

Рассказываем об одной из основных структур данных в веб-разработке — динамических массивах данных (dynamic arrays). В отличие от простых массивов, их размер определяется при выполнении кода, что избавляет программиста от утомительной необходимости планировать распределение памяти.
Эти знания помогут всем желающим выбрать оптимальный инструмент для решения множества типичных проблем и изучить (самостоятельно или на нашем курсе) программирование на Python.
Введение в динамические массивы
Динамические массивы применяются в ситуациях, когда разработчик не знает точно, сколько памяти ему потребуется в тот или иной момент. Они позволяют гибко менять используемый объем ресурсов и освобождать ненужные ячейки. Эти процессы происходят автоматически, поэтому такие массивы и называются динамическими.


Благодаря этой структуре данных программа может занимает в памяти ровно тот объем, который ей необходим для хранения конкретных данных. Представим, что вам нужно сгенерировать список пользователей, которые соответствуют каким-то критериям. Вы не знаете, сколько их будет — 10, 50, 100? Если ошибиться в меньшую сторону, код не будет работать. Если перестраховаться и зарезервировать избыточное место (например, сразу на 1000 пользователей), без ресурсов могут остаться приложения, которым они действительно нужны. Однако с использованием динамических массивов вы забываете обо всех трудностях.
Еще одна проблема, которую решается таким образом — это фрагментация памяти. В своей работе веб-разработчики нередко сталкиваются с ситуацией, когда ресурсов вроде бы должно быть достаточно, однако программа начинает сбоить. Причина в том, что в какой-то момент ей нужен один большой кластер памяти, а свободные ячейки оказываются распределены по нескольким участкам. При использовании динамических массивов система оптимально формирует блоки и эффективно освобождает ненужные площади.
Вопросы производительности
Функционально динамический массив соответствует статистическому, открывая при этом ряд удобных возможностей. Время уточнения или изменения значения любого элемента массива не зависит от его расположения. При последовательном переборе элементов, время операции возрастает в линейной прогрессии, а ресурсы кеша расходуются максимально эффективно. То же самое справедливо для добавления или удаления элементов в середине массива. На проведение этих же операций с элементами в конце массива уходит постоянное амортизированное время, то есть в отдельные моменты скорость падает, однако общая производительность остается на уровне константы.
Если вы уже проштудировали руководство по веб-разработке, вы наверняка сравните динамические массивы со связными списками — они также позволяют менять содержимое без лишних затрат ресурсов. Однако массивы обеспечивают лучшие показатели индексирования и перебора элементов. С другой стороны, они несколько проигрывают в скорости добавления данных — если в списке достаточно изменить внутренние ссылки, то содержимое массива приходится двигать в памяти целиком. Для решения этих проблем применяются буферные окна (gap buffers) и многоуровневые векторы (tiered vectors).

Взгляд за кулисы
Теперь рассмотрим, какая механика стоит за всеми этими операциями — как именно Python создает динамические массивы и как меняет их размер. Для начала практическая демонстрация этого механизма.
import sys # этот модуль позволит нам использовать функцию для определения точного объема, который программа занимает в памяти
n = 10 # задаем пороговое значение
data = [] # создаем пустой список
for i in range(n):
a = len(data) # количество элементов
b = sys.getsizeof(data) # объем памяти
print (‘Length:{0:3d}; Size of bytes:{1:4d}’.format(a, b))
data.append(n) # увеличиваем размер на единицу
После выполнения кода мы видим следующую картину (рамками обозначены границы выделенных блоков памяти):
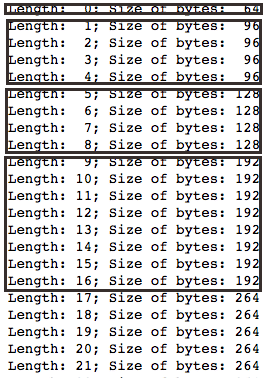
По этой таблице можно понять принцип, которому Python следует при выделении ресурсов. Первые два дополнительных блока содержат по четыре ячейки. После того, как программа последовательно занимает эти пространства, интерпретатор делает вывод о ее ресурсоемкости и сразу предоставляет в два раза больше места. В дальнейшем он будет поступать так же — каждый новый блок будет вдвое превышать предыдущий.
Помните, мы говорили про постоянное амортизированное время при добавлении элементов в конец массива? Падение производительности происходит как раз в тот момент, когда нужно выделить новый, в два раза больший блок памяти. Остальные операции занимают одинаковый период.
Этот принцип позволяет программе быстро добрать небольшое количество ресурсов, которых ей не хватает в начале работы. Если же ее аппетиты продолжают расти, она обращается за помощью все реже.
Алгоритм, который позволяет переносить данные из блока A в блок B, выглядит следующим образом:
- Выделить участок B с нужным объемом памяти, в соответствии с описанным выше методом.
- Установить, что B[i] = A[i], i=0,….,n-1, где n — это текущий номер последнего элемента.
- Установить, что A = B.
- Добавить элементы в новый массив.
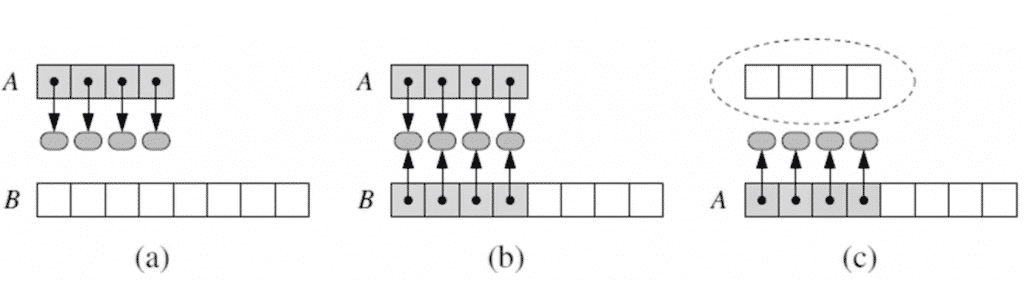
Другими словами, с того момента, как Python создает новый массив B и копирует в него данные, он считает его массивом A. Именно такая элегантная эффективность и снискала этому языку признание тысяч и тысяч программистов по всему миру.
Перламутровые пуговицы
Что ещё можно делать с массивами? Например, структура под названием “куча” (heap) позволяет программисту в любой момент определить в ряду значений минимальное.
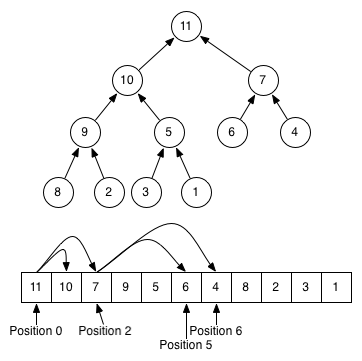
Функционально “куча” представляет собой бинарное дерево, где каждый родитель больше двух своих наследников. Таким образом, верхний узел (heap[0]) всегда оказывается самым меньшим из всего массива.

Список доступных в Python операций с “кучей” включает определение наименьшего элемента, его добавление или удаление, слияние нескольких массивов и др. С помощью “кучи” вы можете, например, выстроить приоритетную очередь для нескольких равноправных процессов, объединить записи двух журналов и выставить их в хронологическом порядке.
Как и другие бинарные деревья, “кучу” может быть сохранить в массиве, но при этом она оказывается компактнее. Дело в том, что в этом случае не требуется пространство для указателей — родителя и его наследников можно найти арифметически по индексам.
Ещё одна вариация структуры на основе массива — двухсторонняя очередь (double-ended queue, deque). Она объединяет в себе функции стека и, собственно, очереди. Как вы помните, главное отличие между этими двумя структурами — порядок получения сохранённых данных. В очереди первыми предоставляются те данные, которые были раньше в ней сохранены (принцип First-In-First-Out). В стеке — наоборот, как в стопке книг или тарелок, сверху оказываются самые новые элементы (First-In-Last-Out).
Двусторонняя очередь позволяет работать с данными с обеих сторон массива — добавлять и удалять элементы как в начале, так и в конце. Классический пример практического применения — планировщик задач для параллельных вычислений. Для каждого участвующего процессора формируется отдельная deque, в которую потоки сохраняются по принципу FIFO. Освободившийся процессор забирает первую задачу в своей очереди. Если она пуста, он обращается к deque другого процессора и забирает себе задачу, которая стоит там последней.
На этом сегодняшний теоретический экскурс окончен. Надеемся, что эти знания помогут вам в изучении Python и покорении новых вершин веб-разработки.