


Pandas — главная Python-библиотека для анализа данных. Она быстрая и мощная: в ней можно работать с таблицами, в которых миллионы строк. Вместе с Марией Жаровой, ментором проекта на курсе по Data Science, рассказываем про команды, которые позволят начать работать с реальными данными.
Среда разработки
Pandas работает как в IDE (средах разработки), так и в облачных блокнотах для программирования. Как установить библиотеку в конкретную IDE, читайте тут. Мы для примера будем работать в облачной среде Google Colab. Она удобна тем, что не нужно ничего устанавливать на компьютер: файлы можно загружать и работать с ними онлайн, к тому же есть совместный режим для работы с коллегами. Про Colab мы писали в этом обзоре.
Пройдите тест и узнайте, какой вы аналитик данных и какие перспективы вас ждут. Ссылка в конце статьи.

Анализ данных в Pandas

Пошаговая инструкция по анализу данных на Python.
- Создание блокнота в Google Colab
На сайте Google Colab сразу появляется экран с доступными блокнотами. Создадим новый блокнот:
- Импортирование библиотеки
Pandas недоступна в Python по умолчанию. Чтобы начать с ней работать, нужно ее импортировать с помощью этого кода:
import pandas as pd
pd — это распространенное сокращенное название библиотеки. Далее будем обращаться к ней именно так. - Загрузка данных
В качестве тренировочного набора данных будем использовать «Отчет об уровне счастья» в разных странах за 2019 год (World Happiness Report). Открыть его можно двумя способами.
- Загрузка в сессионное хранилище
И прочитать с помощью такой команды:df = pd.read_csv('WHR_2019.csv') - Создать объект типа DataFrame вручную
Например, если есть несколько списков и нужно соединить их в одну таблицу или если хотите наглядно оформить небольшой набор данных.
Это можно сделать через словарь и через преобразование вложенных списков (фактически таблиц).
Через словарь:my_df = pd.DataFrame({'id': [1, 2, 3], 'name': ['Bob', 'Alice', 'Scott'], 'age': [21, 15, 30]})
Через вложенные списки:
df = pd.DataFrame([[1,'Bob', 21], [2,'Alice', 15], [3,'Scott', 30]], columns = ['id','name', 'age'])
Результаты будут эквивалентны. - Просмотр данных
Загруженный файл преобразован во фрейм и теперь хранится в переменной df. Посмотрим, как он выглядит, с помощью метода .head(), который по умолчанию выводит пять первых строк:
df.head()
Если нужно посмотреть на другое количество строк, оно указывается в скобках, напримерdf.head(12). Последние строки фрейма выводятся методом.tail().
Также чтобы просто полностью красиво отобразить датасет, используется функцияdisplay(). По умолчанию в Jupyter Notebook, если написать имя переменной на последней строке какой-либо ячейки (даже без ключевого слова display), ее содержимое будет отображено.display(df) #эквивалентно команде df,если это последняя строка ячейки - Узнать размер датасета
Количество строк и столбцов в датафрейме можно узнать, используя метод
.shape:df.shape #покажет размеры сразу по двум осям df.shape[0] #размер по горизонтали - то есть количество строк
df.shape[1] #размер по горизонтали - то есть количество столбцов - Переименование столбцов
Названия столбцов можно переименовать под себя с помощью команды rename:
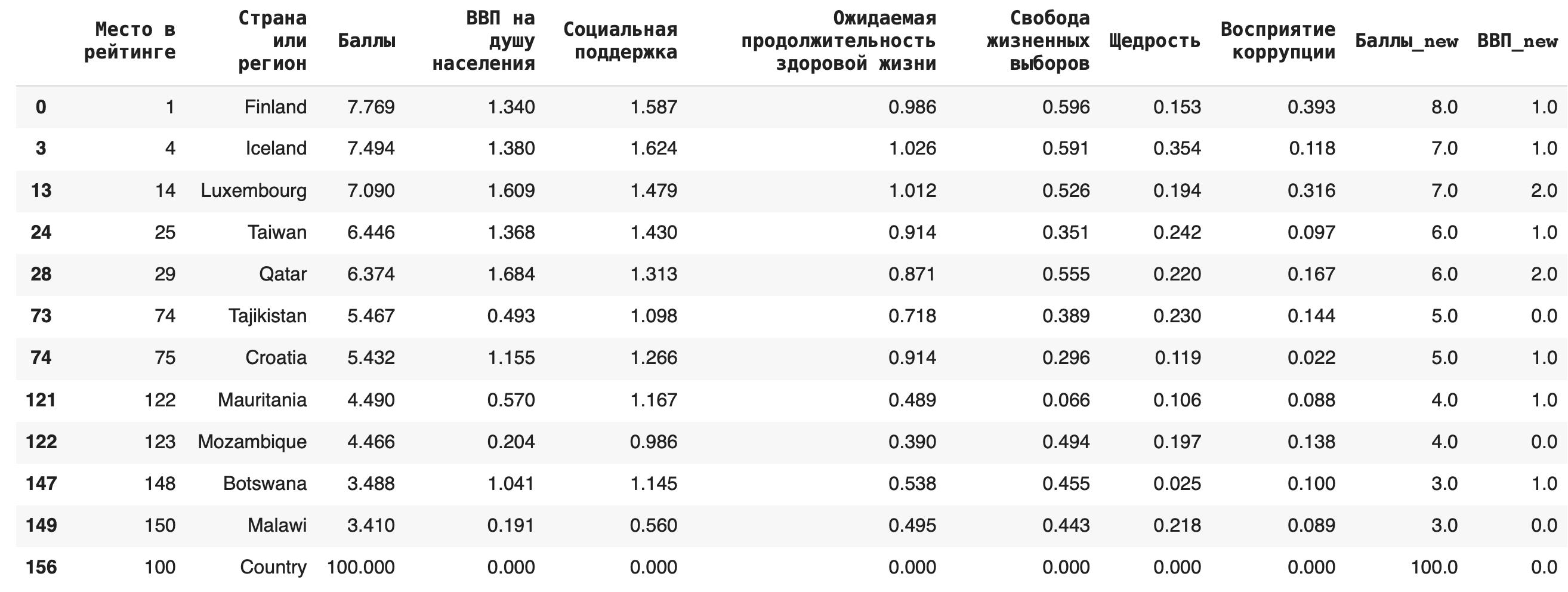
df.rename(columns = {'Overall rank':'Место в рейтинге', 'Country or region':'Страна или регион', 'Score':'Баллы', 'GDP per capita':'ВВП на душу населения', 'Social support':'Социальная поддержка', 'Healthy life expectancy':'Ожидаемая продолжительность здоровой жизни', 'Freedom to make life choices':'Свобода жизненных выборов', 'Generosity':'Щедрость', 'Perceptions of corruption':'Восприятие коррупции'}, inplace = True) df.head()
- Характеристики датасета
Чтобы получить первичное представление о статистических характеристиках нашего датасета, достаточно этой команды:
df.describe()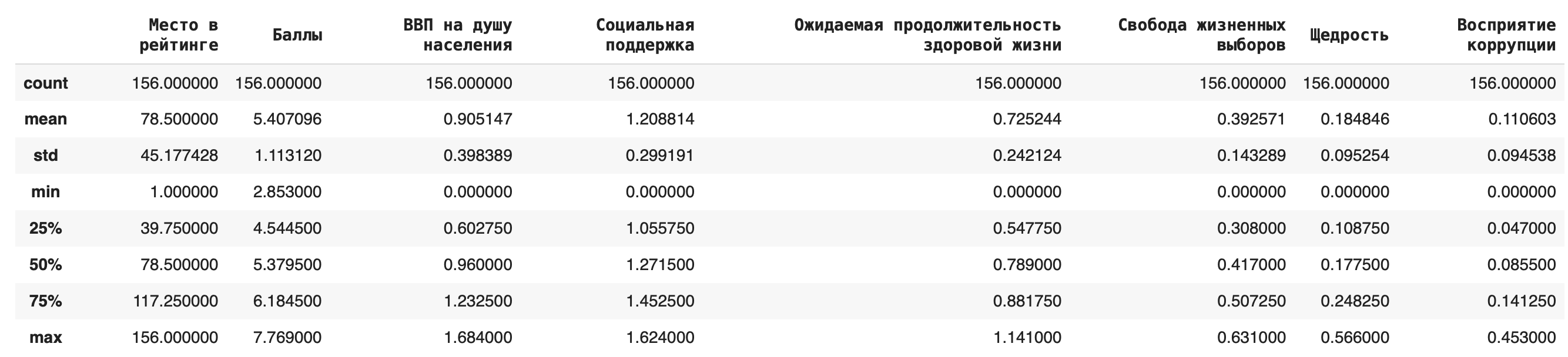
Обзор содержит среднее значение, стандартное отклонение, минимум и максимум, верхние значения первого и третьего квартиля и медиану по каждому столбцу. - Узнать формат и количество значений
Еще одна команда показывает другую справку: сколько значений в каждом столбце (в нашем случае в столбцах нет пропущенных значений) и формат данных:
df.info()
Работа с отдельными столбцами или строками
Выделить несколько столбцов можно разными способами.
1. Сделать срез фрейма df[['Место в рейтинге', 'Ожидаемая продолжительность здоровой жизни']]

Срез можно сохранить в новой переменной: data_new = df[['Место в рейтинге', 'Ожидаемая продолжительность здоровой жизни']]
Теперь можно выполнить любое действие с этим сокращенным фреймом.
2. Использовать метод loc
Если столбцов очень много, можно использовать метод loc, который ищет значения по их названию: df.loc [:, 'Место в рейтинге':'Социальная поддержка']
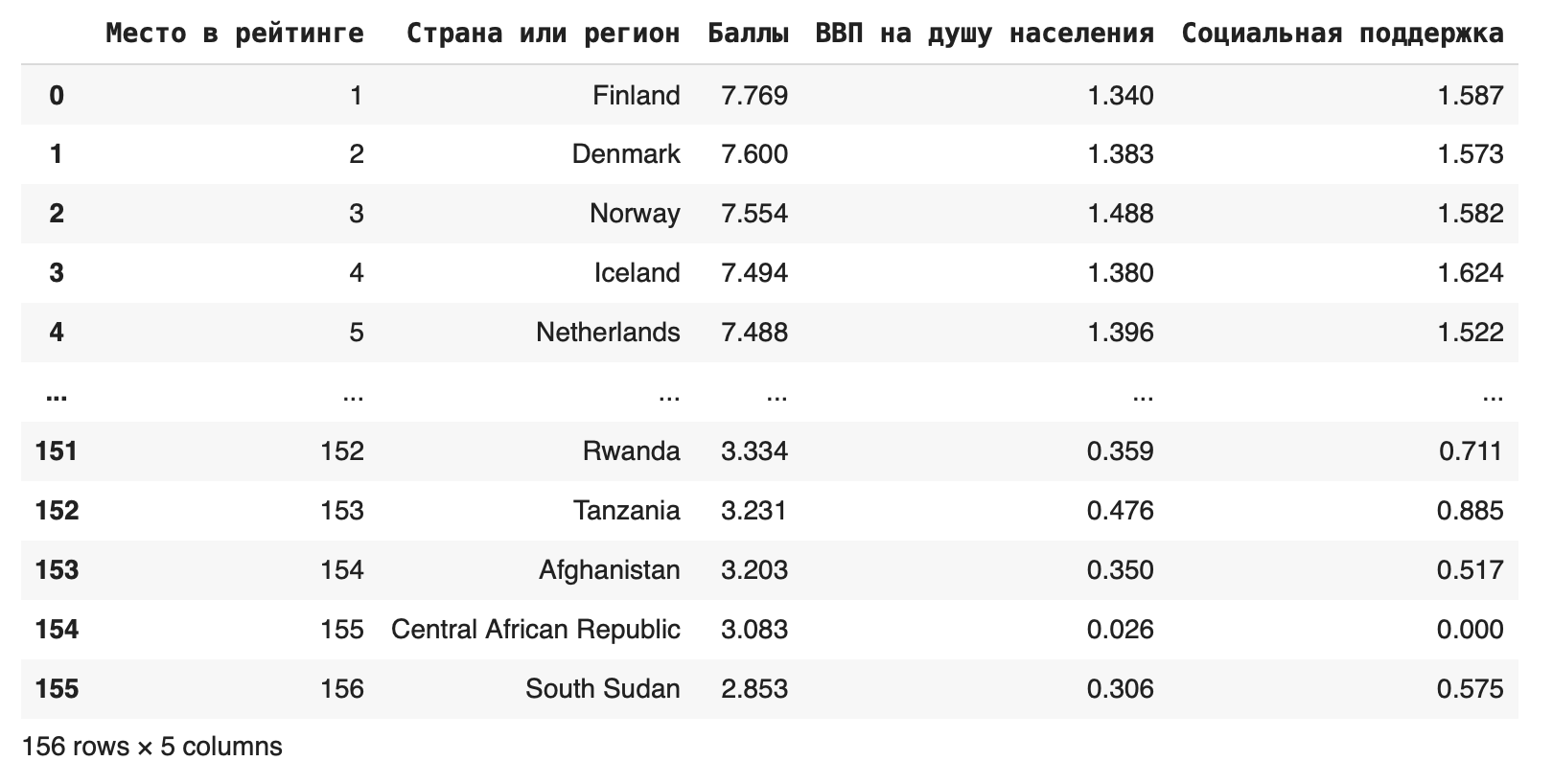
В этом случае мы оставили все столбцы от Места в рейтинге до Социальной поддержки.

3. Использовать метод iloc
Если нужно вырезать одновременно строки и столбцы, можно сделать это с помощью метода iloc:df.iloc[0:100, 0:5]
Первый параметр показывает индексы строк, которые останутся, второй — индексы столбцов. Получаем такой фрейм:
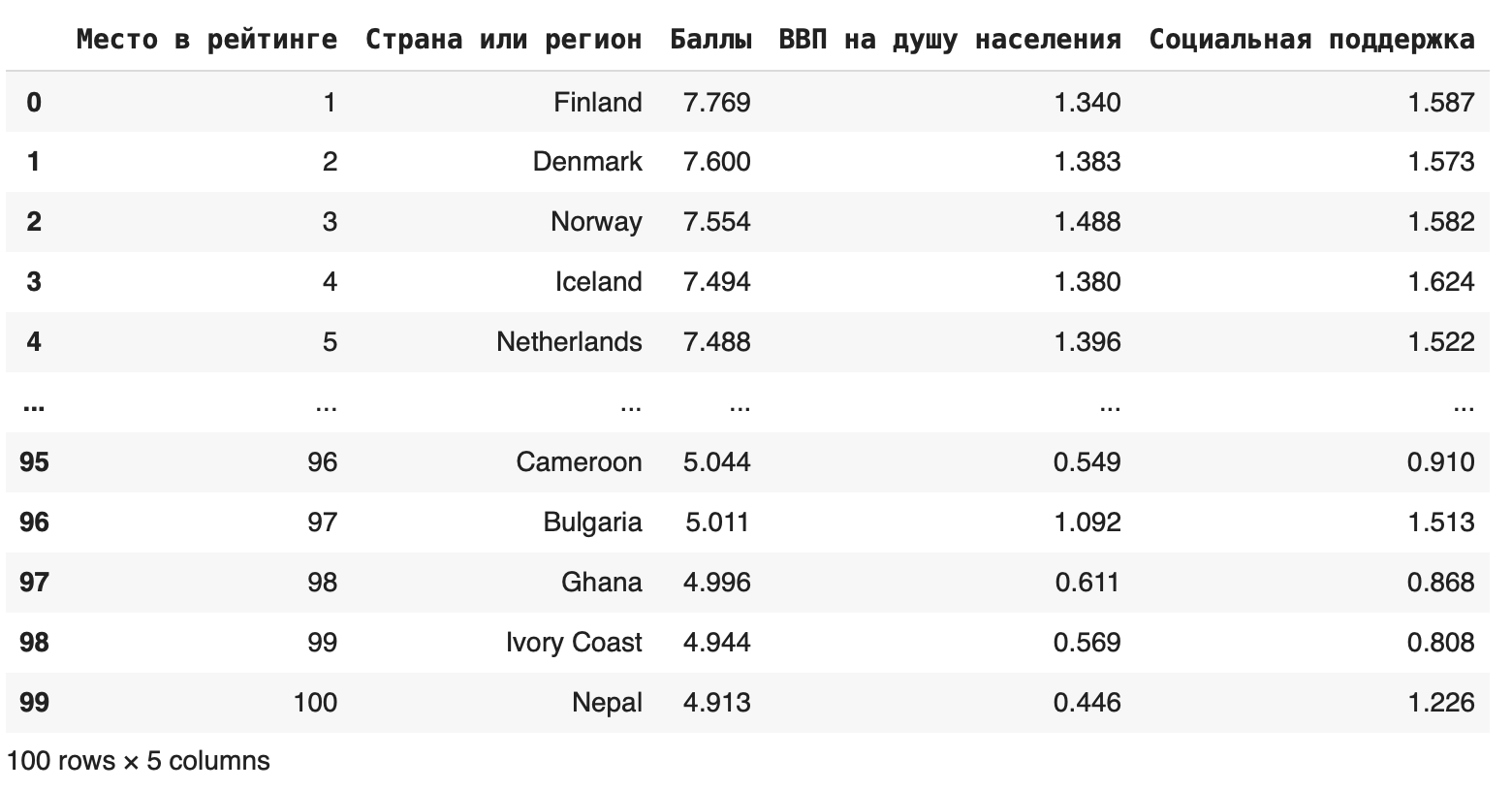
В методе iloc значения в правом конце исключаются, поэтому последняя строка, которую мы видим, — 99.
4. Использовать метод tolist()
Можно выделить какой-либо столбец в отдельный список при помощи метода tolist(). Это упростит задачу, если необходимо извлекать данные из столбцов: df['Баллы'].tolist()
Часто бывает нужно получить в виде списка названия столбцов датафрейма. Это тоже можно сделать с помощью метода tolist(): df.columns.tolist()

Добавление новых строк и столбцов
В исходный датасет можно добавлять новые столбцы, создавая новые «признаки», как говорят в машинном обучении. Например, создадим столбец «Сумма», в который просуммируем значения колонок «ВВП на душу населения» и «Социальная поддержка» (сделаем это в учебных целях, практически суммирование этих показателей не имеет смысла): df['Сумма'] = df['ВВП на душу населения'] + df['Социальная поддержка']

Можно добавлять и новые строки: для этого нужно составить словарь с ключами — названиями столбцов. Если вы не укажете значения в каких-то столбцах, они по умолчанию заполнятся пустыми значениями NaN. Добавим еще одну страну под названием Country: new_row = {'Место в рейтинге': 100, 'Страна или регион': 'Country', 'Баллы': 100} df = df.append(new_row, ignore_index=True)
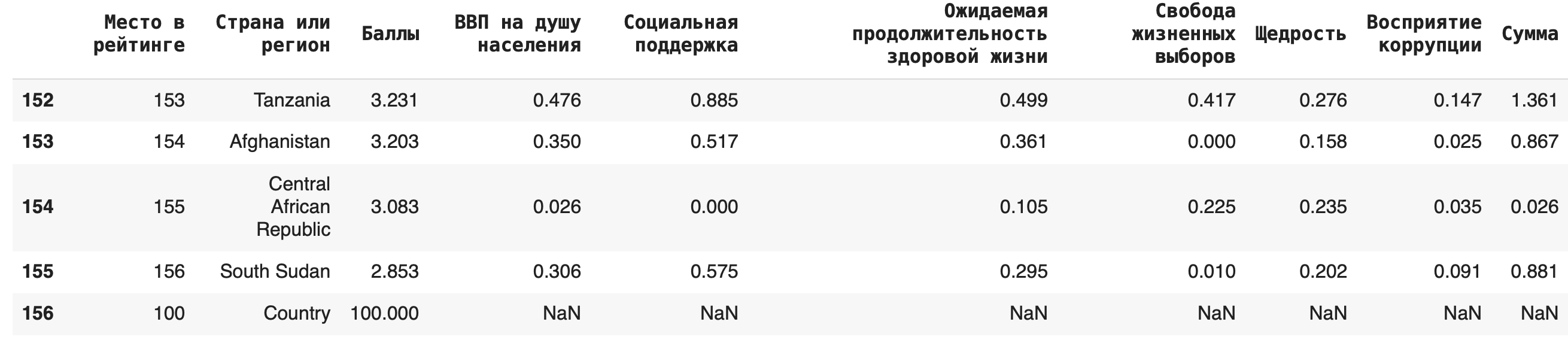
Важно: при добавлении новой строки методом .append() не забывайте указывать параметр ignore_index=True, иначе возникнет ошибка.
Иногда бывает полезно добавить строку с суммой, медианой или средним арифметическим) по столбцу. Сделать это можно с помощью агрегирующих (aggregate (англ.) — группировать, объединять) функций: sum(), mean(), median(). Для примера добавим в конце строку с суммами значений по каждому столбцу: df = df.append(df.sum(axis=0), ignore_index = True)
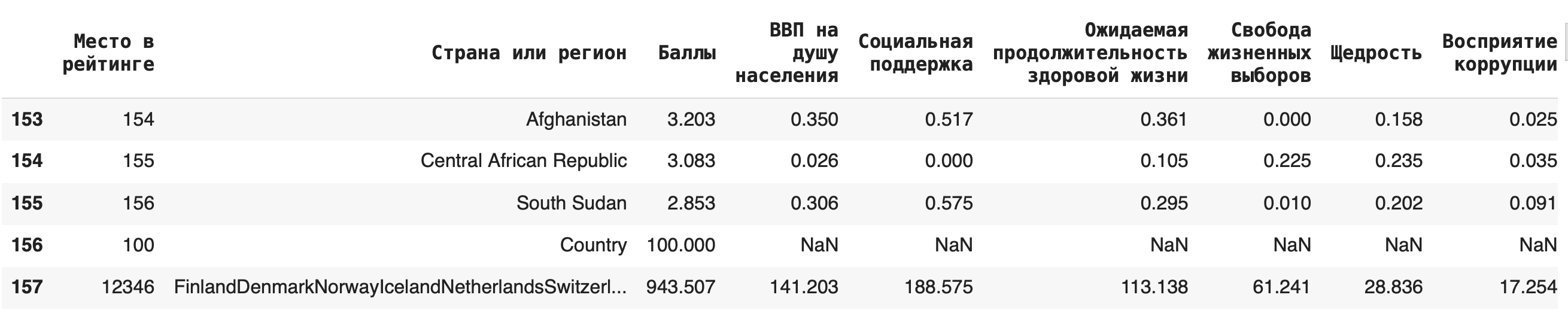
Удаление строк и столбцов
Удалить отдельные столбцы можно при помощи метода drop() — это целесообразно делать, если убрать нужно небольшое количество столбцов. df = df.drop(['Сумма'], axis = 1)
В других случаях лучше воспользоваться описанными выше срезами.
Обратите внимание, что этот метод требует дополнительного сохранения через присваивание датафрейма с примененным методом исходному. Также в параметрах обязательно нужно указать axis = 1, который показывает, что мы удаляем именно столбец, а не строку.
Соответственно, задав параметр axis = 0, можно удалить любую строку из датафрейма: для этого нужно написать ее номер в качестве первого аргумента в методе drop(). Удалим последнюю строчку (указываем ее индекс — это будет количество строк): df = df.drop(df.shape[0]-1, axis = 0)
Копирование датафрейма
Можно полностью скопировать исходный датафрейм в новую переменную. Это пригодится, если нужно преобразовать много данных и при этом работать не с отдельными столбцами, а со всеми данными: df_copied = df.copy()
Уникальные значения
Уникальные значения в какой-либо колонке датафрейма можно вывести при помощи метода .unique(): df['Страна или регион'].unique()
Чтобы дополнительно узнать их количество, можно воспользоваться функцией len():len(df['Страна или регион'].unique())
Подсчет количества значений
Отличается от предыдущего метода тем, что дополнительно подсчитывает количество раз, которое то или иное уникальное значение встречается в колонке, пишется как .value_counts(): df['Страна или регион'].value_counts()

Группировка данных
Некоторым обобщением .value_counts() является метод .groupby() — он тоже группирует данные какого-либо столбца по одинаковым значениям. Отличие в том, что при помощи него можно не просто вывести количество уникальных элементов в одном столбце, но и найти для каждой группы сумму / среднее значение / медиану по любым другим столбцам.
Рассмотрим несколько примеров. Чтобы они были более наглядными, округлим все значения в столбце «Баллы» (тогда в нем появятся значения, по которым мы сможем сгруппировать данные): df['Баллы_new'] = round(df['Баллы'])
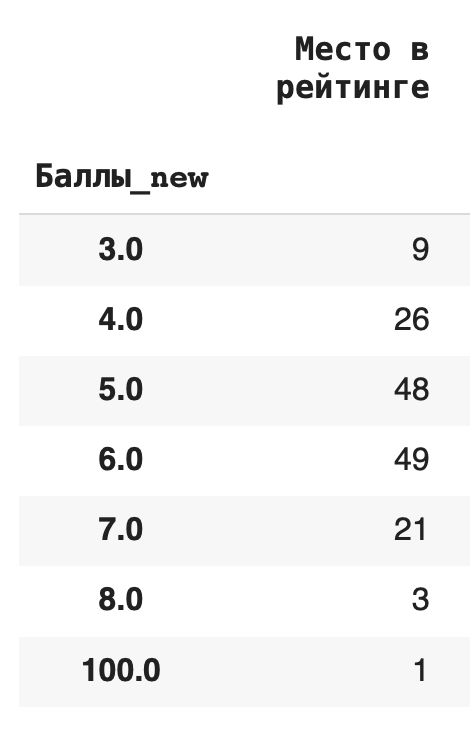
1) Сгруппируем данные по новому столбцу баллов и посчитаем, сколько уникальных значений для каждой группы содержится в остальных столбцах. Для этого в качестве агрегирующей функции используем .count():df.groupby('Баллы_new').count()
Получается, что чаще всего страны получали 6 баллов (таких было 49):
2) Получим более содержательный для анализа данных результат — посчитаем сумму значений в каждой группе. Для этого вместо .count() используем sum():df.groupby('Баллы_new').sum()
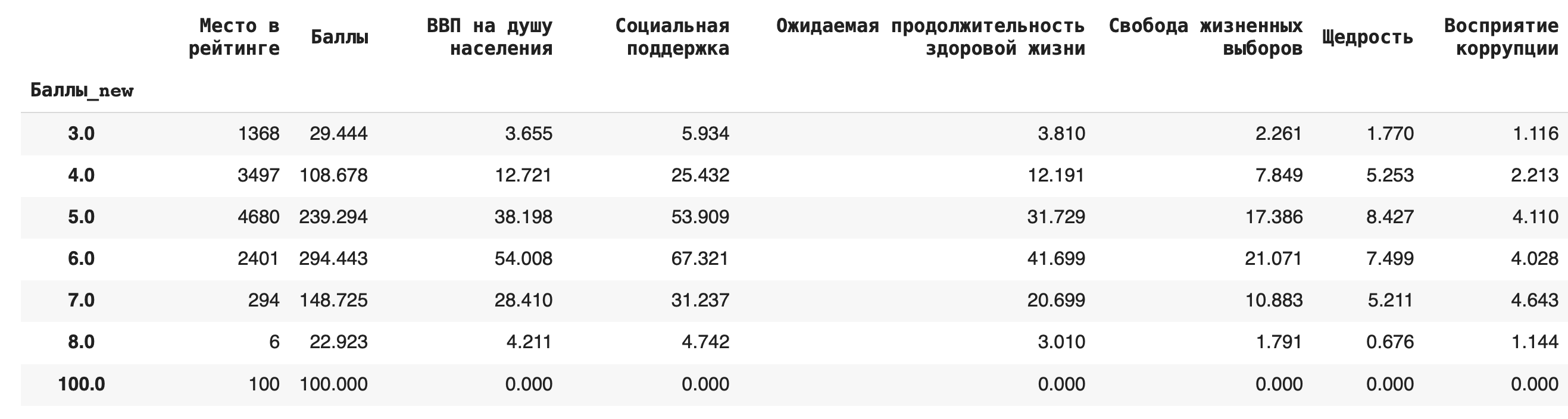
3) Теперь рассчитаем среднее значение по каждой группе, в качестве агрегирующей функции в этом случае возьмем mean():df.groupby('Баллы_new').mean()
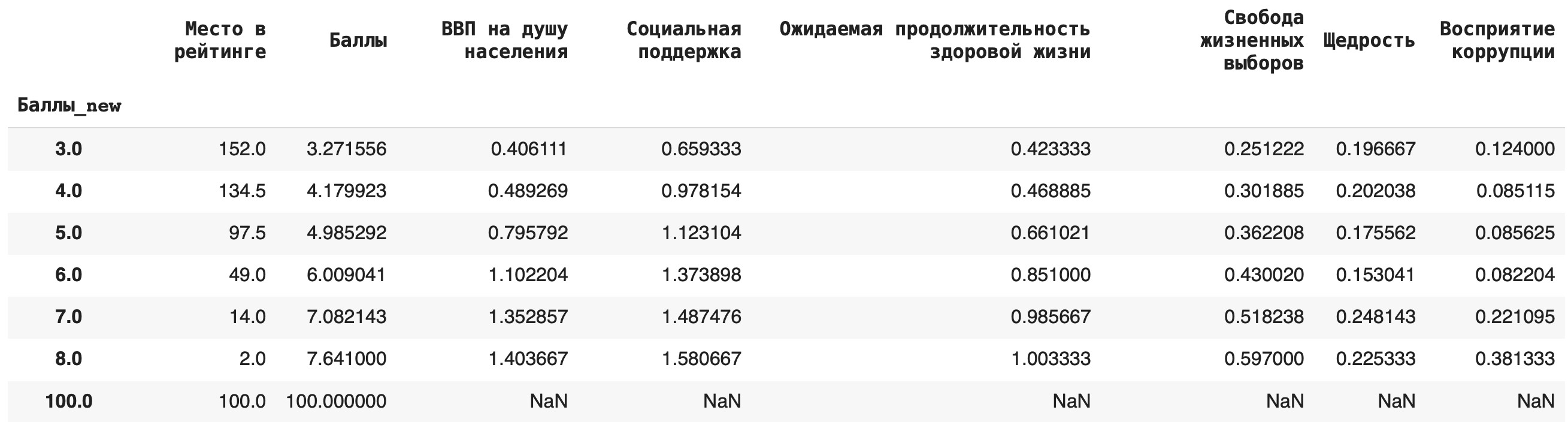
4) Рассчитаем медиану. Для этого пишем команду median():df.groupby('Баллы_new').median()
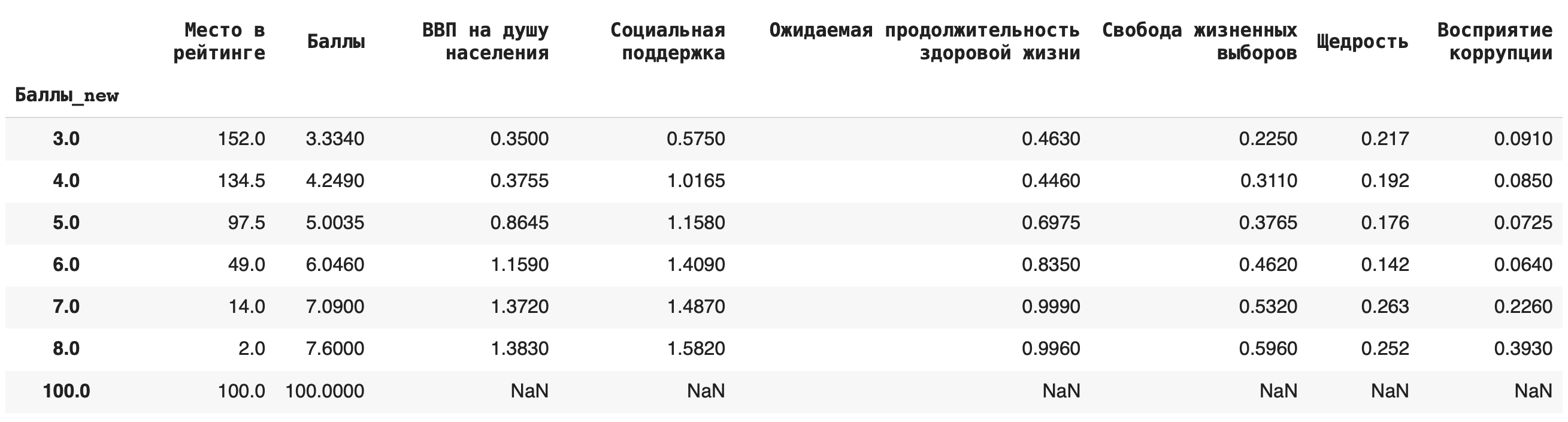
Это самые основные агрегирующие функции, которые пригодятся на начальном этапе работы с данными.
Вот пример синтаксиса, как можно сагрегировать значения по группам при помощи сразу нескольких функций: df_agg = df.groupby('Баллы_new').agg({ 'Баллы_new': 'count', 'Баллы_new': 'sum', 'Баллы_new': 'mean', 'Баллы_new': 'median' })
Сводные таблицы
Бывает, что нужно сделать группировку сразу по двум параметрам. Для этого в Pandas используются сводные таблицы или pivot_table(). Они составляются на основе датафреймов, но, в отличие от них, группировать данные можно не только по значениям столбцов, но и по строкам.
В ячейки такой таблицы помещаются сгруппированные как по «координате» столбца, так и по «координате» строки значения. Соответствующую агрегирующую функцию указываем отдельным параметром.
Разберемся на примере. Сгруппируем средние значения из столбца «Социальная поддержка» по баллам в рейтинге и значению ВВП на душу населения. В прошлом действии мы уже округлили значения баллов, теперь округлим и значения ВВП: df['ВВП_new'] = round(df['ВВП на душу населения'])
Теперь составим сводную таблицу: по горизонтали расположим сгруппированные значения из округленного столбца «ВВП» (ВВП_new), а по вертикали — округленные значения из столбца «Баллы» (Баллы_new). В ячейках таблицы будут средние значения из столбца «Социальная поддержка», сгруппированные сразу по этим двум столбцам: pd.pivot_table(df, index = ['Баллы_new'], columns = ['ВВП_new'], values = 'Социальная поддержка', aggfunc = 'mean')
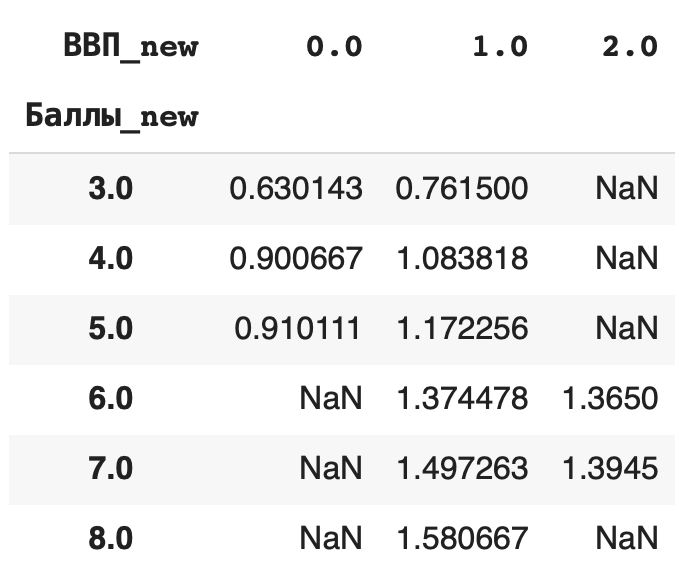
Сортировка данных
Строки датасета можно сортировать по значениям любого столбца при помощи функции sort_values(). По умолчанию метод делает сортировку по убыванию. Например, отсортируем по столбцу значений ВВП на душу населения: df.sort_values(by = 'ВВП на душу населения').head()
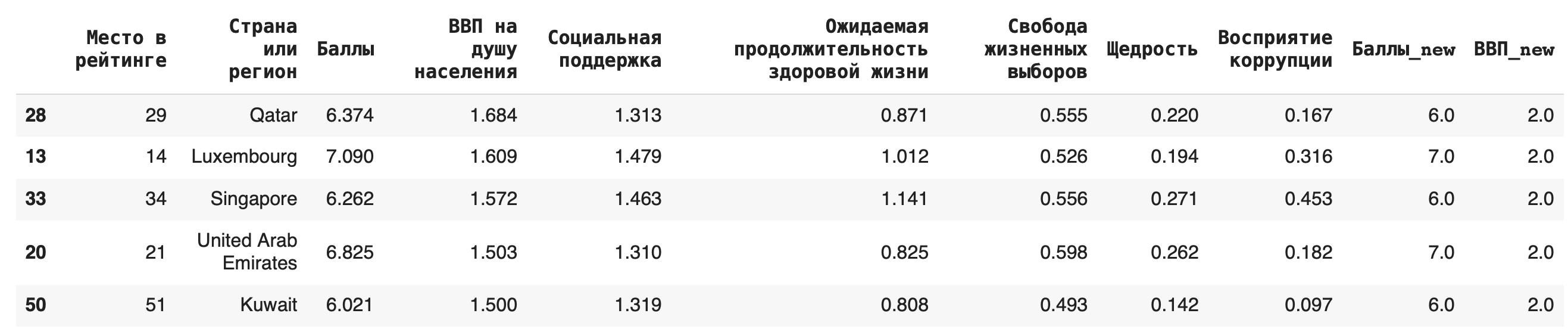
Видно, что самые высокие ВВП совсем не гарантируют высокое место в рейтинге.
Чтобы сделать сортировку по убыванию, можно воспользоваться параметром ascending (от англ. «по возрастанию») = False: df.sort_values(by = 'ВВП на душу населения', ascending=False)
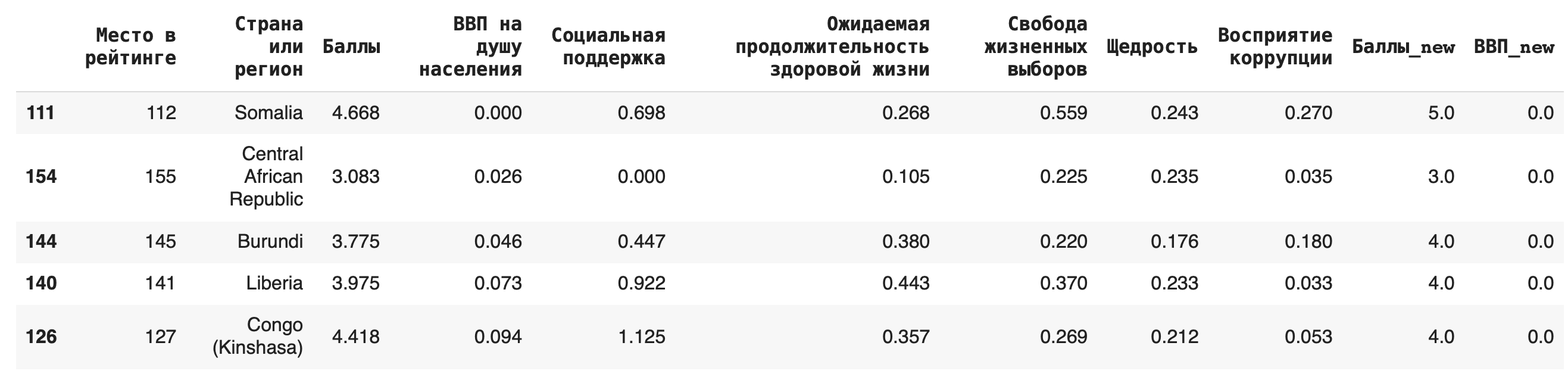
Фильтрация
Иногда бывает нужно получить строки, удовлетворяющие определенному условию; для этого используется «фильтрация» датафрейма. Условия могут быть самые разные, рассмотрим несколько примеров и их синтаксис:
1) Получение строки с конкретным значением какого-либо столбца (выведем строку из датасета для Норвегии): df[df['Страна или регион'] == 'Norway']

2) Получение строк, для которых значения в некотором столбце удовлетворяют неравенству. Выведем строки для стран, у которых «Ожидаемая продолжительность здоровой жизни» больше единицы:df[df['Ожидаемая продолжительность здоровой жизни'] > 1]
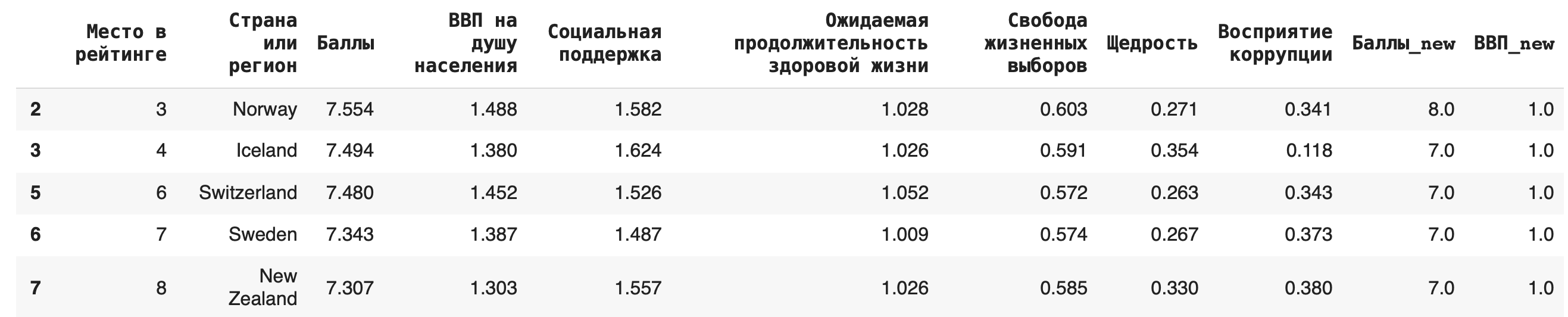
3) В условиях фильтрации можно использовать не только математические операции сравнения, но и методы работы со строками. Выведем строки датасета, названия стран которых начинаются с буквы F, — для этого воспользуемся методом .startswith():df[df['Страна или регион'].str.startswith('F')]

4) Можно комбинировать несколько условий одновременно, используя логические операторы. Выведем строки, в которых значение ВВП больше 1 и уровень социальной поддержки больше 1,5: df[(df['ВВП на душу населения'] > 1) & (df['Социальная поддержка'] > 1.5)]

Таким образом, если внутри внешних квадратных скобок стоит истинное выражение, то строка датасета будет удовлетворять условию фильтрации. Поэтому в других ситуациях можно использовать в условии фильтрации любые функции/конструкции, возвращающие значения True или False.
Применение функций к столбцам
Зачастую встроенных функций и методов для датафреймов из библиотеки бывает недостаточно для выполнения той или иной задачи. Тогда мы можем написать свою собственную функцию, которая преобразовывала бы строку датасета как нам нужно, и затем использовать метод .apply() для применения этой функции ко всем строкам нужного столбца.
Рассмотрим пример: напишем функцию, которая преобразует все буквы в строке к нижнему регистру, и применим к столбцу стран и регионов: def my_lower(row): return row.lower() df['Страна или регион'].apply(lower)

Очистка данных
Это целый этап работы с данными при подготовке их к построению моделей и нейронных сетей. Рассмотрим основные приемы и функции.
1) Удаление дубликатов из датасета делается при помощи функции drop_duplucates(). По умолчанию удаляются только полностью идентичные строки во всем датасете, но можно указать в параметрах и отдельные столбцы. Например, после округления у нас появились дубликаты в столбцах «ВВП_new» и «Баллы_new», удалим их: df_copied = df.copy() df_copied.drop_duplicates(subset = ['ВВП_new', 'Баллы_new'])
Этот метод не требует дополнительного присваивания в исходную переменную, чтобы результат сохранился, — поэтому предварительно создадим копию нашего датасета, чтобы не форматировать исходный.
Строки-дубликаты удаляются полностью, таким образом, их количество уменьшается. Чтобы заменить их на пустые, можно использовать параметр inplace = True.df_copied.drop_duplicates(subset = ['ВВП_new', 'Баллы_new'], inplace = True)
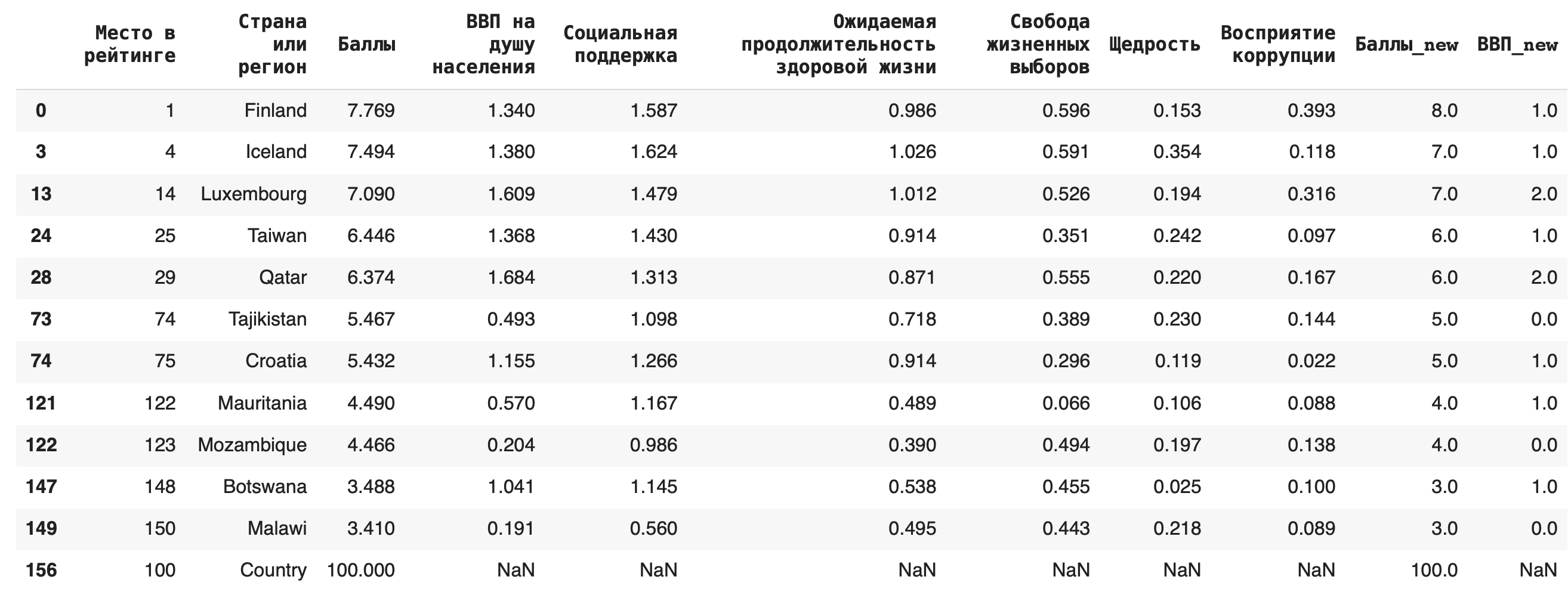
2) Для замены пропусков NaN на какое-либо значение используется функция fillna(). Например, заполним появившиеся после предыдущего пункта пропуски в последней строке нулями: df_copied.fillna(0)
3) Пустые строки с NaN можно и вовсе удалить из датасета, для этого используется функция dropna() (можно также дополнительно указать параметр inplace = True): df_copied.dropna()
Построение графиков
В Pandas есть также инструменты для простой визуализации данных.
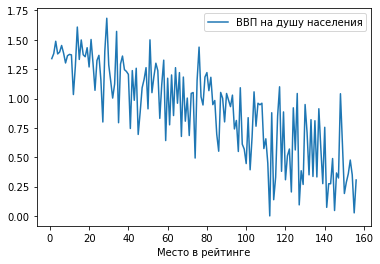
1) Обычный график по точкам.
Построим зависимость ВВП на душу населения от места в рейтинге: df.plot(x = 'Место в рейтинге', y = 'ВВП на душу населения')
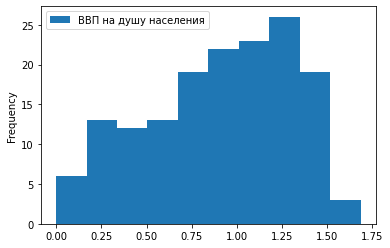
2) Гистограмма.
Отобразим ту же зависимость в виде столбчатой гистограммы: df.plot.hist(x = 'Место в рейтинге', y = 'ВВП на душу населения')
3) Точечный график. df.plot.scatter(x = 'Место в рейтинге', y = 'ВВП на душу населения')
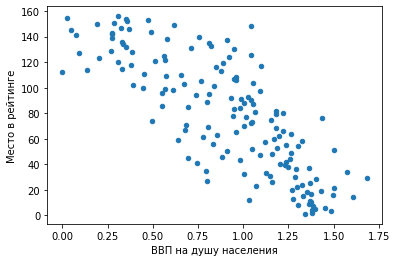
Мы видим предсказуемую тенденцию: чем выше ВВП на душу населения, тем ближе страна к первой строчке рейтинга.
Сохранение датафрейма на компьютер
Сохраним наш датафрейм на компьютер: df.to_csv('WHR_2019.csv')
Теперь с ним можно работать и в других программах.
Блокнот с кодом можно скачать здесь (формат .ipynb).