


Если вы только начинаете свой путь в Data Science, вы наверняка уже слышали про алгоритм K-Means. Он популярный, простой, но… иногда ведет себя как слон в посудной лавке. Сегодня рассказываем про его более хитрого и гибкого кузена — алгоритм DBSCAN.
Обучение с учителем и без, или «Сортируем лего»
Прежде чем нырять в глубины алгоритма, быстро вспомним, где мы находимся на карте машинного обучения.
Глобально задачи ML делятся на два больших лагеря:
- Обучение с учителем (Supervised Learning).
- Обучение без учителя (Unsupervised Learning).
Представьте, что вы дали ребенку ведро с деталями лего.

Сценарий 1 (с учителем). Вы сидите рядом и говорите: «Красные кубики клади в левую коробку, а синие — в правую». У ребенка есть четкая инструкция (разметка данных) и правильные ответы. Это классификация.
Сценарий 2 (без учителя). Вы даете ведро и уходите пить кофе, бросив напоследок: «Разбери это как-нибудь». Ребенок остается один на один с данными. Он может разложить их по цветам. Может — по размеру. А может построить из них домики. Никто не сказал ему, что правильно, а что нет. Он ищет структуру в данных самостоятельно.
Кластеризация — это задача обучения без учителя. Ее цель — сгруппировать объекты так, чтобы похожие оказались в одной группе (кластере), а непохожие — в разных.
Самый известный алгоритм здесь — K-Means (К-средних). Но у него есть фатальный недостаток: вы должны заранее сказать ему, сколько кластеров нужно найти (число К). А что, если вы не знаете? Что, если данные имеют странную форму, а не форму идеальных шариков?
Вот тут на сцену выходит DBSCAN.
Как работает алгоритм DBSCAN?
DBSCAN расшифровывается как Density-Based Spatial Clustering of Applications with Noise. Звучит страшно, но на самом деле название говорит само за себя: «Пространственная кластеризация на основе плотности с шумом».
Давайте разберем это на примере из жизни.
Представьте, что вы на огромной вечеринке под открытым небом. Люди стоят группами, общаются. Где-то толпа плотная, не протолкнуться. Где-то стоят парочки. А где-то бродят одиночки, которые ни с кем не разговаривают.
DBSCAN работает как социолог на этой вечеринке. Он не пытается разделить поле на равные квадраты. Он ищет плотные компании.
Два главных рычага управления (гиперпараметры)
Чтобы запустить DBSCAN, нам нужно задать всего два параметра:
- Epsilon ( или eps) — радиус дружбы. Представьте, что это длина вытянутой руки. Если человек стоит от вас на расстоянии вытянутой руки, вы считаете его своим соседом.
- MinPts (min_samples) — минимальное количество людей, чтобы считать это место тусовкой. Например, мы решаем, что тусовка — это когда рядом стоит минимум четыре человека.
Три типа людей (точек)
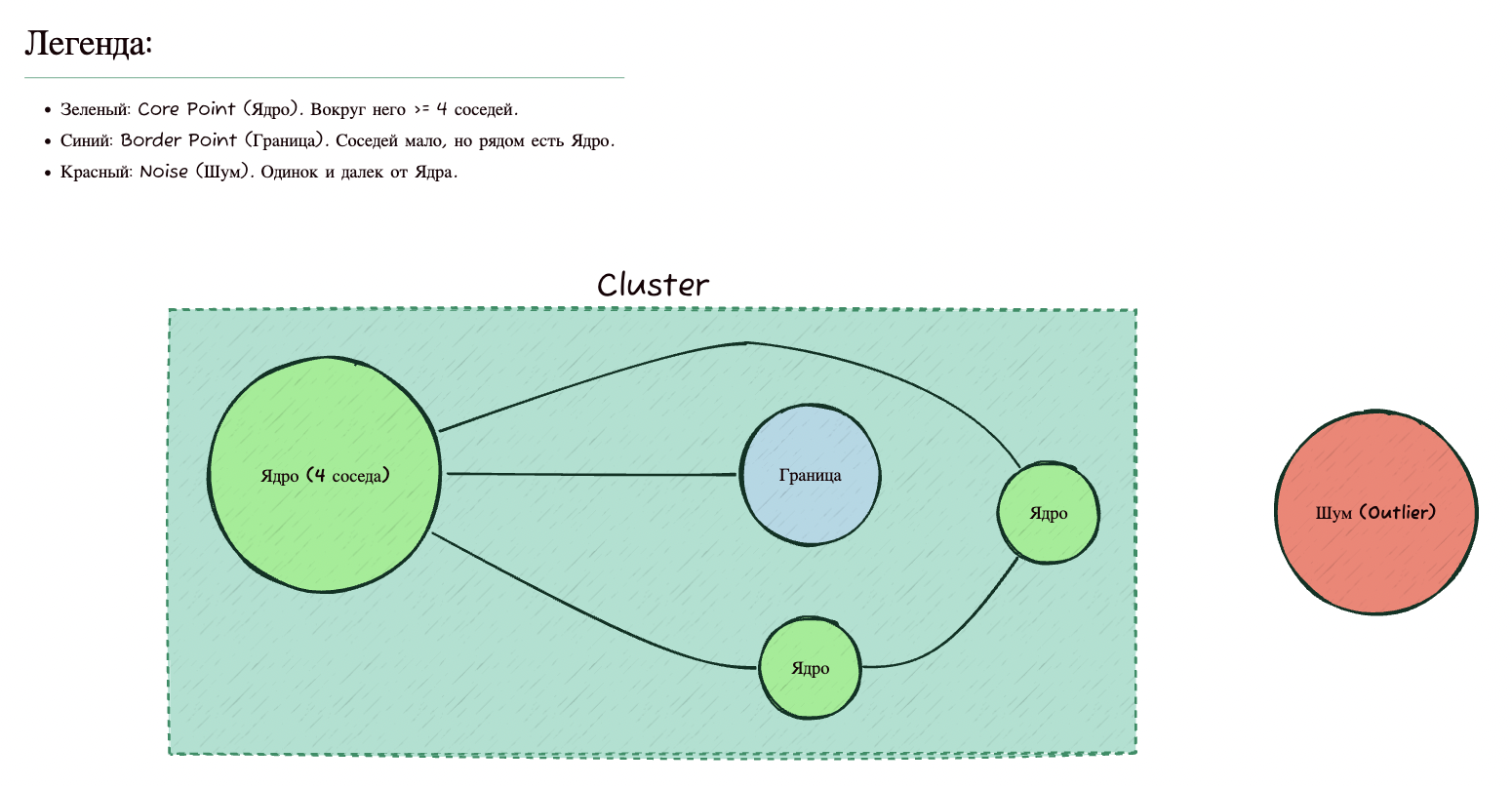
На основе этих двух параметров DBSCAN делит все точки данных на три категории:
- Ядровые точки (Core Points). Это душа компании — у такой точки в радиусе находится не менее MinPts соседей (включая ее саму). Это центр кластера.
- Граничные точки (Border Points). Это те, кто стоит с краю компании. У них в радиусе соседей меньше, чем MinPts, но среди их соседей есть хотя бы одна ядровая точка. То есть они присоседились к тусовке, но сами тусовку не образуют.
- Шум (Noise/Outliers). Это одиночки. У них мало соседей, и среди соседей нет ни одной ядровой точки. Они никому не нужны, алгоритм помечает их как выбросы (–1).
Визуализация логики
Давайте посмотрим на диаграмму, чтобы закрепить понимание. Представим, что MinPts = 4.
Алгоритм по шагам:
- Берем случайную точку, которую еще не проверяли.
- Смотрим вокруг нее в радиусе ε.
- Если соседей много ( ≥ MinPts): поздравляем, мы нашли новый кластер! Помечаем точку как ядровую. Затем мы начинаем «заражать» соседей. Проверяем каждого соседа этой точки: если он тоже ядровый, мы расширяем кластер дальше. Это как цепная реакция или лесной пожар: кластер растет, пока плотность точек высокая.
- Если соседей мало (< MinPts): помечаем точку как шум. (Важно: позже она может стать граничной, если до нее дотянется растущий кластер с другой стороны, но пока она — шум.)
- Повторяем, пока не посетим все точки.
Плюсы и минусы DBSCAN по сравнению с другими алгоритмами
Почему этот алгоритм используется для решения задач? Потому что он решает проблемы, о которые ломает зубы популярный K-Means.
Плюсы DBSCAN:
- Не нужно знать число кластеров. В K-Means вы обязаны сказать: «Найди мне три кластера». А если их там пять? Или два? K-Means все равно найдет три, просто они будут бессмысленными. DBSCAN сам определит оптимальное количество групп.
- Кластеры любой формы. K-Means обожает круги (сферы). Если ваши данные выглядят как один банан, вложенный в другой банан, K-Means разрежет их посередине. DBSCAN же поймет, что банан — это вытянутая изогнутая структура, и корректно выделит ее, переходя от соседа к соседу.
- Устойчивость к выбросам (шуму). Это киллер-фича. Если в ваших данных есть ошибки, случайные всплески или просто мусор, K-Means обязательно включит их в какой-то кластер, сместив центроиды и испортив точность. DBSCAN просто скажет: «Это шум, я не буду это кластеризовать». Это делает его отличным инструментом для поиска аномалий.
Минусы DBSCAN:
- Проблема разной плотности. Представьте, что у вас есть две группы людей: одна стоит в тесном лифте (очень высокая плотность), а другая разбрелась по футбольному полю (низкая плотность). Если вы выберете маленький (радиус), то людей на поле алгоритм посчитает шумом. Если выберете большой , то он объединит всех в лифте в одну кучу с людьми из соседних комнат. DBSCAN плохо работает, когда кластеры имеют сильно различающуюся плотность.
- Проклятие размерности. Если у ваших данных очень много признаков (сотни колонок), понятие расстояния теряет физический смысл (все точки становятся примерно равноудаленными друг от друга). В таких случаях DBSCAN работает плохо без предварительного сжатия данных (например, через PCA).
- Сложность выбора параметров. Подобрать eps иногда — настоящее искусство.

Для каких задач стоит использовать DBSCAN?
Зная плюсы и минусы, мы можем очертить круг идеальных задач для этого алгоритма.
1. Геоаналитика и GPS-трекинг. Это классика. У вас есть координаты такси в городе.
- Кластеры: стоянки такси, популярные места высадки.
- Шум: машина, которая просто едет по трассе. DBSCAN идеально повторяет изгибы улиц, не пытаясь вписать их в круги.
2. Детекция аномалий (Fraud Detection). Банковские транзакции. Большинство операций — нормальные (плотный кластер). Но есть единичные случаи мошенничества, которые сильно отличаются по сумме, времени или месту. DBSCAN пометит их как −1 (шум), что нам и нужно!
3. Сегментация изображений. Выделение объектов на фоне. Если пиксели имеют схожий цвет и находятся рядом, они объединяются в один объект.
4. Рекомендательные системы. Группировка пользователей с очень похожим, специфичным поведением, отсеивая ботов или случайных посетителей (шум).
5. Астрономия. Поиск скоплений звезд и галактик на небесных снимках. Вселенная полна шума, и формы галактик далеки от идеальных сфер.
Пример использования DBSCAN в Python
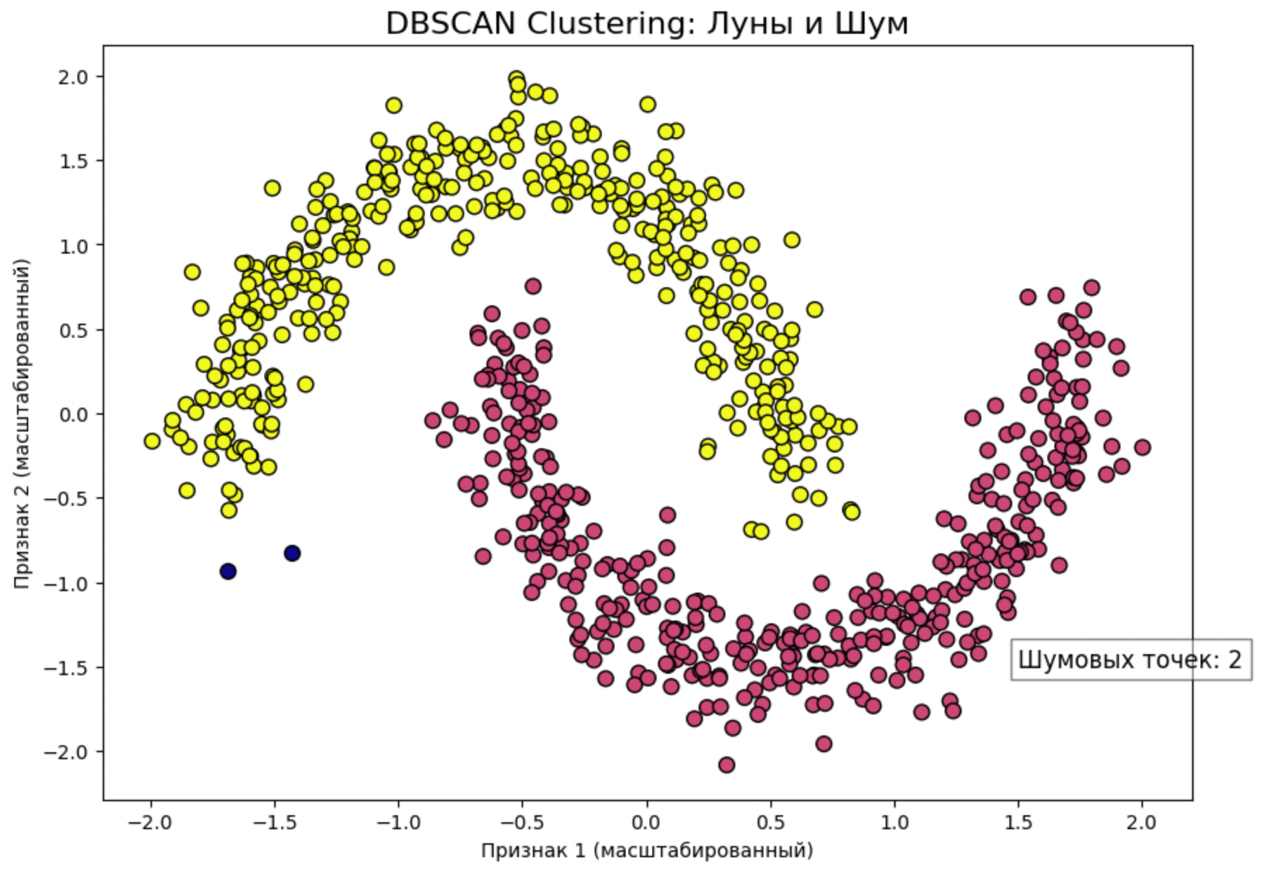
Хватит теории, давайте кодить! Для примера мы возьмем синтетический набор данных make_moons. Это две дуги, вложенные друг в друга. Для K-Means это ночной кошмар, а для DBSCAN — легкая прогулка.
Мы будем использовать библиотеку scikit-learn.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons
from sklearn.preprocessing import StandardScaler
# 1. Создаем данные
# n_samples=750: количество точек
# noise=0.1: добавляем немного разброса, чтобы жизнь медом не казалась
X, y = make_moons(n_samples=750, noise=0.1, random_state=42)
# ВАЖНЫЙ МОМЕНТ!
# DBSCAN основан на расстоянии. Если один признак измеряется в миллиметрах,
# а другой в километрах, алгоритм сломается.
# Всегда масштабируйте данные перед DBSCAN!
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 2. Обучаем модель
# eps=0.3: радиус поиска соседей (после масштабирования данные имеют среднее 0 и станд. откл. 1)
# min_samples=5: нужно 5 точек, чтобы образовать ядро
dbscan = DBSCAN(eps=0.3, min_samples=5)
clusters = dbscan.fit_predict(X_scaled)
# 3. Визуализация
plt.figure(figsize=(10, 7))
# Рисуем точки. c=clusters окрасит их в разные цвета в зависимости от метки
# Точки с меткой -1 (шум) будут окрашены в отдельный цвет
plt.scatter(X_scaled[:, 0], X_scaled[:, 1], c=clusters, cmap='plasma', s=60, edgecolors='black')
plt.title('DBSCAN Clustering: Луны и Шум', fontsize=16)
plt.xlabel('Признак 1 (масштабированный)')
plt.ylabel('Признак 2 (масштабированный)')
# Добавим пояснение про шум
n_noise_ = list(clusters).count(-1)
plt.text(1.5, -1.5, f'Шумовых точек: {n_noise_}', fontsize=12, bbox=dict(facecolor='white', alpha=0.5))
plt.show()
Разбор кода: что здесь происходит?
- make_moons: мы создали две дуги. Если бы вы натравили сюда K-Means, он провел бы линию посередине, разбив каждую дугу на две части.
- StandardScaler: запомните это как «Отче наш». DBSCAN измеряет евклидово расстояние. Если вы не приведете данные к одному масштабу, признак с большими числами будет доминировать.
- eps=0.3: как я выбрал это число? Честно? Методом проб. Но есть и научный метод — график K-расстояний (k-distance graph), где мы ищем «локоть» (резкий перегиб графика расстояний до ближайшего соседа).
- Результат: при запуске вы увидите, что DBSCAN идеально раскрасил две дуги в разные цвета, а несколько точек, выбивающихся из общей массы, пометил как шум (темно-синим цветом).
Как подбирать параметры на практике?
Это самый частый вопрос новичков.
- MinPts. Хорошее эмпирическое правило — брать MinPts размерность данных + 1. Если у вас 2D-данные (как в примере), берите минимум 3 или 4. Если данные очень шумные, увеличивайте это число.
- Eps. Тут ситуация сложнее. Слишком маленький eps — и у вас будет куча шума и миллион маленьких кластеров. Слишком большой eps — и все сольется в один гигантский ком. Обычно начинают с малого и постепенно увеличивают, смотря на процент точек, помеченных как шум.
Коротко об алгоритме DBSCAN
DBSCAN — это мощный инструмент в арсенале дата-сайентиста. Он похож на воду, которая заполняет углубления любой формы, в отличие от K-Means, который пытается накрыть все круглыми крышками.
Главное, что нужно запомнить:
- DBSCAN сам находит количество кластеров.
- Он умеет работать с данными сложной формы (дуги, спирали, кляксы).
- Он отлично фильтрует мусор (шум).
- Он чувствителен к масштабированию данных (не забывайте про StandardScaler!).
- Он может пасовать перед данными с разной плотностью.
В машинном обучении нет «серебряной пули», нет алгоритма, который идеален всегда. Но если вы работаете с реальными, «грязными» данными, где есть выбросы, а структура кластеров неочевидна, — DBSCAN часто становится лучшим выбором.
Пробуйте, экспериментируйте с параметрами, и пусть ваши кластеры всегда будут плотными, а шум — минимальным!