


Классическая ситуация из жизни дата-сайентиста: вы потратили две недели на исследование, перепробовали десятки гиперпараметров, обучили великолепную модель, которая бьет все бейзлайны. Вы пишете скрипт для инференса (применения модели), скидываете его коллеге или пытаетесь запустить на рабочем сервере, и… ничего не работает.
Оказывается, у коллеги стоит другая версия Python, конфликтуют библиотеки pandas и numpy, версия CUDA для видеокарты не совпадает с вашей версией PyTorch, а еще ваш скрипт не может подключиться к базе данных, потому что она не установлена на его компьютере. Фраза «Ну не знаю, на моей машине все работает!» стала настоящим мемом в нашей индустрии.
Именно эту проблему решает контейнеризация. В статье разберемся, что такое Docker, зачем нужен Docker Compose и как они работают под капотом; вместе напишем полноценный проект, состоящий из ML-модели и базы данных.
Что такое Docker: Краткое введение в контейнеризацию
Прежде чем говорить о Docker Compose, нам нужно разобраться с фундаментом — самим Docker.
Docker — это платформа для разработки, доставки и запуска приложений в изолированных средах, которые называются контейнерами. Но давайте переведем это на человеческий язык.

Аналогия из реальной жизни: морские грузоперевозки
Представьте себе мировую торговлю до изобретения стандартных морских контейнеров. Люди перевозили товары в бочках, ящиках, мешках разного размера. Погрузка корабля была настоящим искусством и сущим кошмаром: нужно было думать, как поставить хрупкие ящики с фарфором так, чтобы их не раздавили тяжелые бочки с вином. Каждый корабль, каждый поезд и каждый грузовик требовали своего подхода к погрузке.
А потом изобрели стандартный грузовой контейнер. Теперь неважно, что внутри — автомобильные запчасти, плюшевые медведи или электроника. Снаружи это всегда одинаковый металлический ящик стандартных размеров. Любой кран в мире знает, как его поднять, любой корабль знает, как его поставить в трюм.
Docker делает то же самое, но для программного обеспечения. Вместо того чтобы передавать коллеге ваш код и огромную инструкцию в духе: «Установи Python 3.9, потом скачай вот эту библиотеку версии 1.2, потом настрой переменные окружения, потом установи системную библиотеку libGL для работы с картинками…», вы упаковываете все ваше приложение (код, библиотеки, системные зависимости, настройки) в один стандартный «ящик» — Docker-контейнер. Он будет абсолютно одинаково работать на вашем ноутбуке с Windows, на макбуке вашего коллеги и на мощном Linux-сервере в облаке.
Контейнеры против виртуальных машин
Многие новички спрашивают: «А чем это отличается от виртуальной машины (VirtualBox, VMWare)?» Отличие огромное, и оно кроется в архитектуре.
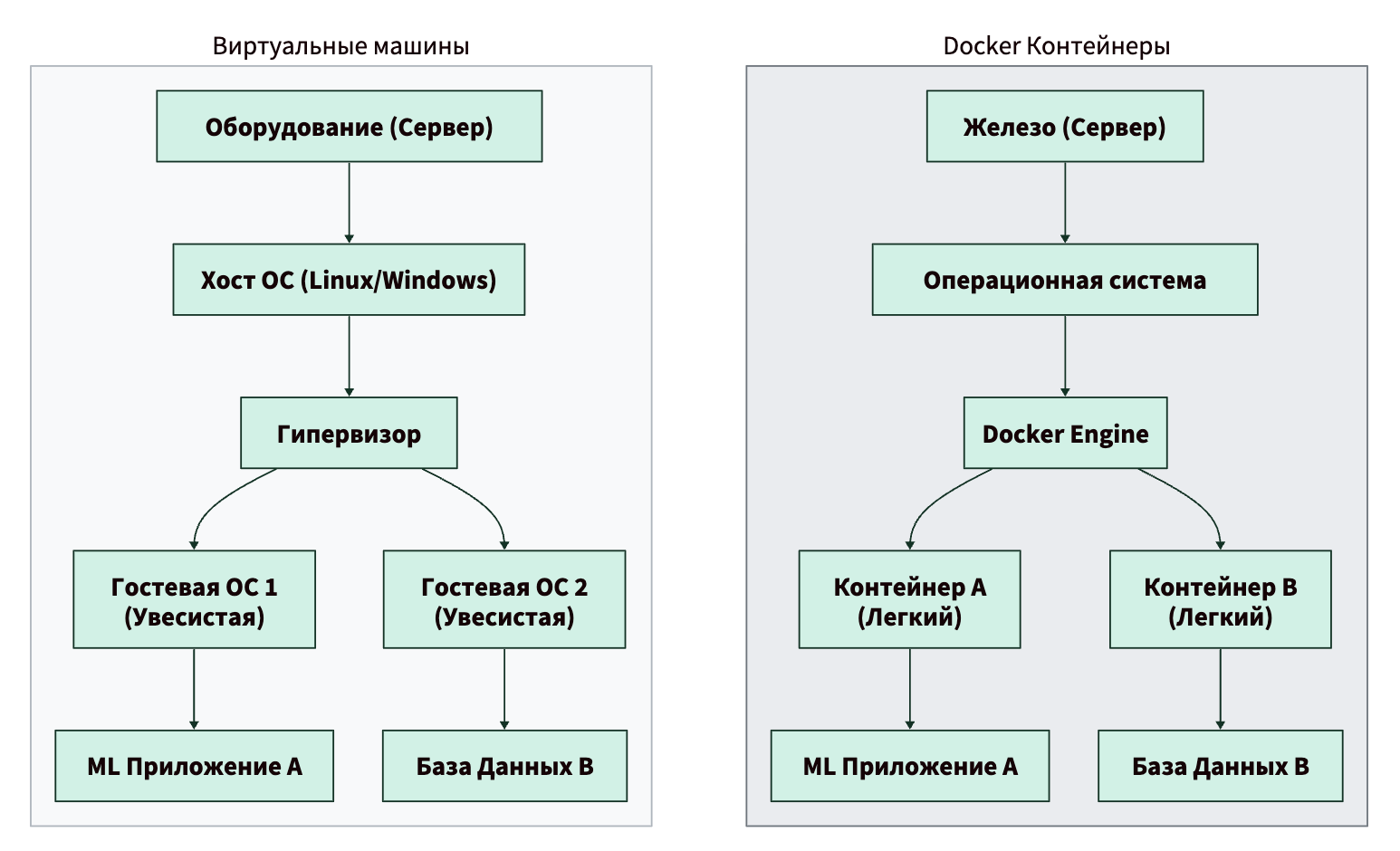
Виртуальная машина (ВМ) эмулирует все железо компьютера и запускает полноценную операционную систему (со своим ядром, драйверами и фоновыми процессами). Это очень тяжело и медленно. Если вам нужно запустить три разных ML-сервиса в трех ВМ, вы запустите три копии операционной системы!
Docker-контейнеры работают иначе. Они не эмулируют железо. Они используют ядро операционной системы вашего компьютера (хоста), но создают изолированные «песочницы» для процессов. Контейнер весит мегабайты, а не гигабайты, и запускается за доли секунды, а не за минуты.
Давайте посмотрим на диаграмму, которая наглядно это демонстрирует:
Два главных понятия Docker, которые нужно запомнить:
- Образ (Image) — это чертеж, слепок, рецепт вашего приложения. Это неизменяемый файл, в котором записано: «Возьми Ubuntu, установи Python, скопируй мой скрипт». Образ можно сравнить с рецептом торта.
- Контейнер (Container) — это запущенный экземпляр образа. Это сам испеченный торт. Из одного образа (рецепта) можно запустить сколько угодно контейнеров (испечь сколько угодно тортов).
Для простых скриптов базового Docker вполне достаточно. Вы пишете Dockerfile (инструкцию по сборке образа), собираете его командой docker build и запускаете командой docker run. Но что делать, если ваш проект становится сложнее?
Что такое Docker Compose
На реальной работе ML-инженер редко пишет скрипты, которые живут в вакууме. Современное приложение — это почти всегда набор микросервисов.
Представьте, что вы сделали крутую систему рекомендаций для интернет-магазина. Чтобы она работала в продакшене, вам нужны:
- Само ML-приложение (например, API на FastAPI), которое принимает запросы и отдает предсказания.
- База данных (например, PostgreSQL), где хранятся профили пользователей и история их покупок.
- Кэш (например, Redis), чтобы не вычислять рекомендации заново для одного и того же пользователя, а быстро отдавать готовый результат.
- Очередь задач (например, Celery + RabbitMQ), чтобы тяжелые фоновые переобучения модели не тормозили основной API.
У вас есть четыре разных компонента. Если использовать только голый Docker, вам придется вручную собирать четыре образа, затем писать четыре длиннющие команды docker run в терминале, вручную настраивать сети, чтобы они видели друг друга, и прокидывать порты. А если вы перезагрузите компьютер, все придется делать заново.
Здесь на сцену выходит Docker Compose — это инструмент для определения и запуска многоконтейнерных Docker-приложений.
Аналогия из реальной жизни: симфонический оркестр
Если отдельный Docker-контейнер — это талантливый музыкант со своим инструментом (например, скрипач), то Docker Compose — это дирижер с партитурой.
Дирижер (Compose) читает ноты (конфигурационный файл compose.yaml) и говорит: «Так, сначала на сцену выходит барабанщик (база данных), затем подключаются скрипки (API), играть они должны в едином ритме (в одной сети), а ноты для них лежат вот в этой папке (тома данных)».
Вам больше не нужно запускать каждый контейнер по отдельности. Вы описываете всю инфраструктуру вашего проекта в одном простом текстовом файле compose.yaml и запускаете весь проект одной-единственной командой: docker compose up.
Три кита Docker Compose: Services, Networks, Volumes
Чтобы понимать Compose, нужно разобраться в трех его главных компонентах.
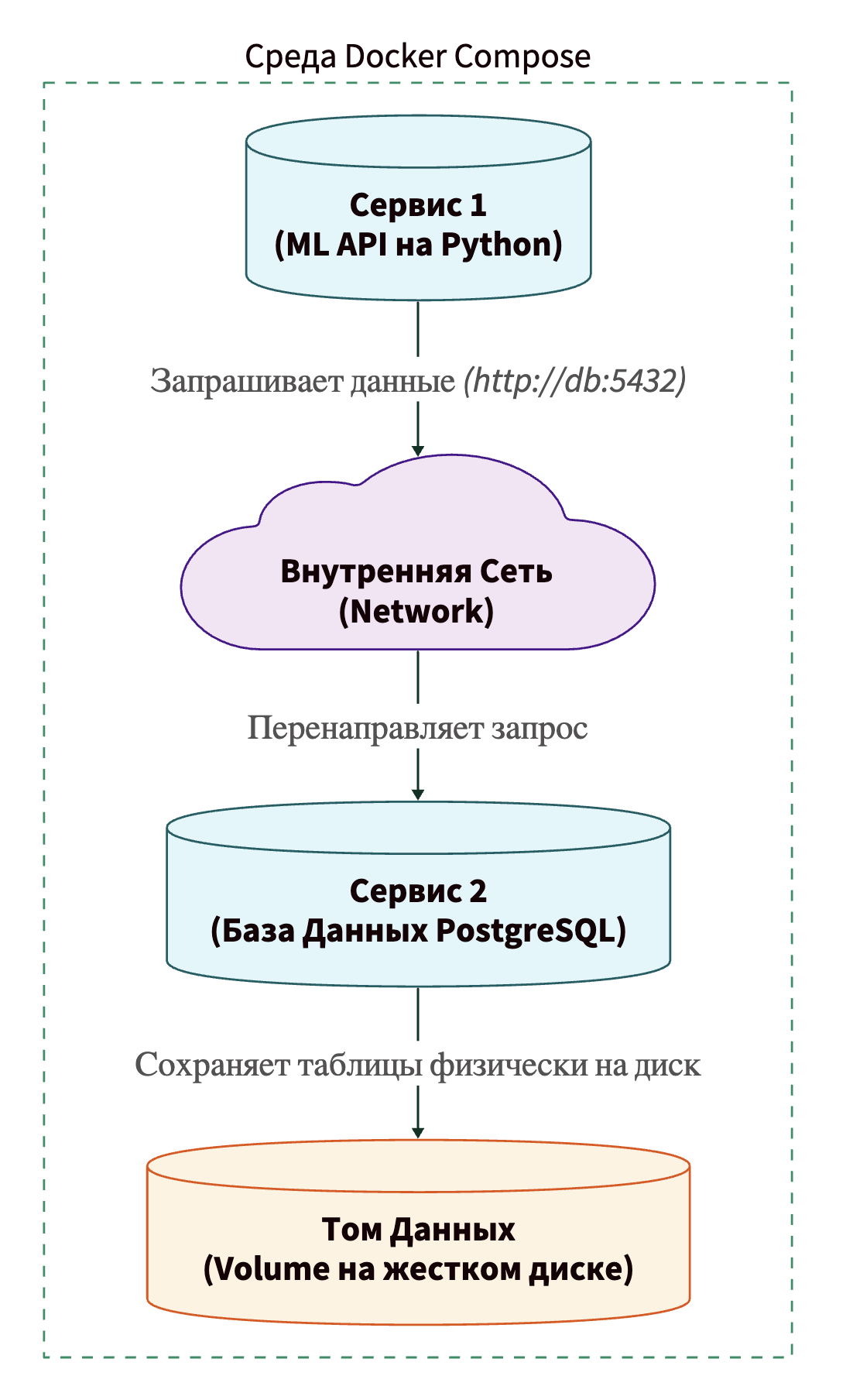
- Services (сервисы). Сервис — это, грубо говоря, один из ваших контейнеров, который выполняет определенную роль в приложении. В нашем примере выше у нас будет четыре сервиса: api, db, cache, worker. В файле конфигурации мы указываем для каждого сервиса, какой образ использовать, какие порты открыть и какие переменные окружения задать (например, пароль от базы данных).
- Networks (сети). По умолчанию Docker-контейнеры максимально изолированы. Они не знают о существовании друг друга. Но нашему API нужно как-то отправлять запросы в базу данных! Docker Compose автоматически создает виртуальную локальную сеть для всех сервисов, описанных в файле. Благодаря этому ваш код в сервисе api может обратиться к базе данных просто по ее имени: http://db:5432. Никаких IP-адресов запоминать не нужно, Compose сам работает как внутренний DNS-сервер.
- Volumes (тома / разделы данных). Если вы удалите контейнер, все данные внутри него исчезнут навсегда. Для ML-приложения это катастрофа. Представьте, что вы сохранили веса обученной модели или базу данных с миллионом записей внутрь контейнера, а потом он перезапустился из-за ошибки. Все пропало! Volumes (тома) — это специальные папки на жестком диске (на хосте), которые монтируются внутрь контейнера. Контейнер думает, что пишет данные в свою внутреннюю файловую систему, но на самом деле они безопасно сохраняются на вашем реальном жестком диске. Даже если контейнер будет уничтожен, данные в томе останутся целы.
Давайте визуализируем, как эти три компонента взаимодействуют внутри Docker Compose:
Как работает Docker Compose: пошаговый разбор цикла
Многим кажется, что Docker Compose — это какая-то магия. Написал файлик, нажал кнопку, и все само заработало. Но, как инженеры, мы должны понимать, что происходит под капотом. Это жизненно необходимо, когда что-то сломается (а в IT всегда что-то ломается) и вам придется это чинить.
Весь жизненный цикл запускается командой в терминале: docker compose up -d (флаг -d означает detached, то есть запустить в фоновом режиме, чтобы не блокировать терминал).
Давайте разберем по шагам, что делает Compose в ту же секунду, когда вы нажимаете Enter.
Шаг 1: Чтение и валидация конфигурации (парсинг)
Сначала Compose ищет в текущей папке файл с именем compose.yaml (или старый вариант docker-compose.yml). Найдя его, он читает его сверху вниз. Это декларативный подход: вы не пишете скрипт «сделай то, потом это». Вы описываете желаемое конечное состояние инфраструктуры. Compose проверяет файл на синтаксические ошибки. Если вы забыли пробел или неправильно назвали параметр, процесс остановится с ошибкой.
Шаг 2: Создание сетей (Networks)
Прежде чем запускать приложения, Compose готовит для них инфраструктуру связи. Он обращается к Docker Engine (основной программе Docker) и просит: «Создай мне новую изолированную сеть». По умолчанию сеть называется по имени вашей папки с добавлением _default. Например, если ваш проект лежит в папке ml_project, сеть будет называться ml_project_default.
Шаг 3: Управление томами (Volumes)
Далее Compose проверяет, нужны ли вашим сервисам постоянные хранилища данных. Если в конфигурации прописаны тома (Volumes), Compose проверяет, существуют ли они уже на вашем жестком диске. Если это первый запуск — он создает пустые директории. Если вы уже запускали проект ранее — он просто найдет существующие данные, чтобы позже подключить их к контейнерам. Это гарантирует, что ваша база данных не обнулится при перезапуске.
Шаг 4: Сборка или скачивание образов (Build/Pull)
Теперь Compose переходит к самим сервисам. Для каждого сервиса ему нужен образ (Image). Здесь есть два пути:
- Pull (Скачивание). Если для сервиса базы данных указано image: postgres:15, Compose пойдет в интернет (на Docker Hub — глобальный реестр образов) и скачает готовый официальный образ PostgreSQL.
- Build (Сборка). Если для вашего ML-кода указано build: . (собрать из текущей директории), Compose найдет ваш Dockerfile, скачает базовый образ (например, Python 3.10), установит библиотеки из requirements.txt, скопирует ваш код и создаст совершенно новый, уникальный образ специально для этого запуска.
Шаг 5: Запуск контейнеров с учетом зависимостей (Run & Depends_on)
Наконец, начинается магия создания контейнеров. Но Compose не делает это бездумно одновременно. Представьте: если ваше API запустится за секунду и сразу попытается подключиться к базе данных, а база данных будет запускаться 10 секунд — ваше API выдаст ошибку подключения и упадет. Чтобы этого избежать, в Compose есть параметр depends_on. Он указывает порядок запуска. Compose сначала запустит базу данных, дождется ее готовности и только потом запустит ваше ML-приложение.
Шаг 6: Отображение портов (Port Mapping)
Контейнеры запущены и общаются друг с другом внутри своей изолированной сети ml_project_default. Но как вам, разработчику, отправить запрос к вашему API из браузера или Postman? Для этого Compose выполняет «проброс портов» (Port Mapping). Например, вы указали ports: «8000:80». Это приказ для Docker: «Слушай порт 8000 на моем реальном ноутбуке (хосте) и все запросы, которые туда приходят, перенаправляй внутрь контейнера на порт 80».
Аналогия: открытие ресторана
Весь этот процесс очень похож на открытие нового ресторана:
- Чтение конфига. Вы читаете бизнес-план (кто нужен, что покупаем).
- Сети. Вы проводите электричество и связь между кухней и залом.
- Тома. Вы арендуете склад для продуктов, чтобы они не испортились, если ресторан закроется на ночь.
- Образы. Вы покупаете готовые холодильники (Pull) и строите уникальную барную стойку по чертежам (Build).
- Запуск. Вы не пускаете посетителей, пока не пришли повара. Сначала повара (база данных), потом официанты (API).
- Порты. Вы открываете входную дверь на улицу, чтобы клиенты могли зайти внутрь.

Создаем проект с Docker Compose
Давайте своими руками создадим типичный микросервисный проект, который часто встречается в задачах машинного обучения.
Идея проекта: Мы напишем простое веб-API на Python с использованием фреймворка FastAPI. Это API будет имитировать работу тяжелой ML-модели (например, классификации текстов). Поскольку ML-модели работают медленно, мы добавим к нашему проекту кэширование с помощью Redis. Логика будет такой: когда пользователь присылает текст, мы сначала проверяем, нет ли уже готового ответа в Redis. Если есть — отдаем мгновенно. Если нет — «прогоняем через модель» (в нашем случае просто ждем три секунды для имитации), сохраняем результат в Redis и отдаем пользователю.
Архитектура нашего проекта:
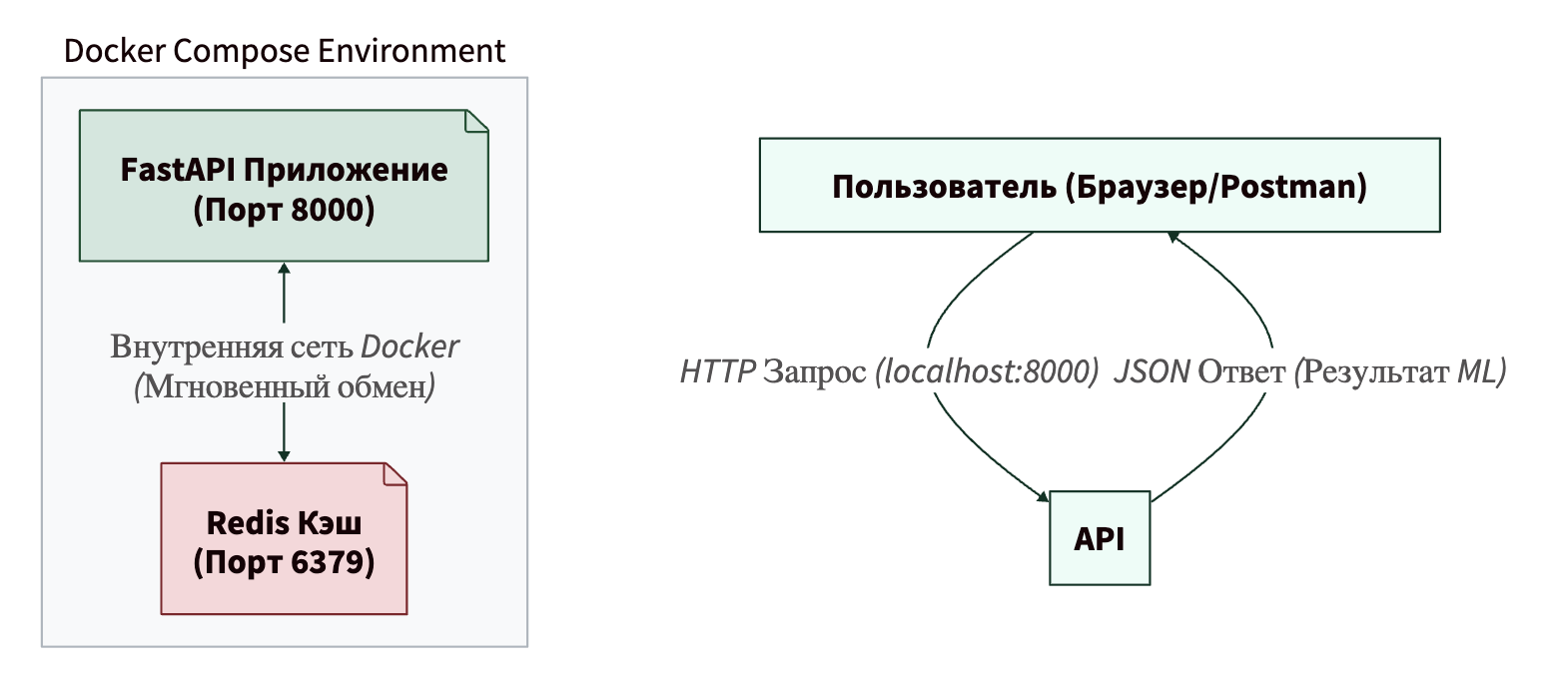
Для этого проекта нам нужно создать отдельную папку (например, ml_compose_project) и положить в нее четыре файла. Давайте разберем каждый из них.
Файл 1: requirements.txt
Здесь мы перечисляем библиотеки Python, которые нужны нашему приложению.
fastapi==0.103.1
uvicorn==0.23.2
redis==5.0.0
- fastapi — для создания самого веб-сервера.
- uvicorn — сервер для запуска FastAPI.
- redis — библиотека для общения с базой данных Redis из Python.
Файл 2: main.py
Это код нашего приложения. Постарался написать его максимально просто и снабдить комментариями.
from fastapi import FastAPI
import redis
import time
app = FastAPI(title="ML Model API with Cache")
# Подключаемся к Redis.
# ВНИМАНИЕ: Заметьте, что host="redis_cache"!
# Это имя сервиса из нашего compose.yaml, Docker сам найдет его IP-адрес.
cache = redis.Redis(host='redis_cache', port=6379, decode_responses=True)
def fake_ml_predict(text: str) -> str:
"""Имитация тяжелой работы ML-модели (например, нейросети)"""
time.sleep(3) # Ждем три секунды
return f"Категория: {len(text)} символов (это фейковый предикт)"
@app.get("/predict")
def predict_text(text: str):
# Шаг 1: Проверяем, есть ли уже ответ в кэше
cached_result = cache.get(text)
if cached_result:
# Если нашли в кэше, отдаем мгновенно!
return {"text": text, "prediction": cached_result, "source": "REDIS CACHE (Fast!)"}
# Шаг 2: Если в кэше нет, запускаем нашу «тяжелую» ML-модель
prediction = fake_ml_predict(text)
# Шаг 3: Сохраняем результат в кэш, чтобы в следующий раз было быстро
cache.set(text, prediction)
return {"text": text, "prediction": prediction, "source": "ML MODEL (Slow...)"}
Файл 3: Dockerfile
Теперь нам нужно объяснить Docker, как упаковать наше Python-приложение в образ. Мы создаем файл с названием Dockerfile (без расширения).
# 1. Берем официальный и легкий образ Python FROM python:3.10-slim # 2. Устанавливаем рабочую директорию внутри контейнера WORKDIR /app # 3. Копируем файл с зависимостями внутрь контейнера COPY requirements.txt . # 4. Устанавливаем библиотеки. # Флаг --no-cache-dir делает так, чтобы pip не сохранял установочные файлы, # это делает итоговый образ легче. RUN pip install --no-cache-dir -r requirements.txt # 5. Копируем весь остальной код (наш main.py) в контейнер COPY . . # 6. Указываем команду, которая будет запущена при старте контейнера CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
Файл 4: compose.yaml (Главный герой нашей статьи)
А теперь самое интересное. Мы связываем наше приложение и базу Redis воедино. Создаем файл compose.yaml.
# Блок services описывает все контейнеры в нашем проекте services: # 1. Сервис нашей ML-модели ml_api: # Указываем, что образ нужно собрать (build) из текущей папки (.), # где лежит Dockerfile build: . # Имя контейнера для удобства отображения в консоли container_name: fastapi_ml_app # Проброс портов: "порт_на_компьютере : порт_в_контейнере" # Мы сможем зайти на http://localhost:8000 ports: - "8000:8000" # Зависимости: не запускай API, пока не запустится кэш! depends_on: - redis_cache # Перезапускать контейнер автоматически, если он упадет из-за ошибки restart: always # 2. Сервис базы данных Redis redis_cache: # Здесь мы не пишем Dockerfile! Мы просто берем готовый образ из интернета image: redis:alpine # Имя контейнера container_name: redis_db # Порты пробрасывать наружу НЕ ОБЯЗАТЕЛЬНО! # Наше ml_api сможет общаться с Redis по внутренней сети Docker. # Мы не хотим, чтобы кто-то из интернета мог подключиться к нашему кэшу. # Подключаем том для сохранения данных (чтобы кэш не стирался при рестарте) volumes: - redis_data:/data restart: always # Блок volumes описывает тома, которые мы используем в сервисах volumes: # Объявляем том redis_data, чтобы Docker его создал на жестком диске redis_data:
Запуск проекта!
Все готово! Откройте терминал в папке с этими файлами и введите волшебную команду:
docker compose up --build
(Флаг —build заставляет Compose пересобрать образ нашего Python-приложения. Это полезно, если вы меняли код).
В терминале побегут строчки: Docker скачает образ Python, скачает образ Redis, установит ваши библиотеки через pip, создаст внутреннюю сеть и запустит оба контейнера.
Теперь откройте браузер и перейдите по ссылке: http://localhost:8000/predict?text=Привет
В первый раз вы увидите, что страница грузится три секунды. Модель «думает». Ответ будет таким: {«text»:»Привет»,»prediction»:»Категория: 6 символов (это фейковый предикт)»,»source»:»ML MODEL (Slow…)»}
А теперь обновите страницу (отправьте тот же запрос еще раз). Ответ появится мгновенно! {«text»:»Привет»,»prediction»:»Категория: 6 символов (это фейковый предикт)»,»source»:»REDIS CACHE (Fast!)»}
Поздравляю! Вы только что развернули полноценную микросервисную архитектуру. Ваше Python-приложение успешно связалось с базой данных Redis по внутренней сети Docker Compose, сохранило данные на диск и отдало вам результат. И все это — без единой ручной настройки сетей и без засорения вашей локальной операционной системы базами данных.
Если вы хотите остановить проект, просто нажмите Ctrl + C в терминале или введите команду: docker compose down. Эта команда аккуратно остановит контейнеры и удалит внутреннюю сеть. Но ваши данные в Redis останутся в безопасности на томе redis_data!
Docker Compose: коротко о главном
- Docker — это способ упаковать ваше приложение со всеми зависимостями в стандартный «контейнер», который гарантированно запустится везде.
- Docker Compose — это инструмент оркестрации для локальной разработки, который позволяет управлять сложными проектами из нескольких контейнеров (сервисов) с помощью одного элегантного конфигурационного файла compose.yaml.
Для ML-инженера владение Docker Compose — это переход на новый уровень профессионализма. Это значит, что вы можете не просто написать скрипт в Jupyter Notebook, но обернуть вашу модель в удобный сервис, прикрутить к ней базу данных для логов, добавить мониторинг (например, Prometheus и Grafana — еще пара строчек в compose.yaml) и отдать готовый, работающий продукт команде внедрения или заказчику.
Не бойтесь экспериментировать! Возьмите свой последний ML-проект, попробуйте написать для него Dockerfile и завернуть его в Compose. Сначала будут возникать ошибки, пути к файлам могут не совпадать, порты могут быть заняты — это абсолютно нормальный процесс обучения. Читайте логи (docker compose logs), изучайте документацию, и очень скоро вы не сможете представить свою жизнь без этого инструмента.
Пишите чистый код, обучайте точные модели и пусть ваши контейнеры всегда собираются с первого раза!
