


Датасеты — это основа анализа данных и работы с искусственным интеллектом. С их помощью обучают нейросети, проводят исследования и находят закономерности в информации. В статье расскажем, что такое датасеты, где их найти и как выбрать подходящие данные для ваших задач.

Что такое датасет для анализа данных
Датасеты — это организованные наборы данных, используемые для обучения, тестирования и валидации моделей машинного обучения.
Они представляют собой таблицы или коллекции данных, где каждая строка может соответствовать отдельному объекту или наблюдению, а столбцы — различным характеристикам (фичам).
Фича (особенность, признак) — это характеристика или атрибут объекта, представляющая собой часть входных данных, которые используются для обучения модели машинного обучения.
Это может быть любая переменная, описывающая данные, например, возраст человека, цвет автомобиля, или количество товаров в магазине.
Метка (целевая переменная, результат) — это значение, которое модель пытается предсказать или классифицировать на основе фич.
Например, в задаче классификации это может быть метка класса (например, «кошки» или «собаки»), а в задаче регрессии — конкретное числовое значение (например, цена дома).
Установка датасета
Большинство популярных датасетов доступны через стандартные библиотеки, такие как TensorFlow и PyTorch или специализированные API. Обычно для работы с датасетом нужно:
- Подключить библиотеку. Например, torchvision (для PyTorch).
- Импортировать датасет. Каждая библиотека предоставляет метод или класс для загрузки определенного датасета.
- Указать настройки. Нужно прописать, где хранить данные, загружать ли их автоматически, использовать ли преобразование (например, нормализацию).
- Разделить данные. Также указывают, какие данные являются обучающими, а какие — тестовыми (проверочными).
Так выглядит установка датасета из библиотеки torchvision:
from torchvision import datasets, transforms dataset = datasets.<НазваниеДатасета>(root='путь', train=True, download=True, transform=transforms.ToTensor())
Теперь разберем, чем различается обучение с учителем, без учителя и с подкреплением, какие датасеты для этого используют и по какому принципу их выбирают.
Обучение с учителем (Supervised Learning)
Обучение с учителем (контролируемое обучение) — это подход, при котором модель обучается на датасетах из размеченных данных.
Размеченные данные — это набор примеров, где каждый объект (например, изображение, текст или числа) включает фичи и метки. Задача модели — найти зависимость между ними, чтобы предсказывать результаты на новых данных.
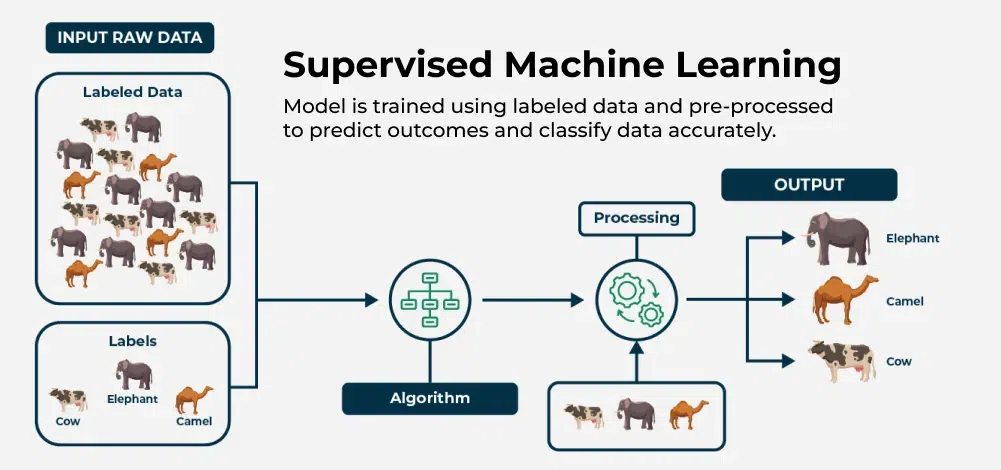
Обучение с учителем используют в задачах классификации и регрессии.
Классификация
Одна из самых популярных задач машинного обучения. Для нее используют датасеты, содержащие объекты с фичами и метками классов (категорий). Модель учится предсказывать класс объекта на основе фич. Вот примеры датасетов для классификации:
Сфера применения: компьютерное зрение.
Датасет из изображений в оттенках серого размером 28х28 пикселей, содержащий рукописные цифры от 0 до 9. MNIST и его расширения основаны на NIST Special Database 19, более раннем датасете из рукописных цифр и букв.
Набор данных: 70 000 изображений (60 000 обучающих и 10 000 тестовых).
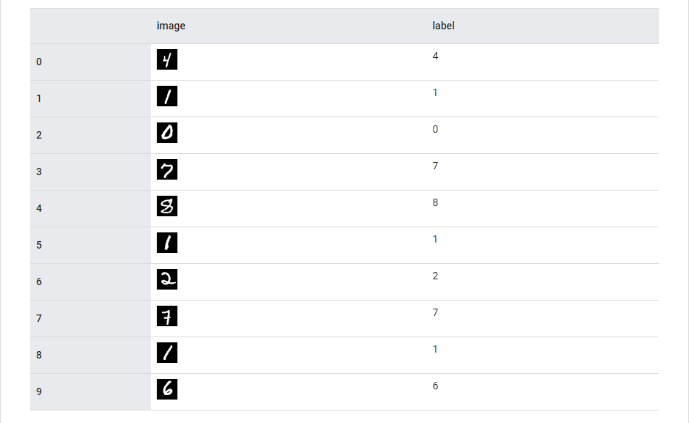
Разновидности и расширения
Вместо цифр включает изображения одежды.
Набор содержит 70 000 изображений в оттенках серого в 10 категориях одежды.
Расширяет MNIST, включает символы и цифры.
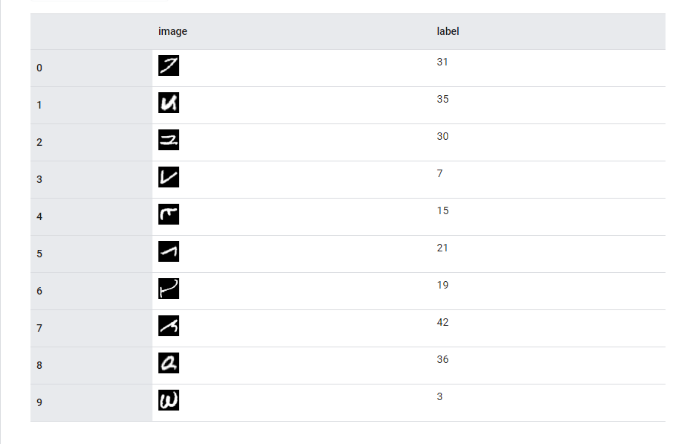
Адаптация MNIST под японские символы каны с полной заменой набора.
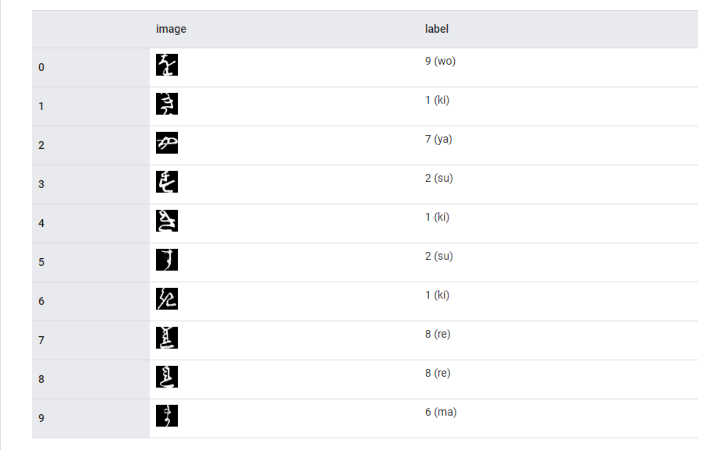
Сфера применения: компьютерное зрение.
Датасет с изображениями размером 32х32 пикселей с объектами 10 классов, таких как самолеты, автомобили, птицы, кошки и т.д.
Набор данных: 60 000 цветных изображений (50 000 обучающих и 10 000 тестовых изображений).
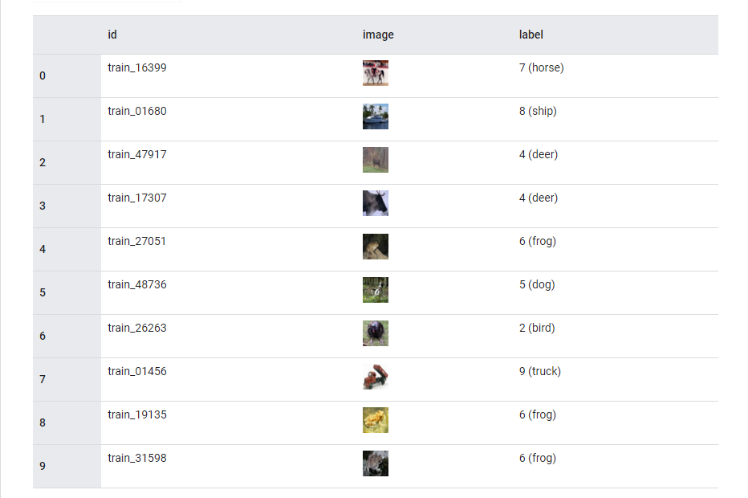
Разновидности и расширения
Расширяет CIFAR-10. Содержит 100 классов объектов (по 600 изображений на класс).
Основан на CIFAR-10, включает изображения 10 классов, но более высокого разрешения (96×96 пикселей).
Несмотря на то, что STL-10 основан на CIFAR-10, он используется скорее для задач частичного обучения (с частичным привлечением учителя), так как помимо маркированных изображений он содержит 100 000 немаркированных (unlabeled).
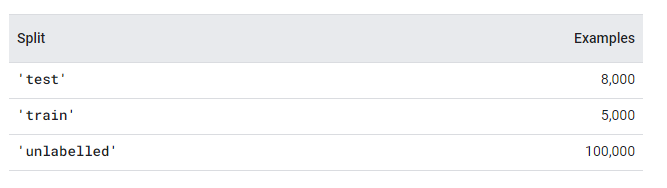
MS COCO (Microsoft Common Objects in Context)
Сфера применения: компьютерное зрение.
Набор данных, содержащий изображения с аннотациями. Они помогают моделям обучаться выполнению задач компьютерного зрения. Датасет включает не только изображения объектов, но и контекст, в котором эти объекты встречаются. Поэтому модели, обученные на нем, смогут понимать логику взаимодействия между объектами.
Набор данных: более 320 000 аннотированных изображений.

Разновидности и расширения
- COCO-Stuff. Расширение, которое включает дополнительные категории объектов, такие как различные типы фонов и фоновых объектов.
- COCO-Keypoints. Версия, где аннотированы ключевые точки на человеческих фигурах для задач распознавания поз.
- COCO-Text. Аннотированные изображения для задач распознавания текста на изображениях (OCR).
IMDB Movie Dataset: All Movies by Genre
Сфера применения: исследование тенденций в киноиндустрии, рекомендательные системы.
Датасет содержит данные о фильмах: текстовые (название, описание), числовые (рейтинг, кассовые сборы).
Набор данных: более 50 000 записей.

Сфера применения: биоинформатика, анализ данных.
Набор наблюдений за цветками ириса. Каждое наблюдение характеризуется четырьмя признаками, связанными с размером чашелистиков и лепестков, и относится к одному из трех видов ирисов.
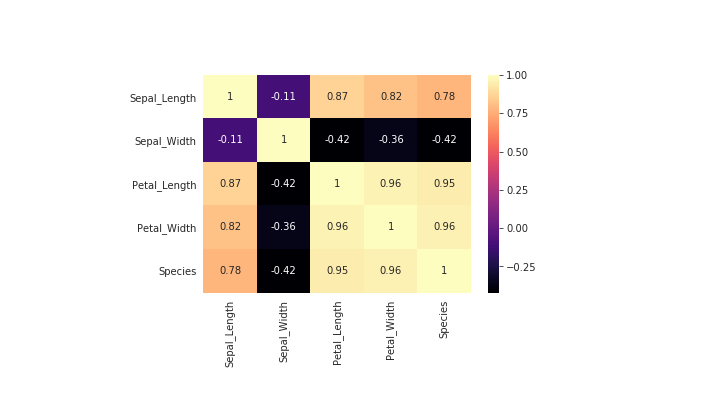
Набор данных: 150 наблюдений, по 50 для каждого из трех видов ирисов (Iris Setosa, Iris Versicolor, Iris Virginica).
Регрессия
Регрессия — это задача машинного обучения, в которой модель обучается предсказывать числовые значения на основе фич. В отличие от классификации, где метки — это категории, в регрессии метки представляют собой непрерывные числовые значения. Примеры датасетов:
Сфера применения: образование, анализ данных, предсказание успеха в обучении.
Датасет, разработанный для исследования факторов, влияющих на академическую успеваемость студентов. Включает информацию о различных характеристиках студентов и их оценках.
Целевая переменная — индекс общей успеваемости студента, выраженный числом от 10 до 100. Более высокие значения указывают на лучшую успеваемость.
Набор данных: 10 000 объектов, каждый из которых описывает различные аспекты учебной деятельности студентов.
Сфера применения: химический анализ, контроль качества, предсказание качества.
Амбициозный проект по классификации вин. Датасет содержит информацию о химических характеристиках вин и их качестве. Переменные датасета сформированы на основе физико-математических признаков (кислотность, хлориды, pH, содержание алкоголя).
Набор данных: красное вино — 1599 образцов, белое вино— 4898 образцов. Каждое с 12 атрибутами.
На сайте Kaggle можно найти еще больше датасетов для разных задач.
Обучение без учителя (Unsupervised Learning)
Обучение без учителя (неконтролируемое обучение) предполагает использование данных без меток.
Модель анализирует только входные данные и пытается найти скрытые структуры или паттерны в данных. При обучении без учителя выполняют задачи кластеризации и снижения размерности.
Кластеризация — это задача группировки объектов по признакам таким образом, чтобы объекты внутри одной группы (кластера) были более похожими друг на друга, чем объекты из разных групп.
Если в классификации используют уже размеченные данные, то в кластеризации классы заведомо не определены. Модель должна сама выделить группы схожих объектов.
Снижение размерности — это упрощение структуры данных, уменьшение числа признаков с сохранением важной информации. Это помогает в визуализации данных, повышении эффективности алгоритмов и уменьшении вычислительных затрат.
В обучении без учителя используют датасеты, такие как:
Mall Customer Segmentation Data
Сфера применения: маркетинг, анализ данных, сегментация клиентов, анализ покупательских привычек.
Датасет нужен для группировки клиентов на основе их покупательских привычек с использованием методов кластеризации. Его можно использовать для машинного обучения без учителя (например, с помощью алгоритма KMeans), чтобы выявить различные сегменты клиентов для дальнейшего анализа и релевантного маркетинга.
Набор данных: 2000 объектов (клиентов), 5 признаков (возраст, доход, баллы лояльности).
Сфера применения: обработка и анализ текстов, выделение схожих тем и группировка документов.
Датасет использует тексты новостей для выделения схожих тем и их группировки.
Наборы данных: около 18 000 сообщений из 20 различных новостных групп (например, спорт, политика, религия).
Сфера применения: анализ данных.
Каталог наборов данных, содержащий разнообразные тестовые данные по таким темам, как астрономия, экономика, социология, медицина и образование для алгоритмов кластеризации.
На этом сайте можно найти множество других датасетов для разных целей.
Обучение с подкреплением (Reinforcement Learning)
Обучение с подкреплением основано на взаимодействии агента с окружающей средой. Агентом может быть программа, алгоритм или система, обучающаяся на основе взаимодействия с этой средой.
Агент предпринимает действия, за которые получает вознаграждения или наказания, и использует этот опыт для принятия более правильных решений в будущем. Модель обучается на основе полученных результатов, а не на заранее заданных метках.
Существуют ли датасеты для обучения с подкреплением?
Обучение с подкреплением редко использует традиционные статические датасеты. Вместо этого применяют среды и симуляции, которые позволяют агенту взаимодействовать с динамическими состояниями.
Для обучения агентов существуют специальные движки и платформы с готовыми траекториями или симуляциями для обучения. Вот некоторые из них:
MuJoCo (Multi-Joint Dynamics with Contact)
Сфера применения: робототехника, симуляции движения и физические системы.
Мощный физический движок, предназначенный для задач оптимального управления, моделирования и анализа сложных систем. Его используют для разработки алгоритмов управления и тестирования перед внедрением моделей в физических роботов, а также для визуализации научных экспериментов и игр.
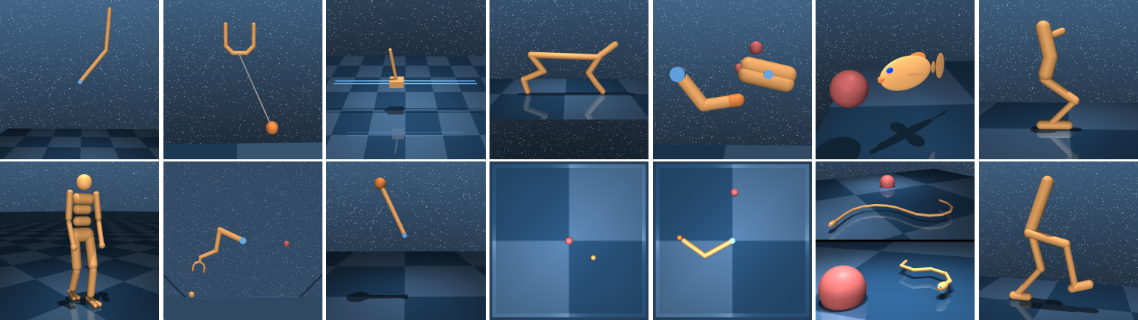
Сфера применения: универсальная платформа для обучения агентов.
Набор симуляций и сред, включая среды с задачами робототехники, играми и симуляцией физических процессов. Основан на физическом движке MuJoCo. Совместим со многими фреймворками, такими как TensorFlow и Theano.
Среды и задачи
- CartPole. Удержание баланса маятника на тележке.
- MountainCar. Управление автомобилем, пытающимся преодолеть гору.
- LunarLander. Симуляция посадки лунного модуля.
- Atari Games. Классические игры Atari, такие как Pong и Breakout.
- Roboschool. Управление роботами со сложными движениями.
- Half Cheetah. Симуляция бега гепарда.
- Walker2D. Балансировка во время передвижения человекоподобного робота.
- Humanoid. Сложное управление человекоподобной моделью.
Сфера применения: робототехника и физические симуляции.
Готовый набор задач с интерпретируемыми вознаграждениями (в соответствии с «предпочтениями» агента). Так же, как и OpenAI Gym, основан на физическом движке MuJoCo и поддерживает простую модификацию.
Как и OpenAI Gym, поддерживает такие задачи, как Cartpole, Half Cheetah.и т. д.
Общие критерии выбора и подготовки датасета
- Размер и репрезентативность
Датасет должен быть достаточно большим и разнообразным. Чем больше данных, тем лучше модель сможет выявить закономерности. - Качество данных
Данные нужно очистить от пропусков, ошибок, шумов и дубликатов. Качество данных напрямую влияет на точность модели. - Баланс классов
В задачах классификации важно, чтобы все классы были представлены равномерно, иначе модель может быть склонна к доминирующему классу. - Актуальность данных
Данные должны соответствовать текущим условиям задачи. Устаревшие данные могут ухудшить производительность модели. - Доступность и формат
Датасет должен быть легко доступен и иметь формат, совместимый с инструментами обработки (CSV, JSON и т.д.).
Как создать свой датасет
Хотя существует множество готовых датасетов, иногда может понадобиться создать собственный. Примерный план действий:
- Соберите данные.
Собирайте данные из доступных источников. Можно собрать данные вручную, но есть и автоматические способы. Например, соцсети и карты предоставляют API для доступа к своим данным.
Или можно воспользоваться веб-скрейпингом. У Python для этого есть специальные библиотеки, такие как BeautifulSoup, Scrapy или Selenium.
- Очистите и подготовьте данные.
Избавьте датасет от «мусорных» данных и пропусков.
Про предобработку и очистку данных писали в статье «Что такое предварительная обработка данных в машинном обучении и как ее провести».
- Форматируйте и организуйте данные.
- Приведите данные к стандартизированному формату, например, CSV, JSON, или TFRecord для TensorFlow.
- Если это изображения, убедитесь, что они имеют одинаковые размеры и формат.
- Разделите данные на тренировочные и тестовые. Классическое соотношение: 80% для обучения и 20% — для тестирования.
- Используйте библиотеки для работы с датасетами. Например, у Hugging Face есть инструкция по созданию и использованию собственных наборов данных.
