


Михаил Белоус — автор одного из модулей курса по Data Science и дата-сайентист в Райффайзенбанке. Он рассказал о том, зачем нужно стандартизировать хранение и сбор данных, как отбирают кандидатов в команду и почему не нужно расстраиваться из-за отказов.
Чем я занимаюсь
Data Scientist — это продвинутый аналитик, знающий бизнес-процессы и владеющий навыками программирования и математики.
Я работаю в департаменте CIB Райффайзенбанка — это корпоративный инвестиционный банкинг. Мы сотрудничаем с компаниями среднего, крупного и международного бизнеса. Я состою в молодой команде, которой около трех лет. Когда я присоединился к коллективу, нас было 8 человек; сейчас мы разрослись до 20 с лишним.
У нас дата-сайентист не просто обучает модели, но выступает скорее fullstack-инженером: он может без помощи дата-инженера и DevOps-специалиста самостоятельно настраивать инфраструктуру, искать данные, переносить их из одного источника в другой, агрегировать, выгружать и затем с ними работать.
Мы рассказывали в этой статье, чем занимается дата-инженер, а в этой — чем занимается DevOps-специалист.


Задачи могут быть разные: от построения базовой аналитики и составления красивых интерпретируемых дашбордов до сложных задач вроде динамического прайсинга (процесс формирования цен на товары и услуги в реальном времени). Также мы занимаемся точечными вопросами: например, строим OCR-модель (Optical Character Recognition), которая автоматически парсит (собирает и систематизирует) различные документы, что позволяет автоматизировать работу сотрудников.
Сейчас я «предсказываю» жизнь клиентов, которые держат у нас депозитные счета. Деньги кладут на разные сроки: например овернайт — это краткосрочный депозит, когда клиент приносит деньги вечером, а утром забирает их обратно. Из-за того, что суммы большие, важен даже маленький процент прироста, за ночь он может все равно что-то заработать. Мы знаем, что клиент будет делать так ежедневно, и нам будет куда выгоднее, если банк будет пользоваться его деньгами. Я ищу таких клиентов и предсказываю, как долго они продержат у нас депозит.
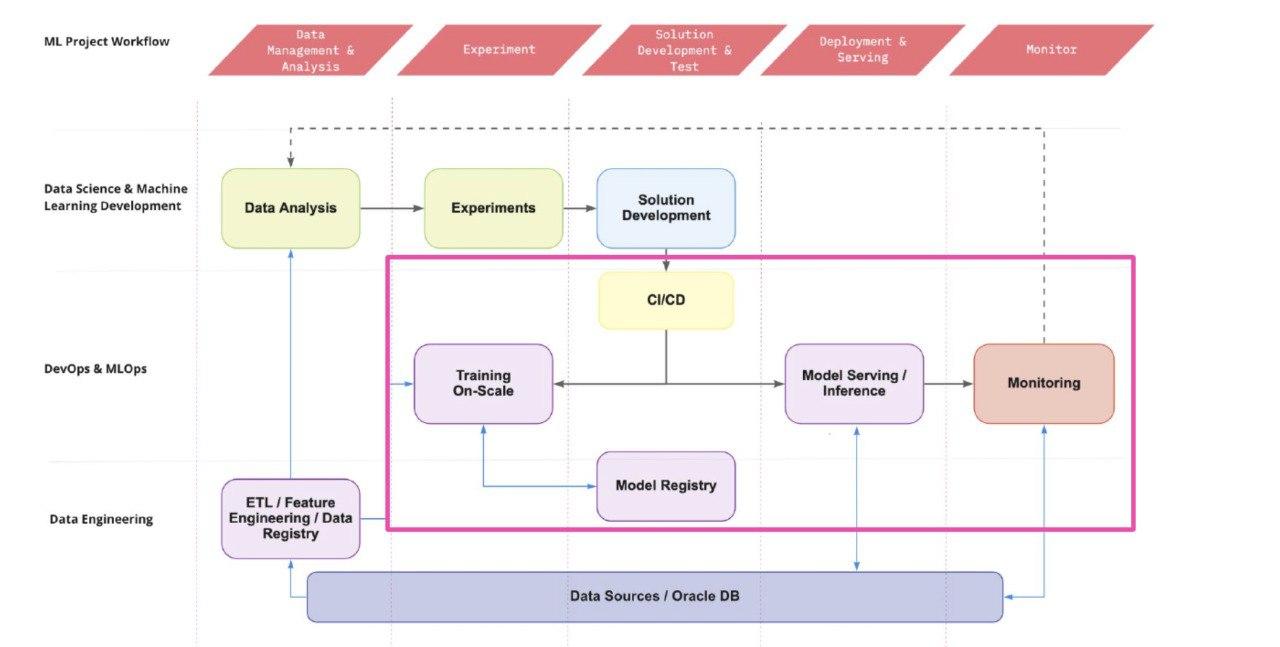
У меня уже настроен пайплайн сбора данных. Раньше источников было много, но для оптимальной работы удобно поместить их в одно место.
Подготовить инфраструктуру для проекта — задача непростая. Я применяю PySpark (инструмент для обработки больших данных) для агрегации и объединения датафреймов (структура данных) и добавления разных фичей. Использую как внутрибанковские, так и внешние фичи, например ключевые ставки Центрального банка. Затем я перевожу собранный датасет в Pandas. Часть данных я чищу там, часть на PySpark, устраняю плохие данные и недочеты. Получается финальный набор данных, на котором можно проводить обучение.
Этот процесс построения пайплайна довольно длинный. Чтобы быстрее проводить эксперименты, я упаковываю его в DVC — инструмент для автоматизации ML-пайплайнов и воспроизводимости экспериментов. Я задаю настройки, в каком порядке выполнять задачи, и он запускает все этапы. В итоге я получаю файл с метриками, которые можно оценивать.

Зачем нужны правильный сбор и хранение данных?
Мы стремимся к тому, чтобы ускорить процессы сбора и хранения данных. Найти нужные, качественные данные в достаточном количестве очень тяжело. К тому же при построении моделей нужно опираться на исторические данные, особенно на данные «тяжелого» 2014 года, чтобы натренировать стрессоустойчивость модели. Она должна предвидеть любые кризисы и проблемы.
Тогда стандарты хранения данных были немного другими и мир держался на Excel-таблицах. Для их сбора нужно обратиться к сотням коллег и уметь верно их перекачивать из разных источников, а в идеале — вообще автоматизировать этот процесс. Поэтому мы строим универсальные каталогизированные хранилища данных.
Мы уже рассказывали, почему стоит перейти с Excel на Python.

Однажды я столкнулся с тем, что данных было слишком много, порядка 1,5 Тб. В Pandas столько данных не поместится — он начинает зависать уже при 10 Гб; обучение тормозило и в PySpark.
Тогда я попробовал перевести процессы в нейросеть TabNet для табличных данных — там я мог обучать модель батчами (частями). Датасет разбивался на равные части и загружался по очереди в оперативную память. Потом это отправлялось в TabNet, сетка обучалась, при этом сохраняя коэффициенты данных, с которыми она хорошо работает. Потом следующие батчи переносились в уже предобученную сетку. Это решило проблему.
Для нас очень важна интерпретируемость моделей, поэтому нейросети мы используем редко. Мы должны четко понимать, какой из параметров влияет на результаты, чтобы взаимодействовать с аспектами бизнеса и в дальнейшем увеличивать прибыль. Результаты нейросетей сложны для интерпретации, поэтому в основном мы используем линейные модели и градиентные бустинги.
Про градиентный бустинг и линейную регрессию рассказывал дата-сайентист Михаил Волович.
Мы стараемся делать все проекты по шаблону, чтобы не собирать код в одном огромном блокноте. Для этого мы распределяем фичи по логике или функциям, которые вызываются по отдельности. Это помогает быстро локализовать баги и не тратить время на проработку всего кода. Мы стараемся покрывать тестами и код, и данные. Также после выкатки модели мы отслеживаем ее перформанс — насколько качественные предсказания она дает и насколько они помогают бизнесу — и свежие данные, на которых она дообучается.
Мы в команде считаем, что хороший дата-сайентист должен уметь справляться со всеми задачами: и протестировать данные, и наладить инфраструктуру. Если специалист может только строить прогнозы и модели, то многие процессы в команде существенно замедляются. Если данные лежат в другом месте и срочно тебе нужны, то куда проще и быстрее самому их забрать, чем писать коллеге, у которого голова забита другими задачами. Поэтому мы всегда спрашиваем на собеседованиях, насколько кандидат умеет работать с данными и знаком с технологиями.
Что мы используем и каких знаний требуем от кандидатов
Мы стараемся внедрять технологии MLOps: DVC, MLFlow (инструмент для управления жизненным циклом модели), чтобы подробнее анализировать разные показатели наших моделей. С большими данными работаем через PySpark, для которого нужно знать SQL и другие хранилища, из которых можно доставать данные (PostgreSQL, Oracle, HDFS (Hadoop Distributed File System)).
С помощью оркестратора данных AirFlow мы переливаем данные из одного источника в другой. Этот инструмент управляет скриптами по расписанию. Например, нужно ежедневно в определенное время запускать скрипт или отправлять сообщение; для этого мы заводим задачу в AirFlow, и он автоматизирует процессы.
Дата-сайентист должен хорошо знать статистику, понимать математику и машинное обучение на высоком уровне. Нужно не только механически уметь решать примеры, но и понимать их суть. На собеседованиях мы даем задачу на рассуждение, которую можно решить разными способами, и смотрим, какими методами пользуется кандидат и от каких отказывается. Так мы проверяем его способность к рассуждению, а не только знание теории вероятности.
Подробнее про математику для дата-сайентистов читайте тут.
Также мы ожидаем, что кандидат на уверенном уровне знаком с Python. Он должен понимать, как устроены структуры данных, и знать асимптотическую сложность — время и память, которые понадобятся программе в процессе работы.
В банковской сфере также очень важно понимать устройство бизнеса. Это не обязательное условие при устройстве на работу, но уже в процессе важно вникнуть во все понятия и законы сферы. Мы для развития также приглашаем коллег, которые проводят нам мастер-классы, читаем литературу про банковский бизнес, активно обсуждаем финансы. Я также слежу за Telegram-каналами, чтобы быть в курсе событий: bitkogan, headlines, Сигналы РЦБ US.

Мы обязательно проводим интервью со всей командой, чтобы просто пообщаться с кандидатом. Мы не обсуждаем технические вопросы, просто болтаем о жизни, чтобы понять, насколько друг другу подходим.
Что может делать стажер в начале работы
Стажерам и новичкам, конечно, не дают тяжелые проекты. Обычно за ними закреплен ментор, который помогает быстро разобраться в инфраструктуре, потому что настроить доступы, узнать, где лежат разные данные, куда ему подключаться, очень непросто. Если он пришел не из финансовой сферы, то ему нужно показать глоссарий, чтобы он смог ориентироваться в основных терминах.
Сначала ему дают несложную аналитику: посчитать, построить базовую модель, написать код на Python. Также мы даем ему задачи на агрегацию и выгрузку данных, чтобы он разобрался в PySpark.
У нас и стажеры, и мидлы имеют одинаковое влияние внутри команды. Независимо от грейда может появиться задача любого уровня сложности. Но, конечно, от мидла ждут большей ответственности, производительности и качества выполненных задач. Специалист старшего грейда должен решать большинство задач самостоятельно, тогда как стажеру, наоборот, следует постоянно задавать вопросы коллегам и обращаться к ним за советом.

Совет: поддержка и помощь старших коллег и экспертов всегда важны. Поэтому я советую вступать в различные сообщества, поддерживать связи и повышать нетворкинг-скиллы. Благодаря этому вы найдете крутых специалистов, которые могут посоветовать интересные источники для учебы, новые полезные технологии.
Также важно устраиваться на стажировки и чаще ходить на собеседования. Не расстраивайтесь из-за отказов, они дарят важный опыт. Мне отказывали много раз, хоть это и обидно, но благодаря таким пробам можно найти свои слабые места и проработать их.