
Pandas — это библиотека Python для обработки и анализа структурированных данных, ее название происходит от «panel data» («панельные данные»). Панельными данными называют информацию, полученную в результате исследований и структурированную в виде таблиц. Для работы с такими массивами данных и создан Pandas.

Введение: работа с открытым кодом
Pandas — это open source-библиотека, то есть ее исходный код в открытом доступе размещен на GitHub. Пользователи могут добавлять туда свой код: вносить пояснения, дополнять методы работы и обновлять разделы. Для работы потребуется компилятор (программа, которая переводит текст с языка программирования в машинный код) C/C++ и среда разработки Python. Подробный процесс установки компилятора С для разных операционных систем можно найти в документации Pandas.
В каких профессиях понадобится библиотека?
Навык работы с этой библиотекой пригодится дата-сайентистам или аналитикам данных. С помощью Pandas эти специалисты могут группировать и визуализировать данные, создавать сводные таблицы и делать выборку по определенным признакам.
Как установить Pandas
1. Скачать библиотеку
На официальном сайте Pandas указан самый простой способ начать работу с библиотекой. Для этого необходимо установить Anaconda — дистрибутив (форма распространения программного обеспечения, набор библиотек или программного кода для установки программы) для Python с набором библиотек. Безопасно скачать его можно на официальном сайте.

2. Настройка установки
Вот несколько советов по установке Anaconda для новичков:
— Выбирайте рекомендованные настройки, на первое время этого будет достаточно. Например, Install for: Just me (recommended).
— Но если не поставить галочку «Add Anaconda to my PATH environment variable», то Anaconda не будет запускаться по умолчанию, каждый раз ее нужно будет запускать отдельно.
— На вопрос: «Do you wish to initialize Anaconda3?» (Хотите ли вы инициализировать Anaconda3?) отвечайте «Да».
— После завершения установки перезагрузите компьютер.
3. Запуск JupyterLab
В командной строке Anaconda запустите JupyterLab — это интерактивная среда для работы с кодом, данными и блокнотами, которая входит в пакет дистрибутива. Для этого введите jupyter-lab.
4. Открытие блокнота
Создайте в JupyterLab новый блокнот Python3. Для его создания надо щелкнуть на значке «+», расположенном в верхней левой части интерфейса. В появившемся меню выбрать «Python 3» для создания блокнота.
5. Импорт библиотеки
В первой ячейке пропишите: import pandas as pd, после этого в следующих ячейках можно писать код.
DataFrame и Series
Чтобы начать анализировать данные с помощью Pandas, нужно понять, как устроены структуры этих данных внутри библиотеки. В первую очередь разберем, что такое DataFrame и Series.
Series
Pandas Series (серия) — это одномерный массив. Визуально он похож на пронумерованный список: слева в колонке находятся индексы элементов, а справа — сами элементы.
my_series = pd.Series([5, 6, 7, 8, 9, 10])
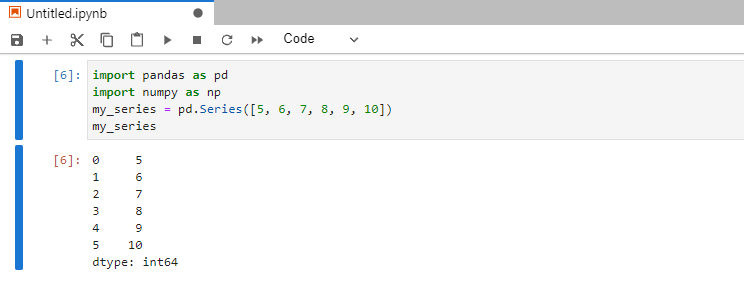
Индексом может быть числовой показатель (0, 1, 2…), буквенные значения (a, b, c…) или другие данные, выбранные программистом. Если особое значение не задано, то числовые индексы проставляются автоматически. Например, от 0 до 5 как в примере выше.
Такая нумерация называется RangeIndex, в ней всегда содержатся числа от 0 до определенного числа N, которое обозначает количество элементов в серии. Собственные значения индексов задаются в квадратных скобках через index, как в примере ниже:
my_series2 = pd.Series([5, 6, 7, 8, 9, 10]), index=['a', 'b', 'c', 'd', 'e', 'f'])

Индексы помогают обращаться к элементам серии и менять их значения. Например, чтобы в нашей серии [5, 6, 7, 8, 9, 10] заменить значения некоторых элементов на 0, мы прописываем индексы нужных элементов и указываем, что они равны нулю:
my_series2[['a', 'b', 'f']] = 0
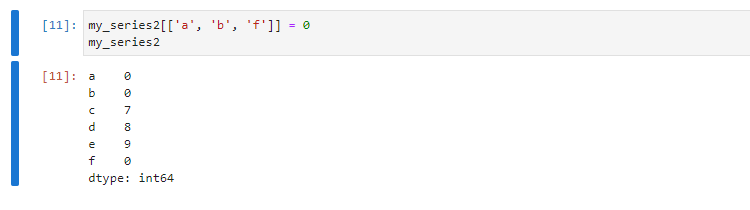
Можно сделать выборку по нескольким индексам, чтобы ненужные элементы в серии не отображались:
my_series2[['a', 'b', 'f']]
Результат:
a 5
b 6
f 10
dtype: int64DataFrame
Pandas DataFrame — это двумерный массив, похожий на таблицу/лист Excel (кстати, данные из табличных файлов Excel можно читать с помощью команды pandas.read_excel('file.xls')). В нем можно проводить такие же манипуляции с данными: объединять в группы, сортировать по определенному признаку, производить вычисления. Как любая таблица, датафрейм состоит из столбцов и строк, причем столбцами будут уже известные объекты — Series.
Чтобы проверить, действительно ли серии — это части датафрейма, можно извлечь любую колонку из таблицы. Возьмем набор данных о нескольких странах СНГ, их площади и населении и выберем колонку country:
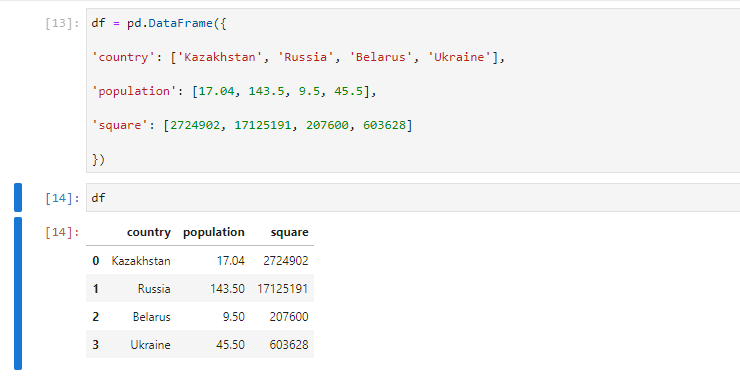
df = pd.DataFrame({
'country': ['Kazakhstan', 'Russia', 'Belarus', 'Ukraine'],
'population': [17.04, 143.5, 9.5, 45.5],
'square': [2724902, 17125191, 207600, 603628]
})
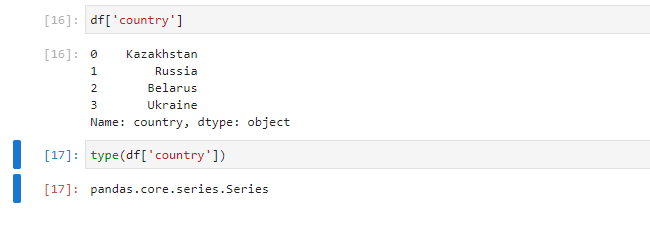
В итоге получится простая серия, в которой сохранятся те же индексы по строкам, что и в исходном датафрейме:
df['country']
type(df['country'])

Кроме этого, у датафрейма есть индексы по столбцам, которые задаются вручную. Для простоты написания кода обозначим страны индексами из двух символов: Kazakhstan — KZ, Russia — RU и так далее:
# Создаем датафрейм с заданными индексами
df = pd.DataFrame({
'country': ['Kazakhstan', 'Russia', 'Belarus', 'Ukraine'],
'population': [17.04, 143.5, 9.5, 45.5],
'square': [2724902, 17125191, 207600, 603628]
}, index=['KZ', 'RU', 'BY', 'UA'])
Результат:
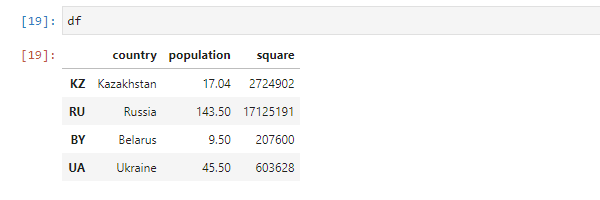
# Изменяем индексы df.index = ['KZ', 'RU', 'BY', 'UA'] df.index.name = 'Country Code'
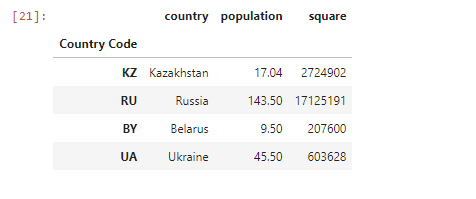
По индексам можно искать объекты и делать выборку, как в Series. Возьмем тот же датафрейм и сделаем выборку по индексам KZ, RU и колонке population методом .loc (в случае .loc мы используем квадратные скобки, а не круглые, как с другими методами), чтобы сравнить население двух стран:
df.loc[['KZ', 'RU'], 'population']
Anaconda выведет следующее:
Country Code
KZ 17.04
RU 143.50
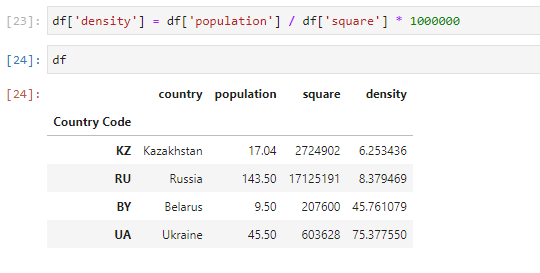
Name: population, dtype: float64Также в DataFrame производят математические вычисления. Например, рассчитаем плотность населения каждой страны в нашем датафрейме. Данные в колонке population (численность населения) делим на square (площадь) и получаем новые данные в колонке density, которые показывают плотность населения:
# Вычисление плотности населения df['density'] = df['population'] / df['square'] * 1000000
Чтение и запись данных
В Pandas работают с форматами csv, excel, sql, html, hdf и другими. Полный список можно посмотреть с помощью метода .read, где через нижнее подчеркивание «_» будут указаны все доступные форматы.
Ниже представлены примеры чтения и записи данных на Python с использованием Pandas:
Чтение данных:
- Чтение данных из CSV файла:
import pandas as pd
# Чтение CSV файла
data = pd.read_csv('data.csv')
# Вывод первых нескольких строк датафрейма
print(data.head())
- Чтение данных из Excel файла:
# Чтение данных из Excel файла
data = pd.read_excel('data.xlsx')
# Вывод первых нескольких строк датафрейма
print(data.head())
- Чтение данных из SQL базы данных:
from sqlalchemy import create_engine
# Создание подключения к базе данных
engine = create_engine('sqlite:///database.db')
# Чтение данных с помощью SQL запроса
query = "SELECT * FROM table_name"
data = pd.read_sql(query, engine)
# Вывод первых нескольких строк датафрейма
print(data.head())
Запись данных:
- Запись данных в CSV или Exсel файл:
# Создание датафрейма
data = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 22]
})
# Запись в CSV файл (или Exсel, нужно будет поменять расширение ниже)
data.to_csv('output.csv', index=False)
- Запись данных в SQL базу данных:
import pandas as pd
from sqlalchemy import create_engine
# Создание датафрейма
data = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 22]
})
# Создание подключения к базе данных
engine = create_engine('sqlite:///new_database.db')
# Запись данных в базу данных
data.to_sql('new_table', engine, index=False, if_exists='replace')
Доступ по индексу в DataFrame
Для поиска данных в библиотеке Pandas используются два метода: .loc и .iloc. Рассмотрим их функциональность и применение.
Метод .loc:
Метод .loc предоставляет доступ к данным по заданному имени строки (индексу) в DataFrame. Рассмотрим пример с набором данных о скорости и ядовитости нескольких видов змей:
data = {'max_speed': [1, 4, 7],
'shield': [2, 5, 8]}
index = ['cobra', 'viper', 'sidewinder']
df = pd.DataFrame(data, index=index)
# Вывод датафрейма
print(df)
Результат:
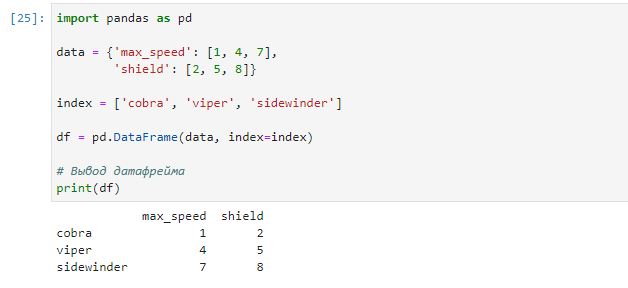
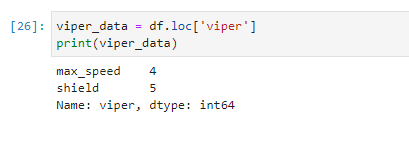
Используя метод .loc, мы можем получить информацию о конкретном виде змеи, например, гадюке (viper):
# Получение данных о гадюке (viper) viper_data = df.loc['viper'] print(viper_data)
Метод .iloc:
Метод .iloc позволяет осуществлять доступ к данным по порядковому номеру строки в DataFrame. Рассмотрим пример с набором данных, имеющим числовые индексы:
mydict = [{'a': 1, 'b': 2, 'c': 3, 'd': 4},
{'a': 100, 'b': 200, 'c': 300, 'd': 400},
{'a': 1000, 'b': 2000, 'c': 3000, 'd': 4000}]
df = pd.DataFrame(mydict)
# Вывод датафрейма
print(df)
a b c d
0 1 2 3 4
1 100 200 300 400
2 1000 2000 3000 4000
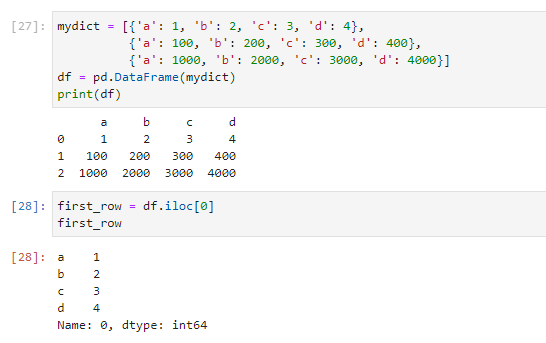
Используя метод .iloc, можно получить данные из первой строки с индексом 0:
first_row = df.iloc[0] first_row
Группировка и агрегирование данных
Для этого используется метод .groupby, он позволяет проводить анализ отдельные группы данных и сравнивать показатели. Например, у нас есть несколько обучающих курсов, информация о которых хранится в одной таблице. Нужно проанализировать, какой доход приносит каждый из них:
Используем .groupby и указываем название колонки title, на основе которой Pandas объединит все данные. После этого используем метод .agregate – он поможет провести математические вычисления, то есть суммировать стоимость внутри каждой группы.
import pandas as pd
# Создание DataFrame с данными о курсах
data = {
'title': ['Курс A', 'Курс B', 'Курс C', 'Курс D', 'Курс E'],
'income': [100, 150, 200, 120, 180]
}
df = pd.DataFrame(data)
# Группировка данных по названию курса и агрегирование дохода
grouped = df.groupby('title', as_index=False).aggregate({'income': 'sum'})
grouped
Обратите внимание на as_index=False, эта часть кода отвечает за то, чтобы сохранить числовые индексы в результатах группировки и вычисления.

Сводные таблицы в Pandas
Их используют для обобщения информации, собранной об объекте исследования. Когда исходных данных много и все они разного типа, составление таблиц помогает упорядочить информацию. Чтобы создавать на Python сводные таблицы, тоже используют библиотеку Pandas, а именно — метод .pivot_table.
Для примера возьмем условный набор данных с простыми категориями one / two, small / large и числовыми значениями. В столбце A две категории foo / bar складываются в слово foobar — текст, который используется в программировании для условного обозначения. В этом случае он указывает, что мы делим данные на две группы по неопределенному признаку.
df = pd.DataFrame({"A": ["foo", "foo", "foo", "foo", "foo",
"bar", "bar", "bar", "bar"],
"B": ["one", "one", "one", "two", "two",
"one", "one", "two", "two"],
"C": ["small", "large", "large", "small",
"small", "large", "small", "small",
"large"],
"D": [1, 2, 2, 3, 3, 4, 5, 6, 7],
"E": [2, 4, 5, 5, 6, 6, 8, 9, 9]})
df
Результат выполнения кода:

С помощью метода .pivot_table преобразуем эти данные в таблицу, а в скобках прописываем условия.
table = pd.pivot_table(df, values='D', index=['A', 'B'], columns=['C'], aggfunc=np.sum) table
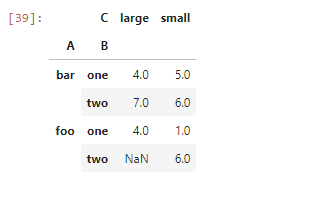
Мы разбиваем данные на две категории: bar и foo, в каждой из них будут подгруппы со значениями one и two, которые в свою очередь делятся на small и large. В сводной таблице мы вычисляем, сколько объектов будет в каждой группе. Для этого используем методы values, index, columns и aggfunc:
- values — метод для агрегации, объединяет элементы в одну систему;
- index и columns — методы, отвечающие за группировку столбцов;
- aggfunc — метод, который передает список функций, необходимых для расчета.
Визуализация данных в Pandas
Дата-аналитики составляют наглядные графики с помощью Pandas и библиотеки Matplotlib — краткое руководство по работе с этим пакетом можно найти на официальном сайте. Там же есть подробная информация о доступных функциях и модулях. Связка Pandas и Matplotlib отвечает за вычислительную часть работы, а вспомогательная библиотека «создает» картинку.
Посмотрим на данные о продажах в одной из компаний:
| Число покупок на одного покупателя | Количество покупателей |
|---|---|
| 7000 | 4 |
| 3755 | 6 |
| 2523 | 13 |
| 541 | 16 |
| 251 | 21 |
| 1 | 31 |
В таблице видно, что одни пользователи совершили уже более 7 000 покупок, а некоторые — сделали первую. Чтобы увидеть подробную картину, составляем график sns.distplot. На горизонтальной оси будет отображаться число покупок на одного покупателя, а на вертикальной — количество покупателей, которые совершили именно столько покупок в этой компании. Так по графику можно определить, что самой многочисленной оказалась группа клиентов, которая совершила всего несколько покупок, а группа постоянных клиентов немногочисленная.
import seaborn as sns
import matplotlib.pyplot as plt
# Создание данных
purchase_counts = [7000, 3755, 2523, 541, 251, 1]
customer_counts = [4, 6, 13, 16, 21, 31]
# Создание графика
sns.set(style="whitegrid")
sns.distplot(purchase_counts, bins=20, kde=False, hist_kws={"alpha": 0.7})
plt.xlabel('Число покупок на одного покупателя')
plt.ylabel('Количество покупателей')
plt.title('Распределение числа покупок')
plt.show()
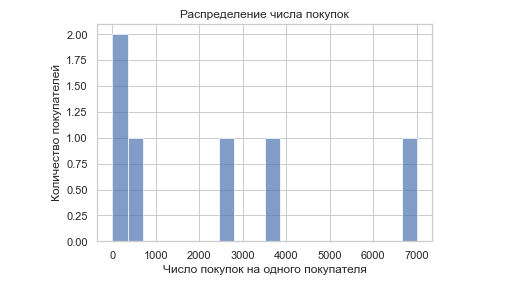
distplot — это график, который визуализирует гистограммы, то есть распределяет данные по столбцам. Каждому столбцу соответствует доля количества объектов в данной группе. Также distplot показывает плотность распределения — плавный линейный график, в котором самая высокая точка указывает на наибольшее количество объектов.
Кроме этого, в Pandas есть другие виды графиков:
- kdeplot — график плотности распределения, который останется, если убрать гистограммы из distplot;
- jointplot — график, показывающий распределение данных между двумя переменными. Каждая строка из набора данных в исходном файле отображается на графике как точка внутри системы координат. У точек на графике jointplot будет два заданных значения: одно по оси X, другое по оси Y.
Например, можно отследить взаимосвязь между тем, сколько минут посетитель проводит в торговом центре и сколько магазинов успевает посетить за это время: кто-то за 30 минут успеет зайти в 5 бутиков, а кто-то обойдет 16. При этом каждый посетитель на графике будет отображаться отдельной точкой.

0 комментариев