


Надежное хранилище данных — важная часть бизнеса. Для маленькой компании достаточно Excel-таблицы, но когда структура данных становится сложной и изменчивой, нужен Data Vault. Как построить хранилище, которое не боится изменений и легко масштабируется, — рассказываем в статье.
Что такое Data Vault
Data Vault — это методология моделирования хранилищ данных (Data Warehouse), разработанная для поддержки гибкого, масштабируемого и аудируемого хранения данных, особенно в условиях быстро изменяющихся и нестабильных источников данных.
У каждой компании, которая собирает и анализирует данные, есть data-хранилища. Первые решения обычно простые и линейные. Например, можно использовать таблицы, которые напрямую повторяют структуру CRM или ERP.

Со временем меняются бизнес-логика и структура источников, поэтому таблиц становится недостаточно. А еще они затирают предыдущую информацию, добавляя новую, так что могут возникнуть проблемы с аналитикой и отчетностью.
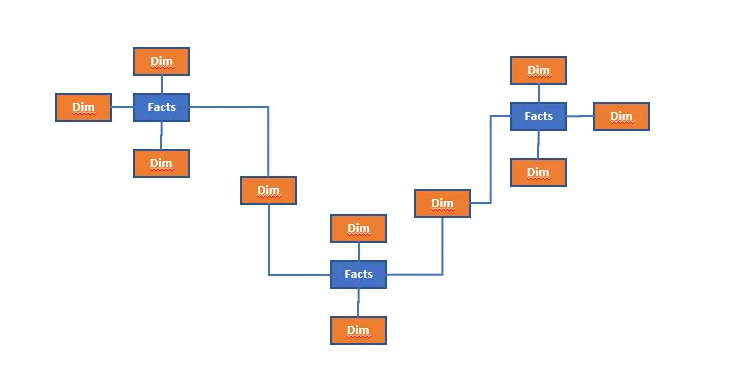
Можно использовать классические подходы к моделированию хранилищ, например 3NF или «звездную» схему по Кимбеллу. Но они недостаточно гибкие, и при частых изменениях структуры и источников их сложно поддерживать. Data Vault — это подход, который позволяет строить стабильные и легко расширяемые хранилища даже в условиях постоянных изменений.
| Подход | Описание | Когда применять |
| 3NF | Каждая таблица содержит только уникальные данные. Все неключевые атрибуты (поля) зависят только от первичного ключа. | Когда нужна строгая структура и хочется избежать избыточных данных. |
| Kimball | Использует «звездную» схему для организации данных. Есть центральная таблица (например, продажи), которая связана с несколькими таблицами измерений (например, продукт, время и т. д.). | Когда важно проводить анализ и быстро составлять отчеты. |
| Data Vault | Включает три типа таблиц: хабы, линки, сателлиты, — которые показывают ключевые бизнес-сущности, отношения между ними и историю изменений. | Когда есть много источников, проект долгосрочный и нужно делать аудит. |

Главные принципы Data Vault
Метод разработал Дэн Линстедт в начале 2000-х. В отличие от классических моделей, Data Vault специально создали для работы в часто меняющихся условиях. Его ключевые принципы:
- модульность: можно легко добавлять новые источники данных и менять структуру хранилища;
- историзация: можно отслеживать изменения данных во времени, сохранять не только текущие значения, но и их предыдущие версии;
- разделение: данные делят на три компонента (хабы, ссылки и спутники), что упрощает управление.
В 2013 году появился Data Vault 2.0. Это обновленный подход, который еще больше акцентирует внимание на автоматизации и адаптивности.
Основные компоненты Data Vault
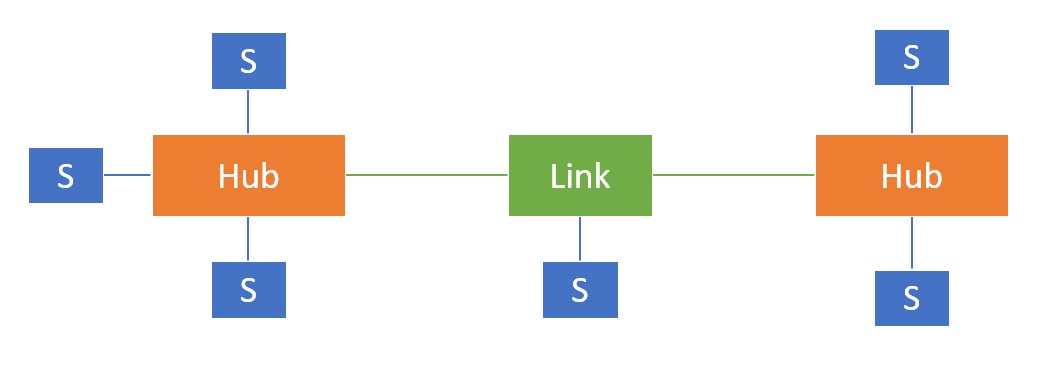
Модель Data Vault включает три типа таблиц.
Узел (Hub)
Это ключевые сущности — объекты, который важны для бизнеса, например клиенты, продукты или заказы. У каждого хаба есть уникальный идентификатор (ID) и технические поля (имя, дата регистрации и т. д.)
Хабы связывают разные компоненты модели. С их помощью можно организовать данные так, чтобы легко находить информацию о важных заказах и клиентах.
Ссылки (Links)
Показывают отношения между разными хабами. Например, какие клиенты сделали какие заказы. Ссылки могут содержать временные метки, с помощью которых можно отслеживать изменения.
Спутники (Satellites)
Содержат атрибуты, которые описывают хабы и ссылки. Могут включать дополнительные данные, например характеристики, статусы и другие изменяемые параметры.
Еще спутники хранят историю изменений. Например, информацию о предыдущем адресе клиента. Каждый раз, когда что-то меняется, создается новая запись.
Плюсы и минусы Data Vault
Data Vault дает много преимуществ при работе с большими и сложными хранилищами:
- масштабируемость: база данных легко растет горизонтально. Можно добавлять новые источники или сущности — достаточно создать новый Hub или Satellite;
- гибкость: можно менять источники данных, добавлять новые поля, но общая структура хранилища не требует изменений;
- поддержка истории: все изменения сохраняются. Можно проводить глубокий анализ данных и составлять отчеты;
- прозрачность: можно легко отследить источник данных, время загрузки. Это упрощает отладку и помогает разобраться в спорных ситуациях.
Помимо плюсов, у Data Vault есть недостатки:
- сложность реализации: для внедрения Data Vault нужны время и ресурсы, особенно на этапе проектирования;
- избыточность: иногда данные могут быть избыточными из-за хранения исторической информации;
- нагрузка на ETL: из-за большого числа таблиц (на каждый Hub — минимум один Satellite) возрастает объем ETL-обработки и метаданных.

Когда использовать Data Vault
Чаще всего Data Vault используют в ритейле, страховании, банках и финтех-компаниях. Он подходит, когда:
- нужно хранить историю всех данных и делать аудит;
- есть много источников данных с разными структурами и качеством;
- ожидается рост хранилища в течение нескольких лет;
- у проекта длительный срок реализации;
- команда может поддерживать сложную ETL-инфраструктуру.
Иногда Data Vault используют и в IT. Он хорошо сочетается с Agile-методологией и позволяет командам быстро реагировать на изменения.
Главное о Data Vault
- Data Vault — это метод моделирования хранилищ, который разделяет данные на хабы, ссылки и спутники.
- Главная особенность Data Vault — гибкость и масштабируемость.
- Data Vault сохраняет историю изменений, что важно для анализа и отчетности.
- В Data Vault можно легко добавлять новые источники или менять бизнес-логику без необходимости заново строить хранилище.
- Метод подходит для крупных и долгосрочных проектов, например банков, ритейл-магазинов, финтех-компаний.
- Data Vault хорошо сочетается с Agile-методологией.