

Прийти к удачному решению можно, даже когда кажется, что задача невыполнима. Это доказали студенты магистерской программы «Инженерия машинного обучения», которые лучше всех справились с непростым заданием по отражению кибератак на водоочистительную систему. Они делятся опытом участия в хакатоне, рассказывают, с какими сложностями пришлось столкнуться и как учеба в магистратуре помогла им решить задачу.
Что за хакатон?
Мы вместе с УрФУ и МИСиС провели совместный 8-дневный хакатон на кейсах от партнеров, в том числе от «Уральского центра систем безопасности» и РЖД. Это был первый турнир, который объединил студентов сразу трех направлений: онлайн-магистратур МИСиС «Науки о данных» и УрФУ «Инженерия машинного обучения» и курсов по Data Science в SkillFactory. Всего в хакатоне приняли участие 15 команд. Они решали актуальные задачи на реальных или приближенных к реальным датасетах от партнеров.

Задача: повысить безопасность водоочистительного завода
Нам предложили кейс от «Уральского центра систем безопасности». Сингапурский университет смоделировал стенд, в точности повторяющий работу реального завода по очистке воды. В течение 11 дней работы стенда собирались данные о состоянии всех процессов. В последние четыре дня стенд подвергался двум типам атак: кибератакам через компьютерную сеть и намеренному выводу из строя некоторых физических компонентов. Исходный датасет включал в себя информацию о состоянии оборудования и характеристиках очищаемой воды, сетевой трафик и вручную размеченные моменты атак.

Мы должны были научиться определять атаки для тестового набора данных, используя инструменты машинного обучения. Мы могли использовать статью с подробным описанием исходного набора данных как справочный материал.
Перед нами стояли две задачи. Самая простая — «научить» модель на примере размеченных данных правильно предсказывать атаки. Заранее мы не готовились, потому что не знали, что именно нас ждет. Мы изучили всю вводную информацию, посмотрели, как проходили предыдущие хакатоны. В день старта нам объявили только первую часть задачи.

Мы сделали ее в тот же день: прочитали статью с описанием данных, выяснили, как именно они собирались, поработали с датасетом. Мы проверили и удалили столбцы с отсутствующими или единичными значениями, перевели данные из object в другой формат, удалили дублирующиеся строки, привели некоторые значения к бинарному числовому виду. Все это необходимо, чтобы программам анализа было комфортнее работать с данными.
На следующий день с нами связались организаторы и сообщили о втором, более сложном задании. Теперь от нас требовалось обучить модель предсказывать возможные атаки на данных без разметок, то есть совсем с нуля. Итоговая модель должна предсказывать, в какой момент совершается атака, а в какой нет.
Как мы пришли к решению
Мы применили два метода проверки гипотез: обучение модели с учителем, что решило первую часть задачи, и обучение без учителя, что решило вторую часть задачи. В первом случае создали 10 моделей, из которых эффективность показали три: логистическая регрессия, гауссово распределение и дерево решений. По итогам проверки лучше всего себя проявил метод дерева решений — показатель точности предсказания модели составил 0,999.
Вторая часть задачи свелась к поиску аномалий — выбросов из исходного датасета. Нам нужно было подобрать модель, которая отмечала бы ситуации, не вписывающиеся в нормальный алгоритм работы оборудования. Эффективнее всего с поиском таких аномалий справляются нейронные сети. Тут и была главная сложность: эту тему мы не успели пройти в магистратуре, а значит, и опыта работы с подобными сетями не было.
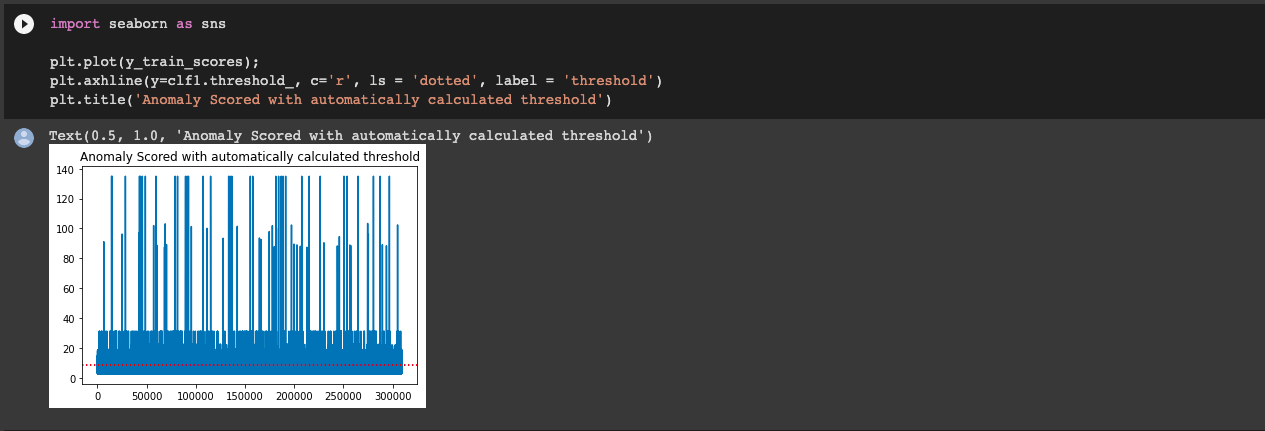
Мы взяли готовую модель — самостоятельно сделать ее мы бы не смогли. Фактически мы круглосуточно искали готовую подходящую библиотеку, нашли, запустили ее, увидели, что результат неплохой, и попытались развить ее: изменяли данные, увеличивали датасет, подбирали параметры, чтобы добиться улучшения итоговой модели. Мы работали с репозиторием нейронной сети инкодера PyOD. Он предлагает вводить настройки вручную, поэтому можно настроить подбор оптимальных гиперпараметров и улучшить предсказательную способность модели.
Когда мы смотрели на доску Miro, где были видны составы других команд, то видели, что в них были уже опытные программисты. При этом в какой-то момент мы заметили, что только наша команда справилась с решением второй части задания. Тогда и появилась надежда на победу. Надо сказать, что все команды хорошо общались между собой, вложили много усилий, отменили учебу и личные дела; кто-то даже не пошел на выпускной.
Учеба в онлайн-магистратуре УрФУ «Инженерия машинного обучения» помогла разобраться с заданием на хакатоне. В магистратуре мы проходили обработку данных, теоретические основы машинного обучения, работу с моделями в Colab — программе, позволяющей писать и запускать код в браузере, — учились настраивать параметры в репозиториях, узнавали, что такое метрики качества, регрессии, кластеризация. Курсы Андрея Созыкина по программной инженерии и проджект-менеджменту очень пригодились при выполнении задания, несмотря на то что мы столкнулись с задачей более высокого уровня.
Советы тем, кто хочет участвовать в хакатонах
- Настройтесь на то, что участие отнимает много времени: личные дела придется временно отодвинуть на второй план. Участникам приходится разбираться в датасетах, выяснять, почему модели не работают, прогнозировать способы их улучшения.
- Готовьтесь к экспериментам: настройку всех наиболее удачных параметров можно делать вручную. Для этого понадобятся не только знания, но и фантазия.
- Любите математику. В основе каждого решения — типовые математические операции, которые нужно комбинировать и развивать в зависимости от конкретной задачи.