


Алексей Кандинский руководит отделом системного администрирования. Он более шести лет помогает развивать и сопровождать IT-инфраструктуру и сервисы в биотехнологической компании BIOCAD. Он рассказывает, как со временем изменилась профессия системного администратора и зачем нужно знать DevOps-практики.
Кто такой системный администратор
Системное администрирование — это поддержание работоспособности и развития IT-системы, а также решение проблем и инцидентов. Сейчас системный администратор в BIOCAD — это больше инженер и представитель операционного направления, чем сотрудник-эникей (сотрудник, который решает несложные технические проблемы), который просто занимается технической поддержкой и базовой конфигурацией серверов.
Классические направления в администрировании:
- системы виртуализации, которые позволяют запускать большое количество виртуальных серверов на одном большом сервере;
- облачные системы;
- сети;
- Windows/Linux-серверы (физические и виртуальные).

В нашей компании в направление системного администрирования также входит DevOps. То есть нужно обеспечивать методологию при разработке приложений и предоставлять инфраструктуру для развертывания контейнеров, обеспечивать CI/CD процессы (процесс безостановочной сборки и доставки кода до различных сред), GitOps (управление инфраструктурой из Git), GitFlow (методики управления ветками проектов в Git) и т.п.
Мы рассказывали, чем занимается DevOps-инженер в этой статье.
У Windows и Linux различаются подходы к настройке операционных систем и решению проблем. В open source решениях (Linux) приходится самостоятельно разбираться в проблеме; документации в большинстве случаев недостаточно, чтобы на 100 процентов понять, как работает продукт. Чтобы продиагностировать проблемы в Linux, нужно внимательно изучить логи и найти информацию об ошибках. Иногда готовые решения можно найти в интернете, но бывает, что приходится локализовывать проблему самостоятельно.
В корпоративных системах (Windows) нужно несколько дней читать подробную документацию, в которой есть схемы по настройке системы и требования к серверу. В Windows обычно сложно найти готовое решение по номеру ошибки, и мы используем документацию либо напрямую обращаемся к вендору.
Чем я занимаюсь
Наша компания — BIOCAD — создает лекарственные препараты для терапии онкологических, аутоиммунных и инфекционных заболеваний. Я отвечаю за IT-инфраструктуру и DevOps-направление. У меня в команде 22 человека: DBA (администратор баз данных), DevOps, Windows-, Linux-администраторы, специалисты по автоматизации инфраструктуры, сетевые администраторы.
Я как архитектор предлагаю, какие IT-сервисы использовать в компании и куда нам развиваться. В компании постоянно внедряются новые решения. Если их внедрять без учета инфраструктуры, то с системой могут возникнуть проблемы: угрозы безопасности, сложность в масштабировании и потенциальная недоступность. Как играющий тренер, иногда вместе со своими сотрудниками разбираюсь в инцидентах — почему работает не так, как должно, — и решаю текущие задачи.
Основная часть рабочего дня проходит на онлайн-встречах: либо мы обсуждаем статусы проектов, либо встречаемся с командой, потому что большинство сотрудников работает дистанционно. Если в офисе можно было просто подойти и спросить о задаче, то сейчас коммуникация замедлилась, а еженедельные встречи позволяют держать всех в одном инфополе.

Один из примеров проектной встречи — обсуждение DR-плана (disaster recovery plan, план аварийного восстановления) в случае катастрофических событий, чтобы системы компании продолжали работать, даже если основные сервера выйдут из строя. В таких случаях для начала нужно понять, какие системы действительно должны быть доступны в первую очередь, а без чего бизнес сможет какое-то время спокойно работать. Мы спрашиваем у владельцев систем о требованиях к скорости восстановления и о возможных потерях и принимаем решение по включению системы в DR-план. Расставив приоритеты, ищем варианты реализации.
Мы выбрали несколько вариантов резервирования виртуальных машин, потому что не все системы можно одинаково обезопасить. Частично мы делали бэкап (резервное копирование) с возможностью поднять систему на любом другом кластере, который находится вне собственного ЦОДа (Центр обработки данных, хранилище для серверного и сетевого оборудования), частично использовали механизм Azure Site Recovery — это реплика виртуальной машины, которая каждые 15 минут отправляет свое состояние в облако. Если появляются проблемы на обычной инфраструктуре, ее можно запустить в облаке, хоть и не так быстро из-за сетевых задержек.
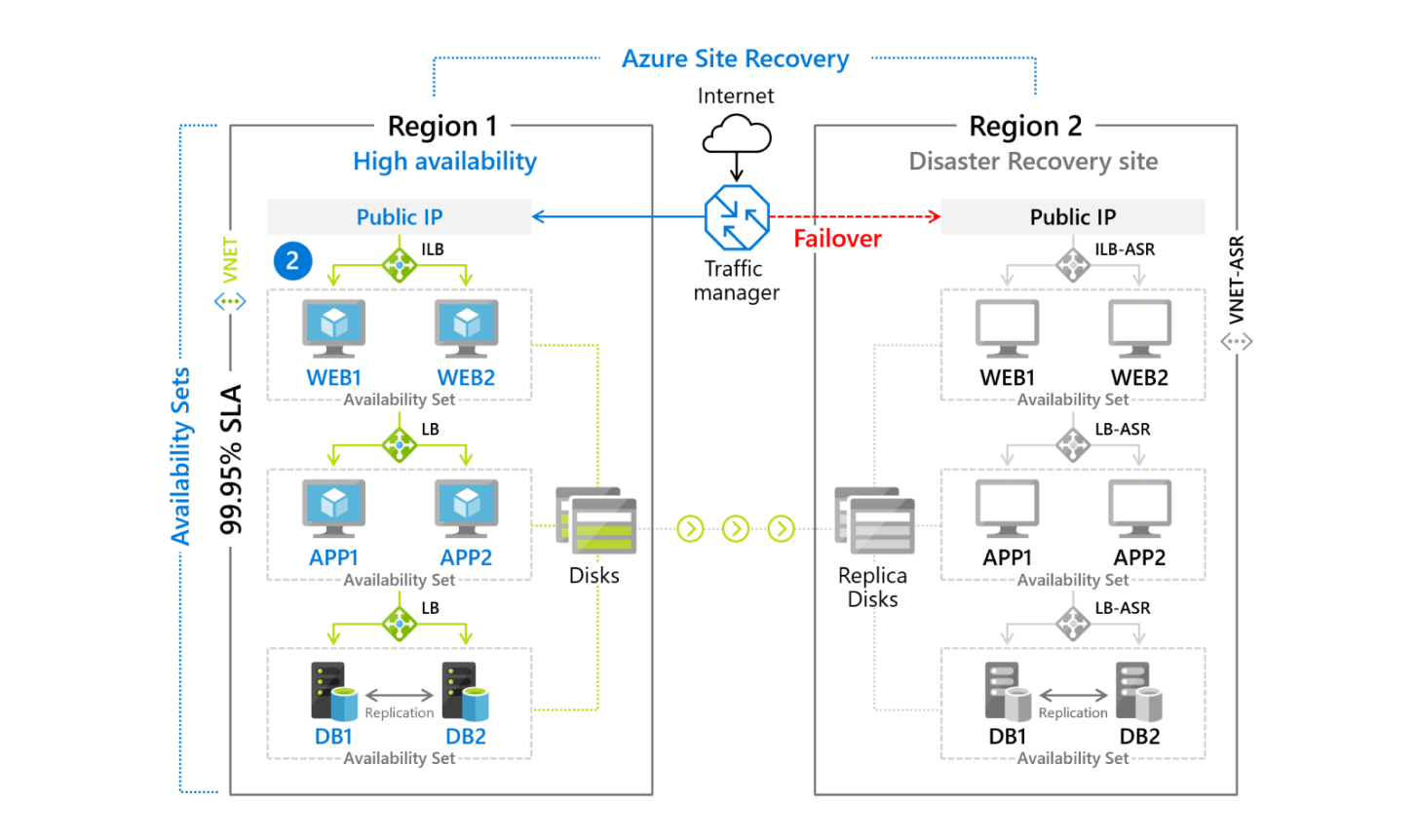
Также мы использовали облачную платформу Azure Kubernetes Services. Kubernetes — это ПО для управления набором контейнеров приложений и их ресурсами. В идеале контейнер не должен накапливать в себе изменения. Если вдруг он перезапустится, все данные или логи очистятся, как будто его только создали.
Но реальность вносит коррективы, и иногда эти данные нужно накапливать. Чтобы их сохранять, к контейнеру подключается виртуальный диск, на котором данные не удаляются. Если контейнер перезапускается, диск, доступный в облаке, отключается, контейнер перезагружается, и диск снова подключается.
Что нужно учитывать при внедрении нового проекта?
Сейчас компания внедряет ECM-систему OpenText для управления документооборотом. В первую очередь нужно провести сайзинг — планирование требований для системы. В соответствии с операциями и количеством пользователей, которые работают над системой, мы рассчитываем, какие нужны процессоры, сколько требуется оперативной памяти, объем дисковой подсистемы хранения данных, ее производительность, распределение системы между ЦОДами.
На этапе миграции — когда мы начали переносить большие объемы данных в систему — выяснилось, что не просчитано быстродействие системы, отдающей данные. Так как платформа высокопроизводительная, она может принимать большие объемы данных, в отличие от системы, которая отдает данные с маленькой скоростью. Пришлось экстренно вносить правки в конфигурацию отдающей системы, чтобы увеличить производительность.
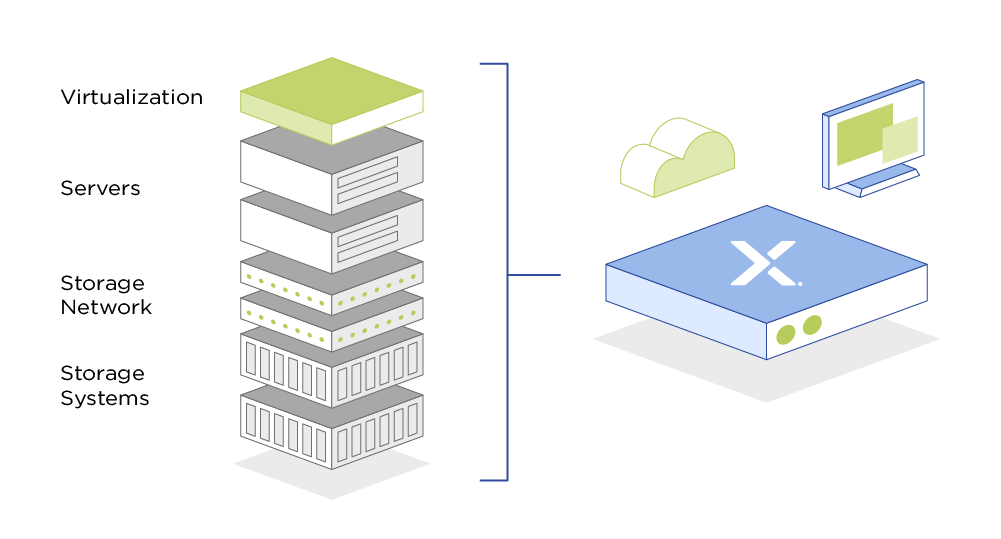
Бывали ошибки, которые мы не просто решали, но и учились избегать. Со временем мы все чаще сталкивались с проблемой «перегрузки» систем хранения данных (СХД). Места хватало, но производительность деградировала из-за количества запросов. У нас было два пути. Первый — увеличить количество СХД и пытаться прогнозировать нагрузки, чтобы сделать все более равномерно, но тогда их будет сложнее обслуживать. Второй — выбрать более современный вариант: гиперконвергентное решение, на чем мы в итоге и остановились.
Классическая схема построения виртуальной инфраструктуры — это серверы без дисков, которые подключены к большой, дорогой и производительной СХД. В гиперконвергентной инфраструктуре мы отказываемся от отдельной системы хранения и объединяем локальные диски серверов в одну большую группу, которая доступна для всех узлов кластера (серверов виртуализации).
От этого несколько положительных эффектов: мы можем легко горизонтально масштабироваться, просто добавив еще серверов с дисковыми емкостями в кластер. К тому же чтение и запись данных происходят с разных серверов, это увеличивает общую «отзывчивость» дисковой подсистемы.
Системное администрирование и DevOps
Сейчас сисадмины стали уходить в разные Ops-практики, например в DevOps. DevOps-методология позволяет быстро проходить весь цикл от разработки ПО до конечного пользователя.
Раньше мы все отдавали на аутсорсинг. Это недорого, можно провести тендер и сменить компанию, которая будет писать продукт. В действительности это работает, если у компании уже есть внутренняя экспертиза. В нашем случае через пару лет аутсорса мы поняли, что не знаем, что происходит на серверах компании, потому что все админские доступы отданы подрядчикам. Обычно они умеют программировать, но у них нет навыков администрирования, например они не контролируют стабильность и безопасность систем.
Тогда уже активно развивался Docker и Kubernetes, и один из моих инженеров предложил его использовать. Это были зачатки DevOps, способ оградить себя от конкретных проблем, чтобы взлом одного сайта не влек за собой взлом всего сервера.
Однако нам нужно было научиться выстраивать весь пайплайн — автоматический конвейер от этапа написания кода до поддержки и мониторинга продукта. Это помогает оптимизировать процесс не только эксплуатации, но и разработки. С помощью этих практик мы добавили тестирование безопасности, функциональное тестирование (как продукт выполняет свои функции), обеспечили максимальную скорость деплоя (перенос сервиса на сервер) и автоматизировали подготовку среды.
Для этого мы решили забрать у подрядчиков продакшн и обязали хранить код на наших серверах GitLab (система управления репозиториями кода), что дало нам возможность отслеживать, кто какие изменения вносил. Мы поддерживаем актуальность кода, следим, чтобы обновление серверов происходило только с репозиториев, находящихся под контролем компании.

Что нужно знать системному администратору
В нашей сфере важно вести всю обязательную документацию не только из-за бюрократических процессов, но и для себя. Если не задокументировать все на первых этапах, через какое-то время можно столкнуться со старой ошибкой и заново потратить время на ее решение.
Сейчас мне интересно разбираться в новых для себя областях, я больше не хочу расти вертикально. Хочу больше узнать про автоматизацию инфраструктуры и увеличить количество систем в компании, к которым применяется подход «инфраструктура как код» (IaC). То есть в GitLab у нас лежит описание инфраструктуры, с помощью которого мы можем в любой момент установить ее дубль в любом месте. Сейчас практики IaC применяет в основном DevOps-группа. Моя задача — ввести их во все группы моего отдела.
Я обязательно выделяю время на изучение новых решений, просматриваю тематические новости. Поэтому я советую постоянно следить за трендами, изучать технологии, которые помогают оптимизировать, масштабировать процессы. Нужно проверять «свежесть» изучаемой области, ведь есть риск, что какие-то технологии уже неактуальны и неэффективны.
