


Нейросеть умеет работать только с числами и ничего другого на вход не принимает. Поэтому что бы вы в нее ни загрузили, сначала это превращается в наборы чисел. А дальше сеть прогоняет эти числа через себя и превращает их в нужный результат — например, в ответ на ваш вопрос или в подпись к фото.

При этом большинство данных конвертируются в числа довольно легко. Картинка — это сетка пикселей, и каждый из них задан числами: яркостью и долями красного, зеленого и синего. Видео — это последовательность кадров: по сути, много картинок, которые сменяют друг друга, и из-за скорости смены нам кажется, что изображение движется. Звук — это колебания, которые записываются как последовательность чисел-амплитуд. Но с текстом сложнее.
Возьмем, к примеру, слово «жираф». В нем нет ни яркости, ни громкости — ничего, что можно измерить и записать готовым числом. Числа тексту приходится придумывать искусственно. Причем так, чтобы они несли смысл: тогда по ним понятно, что «жираф» куда ближе к «слону», чем к «клавиатуре».
Чтобы решить эту задачу, исследователи придумали прием под названием эмбеддинги — о нем мы и поговорим в статье. Вы узнаете, что это такое, зачем они нужны и как нейросеть превращает текст в числа. Статья рассчитана на новичков, поэтому все будем упрощать и объяснять на простых примерах.
Что такое эмбеддинги и как они хранят смысл слова
Слово «embedding» переводится с английского как «вложение» — и в этом весь смысл приема. Объект как будто «вкладывают» в особое числовое пространство, где у каждого слова появляются собственные координаты. По ним и видно, какие слова близки по смыслу, а какие далеки друг от друга.
Сам подход появился задолго до нейросетей — еще в 1950-х годах. Тогда лингвисты заметили интересную закономерность: о значении слова многое говорит его окружение. Например, даже если слово «бариста» вам незнакомо, но регулярно попадается рядом с «кофе», «латте», «эспрессо» и «за стойкой», вы без всякого словаря поймете, что речь о человеке, который готовит кофе.
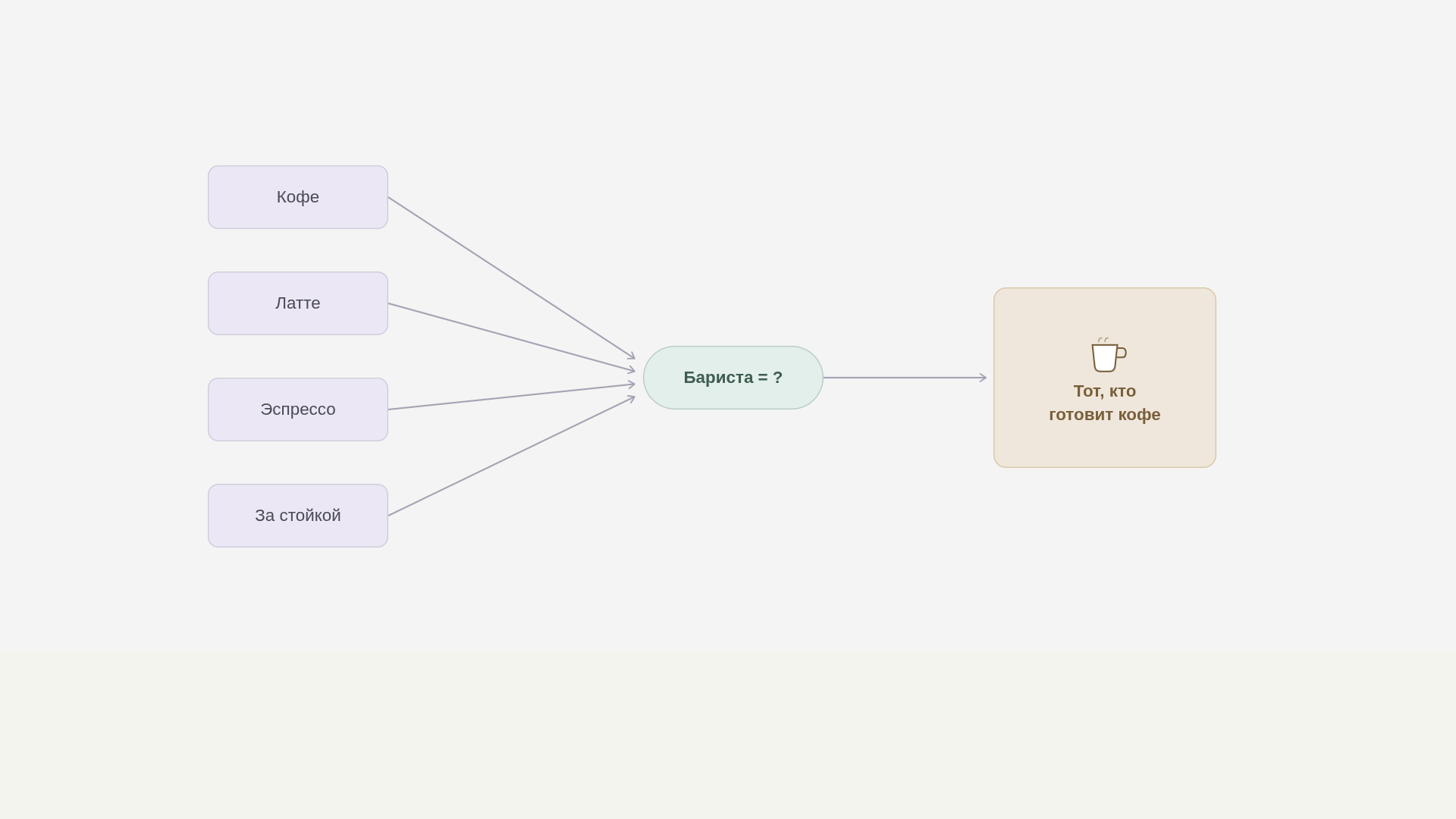
Первыми эту идею подхватили поисковые системы: чтобы находить и сравнивать документы, им нужно было как-то выразить тексты числами. Сделали они это самым прямым способом — брали слово и подсчитывали, рядом с какими другими словами оно встречается во всех текстах: сколько раз поблизости попалось «кофе», сколько — «латте», сколько — «эспрессо», и так по всему словарю. Получался очень длинный список чисел — вектор слова:
бариста = [ …, бетон=0, кофе=53, асфальт=0, латте=31, трактор=0, эспрессо=12, носок=0, … ]
Однако у такого подхода была проблема: в языке десятки тысяч слов, поэтому вектор для каждого слова растягивался на десятки тысяч позиций. Причем почти все эти позиции были нулевыми — ведь в реальности слово «соседствует» лишь с небольшой частью словаря. Такие раздутые разреженные векторы было сложно хранить и медленно сравнивать. Нужен был способ сжать их до компактного вида, оставив главное. Так появился латентно-семантический анализ (LSA) — прием, который уплотнял огромные разреженные векторы в короткие. Это уже было близко к идее эмбеддингов.
С приходом нейросетей эмбеддинги стали обучаемыми. Если в LSA сначала строят таблицу, а затем отдельно сжимают ее математическими методами, то нейросеть учится иначе: она много раз пытается угадать пропущенное слово по окружению. Например: «я налил ___ в чашку» — и модель должна выбрать «чай» или «кофе». Когда она ошибается, веса слегка корректируются — и вместе с ними меняются числа в эмбеддингах. Так получаются компактные векторы, в которых слова из похожих контекстов оказываются рядом.
В 2013 году Google представила метод Word2vec, который учится строить векторные представления слов по их контекстам. Его ценность в том, что такие представления можно было получать быстро и на больших корпусах — то есть не только на небольших учебных примерах, а на реальных данных. А раз эмбеддинги стало возможно обучать в масштабе, их начали широко применять в прикладных задачах: искать похожие слова и тексты, классифицировать документы, строить рекомендации, группировать данные. Именно после Word2vec эмбеддинги стали по‑настоящему практичным инструментом.
Как слова превращаются в числа
В реальных нейросетях эмбеддинги устроены куда сложнее учебных примеров: это векторы из сотен чисел, которые модель сама подбирает при обучении на огромных объемах текста. Из‑за множества параметров и шагов обучения такие числа не задают вручную, а смысл отдельных координат обычно не разбирают поштучно. Но базовая идея простая: каждому слову, фразе или кусочку текста соответствует набор чисел, и модель настраивает его так, чтобы близкие по смыслу слова оказывались рядом в этом числовом пространстве.
Чтобы понять принцип работы эмбеддингов, представим, что у каждого слова есть всего две координаты. Первая — условная шкала «одушевленное ↔ неодушевленное»: 0 — точно неодушевленный предмет, 1 — живое существо. А значения вроде 0.9 мы используем не как «процент живости», а как удобную оценку на шкале: чем ближе к 1, тем вероятнее слово относится к миру живого.
Вторая координата описывает размер по шкале от 0 до 1: 0 — маленькое, 1 — большое, а все промежуточные значения — что‑то среднее по масштабу.
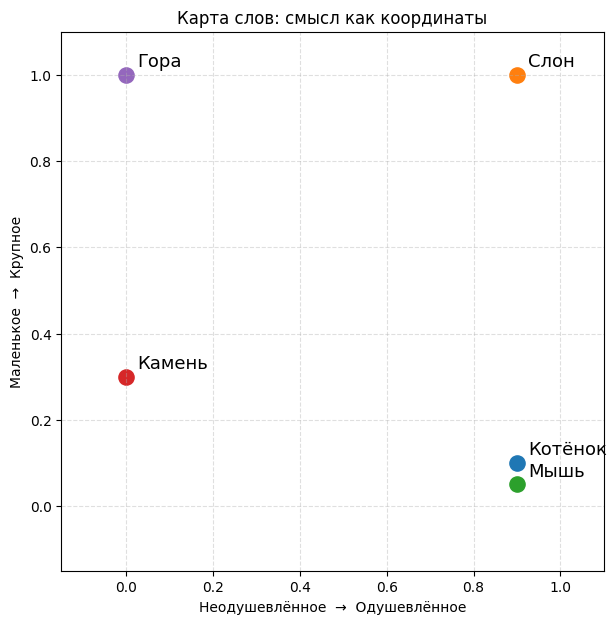
С такими вводными каждое слово можно записать парой чисел (X, Y) и отметить точкой на плоскости. В таблице показаны такие координаты для нескольких слов: у «котенка» вектор будет (0.9, 0.1), а у «горы» — (0.0, 1.0).
Если вы внимательно посмотрите на числа в таблице, то заметите:
- «Котенок» и «мышь» стоят почти вплотную — оба одушевленные и маленькие;
- «Слон» рядом с ними по степени одушевленности, но далеко по размеру;
- «Камень» и «гора» — в зоне неодушевленного и отличаются масштабом.
Интересно, что мы не объясняли компьютеру, что «мышь» похожа на «котенка»: это следует из самих чисел — их векторы оказались близки. Так и работают эмбеддинги: в реальных моделях вместо двух координат используются сотни измерений, которые сеть подбирает автоматически.
Чтобы увидеть это наглядно, построим нашу карту слов с помощью Python. Для этого откройте Google Colab, создайте блокнот и вставьте код ниже:
import matplotlib.pyplot as plt
words = {
"Котенок": (0.9, 0.1),
"Слон": (0.9, 1.0),
"Мышь": (0.9, 0.05),
"Камень": (0.0, 0.3),
"Гора": (0.0, 1.0),
}
plt.figure(figsize=(7, 7))
for word, (x, y) in words.items():
plt.scatter(x, y, s=120)
plt.annotate(word, (x, y), textcoords="offset points", xytext=(8, 6), fontsize=13)
plt.title("Карта слов: смысл как координаты")
plt.xlabel("Неодушевленное → Одушевленное")
plt.ylabel("Маленькое → Крупное")
plt.xlim(-0.15, 1.1)
plt.ylim(-0.15, 1.1)
plt.grid(True, linestyle="--", alpha=0.4)
plt.show()
Если вы все сделали правильно, Colab построит график с точками — по одной на каждое слово из таблицы. По осям отложены две координаты, а расстояние между точками показывает, какие слова оказались ближе друг к другу.
Вы познакомились с общим принципом: слово можно представить вектором чисел, и тогда близость векторов начинает отражать близость смыслов. Но еще раз повторим: в реальных нейросетях такие координаты никто не задает вручную — модель подбирает их сама, и измерений там не два, а сотни. Поэтому в следующем разделе мы разберем, как это происходит при обучении и почему после него слова действительно начинают группироваться по смыслу.

Как нейросеть сама подбирает числа в эмбеддингах
Чтобы понять, откуда берутся эмбеддинги, проведем небольшой эксперимент. Возьмем несколько фраз, запустим обучение упрощенной модели и посмотрим на результаты: сначала ближайшие слова будут выглядеть почти случайно, а затем начнут собираться в группы. После мы спроецируем получившиеся векторы на плоскость и посмотрим, как они выглядят на графике.
Никакой специальной подготовки для эксперимента не нужно: откройте Google Colab, создайте новый блокнот и повторяйте шаги из этого раздела.
Шаг 1. Для начала посмотри фразы, с которыми мы будем работать:
texts = [
"кот пьет молоко",
"котенок пьет молоко",
"кошка любит молоко",
"пес ест мясо",
"собака ест мясо",
"щенок любит кость",
"кофе это напиток",
"чай это напиток",
"кофе с молоком",
"чай с лимоном",
"король это мужчина",
"королева это женщина",
"принц это мужчина",
"принцесса это женщина",
]
texts = [ "кот пьет молоко", "котенок пьет молоко", "кошка любит молоко", "пес ест мясо", "собака ест мясо", "щенок любит кость", "кофе это напиток", "чай это напиток", "кофе с молоком", "чай с лимоном", "король это мужчина", "королева это женщина", "принц это мужчина", "принцесса это женщина",]
Обратите внимание: в этих фразах мы используем только слова, разделенные пробелами — без тире, запятых и точек. Это важно, потому что токенизация здесь самая простая: строка разбивается на токены командой split() по пробелам. Если поставить запятую или точку, знак препинания «прилипнет» к слову, и модель будет считать молоко и молоко, двумя разными словами.
Скопируйте этот список в отдельную ячейку Google Colab и запустите ее — она создаст переменную texts, которая нам понадобится в следующих шагах.
Шаг 2. Теперь обучим простую модель на нашем наборе фраз. Код ниже возьмет список texts, разобьет фразы на слова, составит пары «слово → соседние слова» и несколько сотен раз обновит веса модели, чтобы она лучше угадывала контекст. Скопируйте этот блок в следующую ячейку и запустите ее.
import torch
import torch.nn as nn
import torch.nn.functional as F
import random
torch.manual_seed(0)
random.seed(0)
tokens = [t.split() for t in texts]
vocab = sorted(set(w for sent in tokens for w in sent))
w2i = {w: i for i, w in enumerate(vocab)}
i2w = {i: w for w, i in w2i.items()}
window = 2
pairs = []
for sent in tokens:
ids = [w2i[w] for w in sent]
for pos, center in enumerate(ids):
for j in range(max(0, pos - window), min(len(ids), pos + window + 1)):
if j == pos:
continue
pairs.append((center, ids[j]))
random.shuffle(pairs)
V = len(vocab)
D = 16
class SkipGram(nn.Module):
def __init__(self, V, D):
super().__init__()
self.in_embed = nn.Embedding(V, D)
self.out_embed = nn.Embedding(V, D)
def forward(self, center_ids):
x = self.in_embed(center_ids)
logits = x @ self.out_embed.weight.T
return logits
model = SkipGram(V, D)
opt = torch.optim.Adam(model.parameters(), lr=0.05)
def neighbors(word, topn=6):
if word not in w2i:
return []
W = model.in_embed.weight.detach()
v = W[w2i[word]]
sims = F.cosine_similarity(v[None, :], W, dim=1)
best = torch.topk(sims, k=min(topn + 1, V)).indices.tolist()
best_words = [i2w[i] for i in best if i2w[i] != word]
return best_words[:topn]
probe_words = ["кот", "собака", "кофе", "чай", "король", "королева"]
print("=== До обучения (почти случайно) ===")
for w in probe_words:
print(f"{w:9s} -> {neighbors(w)}")
batch_size = 64
steps = 900
for step in range(steps):
batch = pairs[(step * batch_size):((step + 1) * batch_size)]
if not batch:
batch = random.sample(pairs, k=min(batch_size, len(pairs)))
c = torch.tensor([p[0] for p in batch])
y = torch.tensor([p[1] for p in batch])
logits = model(c)
loss = F.cross_entropy(logits, y)
opt.zero_grad()
loss.backward()
opt.step()
print("\n=== После обучения (появляется смысл) ===")
for w in probe_words:
print(f"{w:9s} -> {neighbors(w)}")
После выполнения кода мы получили такой вывод:
=== До обучения (почти случайно) === кот -> ['кошка', 'принц', 'это', 'с', 'пьет', 'лимоном'] собака -> ['щенок', 'молоком', 'лимоном', 'чай', 'мясо', 'пьет'] кофе -> ['напиток', 'ест', 'принц', 'женщина', 'молоко', 'кость'] чай -> ['кость', 'щенок', 'молоком', 'собака', 'это', 'мужчина'] король -> ['с', 'принцесса', 'мясо', 'пьет', 'молоком', 'напиток'] королева -> ['женщина', 'молоко', 'пес', 'щенок', 'мясо', 'это'] === После обучения (появляется смысл) === кот -> ['котенок', 'кошка', 'любит', 'молоком', 'пьет', 'собака'] собака -> ['пес', 'кошка', 'мясо', 'кот', 'ест', 'лимоном'] кофе -> ['чай', 'принц', 'напиток', 'женщина', 'молоком', 'король'] чай -> ['кофе', 'принцесса', 'король', 'королева', 'принц', 'женщина'] король -> ['принц', 'принцесса', 'напиток', 'чай', 'мужчина', 'женщина'] королева -> ['принцесса', 'мужчина', 'ест', 'чай', 'напиток', 'король']
После обучения в списке «ближайших слов» могут попадаться неожиданные соседи — это нормально. До обучения эмбеддинги случайные, а после обучения модель сближает слова, которые встречаются в похожих контекстах, поэтому она группирует их «по ситуации», а не по строгим словарным определениям.
На результат также влияет то, что мы используем небольшой набор фраз: на таком мини‑корпусе модель легко подхватывает случайные закономерности и иногда «ошибается» в соседях. Главное, что в целом эффект сохраняется — после обучения списки становятся заметно более осмысленными, чем до него.
Шаг 3. Теперь визуализируем получившиеся эмбеддинги. На предыдущем шаге у каждого слова появился многомерный вектор, и сравнивать такие векторы напрямую неудобно. Поэтому код ниже проецирует их в две координаты и строит график: каждое слово — одна точка. На нем будет видно, что слова из похожих контекстов оказываются рядом и образуют группы.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
W = model.in_embed.weight.detach().cpu().numpy()
coords = TSNE(
n_components=2,
perplexity=5,
init="random",
learning_rate="auto",
random_state=0
).fit_transform(W)
plt.figure(figsize=(12, 8))
for i, w in i2w.items():
x, y = coords[i]
plt.scatter(x, y, s=60)
plt.text(x + 0.02, y + 0.02, w, fontsize=12)
plt.title("Эмбеддинги после обучения")
plt.grid(True, linestyle="--", alpha=0.35)
plt.show()
В результате на графике видно, что слова начинают собираться в группы:
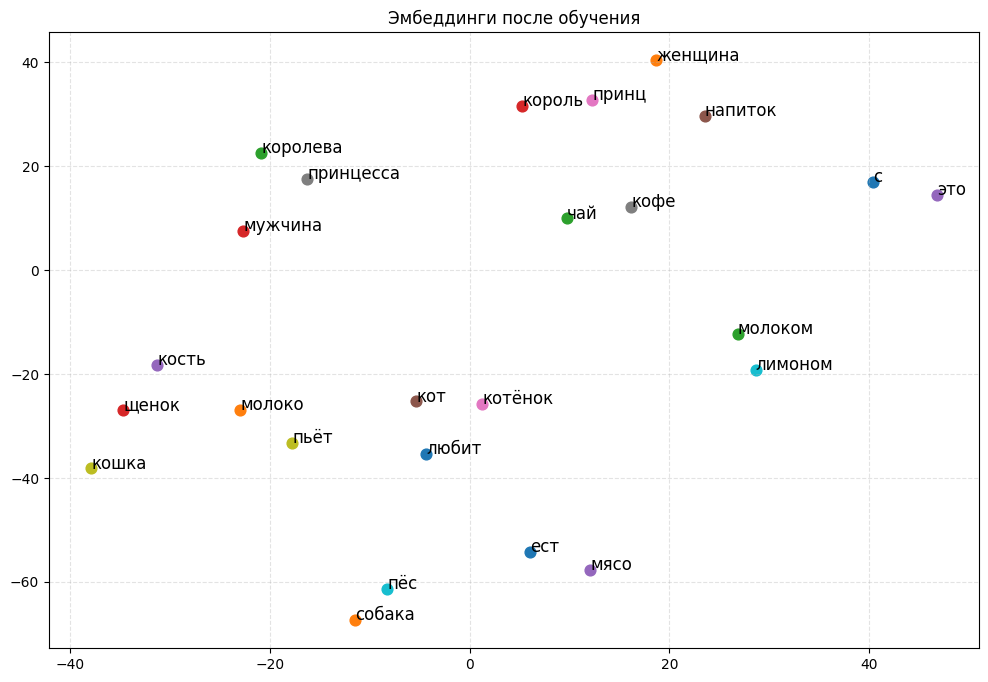
Если вы повторили все шаги, то увидели: эмбеддинги не задаются модели заранее — они формируются в процессе обучения. Сначала векторы случайные, поэтому все выглядит как шум. Однако чем дольше модель тренируется угадывать слова по контексту, тем заметнее она сближает слова из похожих ситуаций — и на графике начинают проявляться осмысленные группы.
