


В статье рассказываем, зачем обрабатывать данные перед загрузкой в модель, как провести предобработку Data Preparation и какие инструменты использовать.
Составить инструкцию помогла Мария Жарова, Data Scientist компании Wildberries.
Что такое предобработка данных
Предобработка — это подготовка набора данных перед загрузкой в модель. Данные в исходном виде часто содержат артефакты, такие как шум, пропуски или дубликаты, которые усложняют их анализ и снижают качество работы алгоритмов.

Артефакты могут появляться по разным причинам:
- Человеческий фактор: ошибки при ручном вводе — опечатки, пропуски или неправильные значения.
- Неполные данные: информация может быть недоступна, например, сотрудник не указал свое место проживания.
- Ошибки при сборе: сбои в автоматических системах, например временные проблемы с сетью, из-за чего часть данных теряется.
- Объединение данных из разных источников: разные форматы или отсутствие значений при объединении нескольких баз.
- Технические ограничения: например, система принимает только положительные числа, а передали отрицательное значение.
- Устаревшая информация: данные не обновляются вовремя, из-за чего информация устаревает.
- Ошибки при миграции: повреждение или потеря данных при переносе из одной системы в другую.
Пример датасета с артефактами:
| ID | Имя | Возраст | Зарплата | Город | Дата приема | Отдел |
| 1 | Иванов Иван | 28 | 100000 | Москва | 2018-05-20 | Продажи |
| 2 | NaN | NaN | 60000 | Санкт-Петербург | 2019-03-15 | Маркетинг |
| 3 | Ольга Петрова | 35 | -1500 | Новосибирск | NaN | Разработка |
| 4 | Андрей Сидоров | NaN | 70000 | Неизвестно | 2021-11-10 | NaN |
| 5 | NaN | 45 | 80000 | Казань | 2020-08-01 | HR |
| 6 | Елена Белова | 29 | NaN | NaN | 2017-09-23 | Продажи |
Пропуски: пропущенные значения в столбцах: Имя, Возраст, Зарплата, Город, Дата приема на работу, Отдел (NaN).
Ошибки в данных: отрицательное значение в столбце Зарплата (значение -1500).
Неоднородные данные:
- В столбце Город указан заполнитель «Неизвестно» вместо названия города.
- Разное представление пропущенных или неизвестных значений:
- NaN (Not a Number) автоматически используется в некоторых системах, например при выгрузке данных из баз или при считывании в библиотеке для анализа данных (такой как pandas);
- «Неизвестно» — это пример текстового заполнителя, который вводят вручную, когда нет информации, — его также нужно обрабатывать как пропуск.
Предобработка помогает устранить все эти проблемы, а в результате — улучшить качество данных и повысить точность модели.
Как автоматизировать предобработку данных
Автоматизация предобработки сокращает время на рутинные задачи и снижает риск ошибок.
Для этого можно использовать различные инструменты и подходы:
- Использование библиотек для предобработки: библиотеки, такие как Scikit-Learn, предоставляют множество готовых инструментов: например, SimpleImputer для заполнения пропусков, StandardScaler для масштабирования, LabelEncoder для кодирования категориальных данных.
Эти инструменты можно объединить в Pipeline — последовательность шагов для автоматической обработки данных.
- Pipeline из Scikit-Learn: объединяет несколько этапов предобработки в один процесс, облегчая повторное применение тех же шагов к разным наборам данных и делая код более структурированным и понятным.
Пример: создание Pipeline для автоматического выполнения всех необходимых шагов предобработки, таких как заполнение пропусков, масштабирование и кодирование признаков.
- Автоматизация с помощью библиотек для подготовки данных:
- Pandas: часто используют для ручной предобработки, но можно создать функции, которые автоматически заполняют пропуски, масштабируют данные и кодируют признаки.
- Feature-engine: библиотека с удобными функциями для автоматизации задач: создание новых признаков, кодирование категорий и работа с выбросами.
- Polars: новая библиотека для высокоэффективной работы с данными и их анализа на Python, альтернатива Pandas для работы с очень большими объемами данных.
- Другие подходы:
- Платформы для машинного обучения: инструменты AutoML, такие как H2O.ai, LAMA и TPOT, автоматически подбирают модели и выполняют предобработку данных, что упрощает процесс для пользователя.
- Написание собственных функций: можно написать функции для типовых задач, например заполнения пропусков медианой или удаления выбросов, и использовать их каждый раз для обработки данных. Это экономит время и обеспечивает единообразие.
Как проводится Data Preparation — на примере
Предобработка данных — это главный этап подготовки набора данных перед загрузкой в модель машинного обучения.
На каждом этапе можно выполнить ручную обработку, использовать автоматические инструменты для упрощения задачи или комбинировать оба способа.
Представим, что у нас есть набор данных о квартирах:
| ID | Площадь (кв. м) | Число комнат | Возраст дома (лет) | Стоимость (млн руб.) | Тип недвижимости | Район |
| 1 | 80 | 3 | 20 | 8 | квартира | А |
| 2 | 100 | NaN | 150 | 10 | дом | Б |
| 3 | 2000 | 2 | NaN | 50 | квартира | А |
| 4 | 100 | 4 | 30 | 6 | апартаменты | В |
| 5 | 150 | 3 | 5 | NaN | дом | Б |
| 6 | 500 | 5 | 300 | 70 | квартира | А |
| 7 | 100 | 3 | 25 | 14 | дом | Б |
| 8 | 80 | 3 | -5 | 8 | апартаменты | В |
| 9 | -150 | 3 | 15 | 12 | дом | Б |
| 10 | 100 | 3 | 25 | 14 | квартира | А |
Разберем поэтапно обработку данных с использованием информации выше.
Используем следующие инструменты:
- Pandas: библиотека для работы с таблицами данных (DataFrame), очистки данных, заполнения пропусков, удаления дубликатов и фильтрации данных.
- Scikit-Learn: библиотека для машинного обучения. Включает инструменты для предобработки данных, которые используются для заполнения пропусков, масштабирования признаков и работы с выбросами.
- Matplotlib и Seaborn: библиотеки для визуализации данных, используемые для анализа, в том числе обнаружения выбросов и шумов.
- Numpy: библиотека для быстрой и эффективной работы с числовыми массивами, включая сложные математические преобразования.
Этап 1 — сбор и анализ данных
На первом этапе важно собрать данные и проанализировать их качество, так как это напрямую влияет на качество модели. На этом этапе можно понять структуру данных, выявить проблемы (пропуски, дубликаты, выбросы) и спланировать методы их устранения.
Сбор данных вручную. Данные можно получить из различных источников: баз данных, веб-скрейпинга, API, CSV-файлов и др. Например, вы можете загрузить данные с использованием Pandas.
Пример кода для загрузки данных:
import pandas as pd
# Создание DataFrame с данными о недвижимости
data = {
'ID': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'Площадь (кв. м)': [80, 100, 2000, None, 150, 500, 120, 80, -150, 100],
'Число комнат': [3, None, 2, 4, 3, 5, 3, 3, 3, 3],
'Возраст дома (лет)': [20, 150, None, 30, 5, 300, 25, -5, 15, 25],
'Цена (млн руб.)': [8, 10, 50, 6, None, 70, 14, 8, 12, 14],
'Тип недвижимости': ['квартира', 'дом', 'квартира', 'апартаменты', 'дом', 'квартира', 'дом', 'апартаменты', 'дом', 'квартира'],
'Район': ['А', 'Б', 'А', 'В', 'Б', 'А', 'Б', 'В', 'Б', 'А']
}
df = pd.DataFrame(data)Автоматизированный сбор данных. Сбор данных можно автоматизировать, чтобы уменьшить время и трудозатраты на их подготовку. Примеры автоматизации включают:
- API-запросы: использование библиотек, таких как requests, для получения данных по API.
import requests
import pandas as pd
response = requests.get('https://api.example.com/data')
data = response.json()
df = pd.DataFrame(data)- Веб-скраппинг: использование библиотек, таких как BeautifulSoup и Selenium, для сбора данных с веб-сайтов.
from bs4 import BeautifulSoup
import requests
url = 'https://example.com/data'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Пример извлечения данных и создания DataFrame
table_data = soup.find_all('table')[0] # Найти таблицу
df = pd.read_html(str(table_data))[0]- Интеграцию с базами данных: использование библиотек, таких как SQLAlchemy или pyodbc, для подключения и извлечения данных из баз.
from sqlalchemy import create_engine
import pandas as pd
engine = create_engine('sqlite:///example.db')
df = pd.read_sql('SELECT * FROM data_table', con=engine)Анализ данных
После сбора нужно провести анализ для понимания структуры данных и выявления проблем, которые требуют предобработки.
Можно использовать готовые функции из Pandas для того, чтобы выявить проблемы, такие как пропуски или выбросы:
- head() выводит первые несколько строк таблицы, чтобы вы могли примерно ознакомиться с содержимым данных.
- info() показывает количество непустых значений в каждом столбце и тип данных в них (целые числа, вещественные числа и т. д.).
- describe() предоставляет сводную статистику. Для числовых признаков — среднее, стандартное отклонение, минимальное и максимальное значения; для категориальных — количество уникальных категорий и частота самой топовой.
Пример кода для анализа данных:
# Просмотр первых строк таблицы
display(df.head())
# Получение информации о типах данных и наличии пропусков
display(df.info())
# Статистическое описание числовых признаков
display(df.describe())
# Проверка на наличие дубликатов
duplicates_count = df.duplicated().sum()
print(f"\nКоличество дубликатов: {duplicates_count}")Важно: display можно заменить на print, если вы работаете не в Jupyter-notebook, но тогда вывод на экран будет не таким наглядным.
На этом этапе можно найти следующие проблемы, которые потребуют дальнейшей предобработки:
- Пропуски. В столбцах «Площадь (кв. м)», «Число комнат», «Возраст дома (лет)» и «Цена (млн руб.)» — пропуски, которые нужно заполнить или обработать.
- Некорректные значения:
- В столбце «Возраст дома (лет)» присутствует значение -5.
- В столбце «Площадь (кв. м)» указано ошибочное отрицательное значение -150.
- Выбросы:
- Значения, такие как площадь 2000 кв. м и 500 кв. м, подозрительно высокие для квартир и могут считаться выбросами.
- Цена 70 млн руб. также выделяется среди остальных значений, что может указывать на выброс.
Этап 2 — очистка данных
После анализа данных можно приступать к очистке. Цель этапа — устранить проблемы, такие как пропуски, ошибки и выбросы, чтобы повысить качество датасета и, как следствие, предсказания модели.
Ручная очистка данных. Для удаления дубликатов или строк с ошибками можно использовать методы Pandas, для работы с NaN-значениями пригодится Numpy.
Пример:
import numpy as np
# Удаление дубликатов
df = df.drop_duplicates()
# Удаление строк с некорректным значением возраста
df = df[df['Возраст дома (лет)'] >= 0]
# Замена ошибочных значений на NaN для последующей обработки
df.loc[df['Площадь (кв. м)'] < 0, 'Площадь (кв. м)'] = np.nanАвтоматизация очистки данных
Для автоматической очистки данных можно использовать библиотеку Scikit-Learn — например, SimpleImputer для заполнения пропусков.
Если у вас есть ошибочные значения, которые удобнее обработать как пропуски, перед использованием SimpleImputer их нужно заменить на NaN.
В этом случае пример кода будет выглядеть так:
from sklearn.impute import SimpleImputer
# Замена отрицательных значений на NaN
df.loc[df['Площадь (кв. м)'] < 0, 'Площадь (кв. м)'] = np.nan
# Использование SimpleImputer для заполнения пропусков
imputer = SimpleImputer(strategy='mean')
df[['Площадь (кв. м)', 'Число комнат', 'Возраст дома (лет)']] = imputer.fit_transform(df[['Площадь (кв. м)', 'Число комнат', 'Возраст дома (лет)']])Вообще, пропуски в данных могут возникать по разным причинам: отсутствие информации, ошибки при сборе данных и т. д. Для их обработки можно использовать еще несколько подходов.
Удаление строк или столбцов с пропусками
Если пропуски присутствуют в небольшом количестве в одном признаке и не содержат важной информации, такие строки можно просто удалить. А если их много в одном столбце — его тоже можно полностью удалить.
# Удаление всех строк, содержащих хотя бы один пропуск
df = df.dropna()
# Удаление всех столбцов, содержащих хотя бы один пропуск
df = df.dropna(axis=1)Этот метод используется, когда данных достаточно и потеря нескольких строк не повлияет на анализ.
Заполнение пропусков
Среднее или медиана: для числовых данных можно использовать среднее значение или медиану. Упрощенная альтернатива SimpleImputer — метод filina из библиотеки pandas.
Пример:
# Заполнение пропусков средним значением
df['Площадь (кв. м)'] = df['Площадь (кв. м)'].fillna(df['Площадь (кв. м)'].mean())Медиану стоит применять, когда данные содержат выбросы, потому что она менее чувствительна к экстремальным значениям. Например, для признака «зарплата» медиана подходит лучше среднего, если в данных встречаются несколько аномально высоких зарплат.
Метод ближайших соседей (KNN): учитывает значения признаков ближайших объектов для заполнения пропусков. Перед применением метода нужно закодировать или удалить категориальные признаки, потому что он работает только с числовыми.
Пример:
from sklearn.impute import KNNImputer
from sklearn.preprocessing import LabelEncoder
# Кодирование категориального признака
encoder = LabelEncoder()
df['Тип недвижимости'] = encoder.fit_transform(df['Тип недвижимости'])
# Заполнение пропусков с использованием KNNImputer
imputer = KNNImputer(n_neighbors=2)
df[['Площадь (кв. м)', 'Число комнат', 'Возраст дома (лет)', 'Цена (млн руб.)']] = imputer.fit_transform(df[['Площадь (кв. м)', 'Число комнат', 'Возраст дома (лет)', 'Цена (млн руб.)']])Метод полезен, когда значения признаков взаимосвязаны и пропуски можно логически предсказать на основе других значений.
Заполнение специальными значениями: например, можно заполнить пропуски значением «неизвестно» для категориальных признаков или «0» для числовых, если это имеет смысл в контексте данных.
Обработка выбросов и устранение шумов
Выбросы — это значения, которые сильно отличаются от остальных данных. Они могут находиться далеко от большинства и обычно возникают из-за ошибок сбора данных или редких, необычных событий.
Шумы — это случайные или непреднамеренные вариации значений, которые не содержат полезной информации. Могут возникать из-за ошибок измерения, проблем с оборудованием, влияния внешних факторов или просто случайных изменений, которые не связаны с основной задачей анализа.
Шумы и выбросы могут привести к неверным выводам модели, затрудняя выделение значимых признаков. Например, если использовать алгоритм линейной регрессии — он пытается найти линию, которая минимизирует ошибки между прогнозом и фактом. Выбросы, которые сильно отличаются от остальных данных, могут «тянуть» эту линию и искажать результат.
Методы работы с выбросами
Обнаружение выбросов
- Boxplot («Ящик с усами»): используется для визуализации выбросов. Выбросы отображаются как точки, находящиеся за пределами «усов» графика.
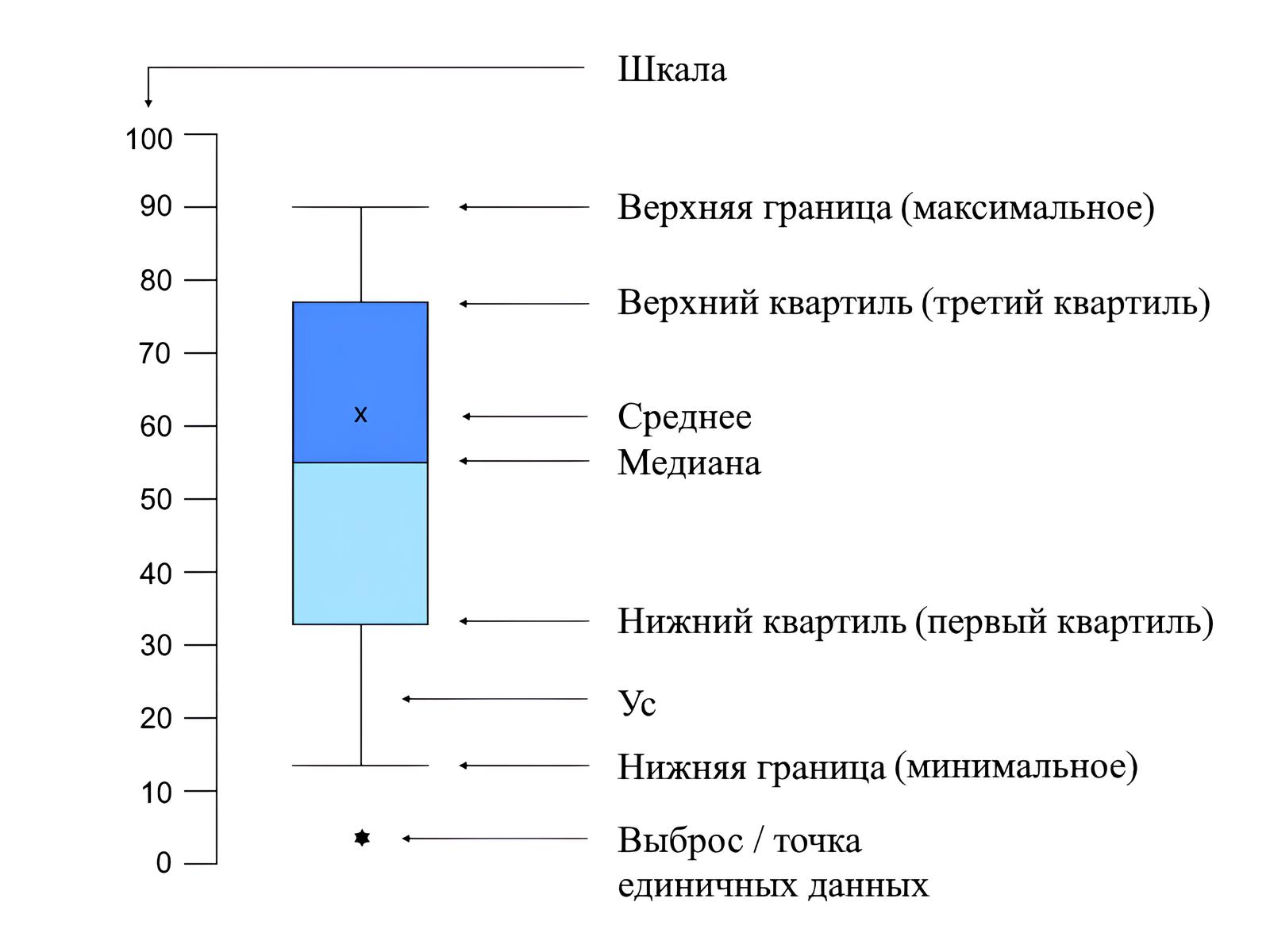
Пример:
import matplotlib.pyplot as plt
import seaborn as sns
# Визуализация выбросов с помощью boxplot
plt.figure(figsize=(8, 5))
sns.boxplot(x=df['Цена (млн руб.)'])
plt.title('Выбросы в цене квартир')
plt.show()Такой график поможет быстро оценить, какие значения сильно выбиваются из общего распределения
- Метод межквартильного размаха (IQR): статистический метод, который используется для определения выбросов. Значения за пределами диапазона [Q1 − 1.5 * IQR, Q3 + 1.5 * IQR] считаются выбросами. Если данные содержат множество выбросов, можно использовать более жесткое ограничение, например, [Q1 − 3 * IQR, Q3 + 3 * IQR].
Пример:
# Определение границ для выбросов
Q1 = df['Цена (млн руб.)'].quantile(0.25)
Q3 = df['Цена (млн руб.)'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# Обнаружение выбросов
outliers = df[(df['Цена (млн руб.)'] < lower_bound) | (df['Цена (млн руб.)'] > upper_bound)]
print(f"Количество выбросов: {len(выбросы)}")
print("Найдены выбросы:\n", outliers)Обработка выбросов
- Удаление выбросов: если выбросы — это результат ошибок или они не отражают реальные данные, их можно удалить.
Пример:
# Удаление выбросов
df = df[(df['Цена (млн руб.)'] >= lower_bound) & (df['Цена (млн руб.)'] <= upper_bound)]- Трансформация данных: если выбросы связаны с высокой вариативностью признака, можно использовать логарифмическую или другую нелинейную трансформацию.
Обратите внимание, что логарифмическая трансформация применима только к положительным значениям.
Пример:
# Логарифмическая трансформация признака
df['Цена (млн руб.)'] = df['Цена (млн руб.)'].apply(lambda x: np.log1p(x) if x > 0 else x)Логарифмирование помогает уменьшить влияние больших значений и сделать распределение данных более симметричным.
- Использование робастных моделей. Некоторые модели устойчивы к выбросам, что помогает минимизировать их влияние. В отличие от линейной регрессии, робастные методы, такие как RANSAC, адаптируются к выбросам, исключая аномальные точки при создании модели.
Пример:
from sklearn.linear_model import RANSACRegressor
from sklearn.linear_model import LinearRegression
# Пример использования робастной регрессии
model = RANSACRegressor(base_estimator=LinearRegression(), random_state=42)
X = df[['Площадь (кв. м)', 'Число комнат', 'Возраст дома (лет)']]
y = df['Цена (млн руб.)']
model.fit(X, y)Методы обработки шумов
Обнаружение шумов
Шумы могут быть обнаружены с помощью визуализации данных. Методы вроде анализа временных графиков помогают увидеть колебания, которые можно считать шумом. Для временных рядов можно использовать скользящие средние, чтобы лучше понять общие тренды и отбросить случайные колебания.
Сглаживание данных
Сглаживание данных используется, чтобы уменьшить влияние случайных колебаний. Это особенно полезно для временных рядов, где присутствуют нерегулярные скачки. Сглаживание можно выполнить с помощью скользящего среднего.
Удаление или сглаживание шумов
Применение фильтров, таких как медианный или фильтр скользящего среднего, помогает сгладить шумы, особенно во временных данных. Первый эффективен для устранения выбросов, а второй подходит для сглаживания временных данных.
Пример:
# Пример сглаживания с использованием скользящего среднего
df['Цена (млн руб.)'] = df['Цена (млн руб.)'].rolling(window=3, min_periods=1).mean()Этот код сглаживает цену, используя среднее значение соседних трех элементов. Параметр min_periods=1 помогает избежать появления NaN в начале ряда.
Устранение аномальных значений
- Робастные методы. В случае табличных данных шумы могут быть похожи на выбросы. Например, незначительные ошибки, такие как «цена на 5% выше или ниже ожидаемого значения», можно сгладить с помощью робастных методов, которые менее чувствительны к небольшим отклонениям. Также такие методы, как RANSAC или Theil-Sen Estimator, помогают уменьшить влияние выбросов. Они присваивают меньший вес значениям, которые сильно отклоняются от общей тенденции.
- Сглаживание кривых (Spline Fitting). Подходит для данных с трендом, которые содержат случайные колебания. Сплайны представляют данные в виде гладкой функции, чтобы устранить мелкие шумы и сохранить основную структуру, в первую очередь используются для аппроксимации данных.

Этап 3 — кодирование категориальных данных
На этом этапе категориальные признаки преобразуются в числовую форму, потому что большинство алгоритмов машинного обучения могут работать только с числовыми данными. В нашем датасете есть два категориальных признака: «Тип недвижимости» и «Район».
Для этого используют несколько методов.
Label Encoding
Метод, при котором каждой категории присваивается уникальное числовое значение. Подходит для категорий с естественным порядком (например, «низкий», «средний», «высокий») или небольшим количеством вариантов.
Важно: если порядок категорий не имеет значения, использование Label Encoding может привести к некорректной интерпретации данных моделью.
Пример кода:
from sklearn.preprocessing import LabelEncoder
# Применение Label Encoding к столбцу "Тип недвижимости" (если категории имеют естественный порядок)
encoder = LabelEncoder()
df['Тип недвижимости'] = encoder.fit_transform(df['Тип недвижимости'])
print(df[['ID', 'Тип недвижимости']])В результате применения LabelEncoder категории «квартира», «дом», «апартаменты» будут преобразованы в числовые значения, например 0, 1, 2.
One-Hot Encoding
Метод, который для каждой категории создает отдельный бинарный признак, указывающий на принадлежность объекта к этой категории. Полезен, если категории не обладают естественным порядком.
Обратите внимание: при большом количестве уникальных категорий One-Hot Encoding может сильно увеличить размер данных. Это снизит производительность и потребует больше памяти. В таких случаях лучше использовать альтернативы, например Target Encoding.
Пример кода One-Hot Encoding:
# Применение One-Hot Encoding к столбцу "Район"
df = pd.get_dummies(df, columns=['Район'], prefix='Район')
print(df.head())В результате применения One-Hot Encoding к столбцу «Район» будут созданы новые столбцы: «Район_А», «Район_Б», «Район_В» со значениями 0 или 1, указывающие, к какому району принадлежит каждая строка.
Пример кода Target Encoding
# Применение Target Encoding к категориальному признаку "Район"
mean_encoding = df.groupby('Район')['Цена (млн руб.)'].mean().to_dict()
df['Район_encoded'] = df['Район'].map(mean_encoding)
df[['ID', 'Район', 'Район_encoded']]Этап 4 — разделение данных на обучающую и тестовую выборки
Этот этап помогает оценить, как хорошо модель будет справляться с новыми данными, а также помогает вовремя обнаружить переобучение.
Основные подходы
Разделение на обучающую и тестовую выборки (Train-Test Split)
Обычно данные делятся на две части: обучающая выборка (80% данных) и тестовая выборка (20% данных), которая используется для оценки точности на данных, которые модель ранее не видела.
Пример кода:
from sklearn.model_selection import train_test_split
# Разделение данных на обучающую и тестовую выборки
X = df.drop(columns=['Цена (млн руб.)', 'ID']) # Признаки (features), удаляем ID как неинформативный признак
y = df['Цена (млн руб.)'] # Целевая переменная (target)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print("Размер обучающей выборки:", X_train.shape)
print("Размер тестовой выборки:", X_test.shape)В этом коде мы используем функцию train_test_split из библиотеки Scikit-Learn для разделения данных. Параметр test_size=0.2 указывает, что 20% информации будет использовано для тестирования, а параметр random_state=42 нужен, чтобы при каждом запуске код делил данные одинаково.
Делить данные на выборки можно с учётом времени (out-of-time подход, в тестирование таким образом попадают более новые объекты) или без этого (out-of-sample).
Кросс-валидация (Cross-Validation)
Используется для более точной оценки модели. Вместо одного разделения данные разбиваются на несколько частей (folds), и модель обучается на k-1 частях, тестируясь на оставшейся. Процесс повторяется k раз, чтобы каждая часть данных побывала в тестовой выборке.
Перемешивание данных (shuffle=True) помогает избежать смещения и получить более точную оценку.
Пример кода:
from sklearn.model_selection import KFold
# Создание объекта KFold для кросс-валидации
kf = KFold(n_splits=5, shuffle=True, random_state=42)
for train_index, test_index in kf.split(X):
X_train, X_test = X.loc[train_index], X.loc[test_index]
y_train, y_test = y.loc[train_index], y.loc[test_index]
# Обучение и тестирование модели происходит внутри этого циклаВ примере выше KFold делит данные на 5 частей и повторяет процесс обучения 5 раз: каждый раз на одной из частей запускается тест, а на остальных — обучение.
Если решается задача классификации и целевая переменная не сбалансирована, стоит использовать StratifiedKFold, который сохраняет пропорцию классов в каждой выборке.
Этап 5 — масштабирование признаков
Масштабирование нужно для приведения числовых признаков к единому масштабу. Это важно для алгоритмов, таких как линейная регрессия, SVM и KNN, чтобы улучшить их сходимость.
Важно: прежде чем проводить масштабирование, нужно разделить данные на обучающую и тестовую выборки. Это помогает избежать утечки данных и оценить качество модели на новой информации.
Разберем основные методы масштабирования.
Стандартизация (Standardization)
Приведение признаков к нулевому среднему и стандартному отклонению, равному единице. Стандартизация делает признаки сопоставимыми по масштабу, но не обязательно приводит их к нормальному распределению.
Пример кода:
from sklearn.preprocessing import StandardScaler
# Применение стандартизации к числовым признакам (сначала обучаем скейлер на обучающих данных)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test) # Применение обученного скейлера к тестовой выборке
print(X_train_scaled[:5]) # Пример первых пяти строк стандартизированных данныхВ результате применения StandardScaler признаки, такие как «Площадь (кв. м)» и «Цена (млн руб.)», будут иметь среднее значение около 0 и стандартное отклонение 1. Но это не означает, что их распределение станет нормальным.
Нормализация (Min-Max Scaling)
Нормализация приводит значения признака к диапазону от 0 до 1, чтобы сделать их сопоставимыми. Она полезна, если у данных разные масштабы, что может мешать работе модели.
Нормализация важна для алгоритмов, чувствительных к масштабу признаков, таких как KNN или SVM. Но если в данных есть выбросы, Min-Max-нормализация может сжать остальные значения, потому что учитывает экстремальные.
Пример кода:
from sklearn.preprocessing import MinMaxScaler
# Применение нормализации к числовым признакам
minmax_scaler = MinMaxScaler()
X_train_scaled = minmax_scaler.fit_transform(X_train[numeric_features])
X_test_scaled = minmax_scaler.transform(X_test[numeric_features])
print(X_train_scaled[:5])После применения MinMaxScaler все числовые признаки будут находиться в диапазоне [0, 1].
Робастное масштабирование (Robust Scaling)
Использование медианы и межквартильного размаха для приведения данных к единому масштабу. Этот метод полезен, если в данных присутствуют выбросы, потому что он менее чувствителен к аномально большим значениям.
Пример кода:
from sklearn.preprocessing import RobustScaler
# Применение робастного масштабирования к числовым признакам
robust_scaler = RobustScaler()
X_train_scaled_robust = robust_scaler.fit_transform(X_train[numeric_features])
X_test_scaled_robust = robust_scaler.transform(X_test[numeric_features])
print(X_train_scaled_robust[:5])RobustScaler помогает уменьшить влияние выбросов, сохраняя важную информацию в данных.
Этап 6 — Feature Engineering
Формально Feature Engineering, или генерация признаков, — это отдельный этап в ML, который не относится к предобработке данных. Но мы включили его, чтобы показать, как завершается работа с данными перед обучением модели.
Специалисты извлекают, создают или трансформируют признаки, чтобы алгоритм лучше распознавал важные закономерности.
Примеры:
- Создание новых признаков на основе существующих («цена за квадратный метр»).
- Разделение числовых признаков на категории (группировка возраста дома на «новый», «средний», «старый»).
- Извлечение временных признаков (например, выделение дня недели или месяца из даты).
Эти действия помогают модели лучше понимать структуру данных и повысить качество предсказаний.
Полезные материалы и ссылки по теме
- Документация pandas: подробное руководство по использованию библиотеки для предобработки данных, включая работу с пропусками, фильтрацию и другие полезные методы.
- Документация Scikit-Learn: разделы по предобработке данных, включая стандартные скейлеры, кодирование категориальных данных и создание Pipeline.
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, Aurélien Géron: книга содержит примеры и практические советы по предобработке данных с фокусом на использовании Python и Scikit-Learn.
- Python for Data Analysis, Wes McKinney: основной ресурс по pandas, написанный создателем библиотеки. В книге разбираются различные техники предобработки, очистки и анализа данных.
- StatQuest — видеозаписи на YouTube с ясными и доступными объяснениями базовых понятий предобработки данных и ML-алгоритмов.
- Kaggle Learn: курсы и практические задания по предобработке данных с использованием реальных датасетов.
- Kaggle: платформа, где можно найти датасеты и проекты, попробовать выполнить предобработку данных самостоятельно и участвовать в соревнованиях.
- Google Colab: интерактивная среда для написания и запуска Python-кода, в которой можно бесплатно работать с большими датасетами и библиотеками, такими как pandas и Scikit-Learn.