if img_in is None:
print("Изображение None")
return {f"Цифра {i}": 0.0 for i in range(10)}, None
try:
prep, vis = preprocess(img_in)
if prep is None:
print("Препроцессинг вернул None")
return {f"Цифра {i}": 0.0 for i in range(10)}, None
print("Выполняется предсказание...")
probs = model.predict(prep, verbose=0)[0]
result_dict = {f"Цифра {i}": float(probs[i]) for i in range(10)}
print(f"Топ-3: {sorted(result_dict.items(), key=lambda x: x[1], reverse=True)[:3]}")
return result_dict, Image.fromarray(vis, "L")
except Exception as e:
print(f"Ошибка в predict: {e}")
import traceback
traceback.print_exc()
return {f"Ошибка: {str(e)}": 1.0}, None
# --- Создаем холст для рисования ---
def make_canvas():
"""Выбираем подходящий компонент в зависимости от версии Gradio"""
try:
from gradio.components import ImageEditor
print("Используется ImageEditor")
return ImageEditor(
label="Холст (рисуйте черным по белому)",
type="numpy",
brush=gr.Brush(colors=["#000000"], default_size=15),
eraser=gr.Eraser(default_size=15),
)
except Exception as e:
print(f"ImageEditor недоступен: {e}")
try:
print("Используется Image с sources=['canvas']")
return gr.Image(
sources=["canvas"],
type="numpy",
label="Холст (рисуйте черным по белому)",
brush_radius=15,
)
except TypeError:
try:
print("Используется Image с source='canvas'")
return gr.Image(
source="canvas",
type="numpy",
label="Холст (рисуйте черным по белому)",
)
except Exception:
pass
try:
print("Используется Sketchpad")
return gr.Sketchpad(label="Холст (рисуйте черным по белому)")
except Exception:
pass
print("Используется простой Image")
return gr.Image(type="numpy", label="Загрузите изображение с цифрой")
# --- Собираем интерфейс ---
with gr.Blocks(title="MNIST Digit Recognizer") as demo:
gr.Markdown("## Распознавание рукописных цифр (MNIST)")
gr.Markdown("Нарисуйте цифру от 0 до 9 и нажмите кнопку «Распознать»")
with gr.Row():
with gr.Column(scale=1):
canvas = make_canvas()
with gr.Row():
btn = gr.Button(" Распознать", variant="primary", size="lg")
clear_btn = gr.Button("Очистить", size="lg")
with gr.Column(scale=1):
out_label = gr.Label(num_top_classes=10, label="Результат распознавания")
out_img = gr.Image(label="Обработанное изображение (28×28)", type="pil")
# Добавляем кнопку «Распознать»
btn.click(
fn=predict,
inputs=[canvas],
outputs=[out_label, out_img],
show_progress=True
)
# Добавляем кнопку «Очистить»
def clear_all():
return None, {f"Цифра {i}": 0.0 for i in range(10)}, None
clear_btn.click(
fn=clear_all,
inputs=None,
outputs=[canvas, out_label, out_img]
)
# --- Запускаем интерфейс ---
print("\nЗапуск интерфейса Gradio...")
demo.launch(share=False, show_error=True, debug=True)
После запуска кода модель начнет обучение на наборе данных MNIST и выполнит три полных прохода по всем тренировочным изображениям. В каждой эпохе вы сможете отслеживать следующие метрики:
- accuracy — точность на обучающей выборке;
- val_accuracy — точность на валидационной выборке;
- loss и val_loss — значения функции потерь, которая показывает, насколько предсказания модели отличаются от правильных ответов. Чем ниже эти значения, тем точнее работает нейросеть.
Время обучения одной эпохи зависит от мощности процессора, наличия графического ускорителя, нагрузки на среду Colab и размера батча — количества примеров, которые модель обрабатывает за раз.
У нас первая эпоха заняла 45 секунд, а последующие — около 80 секунд. После трех эпох нейросеть достигла 98% точности на тестовых данных.
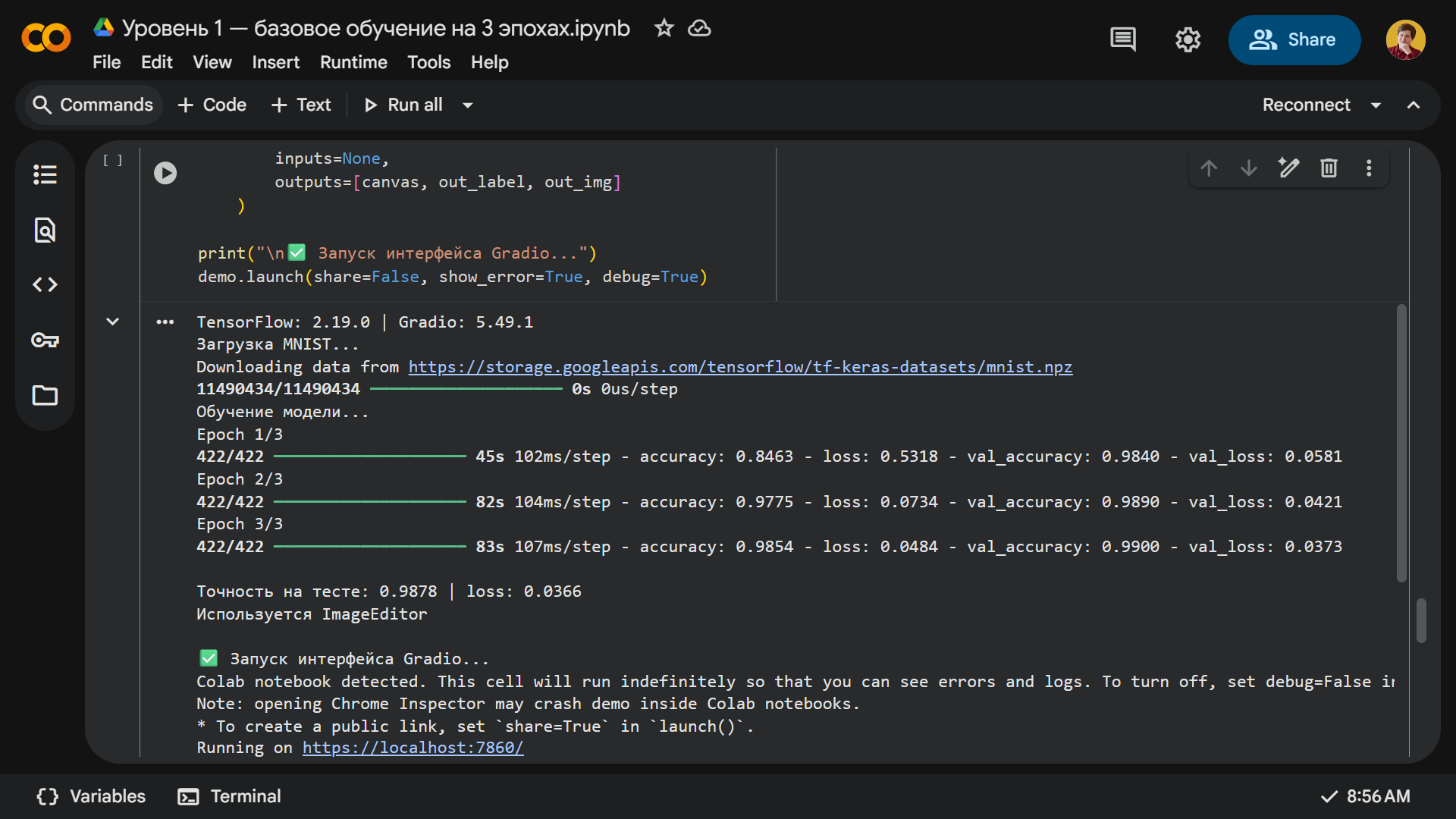
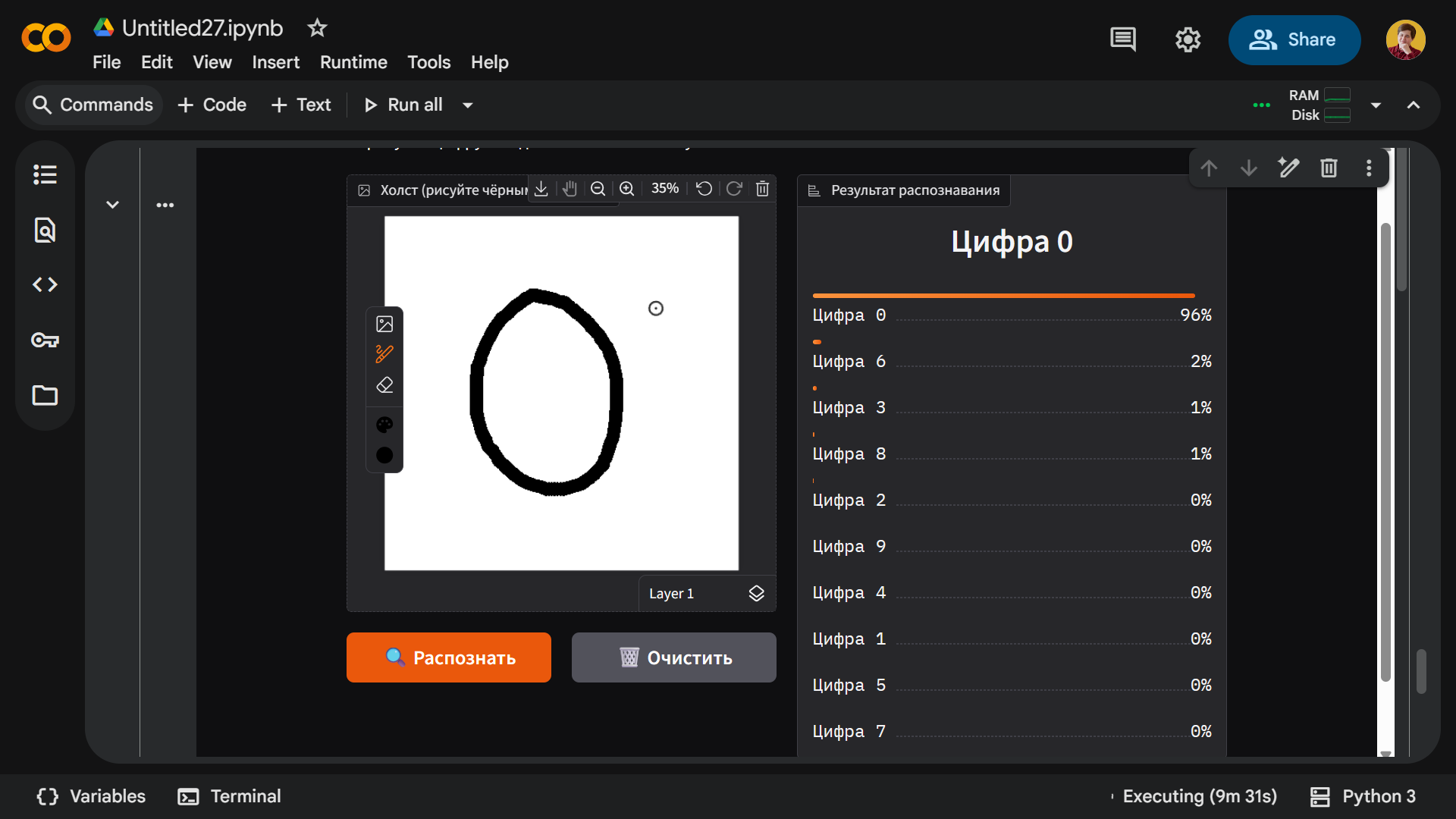
Во время проверки модель действительно распознает большинство цифр, однако почти никогда не делает этого с первой попытки. Нам пришлось два-три раза писать каждую цифру, чтобы получить правильный результат. Например, вот как нейросеть видит ноль:
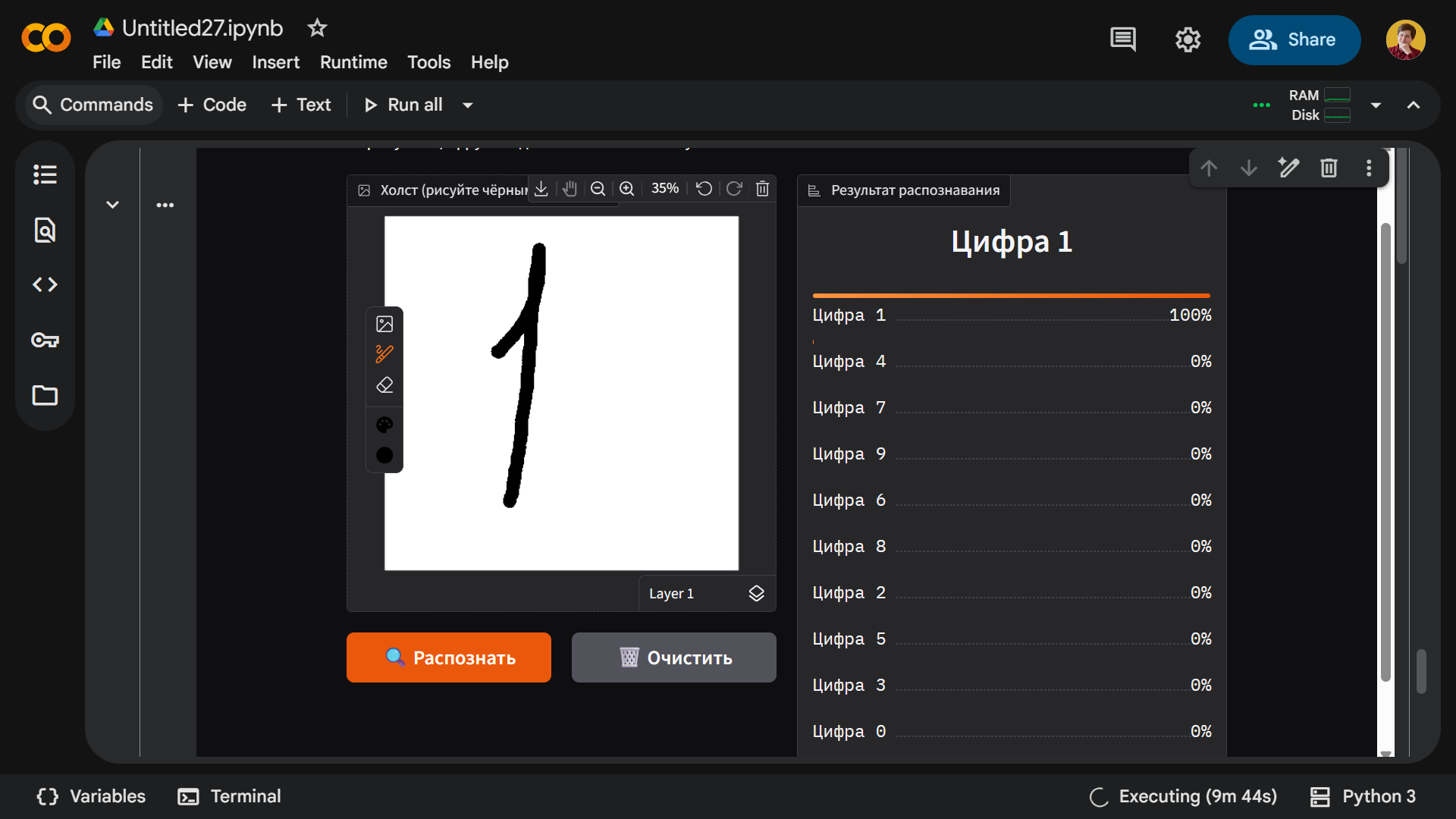
Вот единица:
А это восемь:
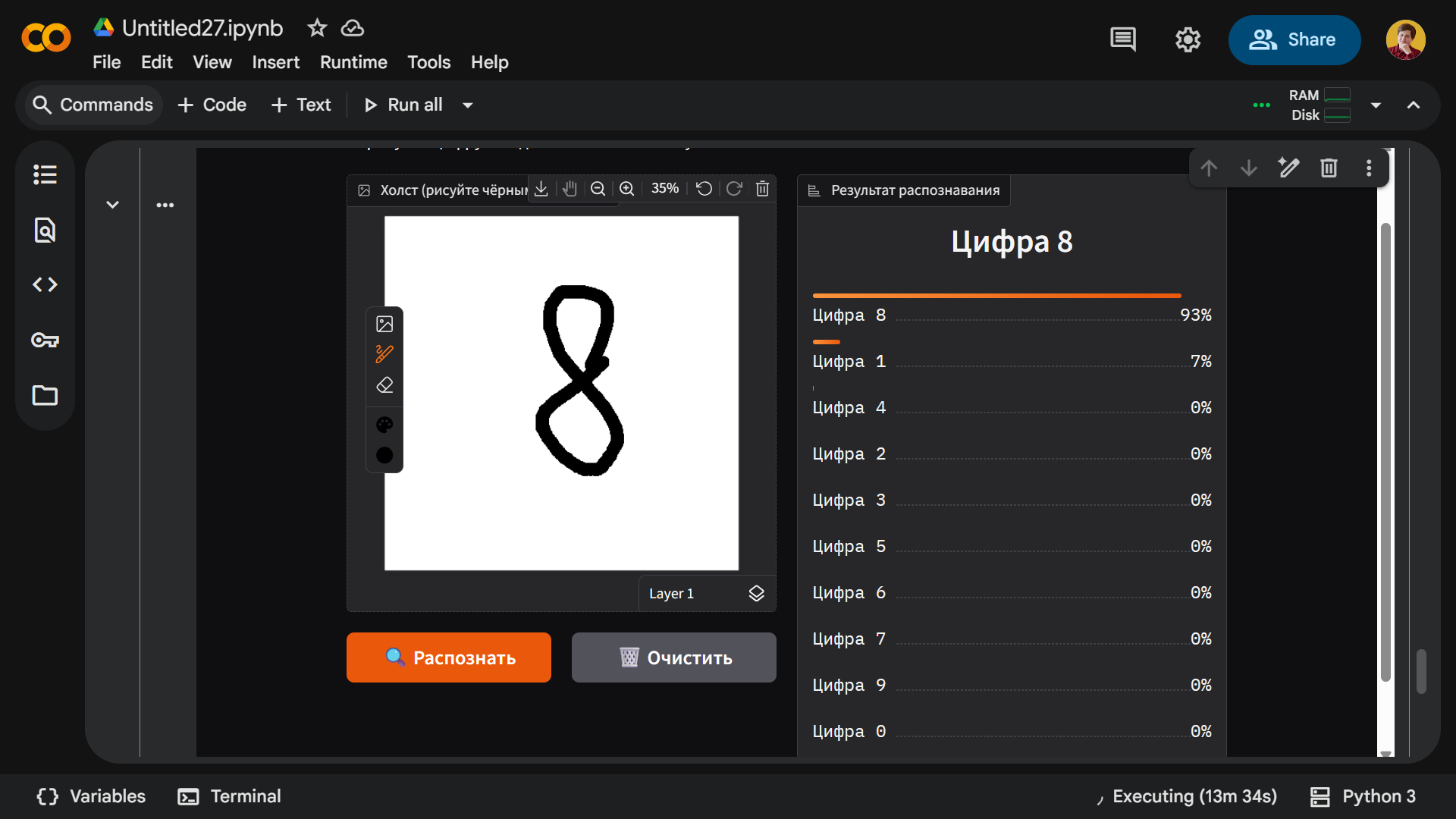
Больше всего проблем возникло с цифрами 7 и 9 — как бы мы их ни писали, модель их не распознавала. Единственный раз, когда у нее получилось определить 7, — это когда мы написали девятку:
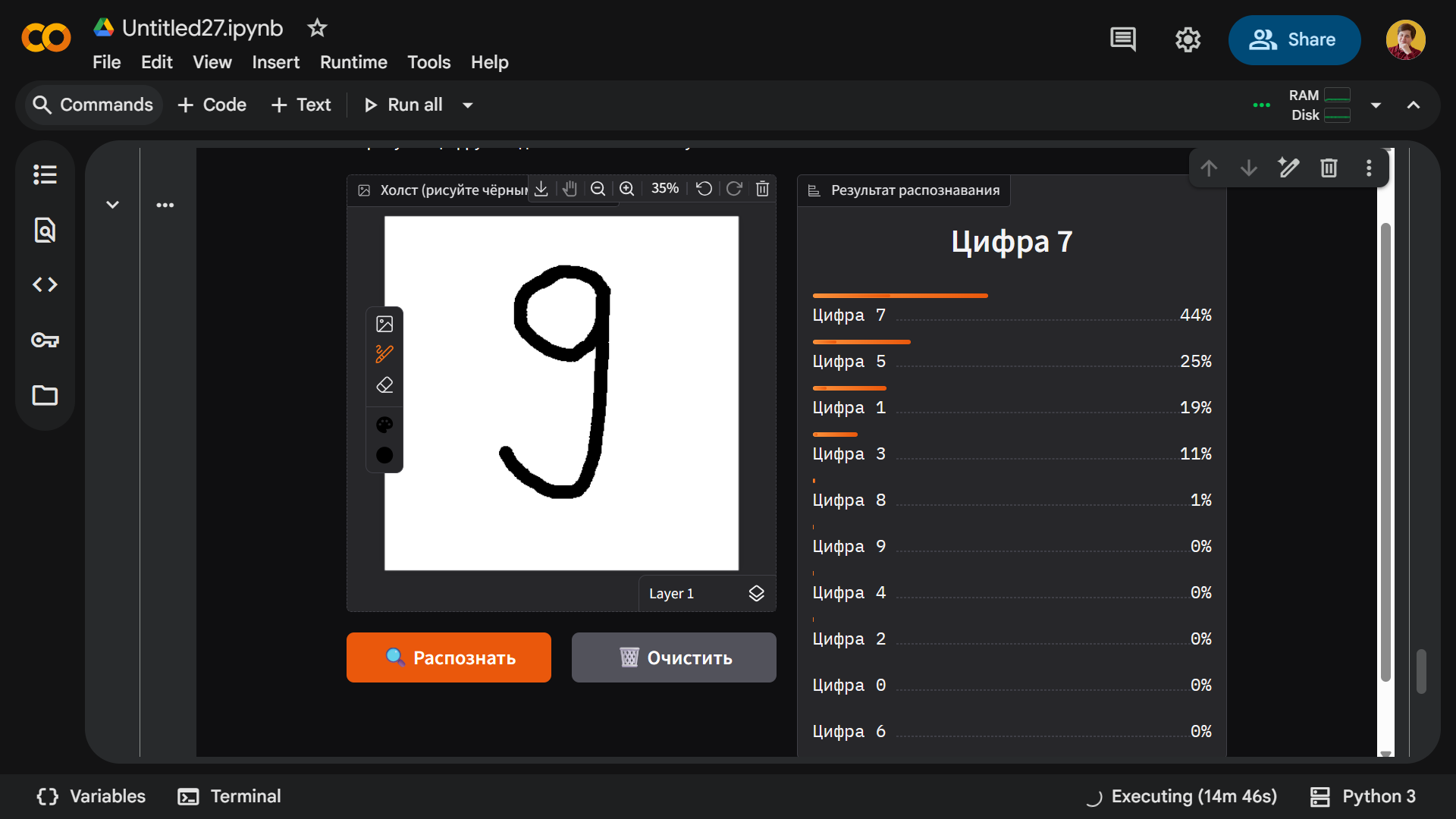
Уровень 2 — обучаем модель на 7 эпохах
Доработаем код и внесем в него несколько улучшений:
- используем BatchNormalization — технику, которая стабилизирует обучение и помогает нейросети быстрее настраивать параметры;
- применим улучшенную предобработку изображений — цифра выровняется по центру, ее линии станут четче и немного толще, а яркость и контраст будут более оптимизированными;
- увеличим количество эпох с 3 до 7 — модель получит больше времени для изучения различных стилей написания цифр.

Для удобства рекомендуем открыть новый блокнот в Google Colab, добавить в него следующий код и дождаться окончания обучения:
# === Нейросеть для распознавания цифр (7 эпох, улучшенная) ===
import os, sys, subprocess, random, numpy as np
from PIL import Image, ImageOps, ImageChops, ImageFilter
try:
import gradio as gr
except Exception:
subprocess.check_call([sys.executable, "-m", "pip", "install", "-q", "gradio==3.50.2", "pillow"])
import gradio as gr
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
SEED = 42
random.seed(SEED); np.random.seed(SEED); tf.random.set_seed(SEED)
print("TensorFlow:", tf.__version__, "| Gradio:", getattr(gr, "__version__", "n/a"))
# Загружаем и нормализуем данные MNIST
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = (x_train.astype("float32") / 255.0)[..., None]
x_test = (x_test.astype("float32") / 255.0)[..., None]
# Создаем сверточную нейросеть с BatchNormalization
def build_model():
inp = keras.Input(shape=(28, 28, 1))
x = layers.Conv2D(32, 3, padding="same")(inp)
x = layers.BatchNormalization()(x); x = layers.ReLU()(x)
x = layers.MaxPooling2D()(x)
x = layers.Conv2D(64, 3, padding="same")(x)
x = layers.BatchNormalization()(x); x = layers.ReLU()(x)
x = layers.MaxPooling2D()(x)
x = layers.Flatten()(x)
x = layers.Dropout(0.30)(x)
x = layers.Dense(128)(x)
x = layers.BatchNormalization()(x); x = layers.ReLU()(x)
out = layers.Dense(10, activation="softmax")(x)
m = keras.Model(inp, out)
m.compile(optimizer="adam", loss="sparse_categorical_crossentropy", metrics=["accuracy"])
return m
model = build_model()
# Обучаем модель 7 эпох и проверяем точность
history = model.fit(x_train, y_train, epochs=7, batch_size=128, validation_split=0.1, verbose=1)
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=0)
print(f"\n[7 эпох] Точность на тесте: {test_acc:.4f} | loss: {test_loss:.4f}")
# Преобразуем рисунок с холста под формат MNIST с улучшенной обработкой
def preprocess(img_np):
if img_np is None:
return None, None
pil = Image.fromarray(img_np)
if pil.mode == "RGBA":
bg = Image.new("RGBA", pil.size, (255, 255, 255, 255))
pil = Image.alpha_composite(bg, pil).convert("RGB")
pil = pil.convert("L")
pil = ImageOps.autocontrast(pil, cutoff=2)
pil = ImageOps.invert(pil)
arr = np.array(pil)
thr = max(30, int(arr.mean() * 0.7))
mask = (arr > thr).astype(np.uint8)
if mask.sum() == 0:
return None, None
ys, xs = np.where(mask > 0)
y1, y2 = ys.min(), ys.max(); x1, x2 = xs.min(), xs.max()
cropped = pil.crop((x1, y1, x2 + 1, y2 + 1))
cropped = cropped.filter(ImageFilter.MaxFilter(3))
w, h = cropped.size
side = max(w, h)
square = Image.new("L", (side, side), color=0)
square.paste(cropped, ((side - w)//2, (side - h)//2))
square = square.resize((28, 28), Image.LANCZOS)
a = np.array(square)
bin_ = (a > a.mean()).astype(np.uint8)
ys, xs = np.where(bin_ > 0)
if len(ys) > 0:
cy, cx = ys.mean(), xs.mean()
square = ImageChops.offset(square, int(14 - cx), int(14 - cy))
x = np.array(square).astype("float32") / 255.0
vis = (x * 255).astype("uint8")
x = x[..., None][None, ...]
return x, vis
# Извлекаем numpy массив из различных форматов Gradio
def _extract_np(img_in):
if img_in is None:
return None
if isinstance(img_in, np.ndarray):
return img_in
if isinstance(img_in, dict):
for k in ("composite", "image", "background"):
if k in img_in and img_in[k] is not None:
return img_in[k]
if "layers" in img_in and img_in["layers"]:
last = img_in["layers"][-1]
if isinstance(last, dict) and "image" in last:
return last["image"]
return None
# Предсказываем цифру с обработкой ошибок
def predict_safe(img_in):
try:
img_np = _extract_np(img_in)
prep, vis = preprocess(img_np)
if prep is None:
return {"Нарисуйте цифру и нажмите «Распознать»": 1.0}, None
probs = model.predict(prep, verbose=0)[0]
scores = {str(i): float(probs[i]) for i in range(10)}
return scores, Image.fromarray(vis, mode="L")
except Exception as e:
print(f"Ошибка в predict_safe: {e}")
import traceback; traceback.print_exc()
return {f"Ошибка: {type(e).__name__}": 1.0}, None
# Создаем холст для рисования с поддержкой разных версий Gradio
def make_canvas():
try:
from gradio.components import ImageEditor
print("Используется ImageEditor")
return ImageEditor(
label="Холст (рисуйте черным по белому)",
type="numpy",
brush=gr.Brush(colors=["#000000"], default_size=15),
eraser=gr.Eraser(default_size=15),
)
except Exception:
pass
try:
print("Используется Image с sources=['canvas']")
return gr.Image(sources=["canvas"], type="numpy", label="Холст (рисуйте черным по белому)", height=300, width=300)
except TypeError:
pass
try:
print("Используется Image с source='canvas'")
return gr.Image(source="canvas", type="numpy", label="Холст (рисуйте черным по белому)")
except Exception:
pass
try:
print("Используется Sketchpad")
return gr.Sketchpad(label="Холст (рисуйте черным по белому)")
except Exception:
pass
print("Используется простой Image")
return gr.Image(type="numpy", label="Загрузите изображение с цифрой")
# Собираем интерфейс Gradio
with gr.Blocks(title="MNIST Level 2") as demo:
gr.Markdown("## Распознавание цифр (0-9) -- модель обучена 7 эпох")
gr.Markdown("Нарисуйте цифру и нажмите «Распознать»")
with gr.Row():
canvas = make_canvas()
with gr.Column():
out_label = gr.Label(num_top_classes=3, label="Топ-3 предсказания")
out_img = gr.Image(label="То, что идет в сеть (28×28)", type="pil")
with gr.Row():
btn = gr.Button("Распознать", variant="primary")
clear_btn = gr.Button("Очистить")
btn.click(predict_safe, inputs=canvas, outputs=[out_label, out_img])
def clear_all():
return None, {"Нарисуйте цифру": 1.0}, None
clear_btn.click(clear_all, inputs=None, outputs=[canvas, out_label, out_img])
print("\nЗапуск интерфейса...")
demo.launch(share=False, show_error=True, debug=True)
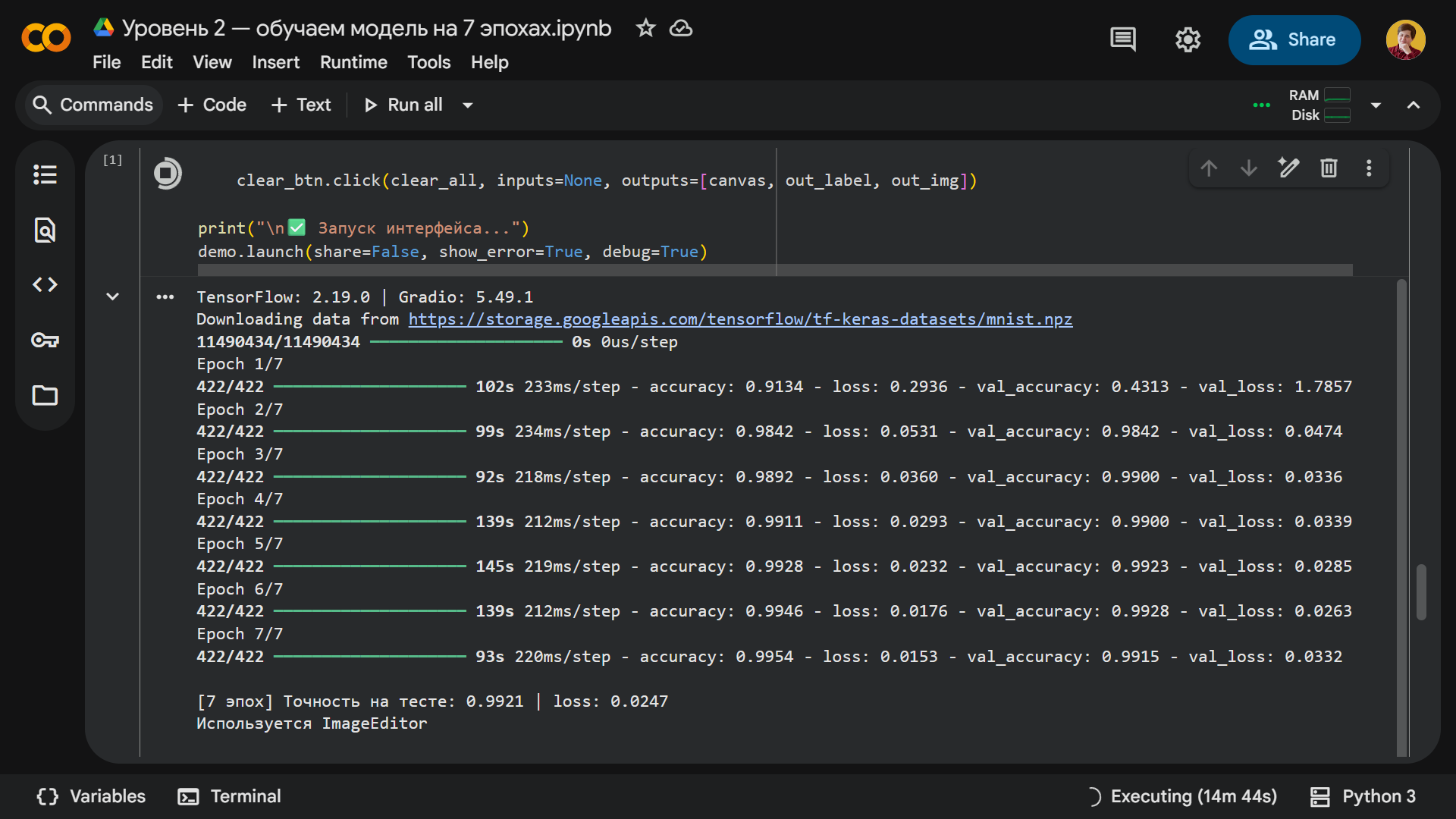
После запуска кода нейросеть проходит семь эпох обучения. Это занимает в три-четыре раза больше времени, чем на первом уровне: каждая эпоха длится 90–140 секунд, а общее время — примерно 15 минут. После завершения процесса точность на тестовой выборке выросла до 99,2%, а значение функции потерь снизилось до 0,0247.
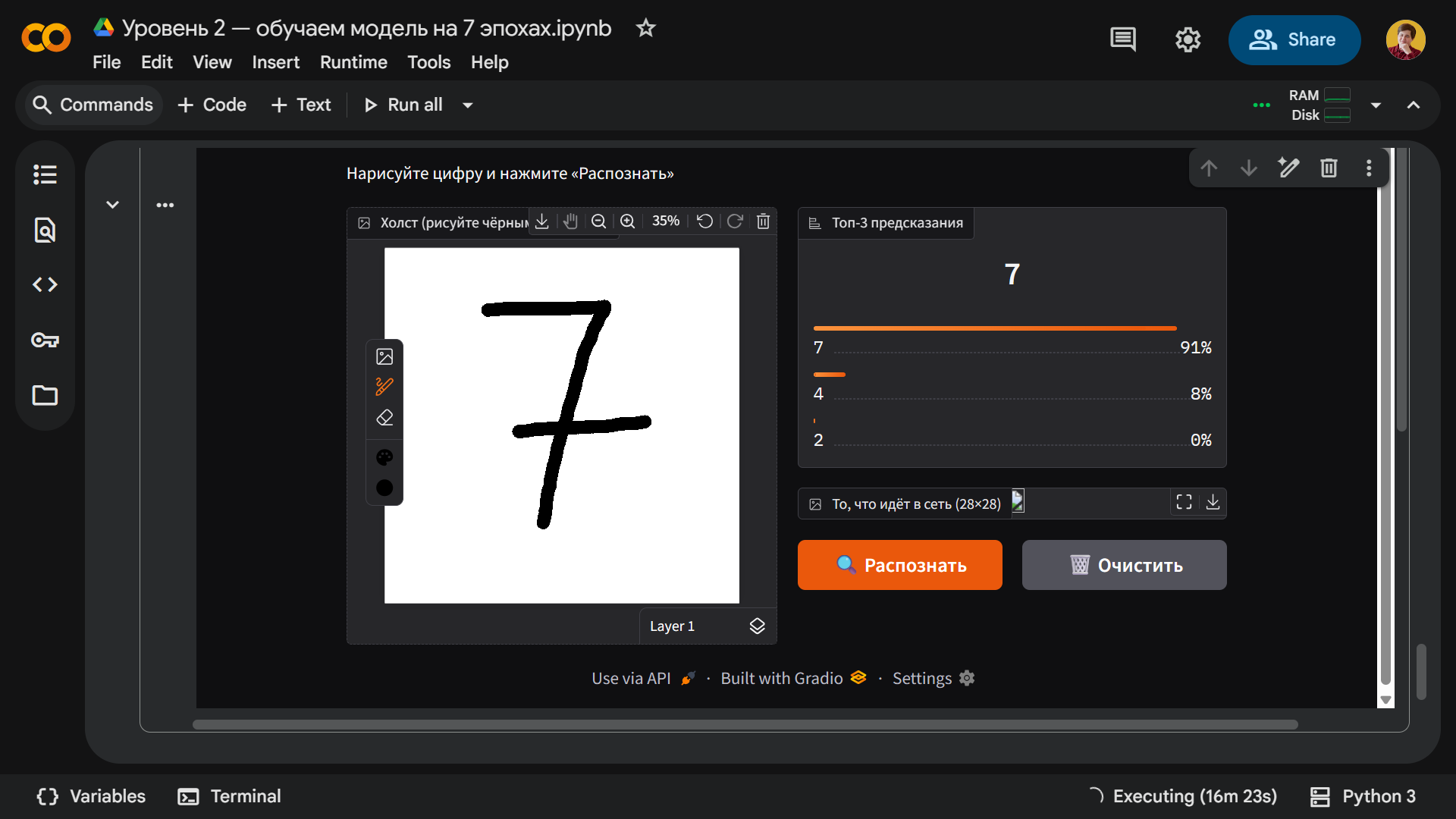
Благодаря большему числу итераций модель стала устойчивее к переобучению и с первого раза практически безошибочно распознает большинство цифр. Например, вот наша проблемная семерка:
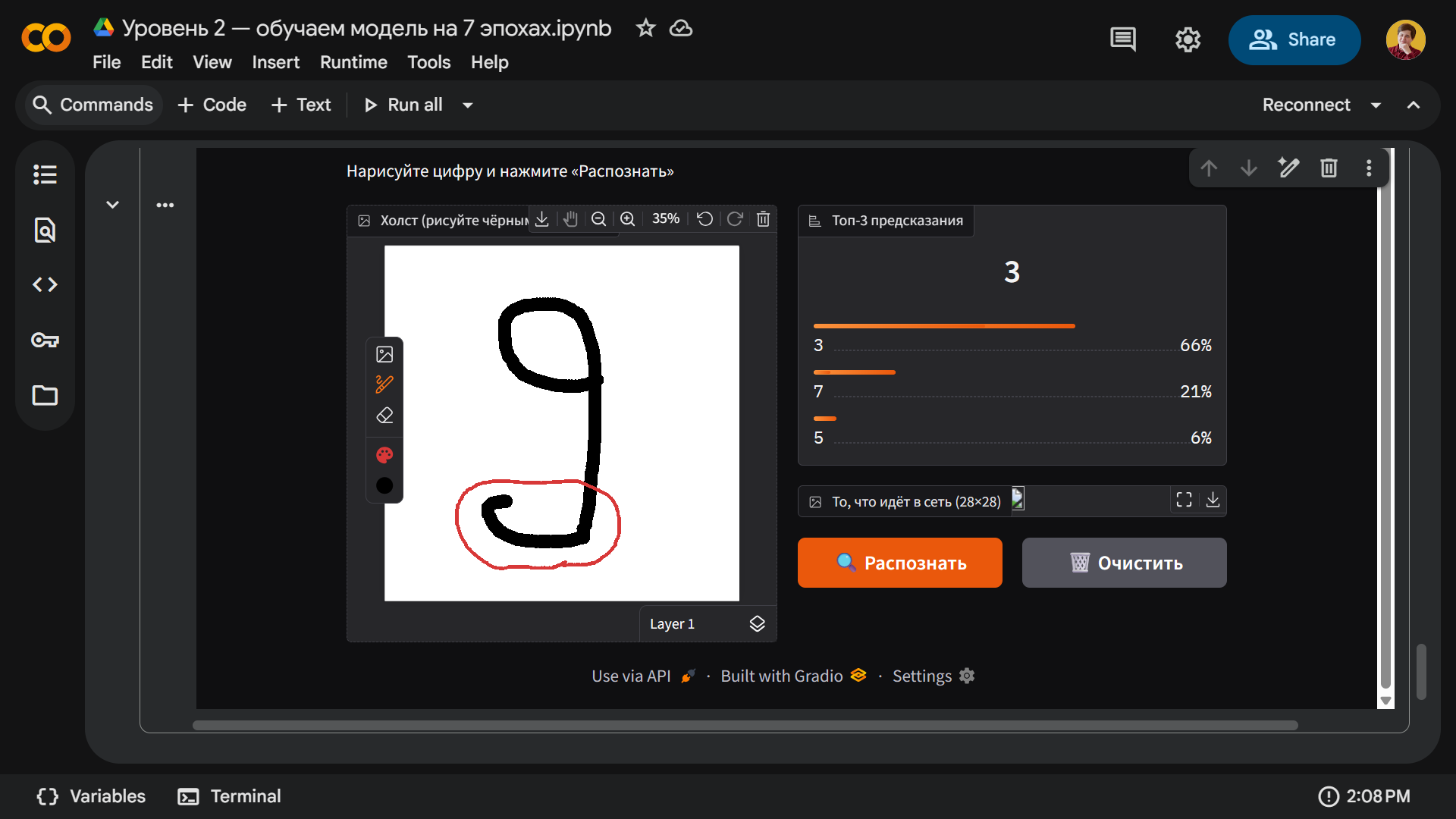
А вот девятка оказалась единственной проблемной цифрой — модель ее периодически распознает, но чаще делает ошибку. Причина в нижнем хвостике — если вы его не добавите, то все работает как положено:
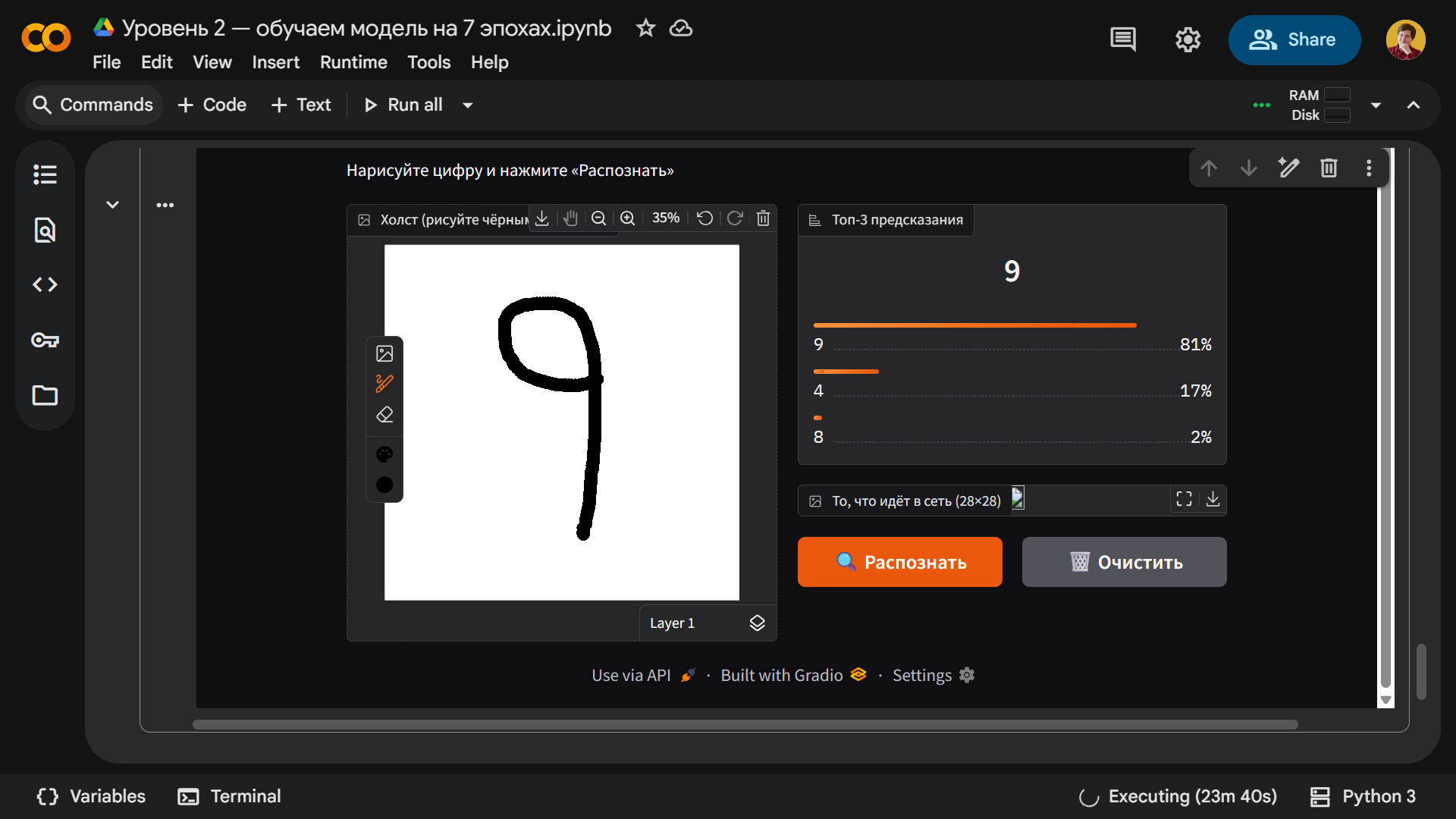
А теперь дорисуем нашей девятке хвост и получим другой результат:
Уровень 3 — дообучение на собственных данных
Это финальная часть для самых терпеливых — тех, кто хочет наконец научить нейросеть распознавать все цифры, включая девятку с хвостиком. В третьей версии мы добавим возможность донастраивать модель прямо из интерфейса. Если модель ошибается, вы сможете вручную указать правильную цифру и добавить пример в мини-датасет.
Далее, после накопления хотя бы десяти таких примеров, можно нажать кнопку Дообучить модель — и сеть проведет короткое дообучение с пониженным темпом обучения, чтобы подстроиться под ваш почерк.
В коде это реализовано через отдельное хранилище пользовательских изображений и меток, динамическое обновление оптимизатора с новым значением learning_rate и повторный вызов функции fit() на накопленных примерах. Благодаря этому модель способна не просто воспроизводить заготовленные цифры из MNIST, а действительно адаптироваться к вашему индивидуальному рукописному почерку в реальном времени — каждый новый пример корректирует веса сети.
Реализация этой версии нейросети занимает около 300 строк кода в редакторе VS Code, поэтому здесь мы публиковать эту простыню не будем. Вместо этого скачайте готовый Python-файл, скопируйте его содержимое, а затем вставьте код в новый блокнот в Google Colab. После запуска модель снова пройдет обучение на семи эпохах, и у вас будет обновленный интерфейс с функцией дообучения нейросети.
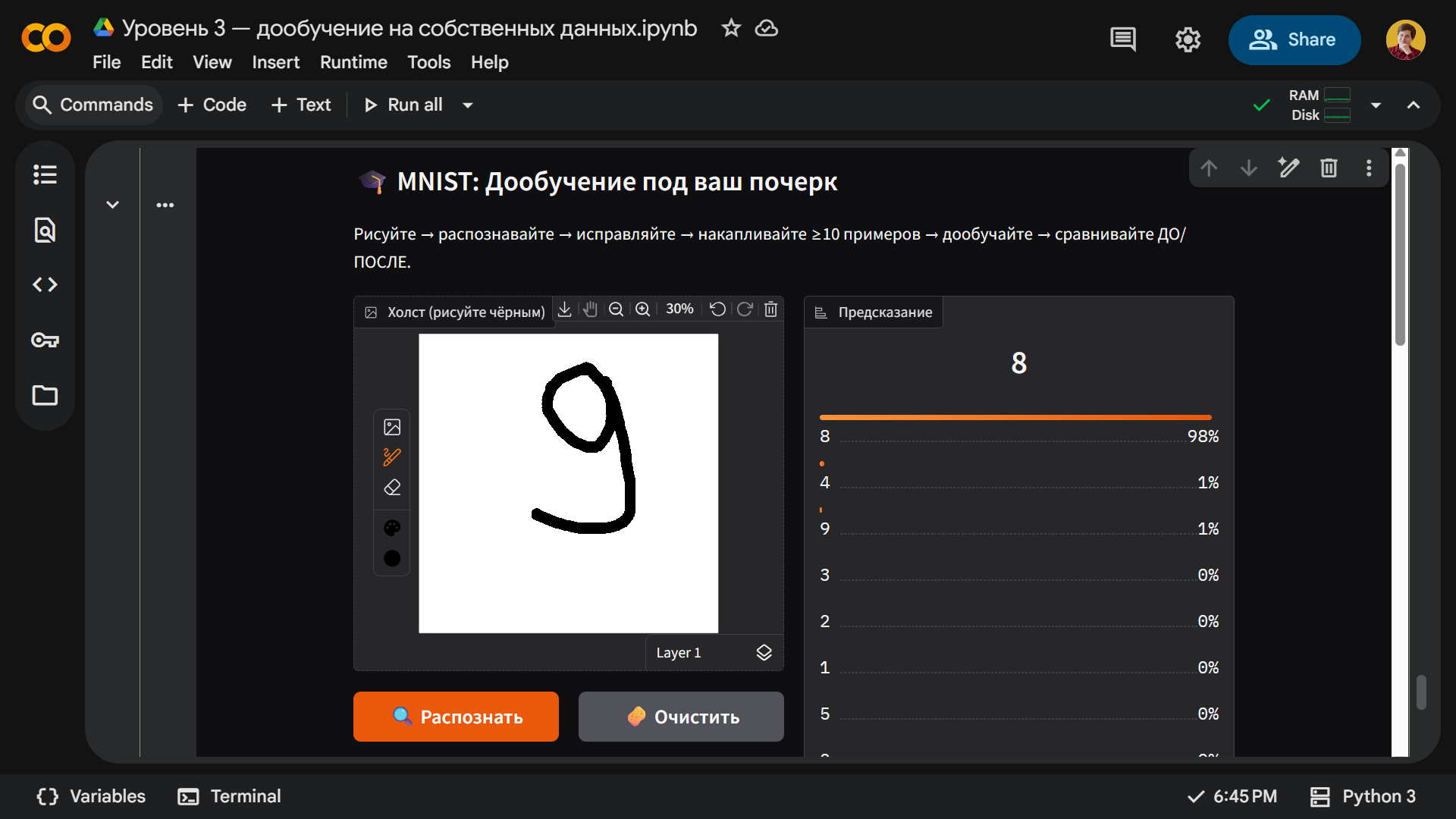
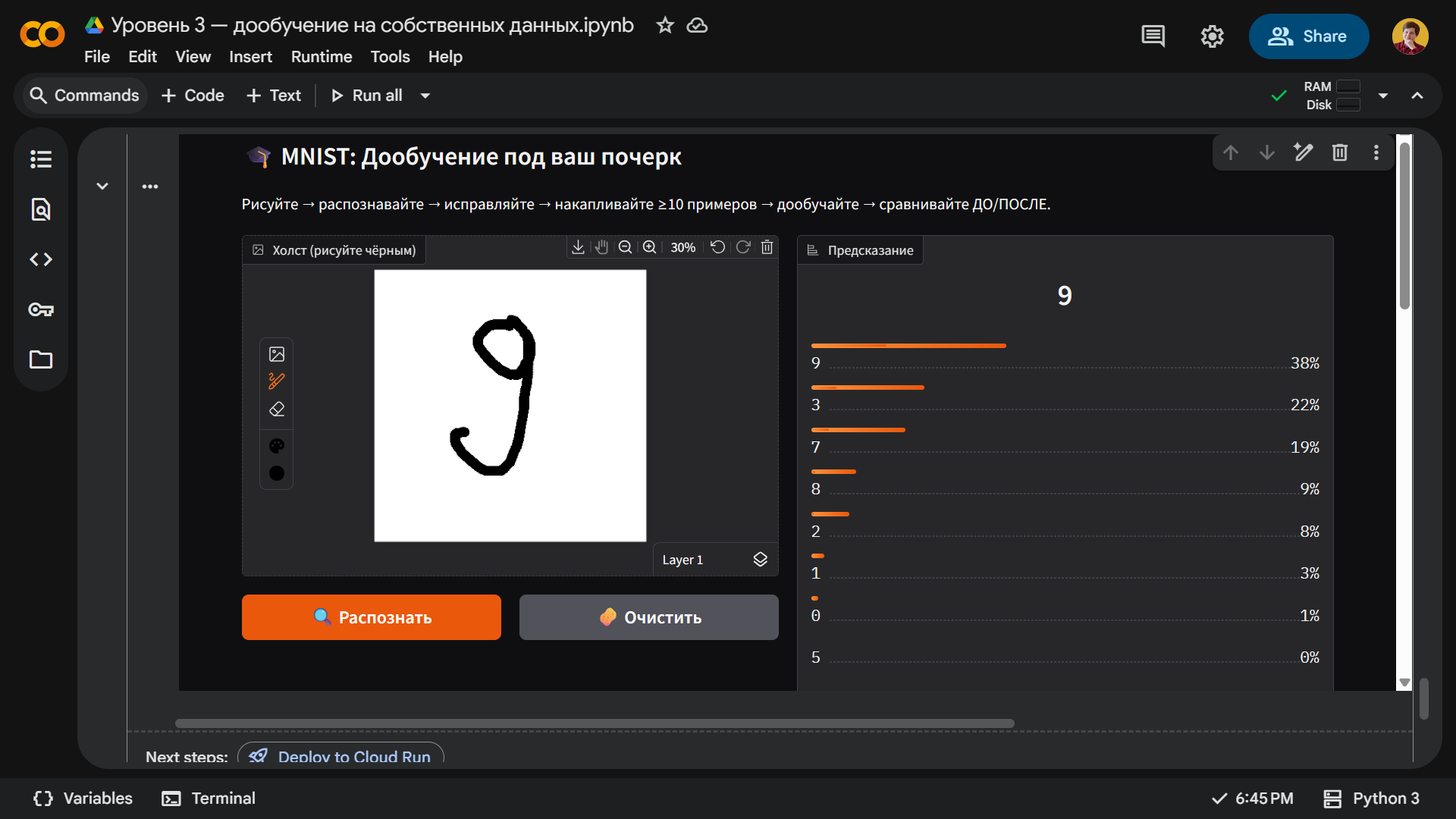
Для начала проверим, что без дообучения нейросеть по-прежнему не распознает девятки с хвостиком. Рисуем и получаем такую восьмерку:
Теперь нарисуем от руки десять примеров, сохраним их и нажмем кнопку Дообучить. После этого нейросеть должна начать лучше ориентироваться в нашем почерке и распознавать девятку с хвостиком.
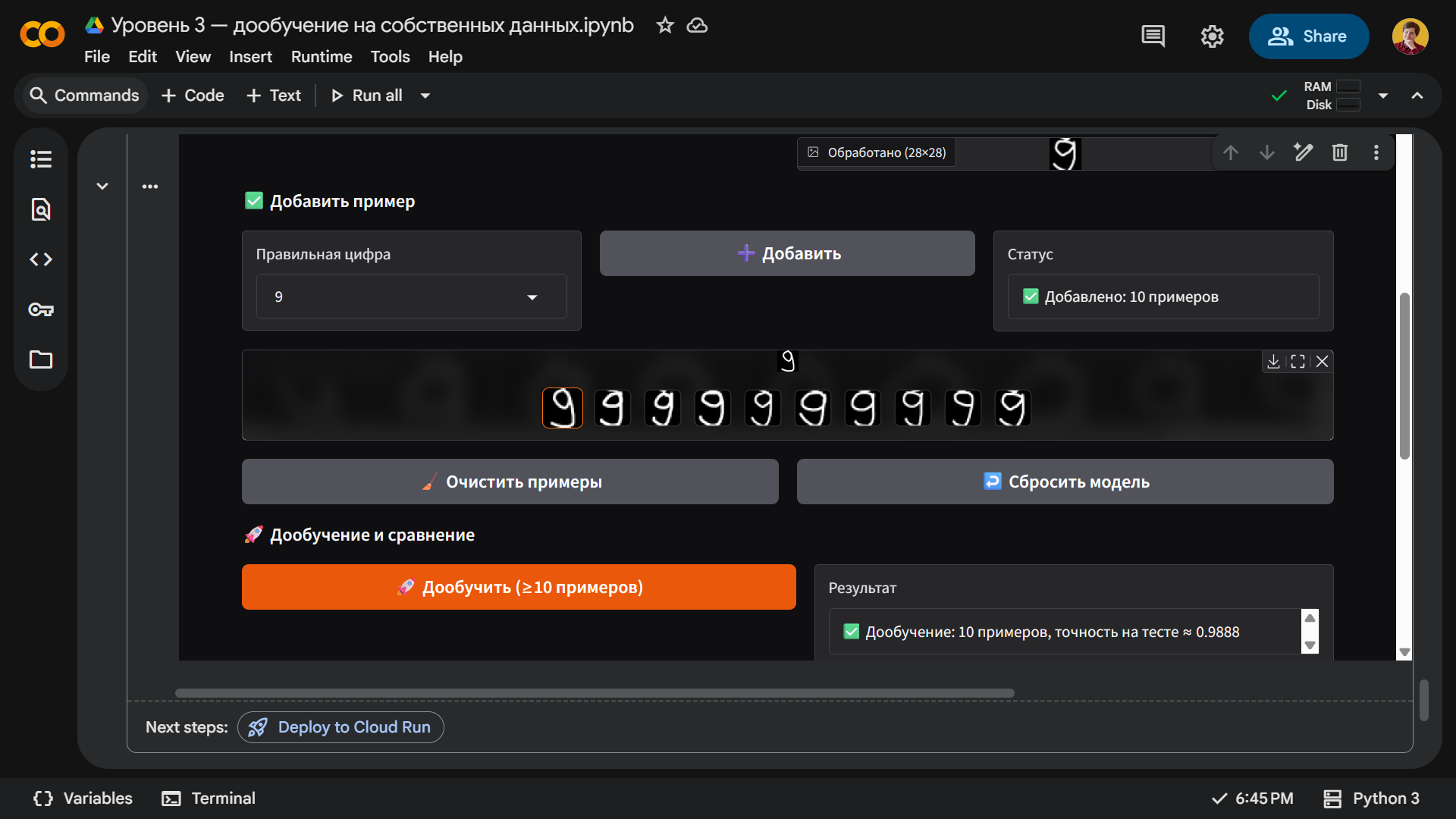
Чуда не произошло — десяти цифр оказалось мало. Поэтому мы продолжили писать девятки и набрали их целых пятьдесят штук. Только после этого нейросеть стала чаще угадывать, чем ошибаться.
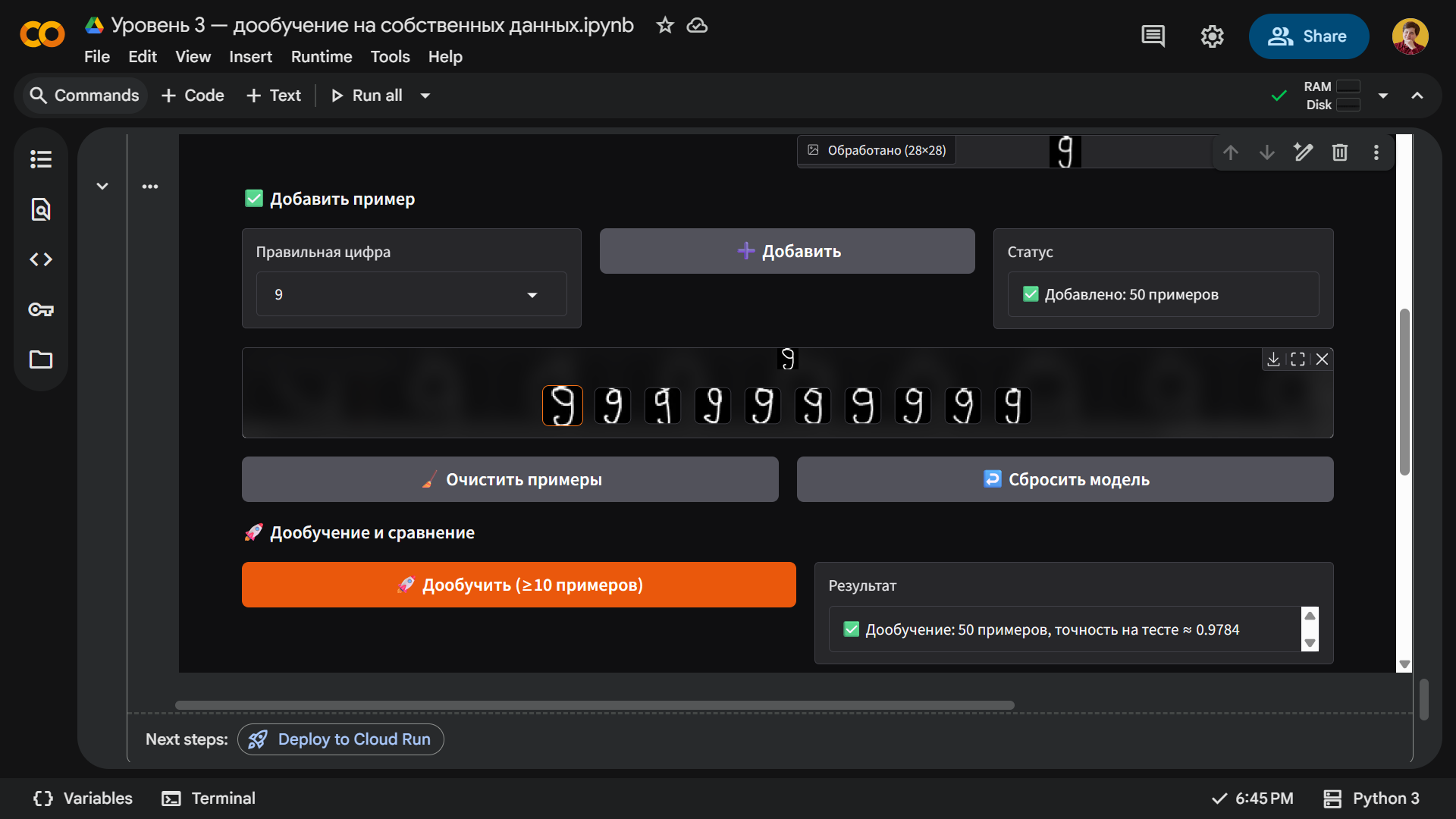
Помимо количества многое зависит от почерка. Например, если мы напишем довольно неразборчивую девятку, то нейросеть узнает в ней нужную цифру, однако процент распознавания будет невысоким:
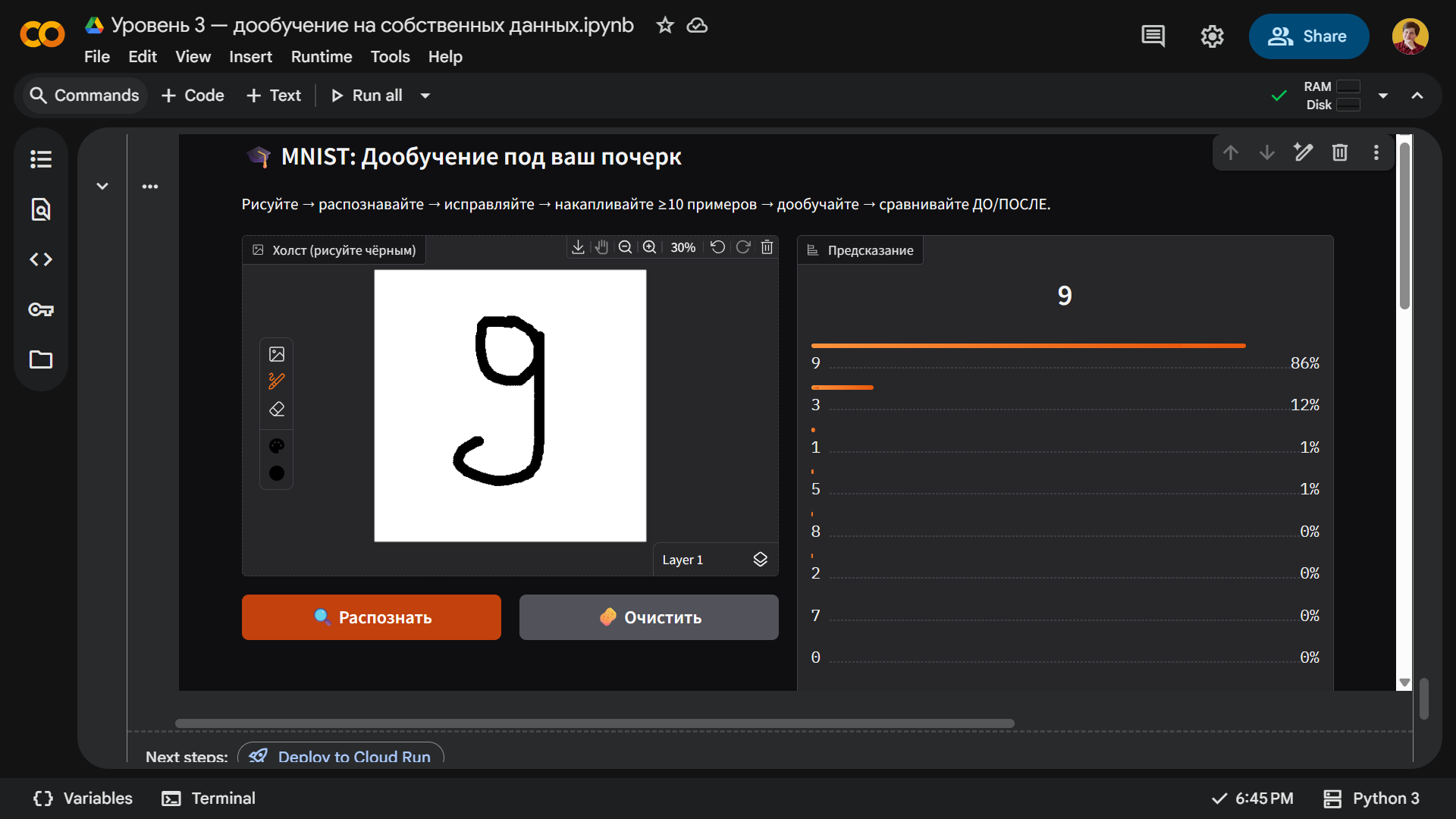
А если мы хоть немного постараемся, то добьемся нужного результата:
Что дальше
Мы создали нейросеть в Google Colab с помощью библиотек TensorFlow и Keras из датасета MNIST. Чтобы углубиться в тему — рекомендуем другую нашу статью «Как написать свою первую нейросеть на Python».
Из нее вы узнаете, как реализовать нейрон — базовый элемент, который принимает входные данные, умножает их на веса, суммирует результаты и пропускает через функцию активации. Весь код вы напишете с нуля, используя только Python и простейшие математические операции — без библиотек машинного обучения.
Такой пример поможет лучше понять, как устроено обучение нейросетей изнутри. Он станет хорошей основой для создания более сложных архитектур — от сверточных сетей до рекуррентных моделей.
