
Scikit-learn (sklearn) — это один из наиболее широко используемых пакетов Python для Data Science и Machine Learning. Он содержит функции и алгоритмы для машинного обучения: классификации, прогнозирования или разбивки данных на группы. Sklearn написана на языках Python, C, C++ и Cython.


Зачем нужна Scikit-learn
Первый релиз библиотеки вышел в 2007 году. Ее используют программисты, которые работают в Data Science и Machine Learning. Они используют библиотеку при построении моделей для обучения как с учителем, так и без.
Scikit-learn применяется:
- в рекомендательных системах: например, реклама на основе ваших ранее проявленных интересов или сервис музыки с «умными» рекомендациями;
- для распознавание текста и изображений;
- для предсказания поведения пользователей, финансовых колебаний и других прогнозируемых явлений на основе существующих данных;
- для классификации данных и автоматического построения метрик в бизнес-анализе;
- при распределении и обработке результатов исследований — научных, медицинских и других.
Это только часть возможных вариантов применения Scikit-learn в бизнесе. Машинное обучение используется в десятках сфер, перечислить все просто не получится.

Зависимости Scikit-learn
Scikit-learn основана на других библиотеках, которые тоже применяются в машинном обучении, анализе данных, компьютерном зрении и смежных сферах.
- NumPy — библиотека для работы с многомерными массивами числовых данных и со сложными математическими операциями.
- SciPy — набор продвинутых математических и научных функций. Основана на NumPy, но глубже и функциональнее.
- Matplotlib — библиотека для визуализации и построения графиков. Поддерживает двумерные и трехмерные построения.
- Pandas — библиотека для обработки данных, анализа и манипуляций с ними.
- SymPy — библиотека для работы с символьной математикой.
- IPython — интерактивная консоль для более удобной работы с библиотеками. Среди ее возможностей — автодополнение фраз, подсветка кода, поддержка визуализации данных и многое другое.
Какие задачи решает библиотека
Препроцессинг. Термин «препроцессинг» (preprocessing) означает предварительную обработку данных. Они приводятся к виду, необходимому для подачи на вход какому-либо алгоритму. Например, изображения подгоняются под один размер и цветовую схему. Из данных извлекаются ключевые признаки, по которым будет обучаться модель, и также приводятся к нужному формату.
Уменьшение размерности. Часто в данных содержится избыточная информация. Например, некоторые признаки можно получить из каких-либо других. Чтобы сделать дальнейший анализ эффективнее, размерность выборки уменьшают — так, чтобы сохранить максимум полезных данных. Для этого используются специальные методы, например метод главных компонент.
Обнаружение аномалий. Алгоритмы «отсекают» из набора данных ошибочные или странные записи, которые только добавляют в результат лишние погрешности. Это нужно, чтобы анализ и обучение работали точнее.
Выбор датасета. Если необходимо познакомиться с библиотекой, можно воспользоваться одним из готовых учебных наборов. Они тоже есть в библиотеке.
Выбор модели. Функции и алгоритмы помогают оценить эффективность разных моделей для решения задачи. Их можно сравнивать друг с другом, проводить валидацию результатов, выбирать более точные. Это нужно для улучшения качества обучения.
Регрессия. Это прогнозирование показателей по уже имеющимся данным, которые могут принимать бесконечное количество разных значений. Эти показатели должны быть связаны с каким-либо объектом, т.е. быть его атрибутами. Например, прогноз числа пользователей на сайте в разные дни — это задача регрессии.
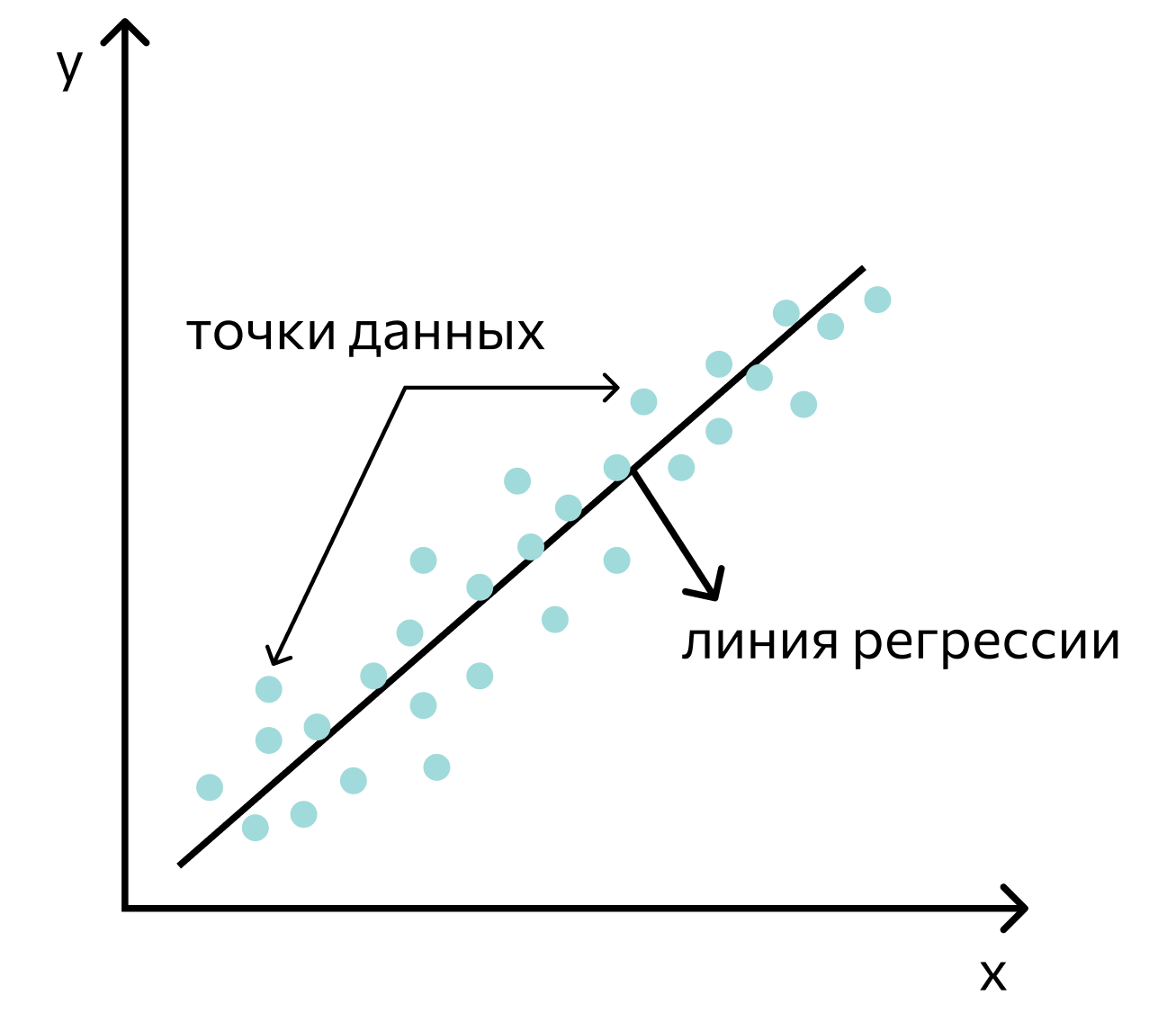
Классификация. Классификация — прогнозирование показателя с конечным количеством значений. Более простое определение — прогнозирование категории, к которой относится объект. Распознавание жанра текста или объектов на картинке — это задачи классификации.
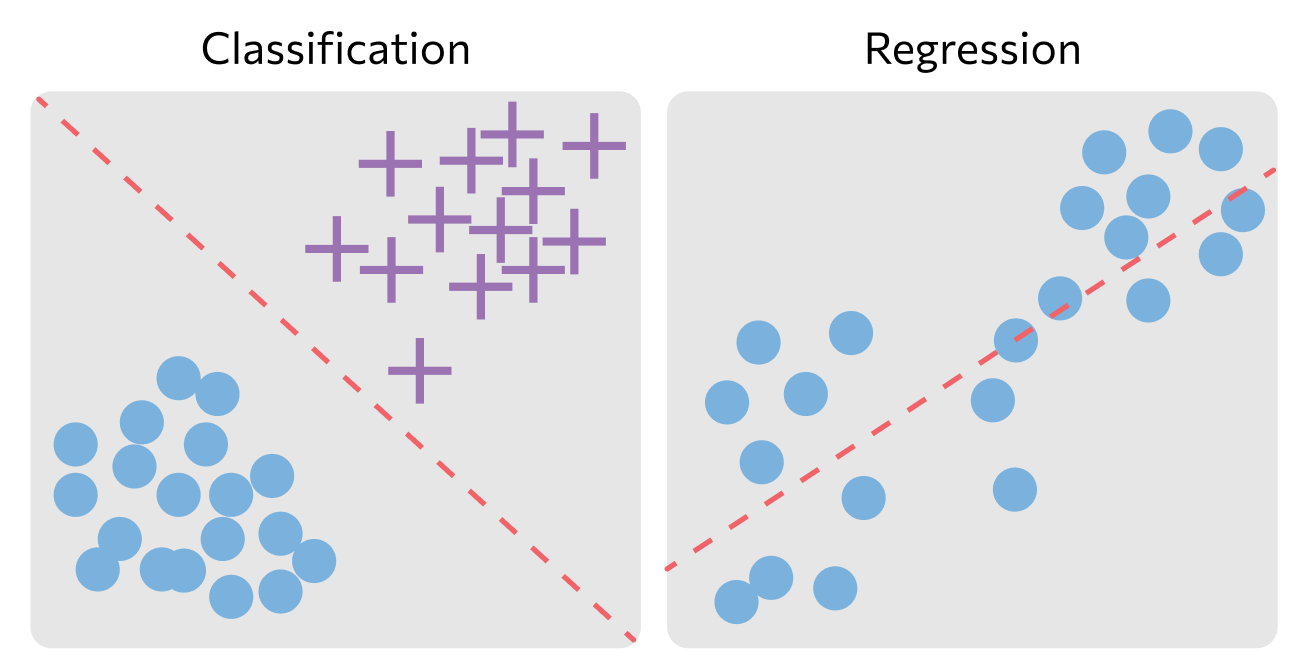
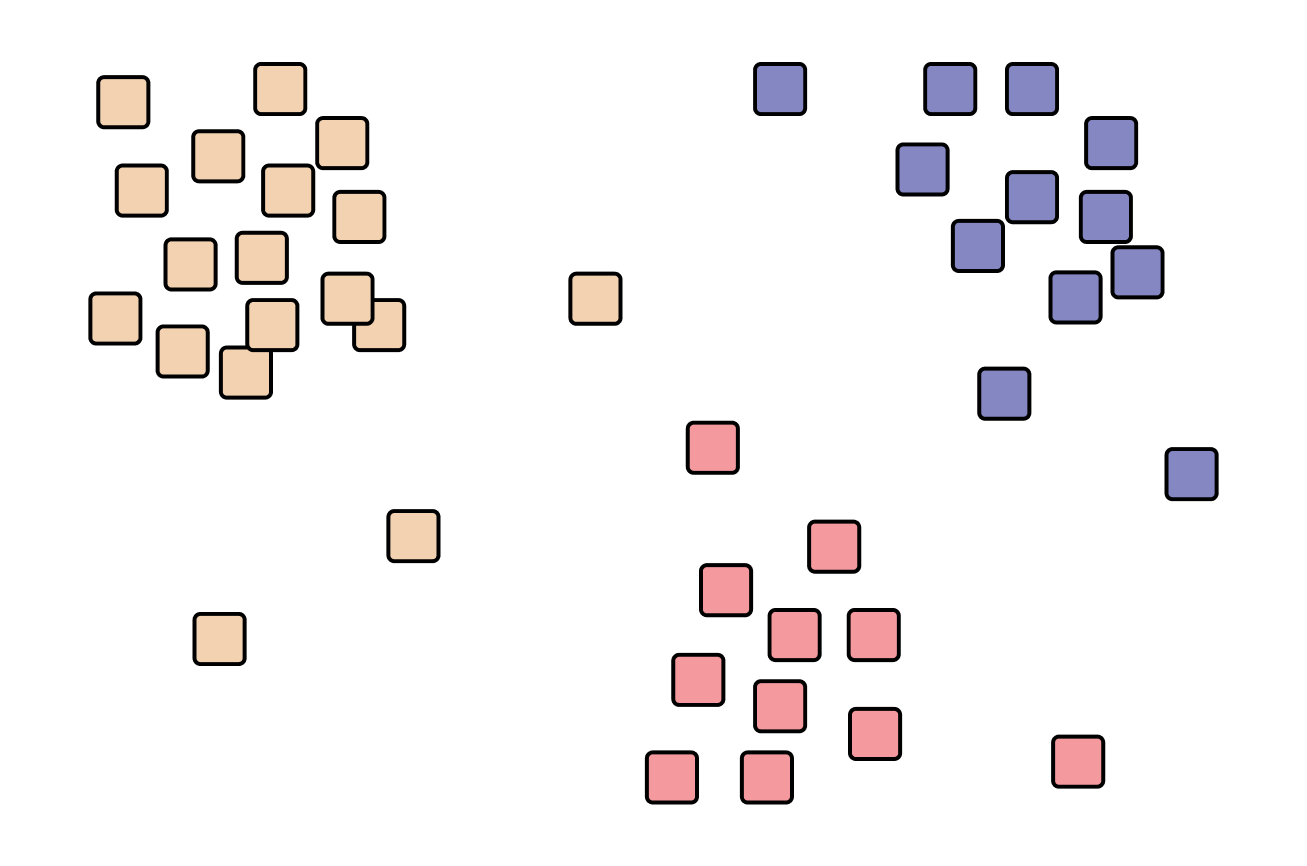
Кластеризация. Это распределение данных из датасета по большим группам — кластерам, т. е. их группировка. Похожие объекты объединяются в классы. Критерии, по которым определяется схожесть, зависят от модели и условий задачи.

Модели машинного обучения
Линейные. Модели с линейной зависимостью одних значений от других. Позволяют строить разделяющие плоскости или аппроксимировать результаты и использовать линейную регрессию.
Метрические. Предугадывают свойства объекта на основе его соседей. Относятся к так называемому ленивому обучению.
Деревья решений. Это древовидные модели, состоящие из наборов правил. Они принимают решения на основе входных условий.
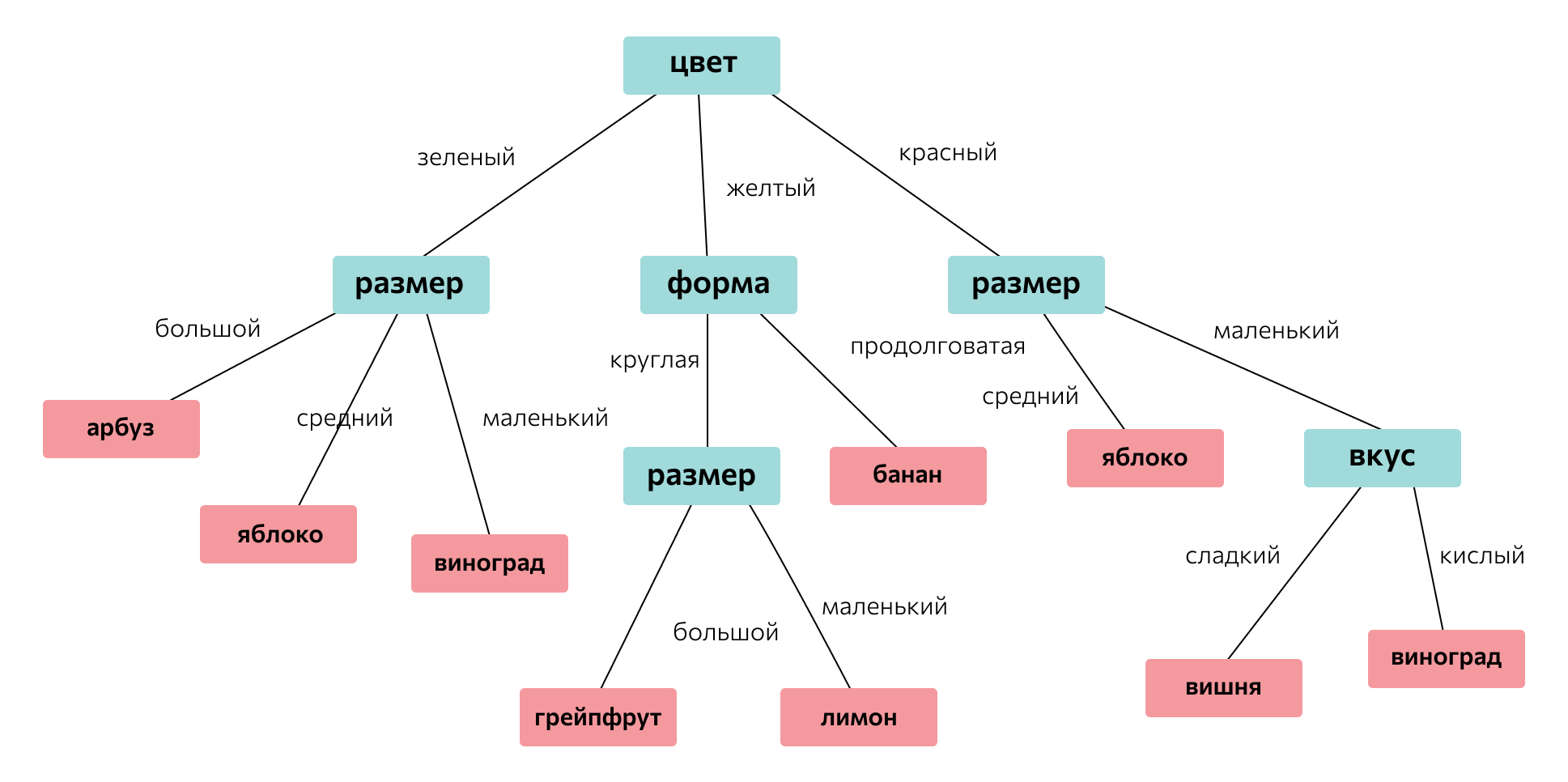
Ансамблевые. Методы, которые используют множество деревьев решений.
Нейросети. Модели, структура которых основана на биологических нейронных сетях, когда нейроны соединены между собой синапсами. Нейрон — вычислительная единица, синапс — путь для передачи информации от одного нейрона к другому. Такая модель самообучается с учетом предыдущего опыта и с каждым разом совершает все меньше ошибок.
Наивный Байес. Модели прогнозирования на основе теоремы Байеса (теорема из теории вероятностей).
Кросс-валидация. Метод многократного обучения, для которого используется датасет целиком. Для каждого шага валидация происходит с одной из частей датасета. Этот метод разбивает данные на несколько секций и обучает несколько алгоритмов на этих секциях.
Это только малая часть возможностей для примера. В библиотеку входят такие популярные методы, как PCA (метод главных компонент, один из основных способов уменьшить размерность данных с минимальными потерями информации), SVM (метод опорных векторов, набор схожих алгоритмов обучения с учителем, использующихся для задач классификации и регрессионного анализа) и другие.
Преимущества Scikit-learn
Многофункциональность. У Scikit-learn много возможностей, начиная с подготовки данных и заканчивая визуализацией результата. Она уже связана со многими технологиями, которыми пользуются в сфере машинного обучения, поэтому библиотеки достаточно для большинства задач, которые встают перед начинающим специалистом по Data Science. Это почти универсальное решение для машинного обучения.
Большое количество алгоритмов. В Scikit-learn входит огромный набор методов и алгоритмов, которые нужны для прогнозирования, кластеризации, распознавания и т.д. Их не нужно писать с нуля — для каждого есть своя функция. Достаточно подать на вход необходимые данные. Для типовых задач есть готовые решения, вплоть до учебных датасетов и подготовленных моделей.
Удобство использования. Связь с другими библиотеками, понятные названия функций и простой синтаксис делают работу удобной и простой.
Бесплатный доступ. Scikit-learn бесплатная и имеет открытый исходный код. Это значит, что любой разработчик может его посмотреть. Sklearn распространяется по свободной лицензии BSD: библиотеку можно использовать и в коммерческих проектах, и в бесплатном ПО. Репозиторий на сервисе GitHub открыт для всех желающих.
Кросс-платформенность. Библиотека Scikit-learn поддерживается операционными системами Linux, Windows и macOS, как и сам Python.
Широкое комьюнити. Специалисты по Data Science активно пишут туториалы, гайды и вспомогательные материалы. Получить информацию легко. А если есть вопросы — можно задать их на специализированном ресурсе и получить ответы от комьюнити.
Популярность. Sklearn используют в ряде крупных проектов: международные сервисы Spotify и Booking, мобильный оператор «Билайн», Газпромбанк, платформа поиска вакансий HeadHunter и т.д. Специалисту по машинному обучению, который владеет Scikit-learn, легко найти работу, в том числе в большой компании.
Недостатки Scikit-learn
Отсутствие ряда возможностей. В Sklearn мало инструментов для построения нейронных сетей. А также меньше возможностей для машинного обучения без учителя, чем для обучения с учителем. Поэтому для некоторых задач одной Scikit-learn будет недостаточно, несмотря на ее обширность.
Обилие зависимостей. Глубокая связь с другими библиотеками — одновременно и плюс, и минус. Конечно, удобнее выстраивать работу с несколькими инструментами одновременно, такой подход расширяет функциональность. Но еще это значит, что для работы с Scikit-learn нужно разбираться в ее зависимостях и желательно уметь пользоваться всеми связанными инструментами. Это повышает порог входа для новичков.
Сложность в изучении. Data Science — сложная отрасль. Нужно хорошо разбираться не только в программировании, но и в математике, алгоритмах прогнозирования и кластеризации. Необходима глубокая теоретическая база. Несмотря на то что сами модели не нужно строить с нуля, разработчик должен понимать, как они работают.

0 комментариев