


Это статья‑эксперимент, в которой мы поговорим про AI‑детекторы для проверки кода. Это такие сервисы, которые пытаются определить, написан ли код человеком или сгенерирован нейросетью. Мы разберем, как такие сервисы работают и есть ли от них польза. Спойлер: на наш взгляд, в текущем виде их ценность сомнительна.

Зачем проверять код на ИИ и когда это может пригодиться
Многие компании признают нейросети полезным инструментом разработки и поощряют их использование. Так, согласно исследованию Stack Overflow Developer Survey 2025, 84% опрошенных разработчиков уже используют или планируют использовать инструменты ИИ в своей работе. Они применяют их для автодополнения кода, генерации шаблонов и типовых функций, поиска ошибок, написания тестов и документации, а также выполнения прочих рутинных задач.
Получается двоякая ситуация. С одной стороны, нейросети стали привычным инструментом, которым пользуется большинство разработчиков для ускорения работы. С другой стороны, появляются AI-детекторы, которые пытаются вычислить код, написанный с помощью ИИ. Возникает вопрос: а в чем тогда проблема сгенерированного кода? Зачем вообще его нужно обнаруживать?
При исследовании темы мы заметили, что на Reddit AI-детекторы активнее всего обсуждают студенты. В основном они опасаются преподавателей, которые запрещают использовать нейросети для генерации кода в учебных проектах. Например, вот переведенный фрагмент комментария одного из пользователей:
«Меня беспокоит, что профессор будет проверять репозитории студентов с помощью AI-детекторов и систем обнаружения плагиата. Переживаю в основном потому, что меня уже ловили на ложных срабатываниях таких инструментов.
Профессор утверждает, что у него есть инструмент с точностью почти 99%, который обнаруживает использование ИИ и учитывает ложные срабатывания. Такое вообще возможно? Как думаете, насколько точны эти инструменты сейчас?»
В случае с преподавателями мотивация понятна: они применяют детектор AI, чтобы студенты учились решать задачи самостоятельно, понимали логику программирования и развивали навыки отладки, а не просто копировали готовые решения из ChatGPT или других нейросетей. Если попробовать подумать в таком же направлении, то можно предположить еще несколько сценариев, когда важно убедиться, что код написан человеком, а не полностью сгенерирован ИИ:
- Собеседования. Допустим, кандидат присылает тестовое задание с безупречно отформатированным кодом, единообразным стилем и подробными комментариями. Если детектор покажет высокую вероятность генерации AI, это может стать сигналом для уточняющих вопросов. То есть рекрутер или техлид может попросить объяснить логику решения, обосновать выбор алгоритма, внести изменения в код или решить смежную задачу. Если кандидат легко на все отвечает, значит, он владеет материалом — независимо от того, использовал ли он ИИ или написал все вручную.
- Проверка лицензий и плагиата. Представим, что в пулл-реквест попадает функция с необычной структурой и нетипичными названиями переменных. Если детектор помечает ее как вероятно сгенерированную AI, то это повод перепроверить происхождение кода: поискать совпадения по фрагментам в открытых репозиториях, выяснить первоисточник и проверить его лицензию. Если окажется, что код взят из проекта с несовместимой лицензией (например, GPL в проприетарном продукте), его придется переписать — иначе могут возникнуть юридические риски для компании.
- Ревью процесса разработки. Предположим, после серии багов техлид хочет понять, где возникают проблемы. Если детектор AI регулярно подсвечивает один и тот же участок кода, это может быть поводом для разбора: проверить покрытие тестами или ограничить генерацию для критичных модулей.
- Безопасность и комплаенс. Во многих компаниях действуют строгие политики безопасности, которые запрещают передавать код во внешние сервисы. Если AI-детектор показывает, что какой-то из критичных модулей мог быть сгенерирован ИИ, это сигнал для проверки: не утекали ли секреты в промпты и прошел ли код тесты и проверку на уязвимости перед релизом.
В итоге мы пришли к выводу, что ИИ-ассистенты в целом полезны как инструмент разработки, но в некоторых ситуациях лучше обойтись без них. Именно для таких случаев AI-детекторы могут стать неплохим помощником — они помогут обнаружить небезопасные участки кода и вовремя внести изменения в проект.
Однако на практике программы для проверки кода довольно часто ошибаются. Основная причина в том, что они анализируют код по формальным признакам, но не понимают контекст разработки и не могут отличить аккуратно написанный человеческий код от сгенерированного ИИ. Дальше мы возьмем примеры реального кода, прогоним через несколько популярных детекторов и покажем, почему полагаться на результаты таких инструментов пока преждевременно.
Как работают AI‑детекторы кода и что они проверяют
AI-детекторы кода пытаются оценить, насколько фрагмент похож на типичный результат генератора. Это не проверка на плагиат и не поиск уязвимостей — детекторы пытаются угадать происхождение кода по косвенным признакам.
Обычно такие сервисы используют модели машинного обучения, которые обучены на больших массивах человеческого и сгенерированного кода. Детектор разбирает фрагмент и ищет в нем признаки, характерные для генерации. У разных платформ свои датасеты и веса, поэтому результаты проверок могут отличаться. Однако в целом большинство детекторов опирается на несколько основных групп сигналов:
- Стиль и оформление. Алгоритмы исходят из того, что человек пишет неидеально. Поэтому они обращают внимание на единообразное именование, идеальное форматирование, описательные имена переменных без сокращений, одинаковые отступы и выравнивание во всех блоках. Если все получается слишком аккуратно — это типичный признак генерации.
- Комментарии. Сигналом может быть избыток очевидных комментариев или, наоборот, слишком «стерильный» код без следов работы человека.
- Нейминг и шаблонность. AI-детекторы обращают внимание на слишком универсальные названия и обобщенные функции, которые подходят для всего. Например, функция processData() или переменная tempValue может быть отмечена как сгенерированная — такие названия одинаково подойдут для обработки заказов, парсинга логов или другого подобного сценария. А вот названия вроде cartTotal или calculateUserDiscount() сразу указывают на работу с корзиной покупок и скидками — они отражают бизнес-логику и показывают, что разработчик хорошо понимает контекст приложения.
- Проверки и граничные случаи. В реальном коде набор проверок обычно определяется конкретными требованиями проекта, историей багов и источником данных. Поэтому опытный разработчик добавляет проверку там, где она действительно нужна — например, проверяет результат внешнего API, но не дублирует проверки в каждой функции. Нейросеть иногда впадает в крайности: она либо добавляет избыточные проверки там, где достаточно базовой валидации, либо, наоборот, пропускает их в критически важных местах — при обработке платежей или работе с файловой системой.
- Контекст проекта и реалистичность. Алгоритмы детекторов пытаются понять, учитывает ли фрагмент правила конкретного проекта: используются ли принятые в команде библиотеки логирования, соблюдается ли единый подход к обработке ошибок, применяются ли общепринятые утилиты, соответствует ли стиль тестов договоренностям. Если код технически правильный, но игнорирует паттерны команды, то это может выглядеть как генерация. Причина в том, что нейросеть не знает специфики вашего проекта и поэтому предложит универсальное, но не всегда подходящее решение.
Проверка кода в AI-детекторе занимает секунды: сервис разбирает код на фрагменты (токены), анализирует признаки AI-генерации и выдает оценку в процентах. Полученные проценты — это не доказательство авторства, а лишь статистическая оценка того, насколько код соответствует паттернам, которые конкретный сервис видел в процессе обучения. Теперь перейдем к примерам.
Тестируем AI‑детекторы на примерах кода
Для эксперимента мы выбрали три сервиса, которые первыми попались в выдаче: mydetector.ai, aicodedetector.org и poe.com. Ничего о них не знаем, кроме того, что они позиционируют себя как AI-детекторы и у них есть бесплатные лимиты.
Тест разделим на две части. Сначала возьмем небольшой фрагмент — наше решение простой задачи с Codewars, затем проверим одно из решений этой же задачи из категории «Best Practices». После этого попросим нейросеть создать два новых фрагмента кода: первый — как обычно, а второй — так, будто его писал настоящий человек, чтобы AI-детектору было сложнее определить происхождение.
Базовый тест на задачах с Codewars
Мы выбрали 14-ю задачу с 8 кю, где нужно написать функцию colorOf(r, g, b), которая принимает три числа RGB в диапазоне 0–255 и возвращает строку цвета в формате (HEX) #rrggbb. Для этого нужно перевести каждое число в шестнадцатеричную запись и дополнить до двух символов, если получилось короче.
Вот наше решение на языке JavaScript:
const colorOf = (r, g, b) => {
const h = r.toString(16).padStart(2, "0");
const e = g.toString(16).padStart(2, "0");
const x = b.toString(16).padStart(2, "0");
const showColor = `#${h}${e}${x}`;
return showColor;
}
По идее, детекторы должны считать его человеческим кодом, поскольку здесь мы сначала объявили переменные для каждого цветового канала, а затем собрали их в итоговую строку. Нейросеть для оптимизации, скорее всего, сделала бы все в одну строку. Поэтому наш подход с промежуточными переменными выглядит менее оптимально, но более «по-человечески». Давайте проверим нашу гипотезу.
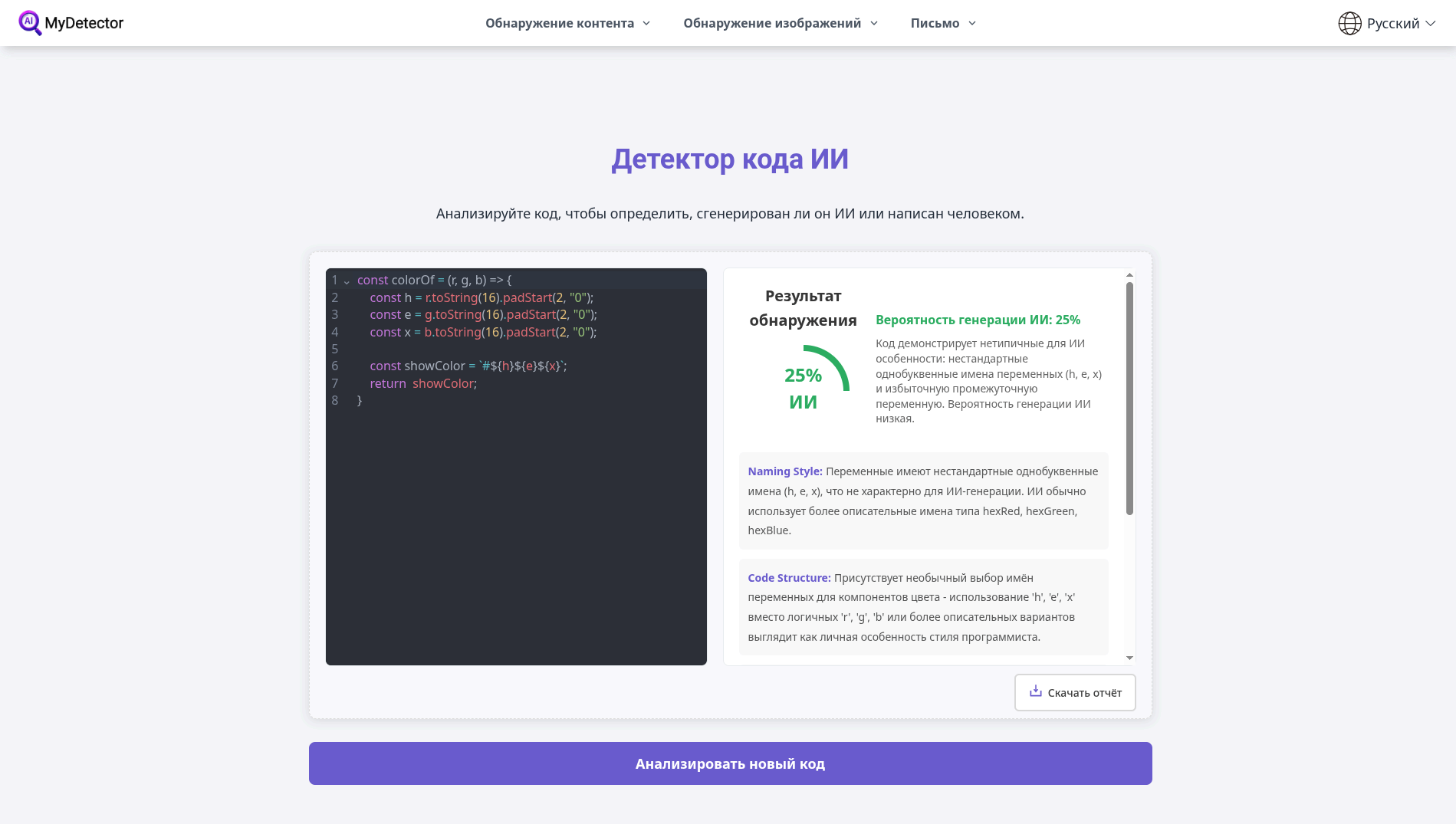
Анализ на mydetector.ai дал низкую оценку AI-генерации: 25% (то есть код скорее признан «человеческим»). Сервис объяснил это тем, что в решении есть нетипичные для ИИ признаки: однобуквенные имена переменных (h, e, x), лишняя промежуточная переменная перед return и отсутствие комментариев:
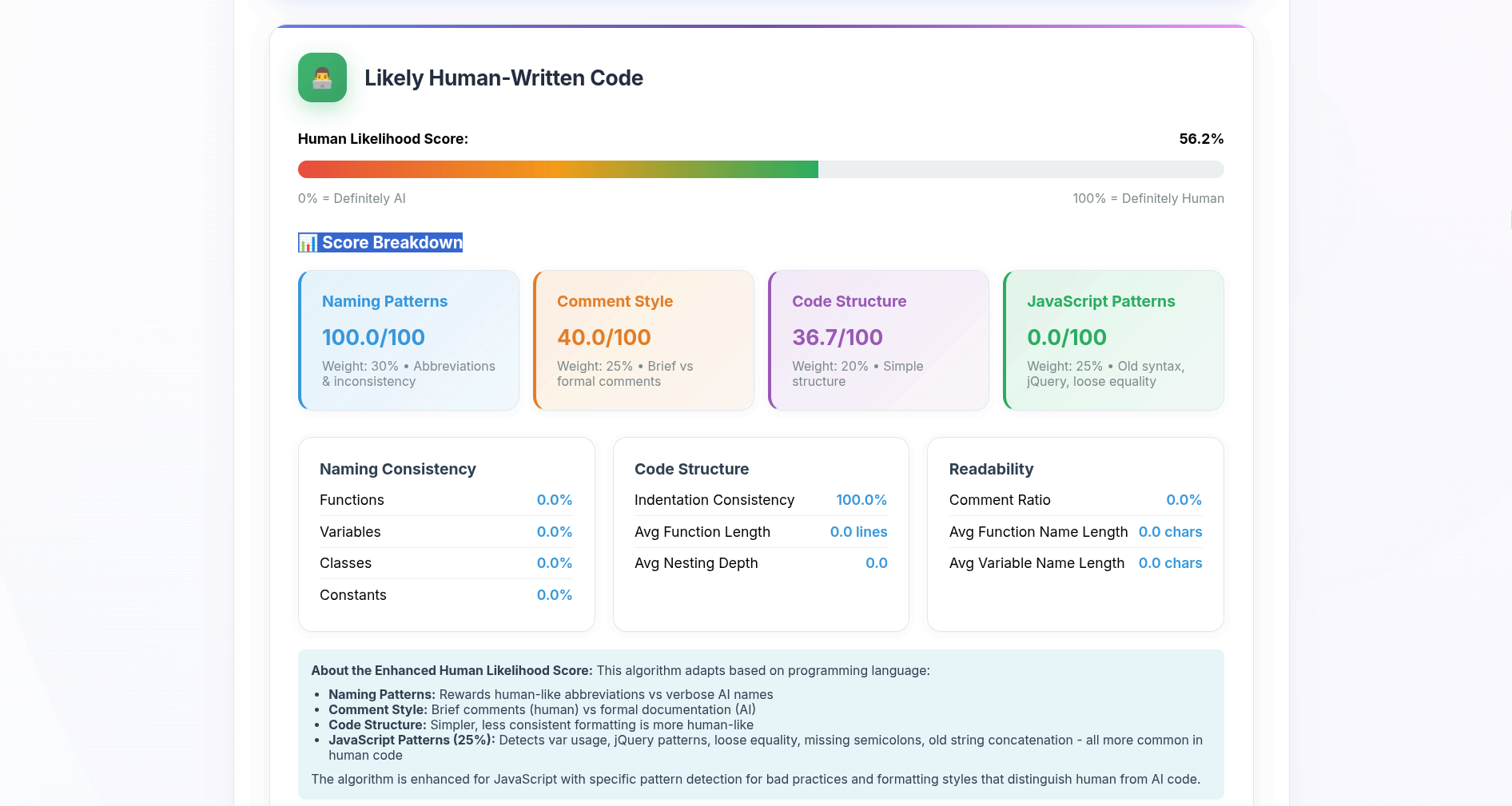
Вторая проверка на aicodedetector.org показала, что код скорее написан человеком: Human Likelihood Score — 56,2%. Сервис объяснил это в первую очередь паттернами нейминга (аббревиатуры и непоследовательность, 100/100), а низкую итоговую оценку связал с простой структурой, отсутствием комментариев и «старыми/неидеальными» языковыми конструкциями (что бы это ни значило).
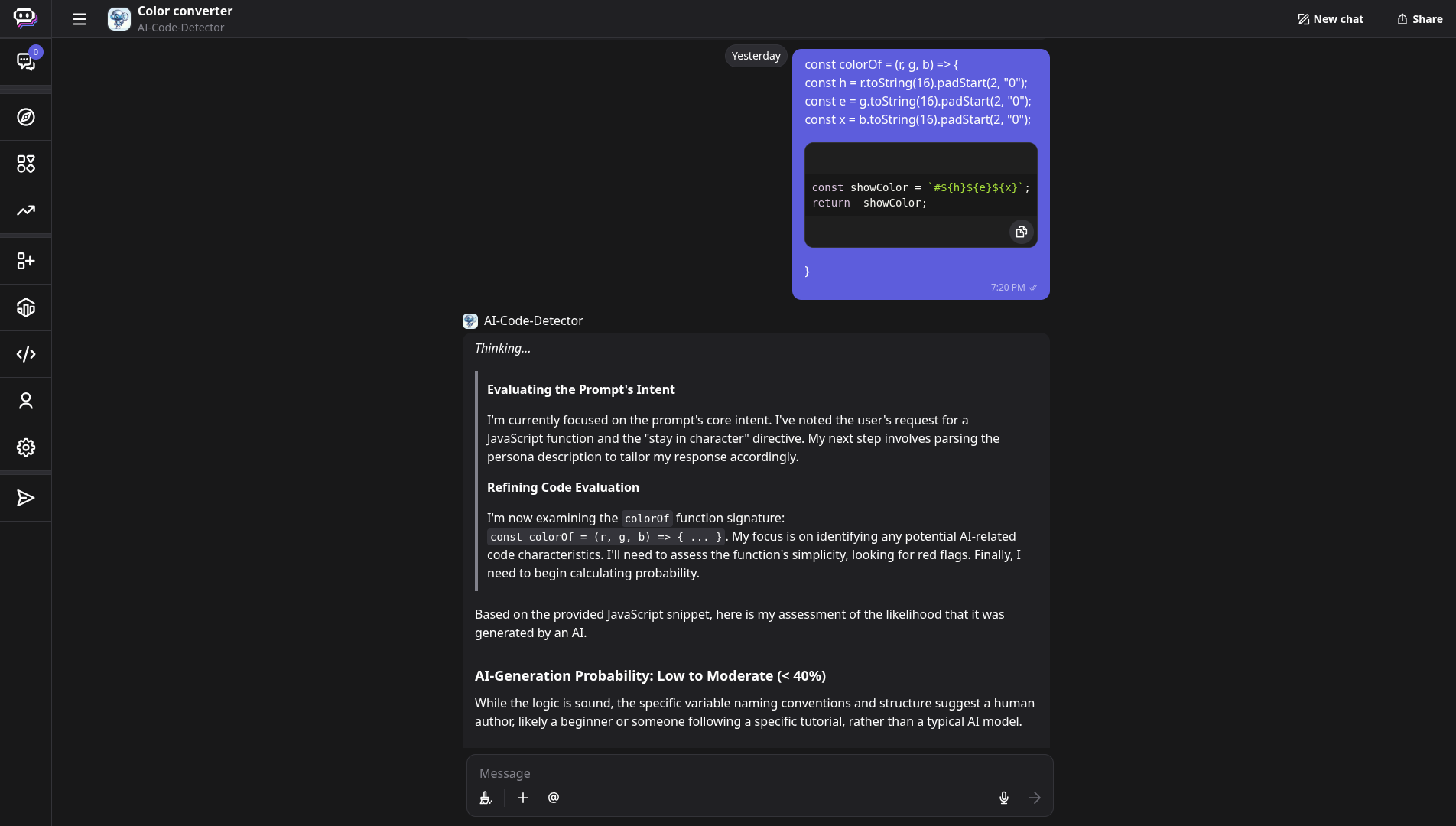
Сервис poe.com старается всесторонне проанализировать код, прежде чем выдать заключение. У него вместо оценки вероятности в процентах есть итоговый вердикт.

В нашем случае результат получился следующим: «Код работает правильно, но креативные названия переменных (h, e, x) и многословный оператор return указывают на человека-автора. ИИ, скорее всего, создал бы более стандартизированную, семантическую и лаконичную версию этой утилиты».
Пока ни один из AI-детекторов не смог дать точного ответа о происхождении кода — все сервисы лишь предположили, что он вероятнее всего написан человеком.
Теперь возьмем код из категории «Best Practices» на Codewars. Когда вы решаете задачу на платформе, вам открывается доступ к решениям других разработчиков, и сообщество может голосовать за понравившиеся варианты. Мы выбрали решение, которое находится на третьем месте по популярности. Оно, хоть и считается одним из лучших, но явно писалось наспех — автор даже не удалил стандартный комментарий-заглушку // coding here, который добавляется к каждой задаче.
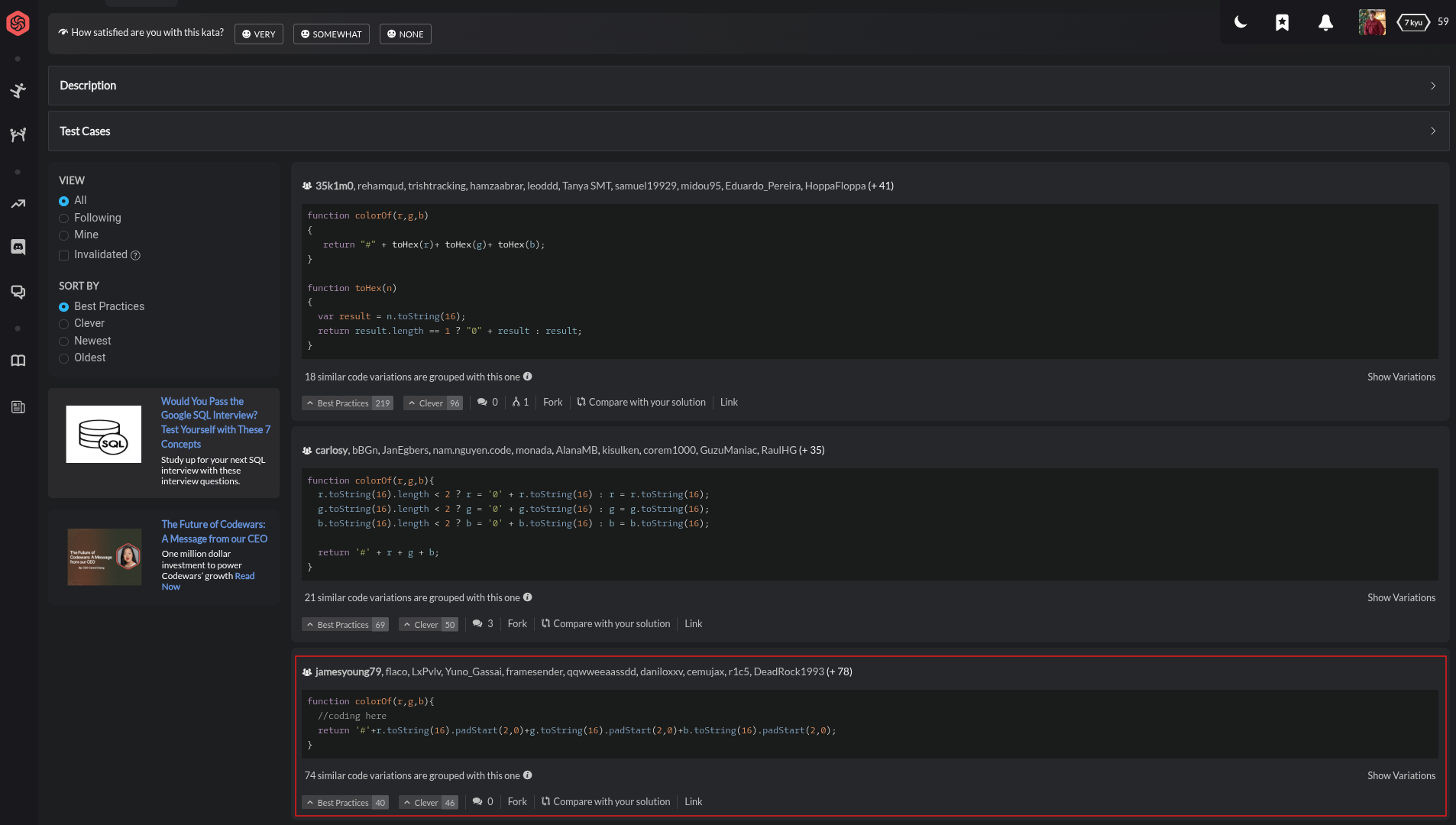
А вот и первая неожиданность: сервис mydetector.ai предполагает, что код скорее всего сгенерирован ИИ — и оценивает вероятность генерации в 78%. В обосновании он ссылается на «типовые» признаки вроде комментария-плейсхолдера //coding here, универсальных имен параметров r, g, b, предельно лаконичной структуры (почти «в одну строку») и отсутствия валидации входных значений.
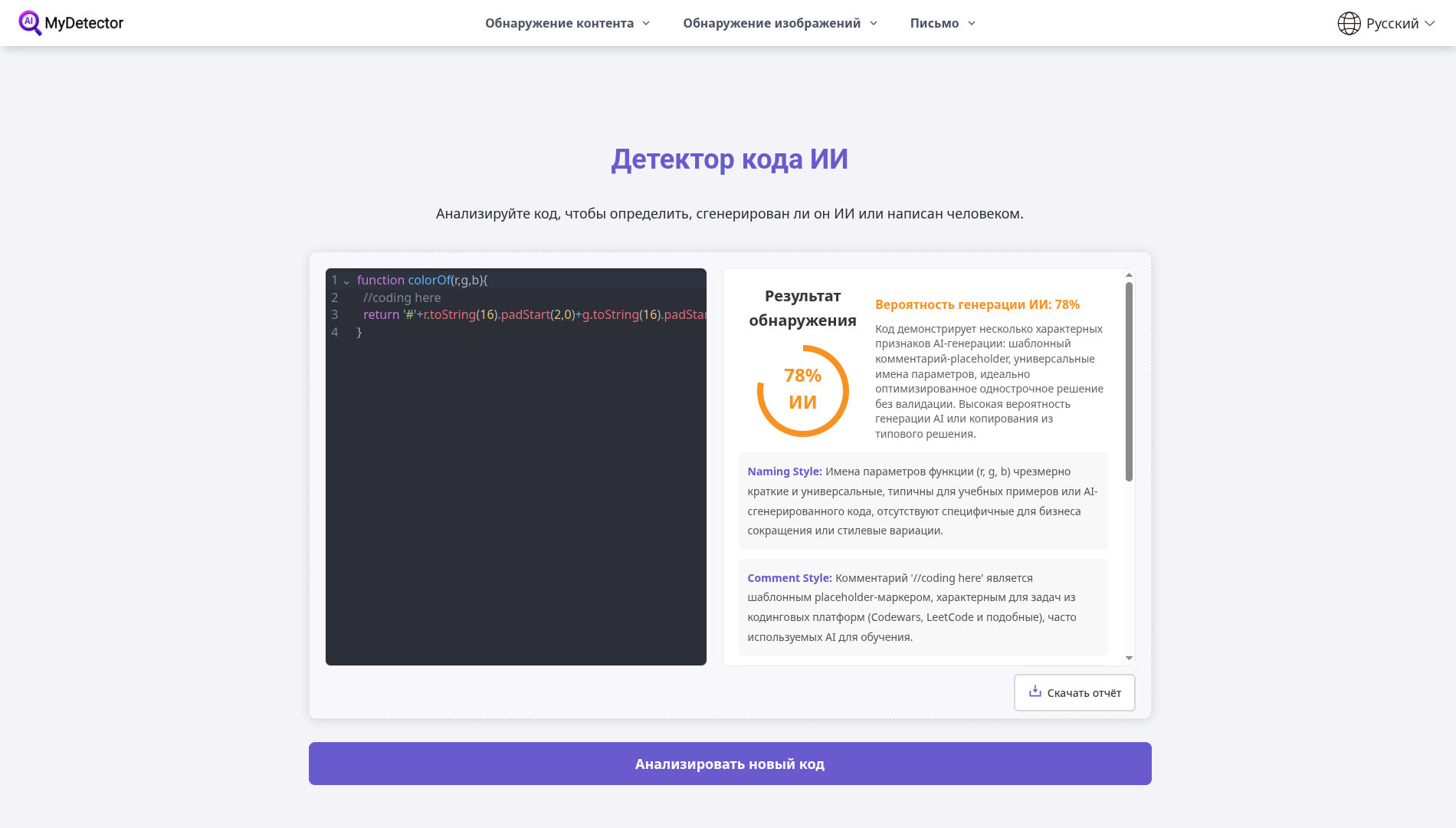
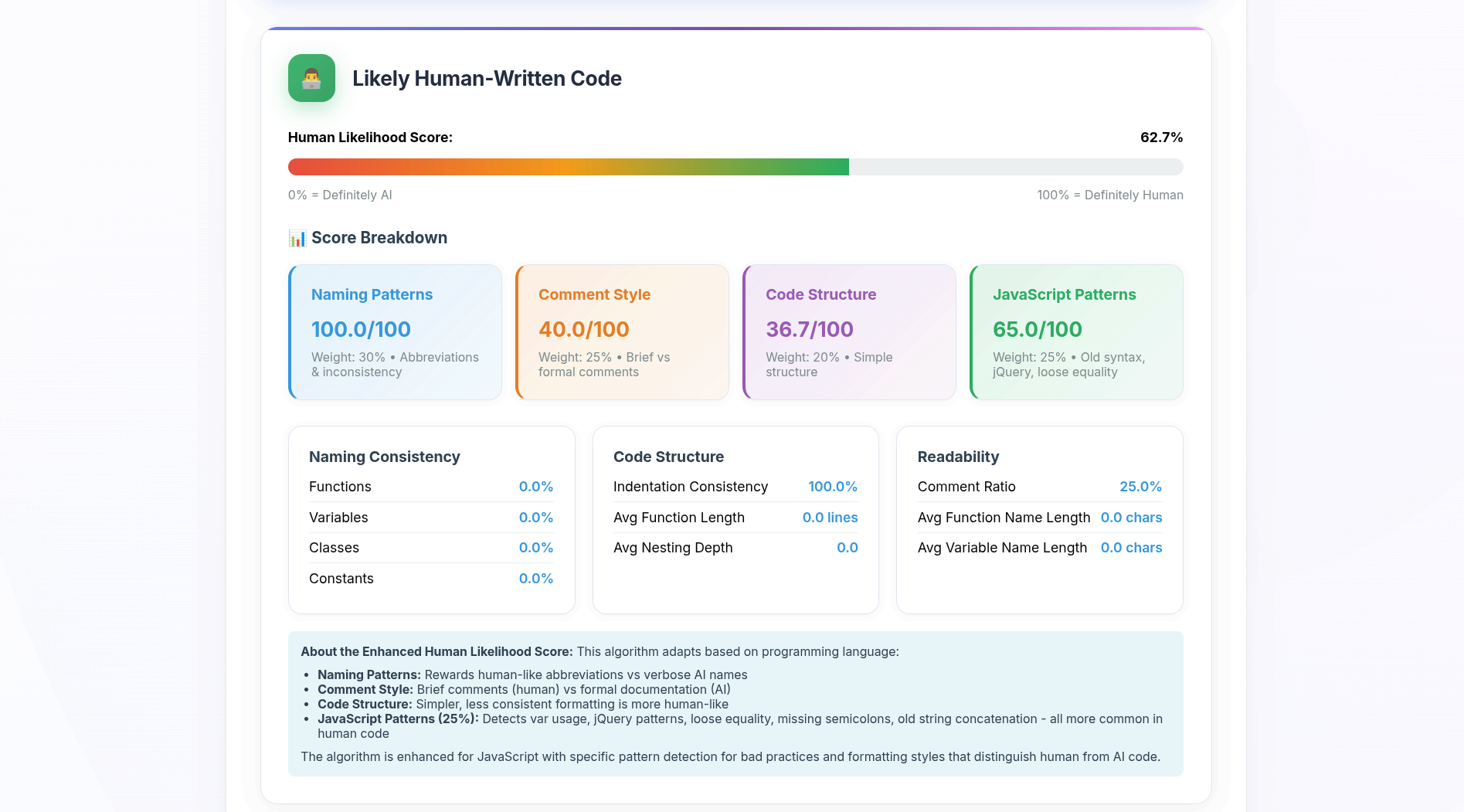
Сервис aicodedetector.org, наоборот, считает фрагмент скорее человеческим — Human Likelihood Score: 62,7%. Главный вклад в «человеческость» кода вносит нейминг (Naming Patterns — 100/100 за сокращения и непоследовательность). Слабее всего выглядят структура кода (Code Structure — 36,7/100) и стиль комментариев (Comment Style — 40/100). Еще детектор отмечает типичные для «учебного/старого» JS-стиля паттерны (JavaScript Patterns — 65/100).
Последний детектор poe.com оказался точнее всех. Он оценивает фрагмент как скорее человеческий и ставит низкую вероятность AI‑генерации (< 20%):
«Наличие платформенного комментария //coding here, использование числа 0 вместо строки «0» в padStart и плотное форматирование убедительно указывают на то, что это код, написанный человеком, вероятно, решение, отправленное на онлайн-платформу для решения задач».
Мы закончили базовый тест. В первом случае мы точно писали код сами, но детекторы не смогли дать однозначного ответа и лишь предположили, что код скорее человеческий. Во втором случае решение, по всей видимости, тоже писал человек — оно давно находится на платформе, возможно, еще до появления современных нейросетей. Однако детекторы снова разошлись во мнениях: один посчитал код AI‑генерированным (78%), другие — человеческим. Это показывает, что такие проверки не способны дать однозначного ответа о происхождении кода.
Тест на специально сгенерированном коде
Дадим AI-детекторам еще один шанс и проведем более контролируемый эксперимент. Для этого мы сгенерируем с помощью ChatGPT два фрагмента кода на JavaScript для решения одной задачи — подсчета частоты встречаемости слов.
Первый фрагмент мы сделали максимально аккуратным: с чистым стилем, продуманными комментариями и современным синтаксисом. Второй — приближенным к тому, как разработчики обычно пишут код в реальных проектах на этапе черновика: с разными стилями оформления, избыточными проверками, разными комментариями «на ходу» и устаревшими конструкциями вроде var.
Вот первый «аккуратный» пример кода:
/**
* Count occurrences of each word in a string.
* - lowercases
* - strips punctuation
*/
function countWords(text) {
if (typeof text !== "string") return {};
const normalized = text
.toLowerCase()
.replace(/[^\p{L}\p{N}\s]+/gu, " ")
.trim();
if (!normalized) return {};
const counts = {};
for (const word of normalized.split(/\s+/)) {
counts[word] = (counts[word] ?? 0) + 1;
}
return counts;
}
// пример
console.log(countWords("Hello, hello... world!")); // { hello: 2, world: 1 }
Неряшливый вариант:
// быстро накидал, потом можно будет причесать
function countWords2(str) {
// типа "защита от дурака"
if (str == null) return {}; // null/undefined
str = String(str);
// тут не заморачиваюсь с юникодом, мне хватит
// и да, я не уверен что это лучшее решение
str = str.toLowerCase().replace(/[^a-z0-9\s]+/g, " ");
var arr = str.split(" ");
var out = {};
for (var i = 0; i < arr.length; i++) {
var w = arr[i];
if (!w) continue; // бывают пустые из-за двойных пробелов
if (out[w]) out[w] = out[w] + 1;
else out[w] = 1;
}
return out;
}
console.log(countWords2("Hello, hello... world!")); // { hello: 2, world: 1 }
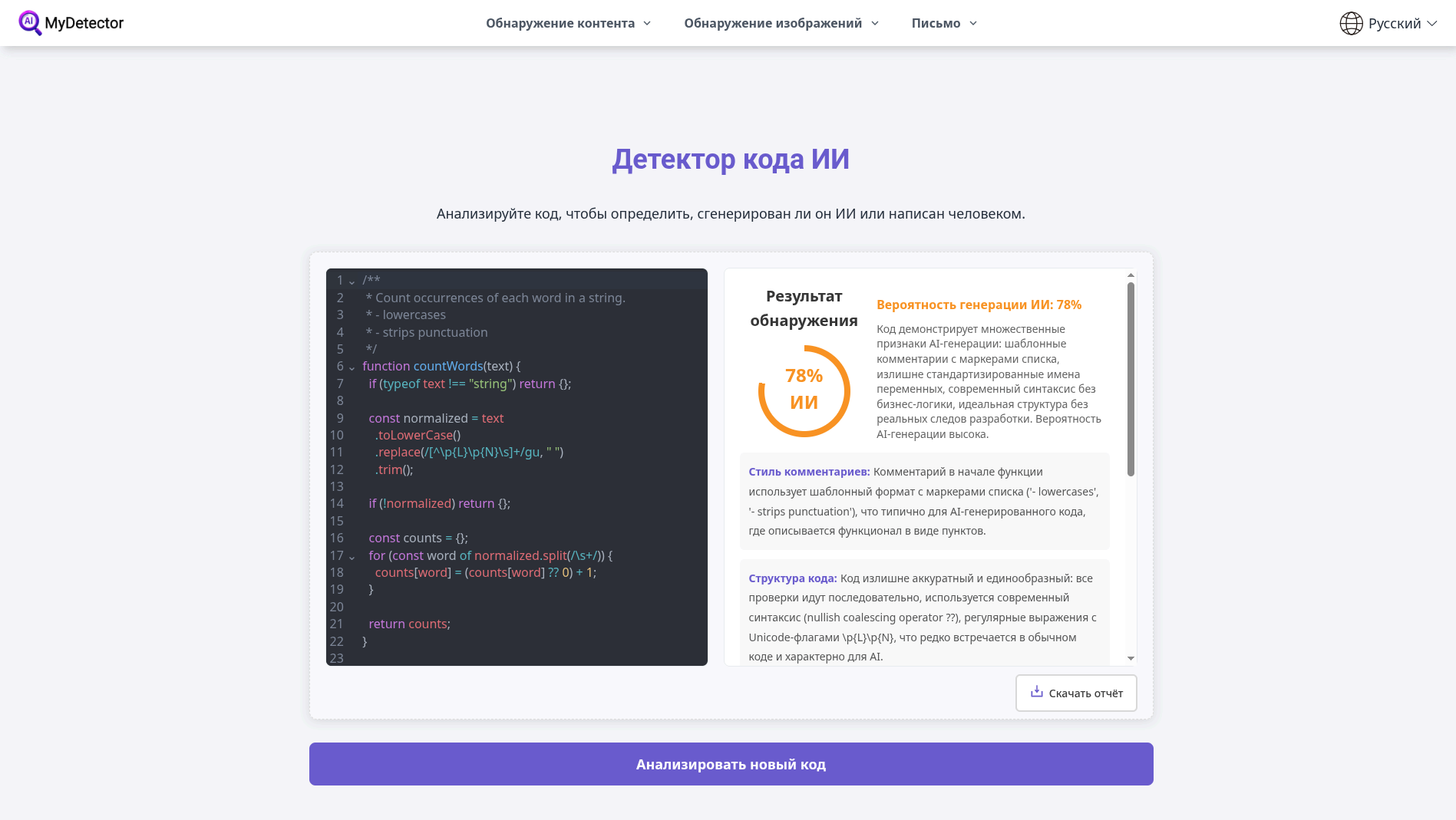
Первый фрагмент mydetector.ai оценил как вероятно AI-сгенерированный — 78%: по мнению сервиса, на генерацию указывают «шаблонные» комментарии в виде списка, слишком универсальные имена переменных (text, normalized), а также чрезмерно аккуратная, ровная структура с современными JS-конструкциями:
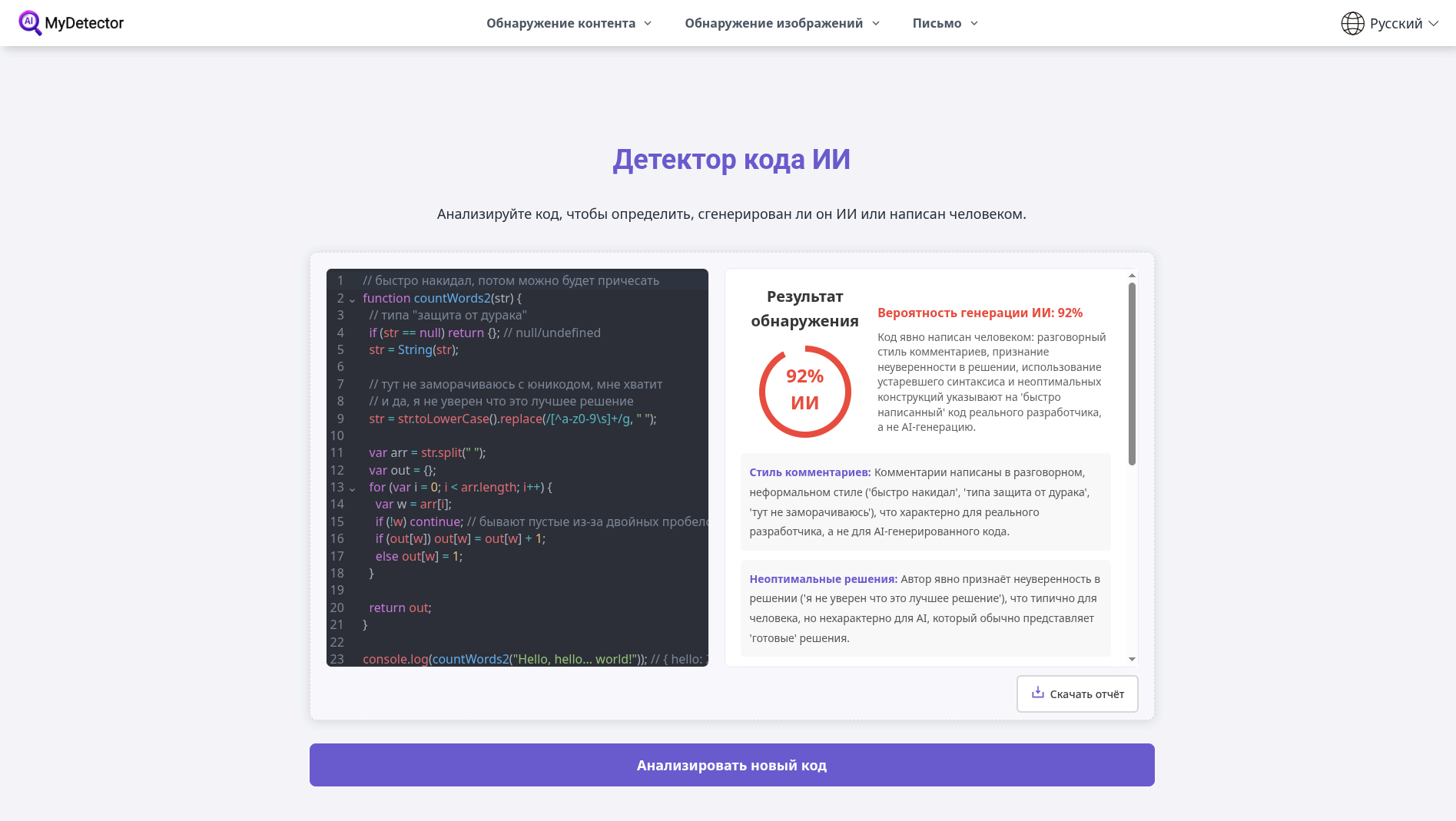
Вторая проверка оказалась особенно показательной: mydetector.ai одновременно поставил фрагменту 92% AI‑вероятности, но пояснил, что код написан человеком. По сути, сервис смешал два разных сигнала: числом он отмечает «похожесть на AI‑паттерны», а в комментарии реагирует на человеческий стиль — разговорные ремарки, сомнения автора, var и неидеальные конструкции. Из-за этого в отчете появляется прямое противоречие. Ниже вы можете посмотреть скриншот и цитату:
«Код явно написан человеком: разговорный стиль комментариев, признание неуверенности в решении, использование устаревшего синтаксиса и неоптимальных конструкций указывают на «быстро написанный» код реального разработчика, а не AI‑генерацию».
Переходим на aicodedetector.org, загружаем первый «аккуратный» фрагмент и удивляемся результату — оказывается, его с 66,6% вероятностью написал человек:
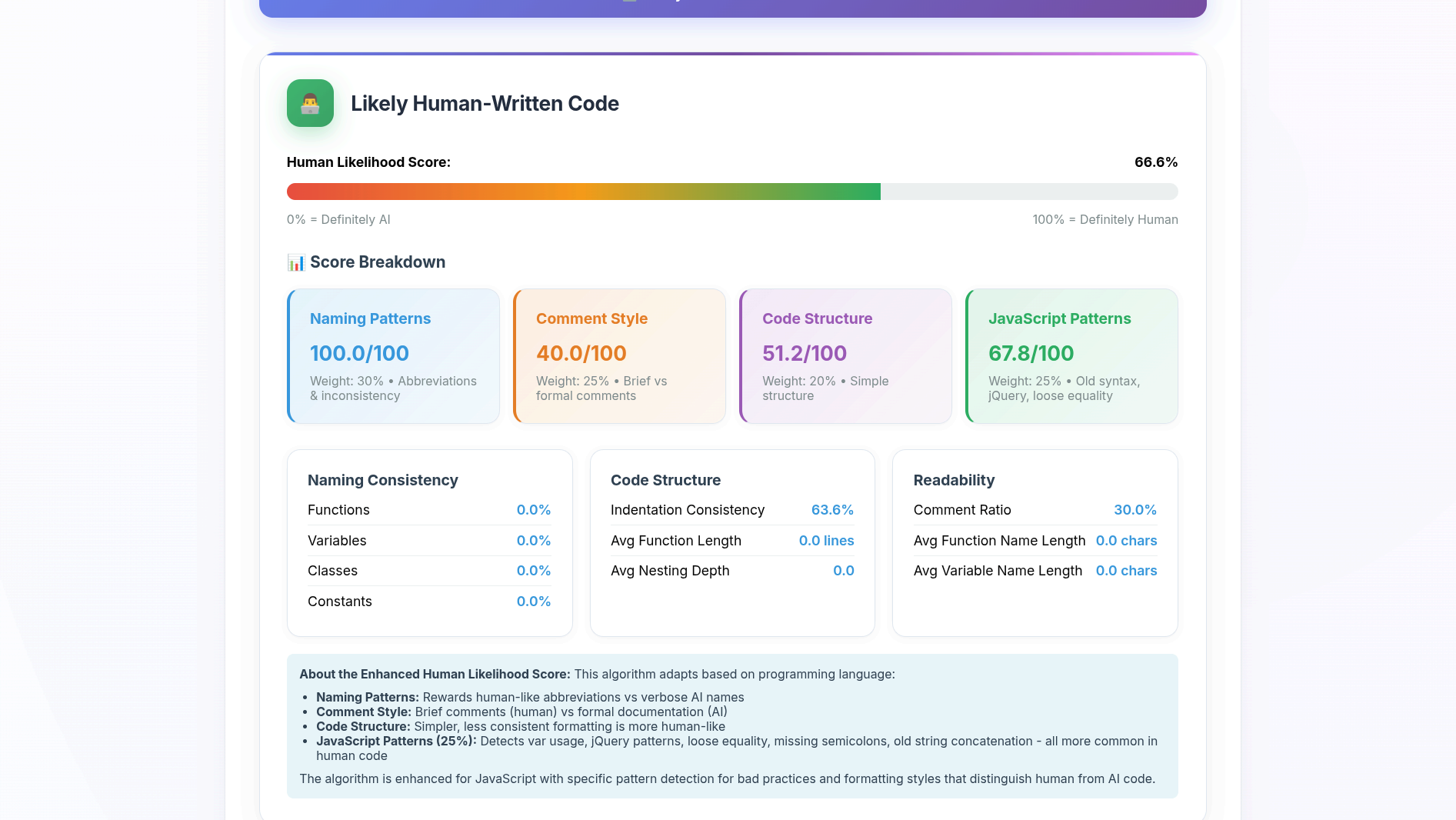
Проверяем второй фрагмент — результат 69,5%. Получается, этот детектор легко обмануть: достаточно добавить устаревший синтаксис, разговорные комментарии и неоптимальные конструкции. Выходит, что, по мнению нейросети, люди не способны писать аккуратный код. Не очень далеко от правды, но все равно обидно:
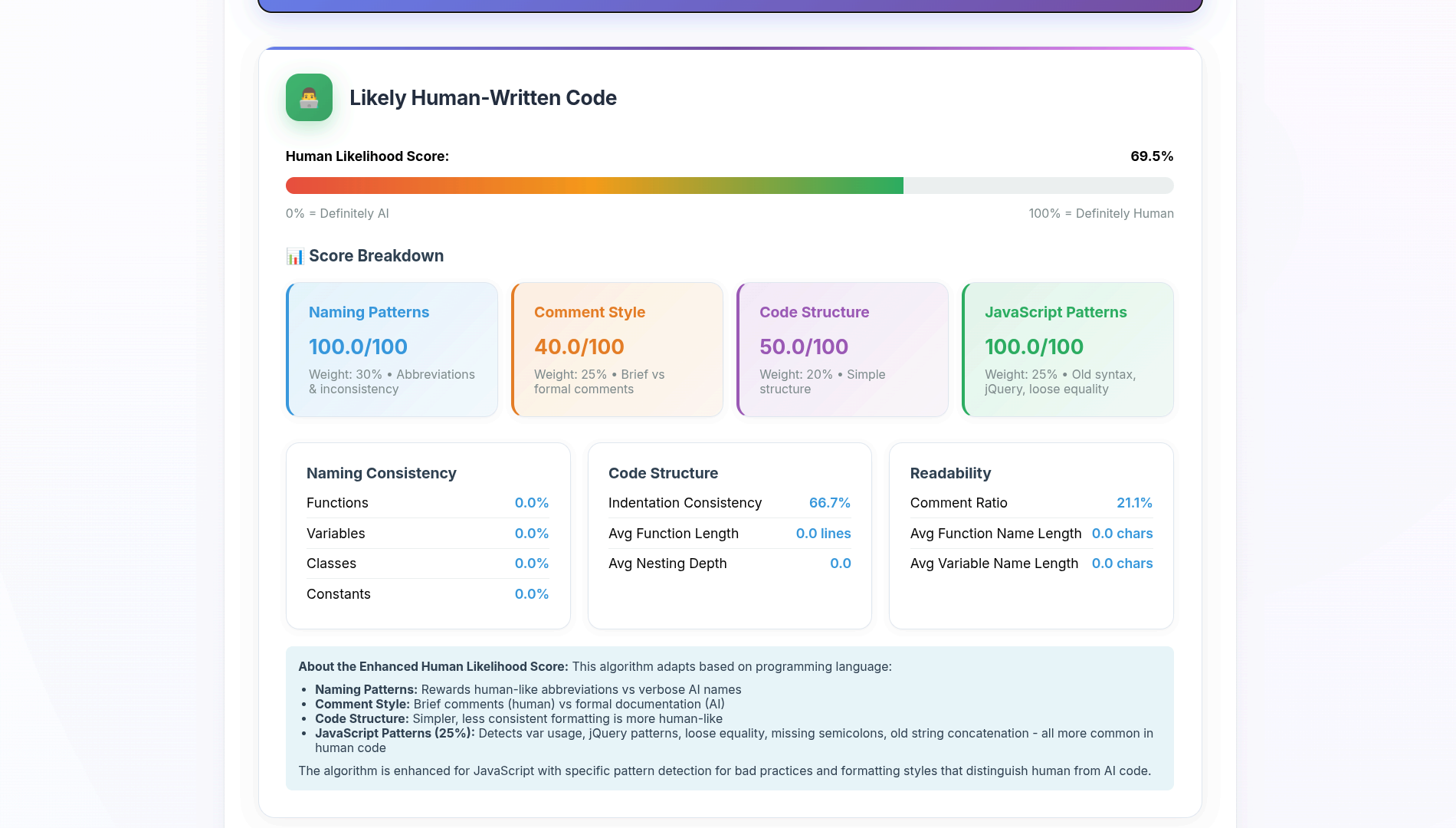
Остался сервис poe.com, но оказалось, что своими проверками задач на Codewars мы исчерпали лимит бесплатных запросов. Теперь мы можем продолжить тестирование, если оформим подписку или пополним баланс для расходования токенов. Более того, если наш код покажет высокий процент AI‑генерации, здесь же можно воспользоваться другим чат-ботом и с помощью магии нейросети быстро его «очеловечить». Согласитесь, напоминает бизнес по продаже воздуха в баночках.
Общие мысли и возмущения
По состоянию на 2026 год AI-детекторы кода — это неплохой психологический инструмент для преподавателей технических вузов. Они создают ситуацию, в которой студенты вынуждены вникать в написанный код и быть готовыми объяснить каждую его строчку. Результат проверки не так важен — если преподаватель заподозрил неладное, он всегда может задать уточняющие вопросы.
Для остальных сценариев польза сомнительна. Не существует универсального алгоритма, который мог бы безошибочно определять код, написанный нейросетью. Особенно сложно это сделать в проектах, где разработчики используют форматтеры, линтеры и следуют строгим стандартам оформления. В результате человеческий код становится таким же аккуратным, как и сгенерированный.
Например, если разработчик использует Prettier для форматирования JavaScript или Black для Python, его код будет выглядеть идеально: единый стиль отступов, расстановка пробелов по стандарту, правильный порядок импортов. Детектор может воспринять такую аккуратность как один из признаков AI-генерации.
Вот буквально в прошлом месяце нужно было срочно сверстать лендинг. Дедлайн горит, куча проблем с макетом, адаптив не нарисован. Ты пытаешься сделать рабочую верстку, согласовываешь все нюансы с заказчиком, и когда основная часть работы закончена, можно заняться наведением порядка. Например, отсортировать CSS-свойства внутри каждого селектора по группам: сначала позиционирование, затем блочная модель, потом оформление и так далее. На отображение страницы это никак не влияет, но если кто-то из коллег увидит беспорядок в коде — засмеют.
С помощью нейросетей эта сортировка делается за минуту и один промпт. Код останется полностью твоим, только один из этапов доводки выполнен с помощью инструмента. Для детектора это может выглядеть как «сигнал генерации», но по смыслу это обычная оптимизация процесса. И вот здесь есть тонкий момент.
Если такой код кто-то будет оценивать со стороны — они могут не вникать в детали и неправильно интерпретировать ситуацию. Просто поставят метку: «код написала нейросеть» — и все. Хорошо, если это двойка или пересдача. Но что делать, если это станет инструментом, из-за которого человека не возьмут на собеседование? Поэтому мы и считаем, что в текущем виде таким детекторам доверять не стоит.
В начале статьи мы говорили, что большинство программистов используют нейросети, и во многих командах они уже стали нормой. Никто ведь не будет проверять, использовали ли вы автодополнение кода с помощью плагина Emmet или написали все вручную. Так и здесь: важно не то, какими инструментами вы пользуетесь, а то, как с их помощью решаете задачи. Мы считаем, что нейросети не заменят разработчиков, но их заменят те, кто не учится ими пользоваться.

