


Для того, чтобы распознавать естественную человеческую речь, в машинном обучении используют специальные модели — языковые. Они умеют воспринимать содержание текста, продолжать предложения и вести осмысленный диалог.
Вместе с дата-сайентистом и биоинформатиком Марией Дьяковой подготовили гайд о том, как устроены самые популярные языковые модели и что нужно знать, чтобы начать с ними работать.
Что такое языковые модели
Языковая модель — это алгоритм, который анализирует текст, понимает его контекст, обрабатывает и генерирует новые тексты. В его основе лежат нелинейные и вероятностные функции, с помощью которых модель предсказывает, какое слово может быть следующим, — рассчитывает вероятность для каждого из возможных слов.

Например, если на вход дано предложение «Сегодня хорошая погода», от хорошо обученной модели ожидается продолжение фразы вида «На улице тепло и солнечно».
В основе языковых моделей, как правило, лежат нейронные сети, обученные на большом количестве текстовой информации. Это могут быть книги, статьи из «Википедии» и словарей, сообщения на форумах и многое другое. Ожидаемый результат для модели зависит от того, на чем конкретно ее обучали.
Например, если обучать модель на литературе об Африке, вполне вероятно, что ожидаемым ответом на запрос «Сегодня хорошая погода» станет «Сегодня не жарко и идет дождь». А если датасетом для обучения станут статьи по метеорологии, ожидаемый результат может выглядеть как «Температура +23°, влажность воздуха 60%».
Задачи языковых моделей
Главная задача языковой модели — «понимать» текст по закономерностям в данных и генерировать осмысленный ответ. Благодаря тонкой настройке ее можно использовать и для других задач. Например, для классификации или NER (Named Entity Recognition) — распознавания сущностей в тексте.
Вот несколько примеров, что можно делать с помощью языковых моделей:
- анализировать тональность текстов, например отзывов в интернет-магазинах;
- сортировать новости по категориям, к примеру «Финансы» или «Общество»;
- обнаруживать и фильтровать спам;
- находить в тексте ключевые мысли, например формировать краткое содержание научной статьи;
- выделять в тексте имена, адреса, названия товаров и цен — скажем, чтобы автоматически наполнить базы данных, и др.
Кроме того, языковые модели могут самостоятельно генерировать осмысленные тексты в ответ на запрос. Например, уже существовали случаи, когда модель генерировала сюжет книги или текст дипломной работы.
Что такое большие языковые модели
Отдельным классом языковых моделей можно выделить LLM (large language model), или большие языковые модели. К ним относятся популярные сегодня типы моделей GPT и BERT. Среди характерных особенностей LLM:
- очень большой размер — в таких моделях используется более миллиарда параметров. В самых известных LLM их сотни миллиардов;
- обучение на огромном количестве входных данных — к примеру, 50 миллиардов веб-страниц из базы Common Crawl;
- большие вычислительные ресурсы, необходимые для создания и обучения такой модели;
- способность обрабатывать входные данные параллельно, а не последовательно.
Благодаря своим размерам и особенностям архитектуры LLM отличаются большей гибкостью. Одну и ту же модель можно использовать и для генерации кода, и для имитации живого диалога или придумывания историй. Яркий пример — всем известная ChatGPT.
Структура языковых моделей
Структура зависит от того, какая математическая модель использовалась при ее создании. Невозможно говорить о какой-то единой структуре — в разные годы применяли разные подходы. Первые языковые модели были статистическими, основанными на вероятностном алгоритме цепей Маркова, более поздние имели в своей основе рекуррентные нейронные сети (RNN). Это вид нейронных сетей, предназначенный для обработки последовательных данных.
Современные большие языковые модели, такие как BERT или GPT, основаны на структуре под названием «трансформер». Такая архитектура оказалась самой эффективной и давала лучшие результаты, чем статистические или RNN-модели.
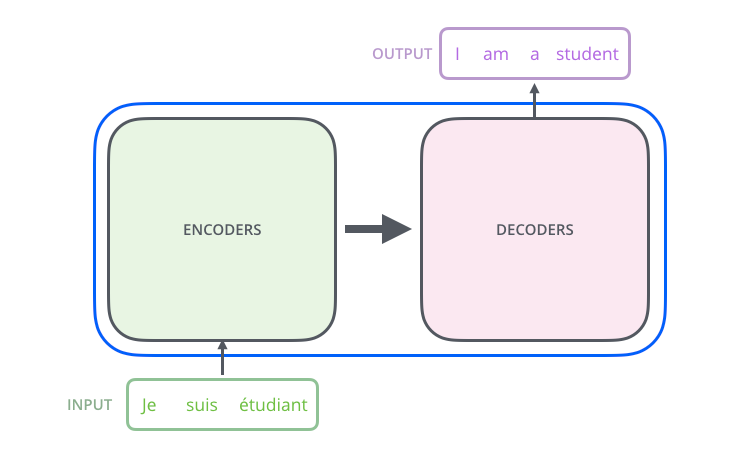
Трансформер — это математическая модель, которая состоит из двух частей — энкодера и декодера:
- Энкодер кодирует входной текст, преобразуя его в вектор чисел, который максимально точно описывает исходные данные.
- Декодер преобразует числовой вектор обратно в текст или другое смысловое выражение, которое требуется от модели. Например, это может быть категория, к которой относится входной текст, — художественная литература, научная статья и так далее.
Внутренний вектор, с которым работает модель, описывает связи между исходными данными и позволяет модели обрабатывать и генерировать текст.
Работа трансформера основана на механизме внимания. Это значит, что слова в тексте рассматриваются не сами по себе, а в контексте: он зависит от слов вокруг, положения слова в предложении и частоты сочетаний конкретных слов. Благодаря этому механизму языковая модель способна глубоко анализировать текст и распознавать его смысл так же, как человек.
Внутри энкодера и декодера находятся разные комбинации слоев внимания и нейронных сетей прямого распространения. Слои внимания определяют контекст и связи между токенами. В их основе лежат три матрицы:
- Матрица запроса (Q) анализирует слово в контексте других слов.
- Матрица ключевых значений (K) проверяет, как то или иное слово относится к входному запросу.
- Матрица значений (V) определяет, что означает слово не в контексте предложения, а для языка в целом.
Нейронные сети прямого распространения расположены после слоев внимания. Они добавляют к данным нелинейные преобразования — превращают вычисленные данные для каждого слова в N-мерный вектор.
Между слоями есть связи, которые помогают учитывать данные с предыдущих слоев. Это помогает не потерять важную информацию при прохождении какого-либо слоя.
Перед загрузкой в энкодер входные данные проходят через слои токенизации и эмбеддинга.
- Токенизация — это процесс, при котором каждому слову или знаку во входном тексте присваивается свой уникальный ID. Модель получает на вход именно набор ID, а не «сырой» текст.
- Эмбеддинг — превращение набора ID в смысловые векторы на первом слое языковой модели. Сами по себе поступающие в модель ID только сопоставляют со словами какие-то числа. Эмбеддинг преобразует их в вектор таким образом, чтобы схожие по смыслу слова находились ближе друг к другу в векторном пространстве.
Например, слова «дождь», «солнце», «ветер», скорее всего, будут находиться рядом в векторном пространстве, потому что все они описывают погоду. А не связанные по смыслу слова вроде «солнце», «компьютер», «собака» будут находиться далеко друг от друга.
Правда, многое зависит от обучения модели. Если ее обучали на текстах, где солнце, компьютер и собака упоминаются в одном контексте, она может распознать их как семантически близкие друг к другу слова.
Отдельный вид эмбеддингов — позиционные. Это слои, которые определяют положение слова в смысловом векторе на основе его позиции в предложении. Они полезны в ситуациях, когда слово меняет смысл в зависимости от его расположения.
Для примера можно взять две фразы в английском языке: I can take («я могу взять…») и I take a can («я беру банку»). Слова одни и те же, но слово can в первом случае означает «могу», а во втором — «банка». Кстати, слово take в первом предложении в зависимости от остальной части фразы может означать не только «взять», но и «выдержать». Чтобы распознавать такие моменты, и нужны позиционные эмбеддинги.
Как работают языковые модели
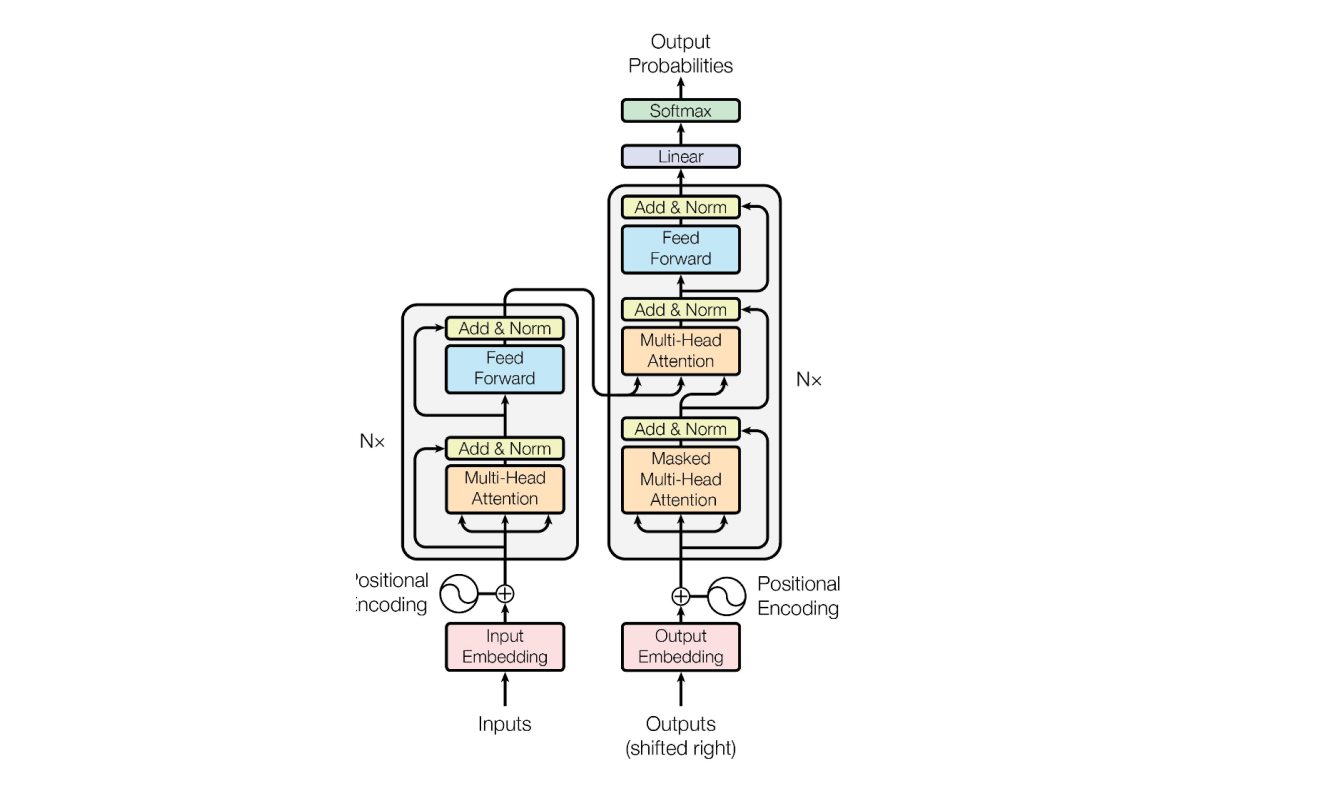
Принцип работы могут различаться в зависимости от архитектуры, но в этой статье мы рассмотрим именно трансформерные, как самые актуальные. Два самых известных семейства моделей, BERT и GPT, работают по одному принципу: предсказывают скрытое слово, наиболее вероятное в заданном контексте.
- Входной текст проходит токенизацию и эмбеддинг.
- После этого загружается в энкодер, где по очереди пропускается через слои внимания и полносвязные слои. На этом этапе входные данные анализируют и выделяют важные токены.
- Из энкодера данные переходят в декодер. Тот получает собранную энкодером информацию о контексте и на ее основе генерирует новые токены — предсказывает на основе предыдущих.
- На выходе трансформер выдает набор вероятностей, которые преобразуются в слова.
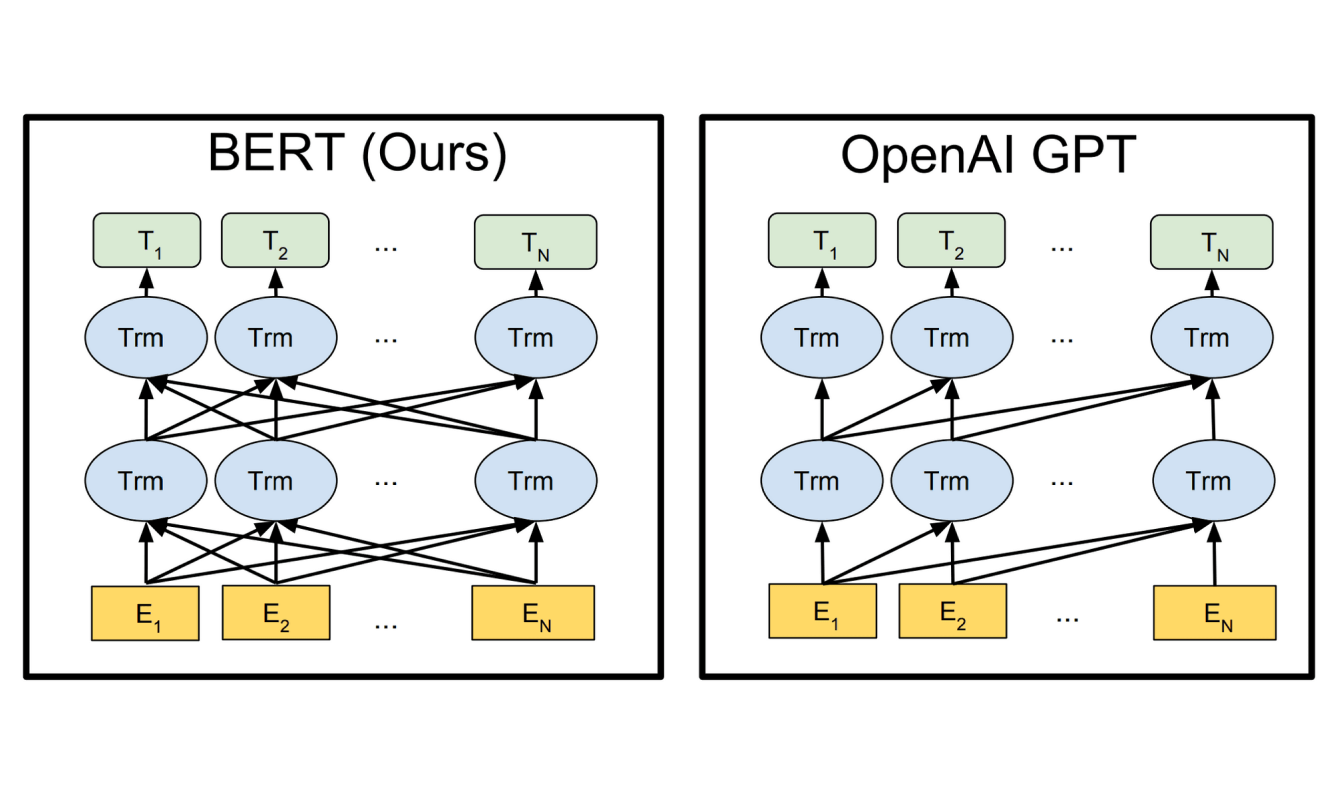
Разница между BERT и GPT в особенностях обработки. В первой основную задачу выполняют энкодеры, вторая построена на базе декодеров. На практике это означает следующее:
- BERT предсказывает слово внутри предложения и учитывает все окружающие слова до и после скрытого. Ее чаще используют в задачах поиска пар, классификации, трансформации имеющихся текстовых данных.
- GPT всегда предсказывает следующее слово и обращает внимание только на предыдущие слова в предложении. На выходе получается набор вероятностей для каждого скрытого слова. Модель удобнее использовать для генерации новых текстов с нуля.
Как обучают языковые модели
Процесс обучения можно разделить на несколько этапов.
1. Подготовка датасета. Для обучения языковых моделей используют огромные текстовые базы данных. Если модель узкоспециализированная, то и данные для нее берут определенного формата, например научные статьи по конкретной теме или комментарии в интернете. А, например, всем известная ChatGPT обучалась на данных очень разного формата, чтобы стать универсальной.
Данные недостаточно собрать — их нужно очистить и подготовить к загрузке в модель. При очистке из огромного массива информации удаляют персональные данные, запрещенные или некорректные сведения. Иначе модель не получится использовать: представьте чат-бот для бизнеса, который нецензурно ругает клиентов.
Очищенные данные готовят к загрузке: токенизируют, а в случае с BERT — заменяют часть слов в фразах на маску. Модель должна научиться предсказывать, какие слова находятся вместо маски. После этого датасет разделяют на обучающий, валидационный и тестовый.
2. Загрузка в модель. Подготовленные данные передают в модель для обучения. Та поочередно тренируется на каждой из частей датасета:
- на обучающей. Эта выборка — набор примеров, которые должны показать модели распределение связей между словами. Когда модель обучается на этой выборке, она корректирует векторы и формирует собственное «представление» о взаимосвязях между словами;
- на валидационной. Эту часть датасета используют после прохождения обучающей выборки — сравнивают, насколько изменилась точность работы модели в зависимости от этапа обучения. Валидацию могут проводить несколько раз и проверяют, в какой момент модель выдает более качественные результаты;
- на тестовой. Тестовые данные нужны уже после завершения обучения и валидации. Их используют, чтобы окончательно протестировать уже обученную модель. Иногда такие наборы данных специально составляют из примеров, которых нет в обучающей и валидационной выборке, — чтобы посмотреть, как поведет себя модель при работе с незнакомыми словами.
Само обучение происходит примерно по тому же принципу, что для классических нейросетей. Оно состоит из трех этапов:
- прямой проход данных по сети — модель обрабатывает информацию и делает предположения о результате;
- вычисление ошибки — модель проверяет, насколько корректны оказались ее предсказания, и вычисляет отклонение от верных значений;
- обратный проход — модель распространяет по слоям вычисленную ошибку и корректирует веса на ее основе, чтобы давать более точные предсказания в дальнейшем.
Разница с обычными нейросетями в том, что этапы сложнее вычислительно: они более комплексно устроены, а происходящие внутри модели процессы могут быть нелинейными. Сама модель намного больше классических нейронных сетей, при обучении используются огромные датасеты — все это может увеличивать риск взрывных градиентов, переобучения, недообучения и других проблем, характерных для нейросетей.
Поэтому главная особенность обучения языковых моделей — необходимость особенно тщательной и тонкой настройки обучающей стратегии, чтобы избежать ошибок. В остальном, структурно и концептуально, подход к обучению остается таким же.
Методы обучения также могут различаться. Среди основных выделяют:
- Предварительное обучение на больших текстовых данных. Его используют, чтобы обучить модель понимать язык в целом, а не какие-то специфические темы. Например, задача разработчика — обучить модель, чтобы она понимала статьи по генетике на русском языке. Но качественных статей на эту тему не очень много, и этого количества не хватит для обучения крупной модели. Поэтому сначала модель обучается на «обычных» текстовых данных разного формата, чтобы потом дообучиться на специфических.
- Тонкая настройка. Сюда входит дообучение существующей модели под конкретную задачу. Например, чат-бота, уже знакомого с языком в целом, дообучают, чтобы он понимал молодежный сленг. Или алгоритм тренируют понимать и анализировать отзывы на сайте.
- Prompt-инженерия. Так дообучают и настраивают уже работающие модели — обучение происходит на основе запросов. Инструкции для модели формулируют так, чтобы та выдавала желаемый результат. Например, подают на вход данные в определенном формате, для которого модель выдаст более четкий ответ.
- Аугментация данных. Это вариант дообучения с помощью искусственно составленного набора данных. Например, модели для биологических задач не просто подают на вход тексты, а предварительно обогащают их названиями генов и молекул. Это учит модель распознавать и понимать специфические термины.
- Обучение с подкреплением. С помощью этого метода модель обучают генерировать текст на основе вознаграждений. Модель получает «подкрепление», если результат выглядит определенным образом. Это помогает, например, настраивать диалоговые модели, чтобы их речь звучала более естественно.
Для решения реальных задач часто используют предобученные модели. Они уже прошли предварительное обучение на больших данных и понимают язык в целом. Остается только дообучить их на специфических датасетах, например с помощью аугментации данных — это поможет решать специализированные задачи.

Построение языковой модели
Простую модель можно построить с нуля самостоятельно, но чаще используют уже готовые: BERT, GPT и другие. Их адаптируют под конкретную задачу, но структура и принцип работы остаются неизменными. Для этого из специализированных библиотек, например TensorFlow или PyTorch, загружают стандартные модели. Часто — предобученные, с уже имеющимися базовыми настройками.
Например, так выглядит построение и обучение модели BERT:
from transformers import BertTokenizer, BertForMaskedLM, Trainer, TrainingArguments
from datasets import Dataset, load_dataset
import torch
# Преобразование предложения в токены
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
sentence = "Transformers are amazing!"
tokens = tokenizer.tokenize(sentence)
print(f"Tokens: {tokens}")
# Подготовка данных к обучению
# Создаем тренировочные данные с помощью маски
masked_sentence = "Transformers are [MASK]!"
input_ids = tokenizer.encode(masked_sentence, return_tensors='pt')
# Создаем метки, заменяя все не замаскированные токены на -100
labels = input_ids.clone()
mask_token_index = (input_ids == tokenizer.mask_token_id).nonzero(as_tuple=True)[1]
labels[input_ids != tokenizer.mask_token_id] = -100
# Пример создания кастомного набора данных
# Здесь мы используем один пример для иллюстрации
train_dataset = Dataset.from_dict({
'input_ids': [input_ids[0].tolist()],
'labels': [labels[0].tolist()]
})
# Загружаем предварительно обученную модель BERT
model = BertForMaskedLM.from_pretrained("bert-base-uncased")
# Выставляем параметры обучения
training_args = TrainingArguments(
output_dir="./results", # папка для выходных данных
learning_rate=5e-5, # темп обучения
per_device_train_batch_size=8, # размер батча
num_train_epochs=3, # количество эпох
logging_dir="./logs", # папка для логов
)
# Создаем обучающий объект
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
)
# Обучаем модель
trainer.train()
# Сохраняем обученную модель
model.save_pretrained("./my_bert_model")В каких сферах и зачем применяют языковые модели
Языковые модели, в частности BERT и GPT, — «золотой стандарт» для задач распознавания естественного языка, или NLP. Фактически это основной инструмент для их решения.
Вот в каких сферах чаще всего обрабатывают естественный язык:
- Наука. Языковые модели генерируют абстракты — краткие содержания научных статей, которые публикуются перед основным текстом. Также модели помогают в поиске научных текстов, классификации статей, обработке результатов исследований и многом другом.
- Медицина. Модели используют для поиска специализированных текстов, анализа симптомов, а иногда — для диагностики. Например, в 2018 году в Пенсильвании разработали языковую модель, которая распознает у людей депрессию по их постам в соцсетях. Точность составила около 70% и зависела от того, насколько активно человек вел соцсеть.
- Создание цифровых сервисов. С помощью языковых моделей работает огромное количество IT-решений: от поисковых систем и переводчиков до чат-ботов в соцсетях. Например, крупные компании создают ботов-помощников с собственным характером и манерой речи.
- Маркетинг. Языковые модели используют для генерации контент-планов, идей для статей и сторис, рекламных постов и баннеров. С их помощью придумывают слоганы и даже названия для новых брендов.
Чаще всего в этих сферах используют уже готовые модели. Собственные в основном разрабатывают в двух случаях: при решении узкоспециализированных задач и во время исследований по созданию новых архитектур.
Как модели могут развиваться в будущем
Когда появилась GPT-3, использование языковых моделей резко выросло, а их развитие ускорилось. Особенно это стало заметно после выхода чат-бота ChatGPT от OpenAI. Техника становится мощнее, возможности для обучения ML-моделей — шире. Скорее всего, этот тренд продолжится и дальше. Вот лишь некоторые направления возможного развития языковых моделей:
- Появление новых архитектур и алгоритмов. Исследования в этой сфере проводят и некоммерческие организации, и крупные бренды. Возможно, появятся новые более эффективные структуры, какой когда-то стал трансформер.
- Решение более абстрактных задач. Вероятно, в будущем языковые модели будут адаптировать под цели, а не конкретные действия. Например, задачей модели станет не «сгенерируй план работ», а «оптимизируй затраты на ремонт».
- Проникновение во все сферы жизни. Чат-боты для поиска и анализа станут такими же привычными, как сейчас — онлайн-переводчики. Результаты работы моделей будут точнее, их начнут активнее использовать для поиска информации или генерации идей.
Как научиться работать с языковыми моделями
Для работы с языковыми моделями необходимы следующие навыки и знания:
- Программирование: владение Python и работа с библиотеками, такими как TensorFlow и PyTorch.
- Математика: понимание линейной алгебры, теории вероятностей и статистики, которые лежат в основе работы алгоритмов машинного обучения.
- Теория обработки естественного языка (NLP): знание архитектуры моделей, принципов их работы, подготовки данных и оптимизации моделей.
Эти навыки проще всего освоить в вузах, где учебные программы помогают последовательно изучать компьютерные науки, математику и машинное обучение. Скилы также можно получить на специальных курсах или самостоятельно — при должном желании и мотивации.
При этом компаниям в первую очередь интересен практический опыт специалиста. Особенно полезно, когда у человека есть специфический бэкграунд. Например, если компания работает в медицинской сфере, знание биологии или медицины может оказаться важнее, чем глубокие знания в IT. Потому что настройка и обучение специализированных моделей требуют понимания данных, которые она анализирует.
Чтобы потренироваться в работе с языковыми моделями, достаточно базовых знаний Python и основ хотя бы одной библиотеки ML. А также нужно понимать основные концепции NLP и уметь подготовить данные.
Полезные материалы для самостоятельного изучения:
- Денис Ротман, Transformers for Natural Language Processing: книга, которая подробно рассматривает современные модели обработки естественного языка.
- Рao МакМахан, «Знакомство с PyTorch»: практическое руководство по одной из ведущих библиотек для разработки моделей глубокого обучения.
- Туториалы и документация от разработчиков: на сайтах TensorFlow и PyTorch можно найти много обучающих материалов, которые помогут углубить знания в машинном обучении и NLP.