
Быстрее получить анализы крови, решить нетривиальную изобретательскую задачу и прогнозировать загрязнение воздуха так же, как погоду, — все это можно реализовать с помощью ML-моделей. Делимся кейсами по машинному обучению выпускников магистратуры «Наука о данных» МИСиС, которые нашли в своих работах применение нейросетям.

«Работая в лаборатории, я заметила, как много времени занимают рутинные операции»
Елена Писарчук начала свою карьеру со специальности «Биотехнология». Обучаясь в университете, она часто бывала в микробиологических лабораториях, а также работала в Институте биохимической физики РАН и Национальном исследовательском центре эпидемиологии и микробиологии имени Гамалеи. Именно здесь она нашла тему для своего будущего ML-проекта. Елена рассказала кейс применения ML AI в реальной жизни.
Я заметила, что в лабораторных экспериментах много времени занимают рутинные операции — например, подготовка растворов, культивирование микроорганизмов и обработка результатов. Чтобы получить достоверные анализы, эксперименты нужно повторять много раз, это довольно долго. Проводя очередной эксперимент, я поняла, что обработку результатов можно автоматизировать с использованием современных технологий. Так я поняла, чему хочу учиться дальше и над какой темой буду работать.
База в биохимических анализах у меня уже была, на магистратуре главной целью было разобраться в алгоритмах компьютерного зрения и нейросетях. Чтобы выбрать инструменты для работы, я сравнила эффективность существующих типов нейросетей (DNN AlexNet, DenseNet 169, Inception и другие), а также проанализировала разные детекторы и дескрипторы особых точек. По итогу для своего проекта выбрала нейросеть DNN ResNet и алгоритм ORB.
При разработке программного комплекса я сначала написала парсер для автоматизированного сбора изображений из поисковой системы Google. С его помощью собрала более 3 тыс. изображений разных патогенных микроорганизмов. Потом алгоритм сортировки отобрал изображения с лучшим качеством, отфильтровал повторяющиеся картинки. Дальше я обучила модель классифицировать изображения с микроскопа, а для удобства использования в лабораториях сделала простой пользовательский интерфейс.

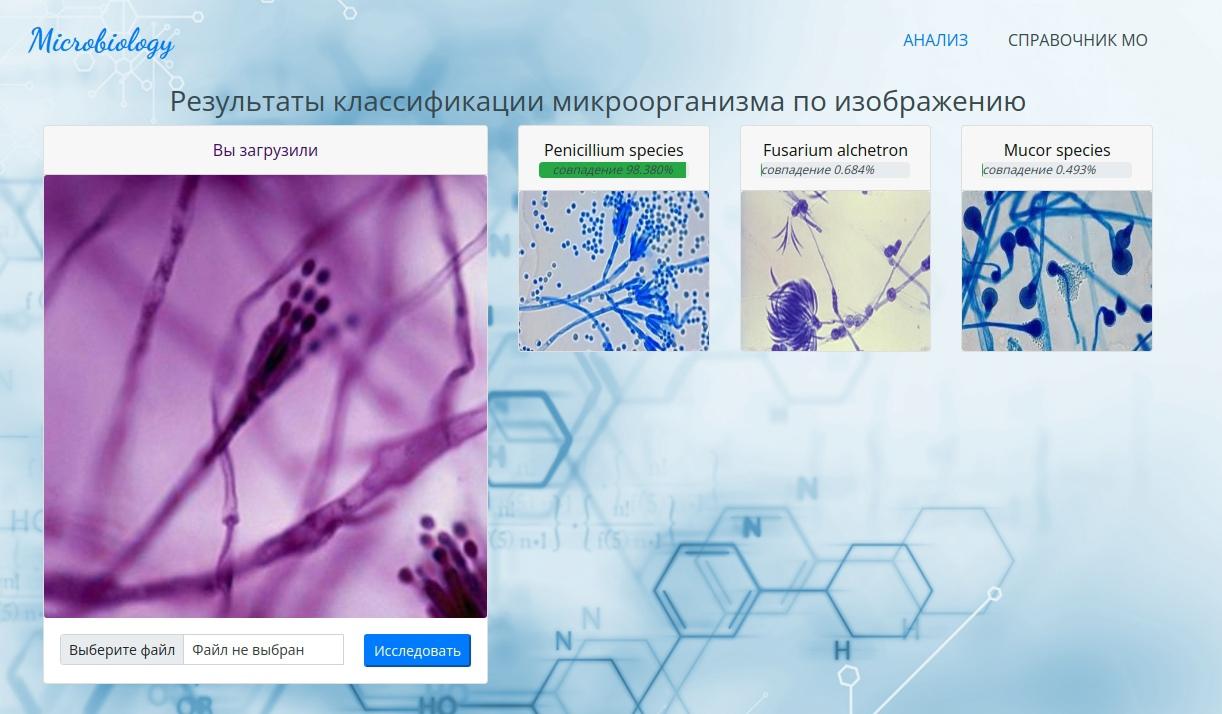
Большую часть нужных мне инструментов я получила во время обучения в магистратуре. Самой сложной частью было не программирование, а оформление результатов работы, потому что программировать для меня — это увлекательно. Программный комплекс я разрабатывала на Python. В каждой программе использован разный набор библиотек. Например, для автоматизированного сбора изображений я взяла библиотеки, которые взаимодействуют с сайтами и имитируют поведение пользователя (BS4, Selenium, Requests). Преобразование изображений проводила с использованием библиотеки CV2. В нее включены реализации моделей компьютерного зрения, в том числе алгоритм поиска ключевых точек ORB, с помощью которого определялись дубликаты в работе. Для обучения нейронной сети использовала среду разработки Google Colaboratory, для графиков визуализаций — библиотеку Matplotlib. Пользовательский интерфейс и серверную часть сайта для взаимодействия с моделью машинного обучения сделала во фреймворке Flask.
Программный комплекс сократит время на биохимические анализы крови, мочи, мазков с кожи. Это значит, что врачи смогут быстрее принимать решения о лечении, предотвращать прогрессирование болезни, а пациенты будут скорее выздоравливать.
Я планирую продолжить работу над классификатором в аспирантуре, сделать его точнее и расширить количество определяемых видов патогенов.

«Концепцию игры через нейроинтерфейс увидел в аниме»
Михаил Стриженов в разработке уже давно, но только на магистратуре начал реализовывать свою мечту — создать игру, которой можно управлять при помощи силы мысли. Прийти к этой идее ему помогло увлечение компьютерными играми и аниме. Михаил рассказал кейс по нейронным сетям в игровой индустрии.
Однажды я посмотрел аниме Sword Art Online, где главный герой управлял игрой с помощью шлема виртуальной реальности. Этот шлем позволял управлять своим персонажем с помощью силы мысли и проектировал игровой мир напрямую в мозг. Мне понравилась концепция, и я решил начать с малого — создать игру на движке UE4, в которой можно было бы управлять частями геймплея с помощью силы мысли.
Я начал проект с изучения нейроинтерфейсов и принципов их работы. В поисках случайно наткнулся ВКонтакте на группу Леонида Питыка, который занимается разработкой экзоскелетов и нейроинтерфейсов. Благодаря нему я узнал, как нейроинтерфейсы работают, а также купил устройство по хорошей цене.
Применение нейронной сети в игровой индустрии пока не очень распространено, поэтому пришлось писать достаточно известным людям в индустрии. Я запрашивал информацию у психофизиолога, заведующего лабораторией нейрофизиологии и нейрокомпьютерных интерфейсов биофака МГУ Александра Каплана, писал главному редактору сайта «Нейроновости» Алексею Паевскому. Алексей помог мне составить список полезных книг по теме.
В магистратуре мы на тот момент проходили распознавание изображений с помощью глубоких нейронных сетей. Я начал думать о том, как эти знания могут помочь мне в реализации мечты. Тогда у меня возникла идея: а что, если переводить данные из мозга в изображения и уже потом классифицировать их и преобразовывать в команды? Индустрия уже давно может хорошо классифицировать изображения, а еще у меня был одноканальный нейроинтерфейс, мне хотелось выжать максимум из подобных устройств. Не каждому человеку захочется надевать на голову огромный шлем, чтобы поиграть в компьютерную игру. А если игра мобильная? Мне хотелось, чтобы даже в метро пользователь мог спокойно, не стесняясь, надеть устройство и поиграть в любимую игру.
Я не первый год в разработке и уже понимаю, что понадобится для работы той или иной технологии. Сразу ясно, что необходимо ПО для взаимодействия с нейроинтерфейсом. Я разрабатывал его на Python с использованием библиотек pySerial, pandas, Pygame, sys, Tkinter, Matplotlib, SciPy, NumPy. Подключение к устройству производится через Bluetooth, отсюда уже становится понятно, какое API нужно использовать. Хорошо, что мой нейроинтерфейс MS-04 разработан по достаточно известной технологии от NeuroSky и у нее есть документация, по которой я понял как необходимо парсить пакеты данных. Для ПО хватит простого текстового редактора, например VS Code. Для исследований использовал ПО Jupyter Notebook.
Готовое ПО для нейроинтерфейса я испытывал на своих друзьях, проверял его по значениям медитации, концентрации внимания, так как по ним проще всего было установить работоспособность программы.
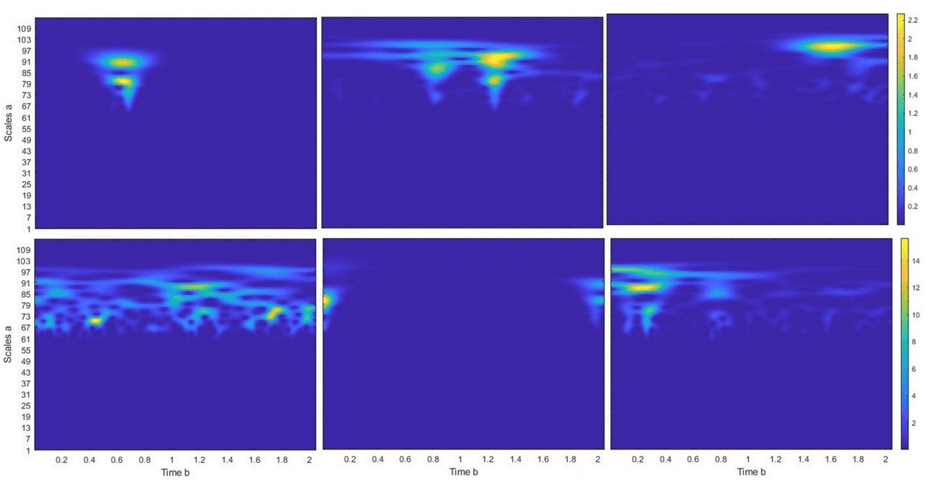
Итогом стал программный комплекс, который собирает данные ЭЭГ с мозга через одноканальный нейроинтерфейс, очищает их от шумов, преобразует в скалограмму и классифицирует изображения. Эту технологию можно использовать не только для игр, но и для управления протезами или умным домом. Мы с командой уже начали разрабатывать под это ПО игру, в которую можно играть с помощью нейроинтерфейса. Будущее игровой индустрии за нейронными сетями.
«Хотелось своей работой повлиять на проблемы родного города»
В Алматы, родном городе Даурена Наипова, очень актуальна проблема загрязнения воздуха. Поэтому Даурен решил создать модель, которая может анализировать и прогнозировать концентрацию вредных веществ и микрочастиц в воздухе.
Все люди имеют право дышать чистым воздухом. Экологические проблемы, особенно загрязнение воздуха, очень актуальны для Алматы. Мне хотелось своей работой повлиять на решение проблемы.
Чтобы собрать данные для анализа, я сначала связался с автором проекта airkaz.org. На его сайте оказалось мало данных для обучения модели. Затем я поехал в госкомпанию «Казгидромет» в Алматы, объяснил, что я студент и пишу диссертацию. Здесь мне удалось получить данные измерений за 2020–2022 годы с 11 станционных пунктов наблюдения за загрязнениями. На этих станциях используются анализаторы от фирмы Hоribа, которые измеряют содержание в воздухе СО (монооксид углерода/угарный газ), SО2 (диоксид серы/сернистый газ), NО (оксид азота), NО2 (Диоксид азота), РM10 и РM2.5.

Я решил начать работу с PM — это смесь твердых частиц и жидких капель диаметром менее 10 микрон. Такие частицы способны проникать глубоко в легкие и оседать там, а PM2.5 могут из легких попадать в кровеносную систему. В соответствии с рекомендациями ВОЗ среднесуточный уровень PM2.5 в воздухе не должен превышать 25 микрограмм на кубический метр. Если в воздухе долго сохраняется повышенное содержание этих частиц, у людей развивается аллергия, дыхательные заболевания, онкология.
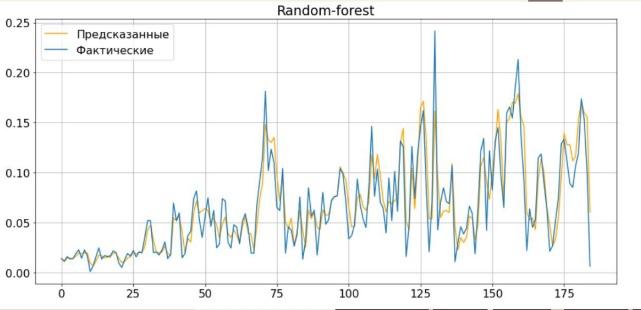
В идеале мне хотелось, чтобы моя модель прогнозировала загрязнение воздуха PM на период до недели. Чтобы выбрать оптимальный алгоритм, я испытал несколько моделей машинного обучения: авторегрессионный метод SARIMA, «Линейную регрессию», ХGBооst, «Случайный лес,» Рrорhеt, двунаправленный LSTM, СNN LSTM, СоnvLSTM. Лучшие метрики качества при наименьшем времени обучения показала модель «Случайный лес». Этот метод создает множество деревьев принятия решений. Каждое дерево алгоритм обучает на отдельной выборке данных, а итоговый прогноз составляет, усредняя прогнозы от всех деревьев.
Программу я реализовал на языке Рythоn 3.8.8 в среде Juрytеr Nоtеbооk с использованием библиотек pаndаs, NumPy, Mаtрlоtlib, Statmodels, Хgbооst, Kerаs, sklеаrn, Рrорhеt. В будущем планирую испытать ее на других данных, попробовать составить более точный прогноз. Хочется, чтобы информация о загрязнении воздуха была доступной наряду с прогнозом погоды.
«Нейросети могут дать направление поиска для инженеров и изобретателей»
Еще в старших классах Сергей Гурылев увлекался теориями решения изобретательских задач (ТРИЗ) — это методология, позволяющая быстрее находить решения для нестандартных технических задач. В магистратуре ему захотелось попробовать сделать что-то похожее, но с помощью нейронных сетей.
Нейросети могут задать направление поиска для инженеров и изобретателей, работающих над усовершенствованием технических систем. Экспертная система на нейросети повысит производительность труда ученых и специалистов, сэкономит время, выявит сложные взаимосвязи на основе больших данных, которые трудно обнаружить при ручной аналитике.
Я решил создать модель, в которую можно было бы ввести техническую задачу на естественном русском языке и получить в ответ описание ее решения. Я начал со сбора патентных данных из открытых источников, использовал базу Яндекс.Патенты. Пожалуй, собрать достаточно данных для обучения языковой модели было самым сложным этапом проекта.
Для генерации решений выбрал большие языковые модели на архитектуре «Трансформер». Для их использования не нужно делать разметку исходных данных, и таким образом всю патентную информацию из открытых источников можно было использовать как есть. Также важно было то, что языковые модели имеют свойство в процессе обучения становиться базами знаний, из которых ответы можно получать, задавая вопросы на естественном языке. Из языковых моделей я выбрал T5, она подходила по типу решаемой задачи — генерации из одной последовательности другой (seq2seq).
Итогом работы стало веб-приложение, в которое можно ввести свою задачу и получить несколько вариантов решений из базы данных существующих изобретений.
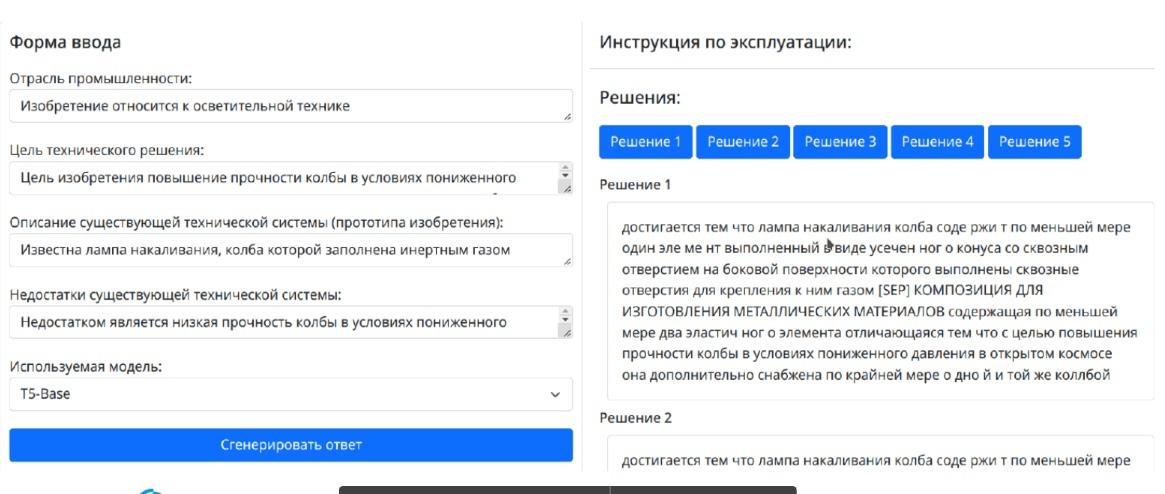
Чтобы развить эту модель, я планирую собрать больше данных для обучения, поэкспериментировать с языковыми моделями больших размеров. Также можно попробовать разные архитектуры моделей. Например, придумать, как добавить в языковую модель информацию о физических и химических явлениях.