

Представьте ситуацию: ваша рекомендательная модель работает на сервере в продакшене и обслуживает тысячи пользователей. Вдруг бизнес-метрики падают, а система начинает выдавать странные предсказания. Как понять, что происходит внутри «черного ящика», не останавливая сервер?
Ответ один — правильно настроенные логи. Без логирования в Python ни одна, даже самая гениальная ML-модель, не выживет в реальном мире. В статье рассказываем, как превратить хаос из print() в профессиональную, структурированную систему логирования. Разберем встроенный модуль logging, уровни и форматтеры, а в конце напишем реальное FastAPI-приложение для нашей ML-модели с модными и современными JSON-логами.
Что такое логирование и почему print() — это зло?
Логирование — это процесс автоматической записи информации о работе программы. Это своеобразный «черный ящик» сервиса, как бортовой самописец в самолете. Пока все хорошо, вы в него не заглядываете, но в случае крушения записи в нем — это единственный способ понять причину сбоя.

Функции логирования:
- Отладка (Debugging) — поиск багов при разработке. Логи пошагово показывают, с какими размерностями тензоров (shapes) работает модель.
- Мониторинг (Monitoring) — наблюдение за здоровьем системы в реальном времени. Например, фиксация времени ответа модели: если оно превышает 500 мс, пора бить тревогу.
- Аудит (Auditing) — запись действий, критически важных и с точки зрения бизнеса, и с точки зрения безопасности. Например: «Пользователь ID 455 запросил генерацию картинки. Списано 2 токена».
Многие новички в Data Science и ML задают резонный вопрос: «Зачем мне учить какой-то сложный модуль logging, если я могу просто написать print(«Модель обучилась»)?»
Давайте разберем, чем логи отличаются от принтов и почему от print() в реальных проектах необходимо избавляться.
Как работает модуль logging в Python
В Python есть встроенный модуль logging. Его не нужно устанавливать через pip — он поставляется вместе с языком. На первый взгляд он кажется переусложненным, поскольку использует объектно-ориентированный подход и состоит из нескольких независимых компонентов.
Давайте разберем их на простом жизненном примере. Представьте, что логирование — это процесс публикации новостей в газете.
- Logger («Логгер»/редактор) — главный объект, с которым вы работаете в коде. Вы передаете ему сообщение. Он оценивает его важность и решает, стоит ли пускать его в работу.
- Filter («Фильтр»/цензор) — дополнительный механизм, отбрасывающий сообщения по сложным правилам. Например, он может пропустить логи только от пользователей из определенного города.
- Handler («Обработчик»/курьер) — доставляет сообщение до конечной точки. Один курьер несет газету в киоск (выводит лог в консоль), другой — везет в архив (записывает в файл), третий — отправляет по электронной почте или шлет алерт в Telegram. У одного логгера может быть много хендлеров!
- Formatter («Форматтер»/верстальщик) — перед выдачей материала верстальщик должен придать ей красивый вид. Он добавляет дату, заголовки и колонки. Форматтер превращает сырое сообщение «Упала база» в структурированную красивую строку: [2023-10-27 15:00:00] — ERROR — db.py — Упала база.
Чтобы лучше понять, как эти компоненты взаимодействуют, давайте посмотрим на диаграмму:
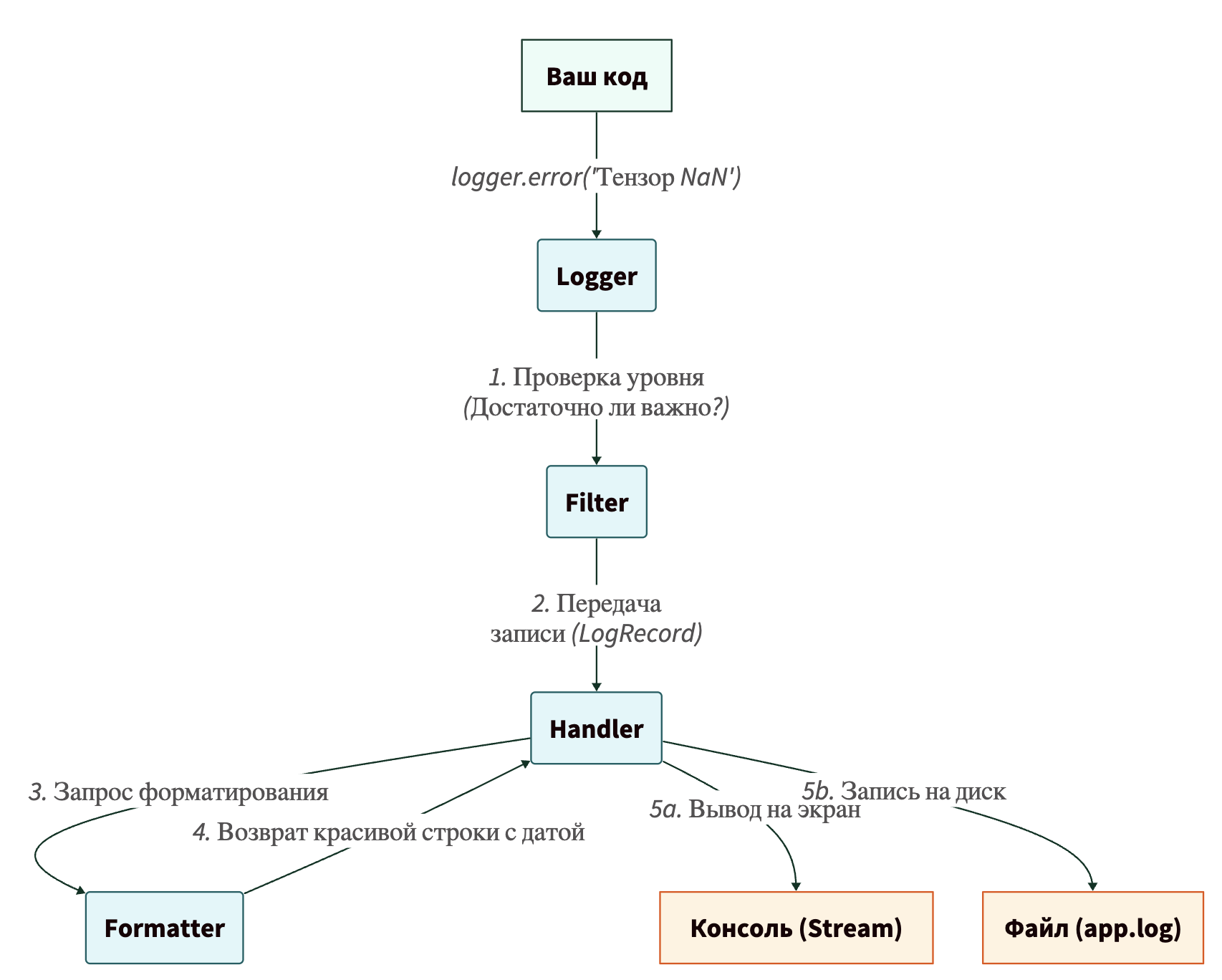
Когда вы пишете logger.info(«Привет»), сообщение проходит через целый конвейер, прежде чем оно появится на экране или в файле. Именно эта модульность делает logging таким мощным: вы можете поменять внешний вид логов (Formatter), не меняя логику их доставки (Handler).
Уровни логирования: от DEBUG до CRITICAL
Уровни логирования — это способ указать важность сообщения. Основных уровней в Python пять, у каждого есть свой числовой вес (от 10 до 50). Это необходимо для того, чтобы задавать пороговый уровень (threshold).
Если вы установите порог логгера на WARNING (30), то все сообщения с меньшим весом (DEBUG и INFO) будут автоматически проигнорированы. Это работает как фейс-контроль в клубе: пускают только тех, чей статус не ниже заданного.
Давайте подробно разберем каждый уровень с примерами из сферы машинного обучения.
DEBUG (Уровень 10)
Для чего нужен: детальная информация, которая будет полезна разработчику при поиске багов.
Пример в ML: вывод размерностей матриц перед умножением, печать сырых ответов от API, значения гиперпараметров при старте.
logger.debug(f"Размерность входного тензора: {x.shape}")
logger.debug(f"Загружен батч номер {batch_idx}")
В продакшене этот уровень всегда отключают, иначе жесткие диски переполнятся за пару часов.
INFO (Уровень 20)
Для чего нужен: подтверждает, что программа работает как ожидалось. Обычные информационные сообщения.
Пример в ML: начало или конец эпохи обучения, успешная загрузка весов модели, запуск сервера.
logger.info(f"Эпоха {epoch}/100 завершена. Loss: {loss:.4f}")
logger.info("Веса модели успешно загружены из s3://bucket/model.pt")
WARNING (Уровень 30)
Для чего нужен: показывает, что произошло что-то неожиданное или что может случиться проблема в будущем. Программа продолжает работать, но на это стоит обратить внимание.
Пример в ML: в датасете попалась картинка битого формата (мы ее пропустили), модель предсказала аномальное значение, заканчивается место на диске.
logger.warning(f"Файл {img_path} поврежден. Пропускаем его при обучении.")
logger.warning("Обнаружен дрейф данных (data drift) в фиче 'age'.")
ERROR (Уровень 40)
Для чего нужен: сообщает, что произошла серьезная проблема, из-за которой программа не смогла выполнить функцию, но само приложение при этом не падает полностью.
Пример в ML: не удалось подключиться к базе данных для записи предсказаний, API стороннего сервиса вернуло ошибку 500.
try:
db.save(prediction)
except ConnectionError as e:
logger.error(f"Не удалось сохранить предсказание в БД: {e}")
Совет из практики: используйте logger.exception(«Текст») внутри блоков except. Это тот же ERROR, но он автоматически прикрепит к логу полный traceback (стек вызовов), что бесценно при поиске причины падения.
CRITICAL (Уровень 50)
Для чего нужен: предупреждает о фатальной ошибке. Программа не может продолжать работу и, скорее всего, сейчас завершится (упадет).
Пример в ML: нехватка видеопамяти (CUDA Out of Memory), удален главный конфигурационный файл.
logger.critical("CUDA Out of Memory! Остановка процесса обучения.")
Разница сред (Dev / Staging / Prod)
Правильная настройка уровней зависит от окружения, где запущен код:
- Dev (на вашем ноутбуке): уровень DEBUG. Вы хотите видеть абсолютно все, чтобы понимать, как работает код.
- Staging (тестовый сервер): уровень INFO. Вы проверяете, как система работает в целом, баги на уровне кода уже отловлены.
- Production (боевой сервер): уровень WARNING или ERROR. На боевом сервере миллионы запросов. Если писать INFO на каждый чих, логи станут нечитаемыми, а сервер будет тратить ресурсы процессора на запись текста, а не на инференс нейросети.

Форматтеры и обработчики (Handlers)
Итак, мы поняли, как создавать сообщения. Теперь давайте настроим то, как они будут выглядеть и куда они будут сохраняться.
Форматтеры (Formatter)
По умолчанию logging выводит сообщения довольно лаконично. Мы можем создать объект Formatter и передать ему строку с нужными плейсхолдерами.
Самые полезные плейсхолдеры:
%(asctime)s— точное время.%(levelname)s— уровень (INFO, ERROR).%(name)s— имя логгера (обычно имя файла модуля).%(filename)sи%(lineno)d— имя файла и номер строки, где вызван лог.%(message)s— само сообщение.
Пример создания форматтера:
import logging # Создаем формат: [Время] | УРОВЕНЬ | Файл:Строка | Сообщение formatter = logging.Formatter( fmt='[%(asctime)s] | %(levelname)-8s | %(filename)s:%(lineno)d | %(message)s', datefmt='%Y-%m-%d %H:%M:%S' )
Обратите внимание на %(levelname)-8s — минус восемь означает, что слово будет выровнено по левому краю и займет ровно восемь символов. Это делает строки в консоли аккуратными и удобными для просмотра.
Обработчики (Handlers)
Чтобы логгер начал куда-то писать, ему нужно добавить обработчики.
StreamHandler («Вывод в консоль») – это аналог print(). Пишет в стандартный поток вывода (stdout) или ошибок (stderr).
console_handler = logging.StreamHandler() console_handler.setFormatter(formatter)
FileHandler («Запись в файл») пишет логи в текстовый файл на диске.
file_handler = logging.FileHandler('my_model_training.log', mode='a', encoding='utf-8')
file_handler.setFormatter(formatter)
Проблема переполнения диска и ротация логов
Представьте, что ваш FastAPI-сервер с ML-моделью работает год. Если использовать обычный FileHandler, ваш файл app.log вырастет до 50 Гигабайт. Его невозможно будет открыть ни в одном текстовом редакторе, а когда закончится место, сервер просто откажет.
Для решения этой проблемы применяют ротацию логов (Log Rotation). Суть в том, что когда файл достигает определенного размера (или когда проходит определенное время), он архивируется, а потом создается новый пустой файл.
В Python для этого есть два отличных хендлера:
- RotatingFileHandler: ротация по размеру. Например, файл дорастает до 10 МБ, переименовывается в app.log.1, а запись продолжается в новый app.log. Можно хранить, например, только пять последних файлов (остальные удаляются).
- TimedRotatingFileHandler: ротация по времени. Создает новый файл каждый день в полночь.
Пример ротации по размеру:
from logging.handlers import RotatingFileHandler
# Максимум 5 файлов по 10 Мегабайт каждый
rotating_handler = RotatingFileHandler(
'production.log',
maxBytes=10*1024*1024, # 10 MB
backupCount=5,
encoding='utf-8'
)
rotating_handler.setFormatter(formatter)
# Собираем все вместе
logger = logging.getLogger("ML_Logger")
logger.setLevel(logging.DEBUG)
logger.addHandler(console_handler)
logger.addHandler(rotating_handler)
logger.info("Логгер успешно настроен! Теперь мы пишем и в консоль, и в файл с ротацией.")
Структурные логи (Structured Logging) и почему JSON рулит
До этого момента мы говорили про логи в формате обычного текста (plain text). Для человека читать строку вида [2023-10-27 15:00] INFO user_id=123 bought item_id=456 не составляет труда.
Но в современном продакшене логи читают не люди, а машины. Когда работает кластер из 10 серверов, на каждом из которых крутится по пять ML-моделей, они генерируют миллионы строк логов в минуту. Эти логи собираются специальными агентами(Filebeat, Fluentd) и отправляются в централизованные системы хранения и анализа — ELK (Elasticsearch, Logstash, Kibana), Loki или облачные Datadog.
Если вы отправите туда текстовую строку и захотите найти «все покупки пользователя 123», вам придется писать сложные регулярные выражения (Regex), чтобы вытащить ID из текста. Это медленно, больно и неэффективно.
Решение — структурированное логирование. При таком подходе каждый лог — это не строка текста, а словарь в формате JSON.
Сравните:
- Обычный лог:
2023-10-27 15:00:00 INFO Model v1.2 predicted class 4 with probability 0.98 for image img_88.jpg - Структурный лог (JSON):
{
"timestamp": "2023-10-27T15:00:00Z",
"level": "INFO",
"model_version": "v1.2",
"predicted_class": 4,
"probability": 0.98,
"image_id": "img_88.jpg",
"message": "Prediction successful"
}
В системе вроде Kibana или Datadog вы сможете за секунду сделать запрос: level == «INFO» AND probability < 0.5 AND model_version == «v1.2». Вы сможете строить графики распределения вероятностей прямо по логам! Для ML-инженера это просто магия, позволяющая мониторить деградацию модели (data drift) в реальном времени.
Как сделать JSON-логи в Python?
Есть два популярных пути:
- Использовать библиотеку python-json-logger (она работает поверх стандартного logging).
- Использовать продвинутую стороннюю библиотеку structlog.
Библиотека structlog — это индустриальный стандарт. Она позволяет «привязывать» (bind) контекст к логгеру. Например, в начале функции вы привязываете request_id, а потом все последующие логи внутри этой функции автоматически будут содержать этот идентификатор.
Пример работы со structlog:
# pip install structlog
import structlog
# Настраиваем вывод в формате JSON
structlog.configure(
processors=[
structlog.processors.TimeStamper(fmt="iso"),
structlog.processors.JSONRenderer()
]
)
log = structlog.get_logger()
# Добавляем контекст
log = log.bind(model_version="YOLOv8", environment="prod")
# Пишем лог
log.info("inference_started", image_size=(640, 640), batch_size=8)
# Вывод: {"model_version": "YOLOv8", "environment": "prod", "image_size": [640, 640], "batch_size": 8, "event": "inference_started", "timestamp": "2023-10-27T15:00:00Z"}
DevOps-инженеры будут носить вас на руках, если вы начнете отдавать им логи в таком формате.
Практическая часть: собираем реальный пример с FastAPI
Теория — это хорошо, но давайте применим знания на практике. Напишем микросервис на FastAPI, который эмулирует работу ML-модели.
Мы настроим логирование самым правильным способом — через конфигурационный словарь (logging.config.dictConfig). Это позволяет описать все логгеры, форматтеры и хендлеры в одном месте (часто это выносят в отдельный logging.yaml или logging.json файл).
Наш план:
- Создать два форматтера: один — для локальной разработки (красивый цветной текст), второй — для продакшена (JSON).
- Настроить хендлер для консоли.
- Перехватить дефолтные логи самого FastAPI (сервера Uvicorn), чтобы они тоже подчинялись нашим правилам.
Для работы понадобится установить pip install fastapi uvicorn python-json-logger.
Создадим файл app.py:
import logging
import logging.config
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import random
import time
# 1. Описываем конфигурацию логирования в виде словаря
LOGGING_CONFIG = {
"version": 1,
"disable_existing_loggers": False, # Важно! Не отключаем логи FastAPI/Uvicorn
"formatters": {
# Форматтер для локальной разработки (читаемый текст)
"default": {
"format": "[%(asctime)s] %(levelname)s in %(module)s: %(message)s",
"datefmt": "%Y-%m-%d %H:%M:%S"
},
# Форматтер для продакшена (JSON)
"json": {
"()": "pythonjsonlogger.jsonlogger.JsonFormatter",
"format": "%(asctime)s %(levelname)s %(module)s %(message)s"
}
},
"handlers": {
# Вывод в консоль
"console": {
"class": "logging.StreamHandler",
"formatter": "default", # Для продакшена поменяйте на "json"
"stream": "ext://sys.stdout"
},
# Ротация в файл (полезно, если нет систем сбора логов типа ELK)
"file": {
"class": "logging.handlers.RotatingFileHandler",
"formatter": "json", # В файл всегда пишем JSON
"filename": "ml_service.log",
"maxBytes": 5000000, # 5 MB
"backupCount": 3
}
},
"loggers": {
# Наш основной логгер для приложения
"ml_app": {
"handlers": ["console", "file"],
"level": "DEBUG",
"propagate": False
},
# Переопределяем логи сервера Uvicorn, чтобы они писались в наш файл
"uvicorn.access": {
"handlers": ["console", "file"],
"level": "INFO",
"propagate": False
}
}
}
# Применяем конфигурацию
logging.config.dictConfig(LOGGING_CONFIG)
# Получаем наш логгер
logger = logging.getLogger("ml_app")
app = FastAPI(title="ML Prediction Service")
class PredictionRequest(BaseModel):
user_id: int
text: str
@app.on_event("startup")
async def startup_event():
# INFO - так как это важное событие жизненного цикла
logger.info("Запуск ML-сервиса. Загрузка весов модели (эмуляция)...")
time.sleep(1)
logger.info("Модель успешно загружена в память.")
@app.post("/predict")
async def predict(request: PredictionRequest):
# Привязываем user_id к логам, чтобы понимать, чей это запрос
logger.debug(f"Получен запрос на предсказание. Текст: '{request.text}'", extra={"user_id": request.user_id})
if len(request.text) < 3:
# WARNING - пользователь ввел чушь, но сервер не сломался
logger.warning("Слишком короткий текст для предсказания", extra={"user_id": request.user_id})
raise HTTPException(status_code=400, detail="Текст должен быть длиннее 3 символов")
try:
# Эмуляция работы нейросети (иногда она падает)
start_time = time.time()
if random.random() < 0.1: # 10% шанс ошибки
raise ValueError("Внутренняя ошибка тензорных вычислений (NaN)")
score = random.uniform(0.1, 0.99)
process_time = round((time.time() - start_time) * 1000, 2)
# INFO - успешный результат работы бизнес-логики
logger.info(
"Предсказание успешно сгенерировано",
extra={
"user_id": request.user_id,
"prediction_score": score,
"process_time_ms": process_time
}
)
return {"score": score}
except Exception as e:
# ERROR - используем exc_info=True (или logger.exception), чтобы записать Traceback
logger.error(f"Ошибка при инференсе модели: {e}", exc_info=True, extra={"user_id": request.user_id})
raise HTTPException(status_code=500, detail="Внутренняя ошибка сервера")
Как это работает:
- Мы использовали dictConfig. Это самый чистый способ настройки. Если вы захотите переключить консоль на JSON перед деплоем на сервер, вам нужно будет изменить всего одно слово в словаре: «formatter»: «default» на «formatter»: «json».
- Мы используем аргумент extra={…} в логах. Библиотека python-json-logger автоматически подхватит эти ключи и добавит их в итоговый JSON. Таким образом, в файле ml_service.log мы получим структурированные данные со временем ответа и оценкой модели.
- При ошибке вычислений (эмуляция 10% падений) мы используем exc_info=True. Это гарантирует, что в лог попадет полный стек вызовов, и вы сможете найти строку кода, где произошла математическая ошибка (например, деление на ноль в лоссе).
Запустите этот код командой uvicorn app:app —reload и поделайте запросы через http://localhost:8000/docs. Посмотрите, как красиво логи выводятся в консоль и как профессионально они складываются в JSON-файл ml_service.log.
Логирование в Python: коротко о главном
Логирование — это не просто скучная обязанность программиста. Для специалиста по машинному обучению и Data Science логи — это глаза и уши вашей модели в реальном мире.
Как ими пользоваться:
- Забудьте про print() в любом коде, который выходит за рамки Jupyter Notebook. Приучайте себя сразу импортировать logging.
- Используйте уровни с умом. DEBUG — для разработки, INFO — для важных этапов (начало/конец эпохи), WARNING — для странностей в данных, ERROR — для перехвата исключений.
- Не забывайте про ротацию. Если вы пишете логи в файл, всегда используйте RotatingFileHandler. Иначе однажды ночью ваш сервер упадет из-за нехватки места на диске.
- Структурируйте логи для продакшена. Переход от обычного текста к JSON (python-json-logger или structlog) — это квантовый скачок в качестве мониторинга. Вы сможете визуализировать работу вашей модели в дашбордах и находить причины аномалий за секунды.
Настройка качественного логирования занимает от силы 20 минут в начале проекта, но экономит десятки часов нервной отладки в будущем. Любите свои модели, пишите хороший код и пусть ваши логи всегда состоят только из уровня INFO!