


Синтез речи — технология, которая преобразует написанный текст в аудиосигнал. Программа анализирует слова и создает звуки, которые имитируют человеческий голос.
Метод называют по-разному: генерация речи, Text-to-Voice (T2V), Text-to-Speech (TTS), — но суть остается та же. Основная цель TTS — озвучить текст голосом, чтобы его можно было слушать, вместо того чтобы читать.
Вместе с Григорием Стерлингом, лидом команды TTS в SberDevices, разбираемся, как устроена технология, как разрабатывают синтезаторы речи и что нужно знать, чтобы работать в этой сфере.
Как развивался синтез речи
Технология появилась еще в 18 веке, когда австро-венгерский ученый-механик Вольфганг фон Кемпелен создал «говорящую машину». Это была система из мехов, трубок и мембран, которая воспроизводила звуки, напоминающие речь.


В 1937 году инженер Гомер Дадли из Bell Labs разработал Voder — первое электронное устройство для синтеза речи на основе электрических сигналов.
К 1960-м годам TTS начала переходить в цифровую эпоху. В MIT сделали одну из первых компьютерных систем — DECtalk, основанную на цифровых методах. Однако из-за ограниченных вычислительных мощностей синтезированная речь звучала искусственно. Лишь в 1990-х, с появлением более производительных компьютеров, получилось улучшить качество голосов и сделать их приближенными к человеческой речи.
Для синтеза речи использовали два основных подхода:
- Конкатенативный синтез. Основан на соединении фрагментов записанной речи (например, отдельных звуков, слогов или слов). Они «склеивались» в нужном порядке для создания целых слов и предложений.
Хотя этот метод создавал более естественное звучание по сравнению с ранними подходами, у него были недостатки: неестественные переходы между звуковыми сегментами и большие затраты на сбор данных.
Этот вид синтеза начал устаревать с появлением нейросетевых методов в середине 2010-х годов.

- Параметрический синтез. Задача синтеза решается в два этапа: акустическая модель и вокодер. Сначала по тексту предсказываются некоторые параметры речи — чаще всего спектрограмма. Затем она превращается в звук с помощью другой модели — вокодера.
Долгое время этот метод создавал «бубнящие» и «звенящие» звуковые дорожки. Но в 2016 году генеративная модель WaveNet, которая использовала параметрический подход, смогла синтезировать речь, максимально приближенную к человеческой.
Какие возможности у технологии TTS
Синтез речи не ограничивается простым преобразованием текста в звук. Существуют разные задачи, которые расширяют возможности этой технологии, такие как:
- клонирование голоса (voice cloning) — с использованием короткого образца голоса, который может быть любого размера, вплоть до нескольких секунд;
- эмоциональный синтез — с добавлением разных эмоциональных оттенков и стилей;
- многоязычный синтез — с учетом особенностей каждого языка: грамматики, интонаций, ударений, а также сложных фонетических правил;
- диалектный синтез — с учетом региональных особенностей, акцентов и диалектов. Это может быть полезно для создания более аутентичных голосов, например с британским, австралийским или американским акцентом;
- персонализированный синтез — создание голоса под конкретные потребности и предпочтения. В отличие от клонирования, этот синтез может основываться не на образце конкретного человека, а на заранее выбранных характеристиках голоса (тембр, интонация, скорость речи). Его часто используют для озвучки разных персонажей в аудиокнигах;
- синтез шепота или крика — отдельная задача синтеза, когда речь должна быть тихой (например, шепот) или, наоборот, более громкой и уверенной. Это требует особой обработки, так как изменяются не только акустические параметры, но и интонационные особенности.
Где используют синтез речи
Вот несколько основных направлений, в которых используют TTS:
- Виртуальные ассистенты: например, Салют от Сбера, Siri от Apple, Алиса от Яндекса, которые озвучивают ответы пользователю.
- Озвучивание аудиокниг.
- Помощь при навигации в GPS-системах.
- Инклюзивные технологии для людей с нарушениями зрения (озвучивание интерфейсов, экранные читалки).
- Контакт-центры и голосовые боты для автоматизации общения с клиентами.
- Видео, реклама и игры, где нужно сделать озвучку реплик.
Как устроен процесс синтеза речи
Процесс включает несколько этапов, разберем подробнее каждый из них.
Этап 1 — нормализация текста
Текст, который подается в модель, нужно привести в нормализованный вид, то есть раскрыть числа и сокращения, а также проставить ударения во всех словах.
- Нормализация. Записанные в обычном виде числа и сокращения раскрываются буквами целиком, как они произносились бы голосом. Например «Я родился в 1992 г. в г. СПб» трансформируется в «Я родился в тысяча девятьсот девяносто втором году в городе Санкт-Петербурге». Обычно эту задачу решают правилами, но современные NLP-технологии позволяют применять нейронные сети.
- Простановка ударений. Для всех слов в предложении нужно поставить ударения. Обычно для этого используют фонетические словари, но для редких или новых слов нужна отдельная модель. В русском языке также есть омографы — слова, которые пишутся одинаково, но в зависимости от контекста у них разное ударение. Например: «когда вы посмОтрите в окно» и «посмотрИте в окно». Для постановки ударений есть открытые Python-библиотеки, например ruaccent.
- Для некоторых движков TTS нужна фонемизация текста, то есть запись букв в звуковой форме. Например, «январь» → «й а н в А р’». Фонетический алфавит — это термин из лингвистики, и какого-то одного устоявшегося не существует. Рекомендуется использовать IPA — international phonetic alphabet — и работающие в нем open-source фонемизаторы.
- Моделирование просодии. Просодией называется интонация, с которой произносится какой-нибудь текст. Например, на какие слова делается логическое ударение (эмфаза) или паузы в речи. Синтез речи будет более качественным и контролируемым, если за расстановку этих или других параметров будет отвечать отдельная NLP-модель.
Этап 2 — преобразование элементов через текстовый энкодер
Энкодер — это компонент модели машинного обучения, который преобразует входные данные (в данном случае текст) в эмбеддинг — числовое представление, которое сохраняет смысл и контекст информации.
В нем содержатся данные о голосе, эмоциональном контексте, ударениях.
Методы:
- Рекуррентные нейронные сети (RNN). Модели обрабатывают текст последовательно, передавая информацию о предыдущих элементах на каждом шаге. Это помогает лучше сохранять контекст, особенно в длинных текстах.
Стандартные RNN могут терять важные связи на больших промежутках, поэтому применяют усовершенствованные версии, такие как долгая краткосрочная память (LSTM) и управляемые рекуррентные блоки (GRU).
Пример применения таких сетей — архитектура Tacotron 2, которая использует последовательную обработку для синтеза речи.
- Сверточные нейронные сети (CNN). CNN используются в архитектурах типа WaveNet для обработки локальных зависимостей, таких как фонемы и слова. И выделяют важные признаки текста для дальнейшего синтеза речи.
- Трансформеры (Transformers). Модели, такие как BERT, используют механизм внимания (self-attention) для параллельной обработки текста. Так они могут учитывать как локальные, так и глобальные зависимости в данных — это ускоряет обучение и синтез речи по сравнению с RNN.
Этап 3 — прогнозирование длительности
Duration Predictor — это компонент моделей синтеза речи, который отвечает за прогнозирование времени звучания каждой фонемы в тексте. По сути, он «решает», сколько времени нужно на произнесение каждого звука, чтобы речь звучала естественно.
Последовательность чисел (представление фонем), полученная от энкодера, «растягивается» в соответствии с предсказанной длительностью каждой фонемы.
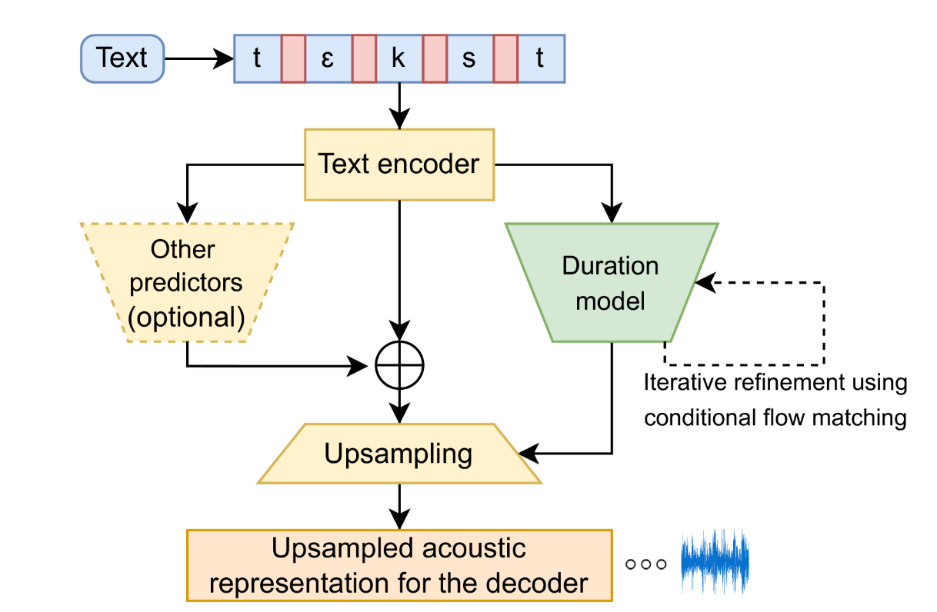
Этот модуль нужен только для неавторегрессионных моделей (FastSpeech, Vits), а для авторегрессионных (Tacotron 2, Valle) — не нужен. В Tacotron 2 длительность фонем часто контролируется напрямую через механизм внимания — модель решает, когда переходить от одной фонемы к другой, на основе контекста.
Методы:
- Трансформеры (Transformers). Модели, такие как FastSpeech, предсказывают длительность фонем с использованием механизмов внимания (self-attention). В FastSpeech 2, помимо длительности (duration), также прогнозируются высота тона (pitch) и энергия (громкость и интенсивность). Благодаря этому речь становится более выразительной и естественной.
Этап 4 — генерация визуального представления звука с помощью декодера
Декодер — это часть нейросети, которая преобразует эмбеддинги в мел-спектрограмму. Мел-спектрограмма — это визуальное представление звукового сигнала, отображающее его частоты во времени. Она служит основой для последующего преобразования в аудиосигнал.
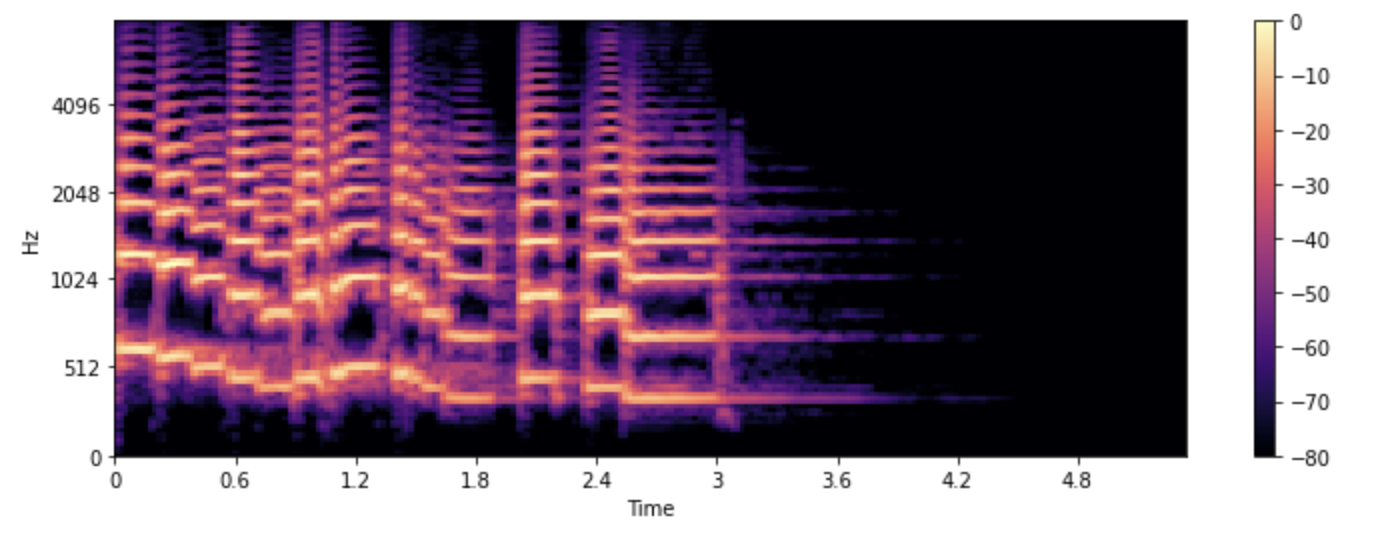
Методы: для декодирования применяют те же слои, что и для энкодинга: CNN, RNN и Transformers.
Этап 5 — генерация звукового сигнала с помощью вокодера
Вокодер — это алгоритм, который преобразует мел-спектрограмму, полученную от декодера, в финальный звуковой сигнал. Это последний шаг в процессе синтеза речи.
Методы:
- Flow-based-модели. Например, модель WaveGlow использует flow-based (потоковое) программирование для преобразования мел-спектрограмм в аудиосигналы с высоким качеством.
- Generative Adversarial Networks (GAN). Архитектуры, такие как MelGAN и HiFi-GAN, используют GAN-фреймворк, в котором одна модель генерирует звук, а другая оценивает его качество.
В последнее время стало модно делать end2end-модели, в которых все модули соединены и учатся совместно. Это улучшает качество, но требует больше вычислительных ресурсов.

Какие инструменты и технологии используют для синтеза речи
Синтезаторы речи — это системы, состоящие из энкодера, декодера и вокодера. Одни модели охватывают весь цикл синтеза, а другие фокусируются лишь на отдельных этапах — акустической обработке или вокодинге. Разберем, чем они отличаются.
Модели для полного цикла синтеза
- VITS (Variational Inference Text-to-Speech). Использует вариационное автокодирование и GAN для единовременной генерации аудиосигнала.
- GradTTS. Одна из первых моделей, где применили denoising diffusion к задаче синтеза речи. Это подход, в котором сильно зашумленная картинка путем многократного применения «расшумляющей» нейросети преобразуется в чистую мел-спектрограмму. В конце она озвучивается вокодером.
- Tacotron 2 + WaveGlow. Текстовый ввод передается в модель Tacotron 2. Она выполняет энкодинг текста и преобразует его в эмбеддинг. Декодер Tacotron 2 генерирует мел-спектрограмму из этого представления. WaveGlow озвучивает спектрограмму, преобразуя ее в аудиосигнал.
Модели для отдельных этапов синтеза
- FastSpeech 2. Проводит энкодинг и декодинг. Также использует адаптер вариаций, который добавляет к эмбеддингу дополнительную информацию: длительность, высоту тона и энергию.
Применение: энкодинг, декодинг.
- MelGAN. Состоит из генератора и дискриминатора, которые обучаются вместе: генератор создает аудио, пытаясь обмануть дискриминатор, который учится отличать подделки от настоящих аудиосигналов.
Применение: вокодинг.
- HiFi-GAN. Использует два типа дискриминаторов для оценки и улучшения качества сгенерированных аудио:
- многомасштабный, который анализирует аудиосигналы на различных временных масштабах;
- многопериодный, который фокусируется на периодических аспектах звука, таких как гармоники (уникальный тембр и эмфаза) и циклические паттерны (ритмические и тональные повторения).
Как разрабатывают синтез речи
Для написания кода систем синтеза речи проще всего взять open-source-реализации известных архитектур (FastSpeech, Tacotron 2 и т. д.).
Для тренировки моделей необходимы пары из текста и соответствующего ему аудио. Эти записи должны быть сделаны профессиональными дикторами с правильными интонациями и нужным стилем. В коммерческих приложениях нужно использовать лицензированные датасеты или создавать собственные.
В разработке систем синтеза и адаптации данных и моделей под конкретные цели обычно используют Python:
- для получения мел-спектрограмм применяют библиотеку librosa;
- в библиотеке torchaudio есть почти все необходимое для работы с аудио;
- для извлечения частоты основного тона используют алгоритм Yin либо библиотеку reaper.
При разработке и обучении моделей глубокого обучения применяют фреймворки TensorFlow и PyTorch. Для машинного обучения и обработки данных также используют библиотеку scikit-learn.
Совершенствование модели
Любую модель можно улучшать разными способами:
- Feature engineering (генерация признаков): создание новых признаков из имеющихся данных, их преобразование и нормализация, для того чтобы дать модели больше полезной информации для обучения.
- Модули и функции потерь: добавление новых слоев в модель или изменение ее структуры, а также использование функций потерь, которые помогут модели лучше справляться с задачей.
- Подготовка данных: улучшение качества данных, разметка и увеличение их объема. Это включает очистку данных от ошибок и решение проблем с несбалансированными выборками, чтобы модель обучалась на более качественном наборе.
Метрики производительности
При оценке производительности модели часто применяют метрику Real Time Factor (RTF). Она показывает, сколько секунд аудио генерируется за одну секунду реального времени.
На практике же не менее важной метрикой является First chunk latency — задержка до начала воспроизведения, которую мы рассмотрим на примере ниже.
Есть две модели, которые отличаются возможностью делать стриминг и RTF:
- RTF = 0.1: 10 секунд звука генерируются за одну секунду, но модель не поддерживает стриминг. Пользователь услышит звук через одну секунду.
- RTF = 0.5: 2 секунды звука за одну секунду, но модель поддерживает возможность стриминга, что позволяет снизить латенси до очень маленьких значений, например 100 мс. Когда модель работает в потоковом режиме, речь генерируется по мере обработки текста: она начинает воспроизводиться еще до того, как весь текст был полностью обработан.
Несмотря на то что первая модель более производительная, пользователям приятнее будет слушать вторую модель, потому что воспроизведение начнется быстрее.
Контролируемость синтеза
Контролируемость синтеза — это способность современных TTS-систем управлять интонацией, ударениями и эмоциями, чтобы речь звучала естественно и передавала нужный смысл. Например, фраза «Вы заплатите завтра?» может звучать по-разному в зависимости от контекста. В русском языке за вопросительную интонацию отвечает особый восходящий интонационный контур. Важно уметь управлять этим в движке синтеза речи, чтобы исправлять ошибки.
Также важны инструменты для исправления ошибок и улучшения качества синтеза, такие как Resemble Enhance, которые позволяют устранять артефакты и улучшать звучание речи.
Какие перспективы развития синтеза речи
Развитие технологий синтеза речи зависит от того, для кого они предназначены — для бизнеса (B2B) или конечных пользователей (B2C).
- B2B (business-to-business)
В бизнес-сегменте синтез речи часто используют в колл-центрах. Главная цель — создать недорогую систему с хорошим качеством. Иногда легкая «роботичность» в голосе допустима, потому что это помогает клиентам сразу понять, что они разговаривают с машиной. - B2C (business-to-consumer)
В сфере B2C, например в голосовых помощниках и озвучке контента, требуется высокое качество речи. Пользователи ожидают, что технологии будут идеально имитировать живой голос, добавлять эмоции и мгновенно генерировать звук. Чтобы достичь такого уровня реализма и качества, требуется много работы: эксперименты, сбор данных и обучение моделей. Часто для работы таких моделей нужны современные GPU, и стоимость синтеза получается выше.
Что нужно изучить для работы с Text-to-Speech
1. Основы Python
Для создания простых приложений с синтезом речи нужны базовые навыки работы с Python. Важно уметь использовать библиотеки и готовый код из открытых репозиториев.
- Освойте ключевые конструкции языка: переменные, циклы, функции.
- Научитесь работать с библиотеками для глубокого обучения, такими как PyTorch или TensorFlow, для создания моделей синтеза.
2. Математика
Глубокие знания математики помогут лучше понять механизмы работы моделей синтеза речи.
- Изучите линейную алгебру для понимания работы нейронных сетей и преобразований данных.
- Разберитесь в теории вероятностей и статистике, чтобы оценивать модели и работать с их прогнозами.
- Освойте численные методы для оптимизации моделей и повышения точности синтеза.
3. Digital Signal Processing (DSP)
Обработка сигналов — очень важный навык для работы с аудио.
- Научитесь преобразовывать и анализировать звуковые сигналы с помощью методов цифровой обработки сигналов (DSP).
- Изучите, как звуковые волны можно представить в виде данных для синтеза речи.
4. Deep Learning
Глубокое обучение лежит в основе современных систем TTS.
- Изучите архитектуры нейронных сетей, такие как CNN и RNN, которые широко применяются для анализа и генерации данных.
- Ознакомьтесь с конкретными архитектурами, разработанными для синтеза речи, такими как Tacotron 2, FastSpeech и VITS.
- Изучите современные подходы в генеративных нейросетях. Например, GAN, diffusion, flow, LLM.
5. Лингвистика
Знания лингвистики помогают создавать более естественный синтез речи.
- Изучите основы фонетики, включая фонемы, интонации и ритмы.
- Разберитесь в акцентуации, паузах и ритмах речи для создания более естественных голосов.
6. Физика звука и биология
Понимание физики звука и биологии слуха важно для синтеза качественной речи.
- Изучите основы акустики — как формируются звуковые волны, как они передаются и воспринимаются.
- Разберитесь в работе голосовых связок и как различные звуковые сигналы воспринимаются человеческим ухом.
Синтез речи — что нужно запомнить
- Синтез речи — это процесс преобразования текста в аудиосигнал с помощью ИИ.
- Его применяют в разработке виртуальных ассистентов, навигационных систем, создании аудиокниг и инклюзивных технологий.
- Процесс синтеза включает разделение текста и последующую обработку данных энкодером, декодером и вокодером.
- Энкодер преобразует текст в числовое представление, декодер генерирует мел-спектрограмму, а вокодер превращает ее в звуковой сигнал.
- Иногда в процесс включают duration predictor, который предсказывает длительность каждого звукового элемента для более точной синхронизации.
- Модели могут охватывать полный процесс синтеза или фокусироваться на отдельных этапах — акустической обработке или вокодинге.
- Технологический стек для разработки TTS включает Python с такими библиотеками и фреймворками, как librosa для аудио, NLTK для обработки текста и PyTorch для построения моделей.