


Машинное обучение — это область искусственного интеллекта, которая дает компьютерам возможность учиться на опыте без явного программирования. Технология позволяет обрабатывать огромные объемы данных, находить в них закономерности и делать прогнозы с высокой точностью. Когда на пробежке вы запускаете плейлист, который сгенерирован специально для вас, или смотрите подборки товаров по вашим интересам — все это результат машинного обучения.
Как компьютеры учатся, чем им помогают пользователи, когда им нужны учителя — отвечаем на эти и другие вопросы в статье.
Какими бывают модели машинного обучения
Выделяют три типа машинного обучения:
- Надзорное обучение — когда перед началом обучения «учитель», то есть человек, знает правильный ответ. Остается научить машину понимать логику выбора верного ответа.
- Ненадзорное обучение — когда перед началом обучения правильных ответов нет. Модель учится анализировать большой массив данных, искать скрытые зависимости и алгоритмы.
- Подкрепляющее обучение — когда обучение происходит на базе вариативности шагов пользователя. Самый яркий пример — игры с компьютером в шахматы, нарды или шашки. Модель запоминает ходы пользователей и учится просчитывать стратегию наперед.
В статье мы поговорим про первый типа обучения — надзорное обучение или обучение с учителем.

Линейная регрессия
Помните простые школьные тесты по математике, где нужно было продолжить ряд? Например: 2, 4, 6, 8, Х. Интуитивно вы уже знаете, что на месте Х должно стоять 10.
Линейная регрессия учит машину искать такие зависимости между переменными. Метод широко применяется в экономике, финансах, маркетинге и других областях, где необходимо предсказывать, как одна переменная влияет на другую.
Важно понимать, что это примитивный метод, где модель способна учитывать одну-две простые зависимости.
Для чего используют: для оценки цен на жилье, акций, прогнозирования продаж.
Логистическая регрессия
Еще один простой механизм машинного обучения, который позволяет делить объекты по классификации и категории. Как и линейная регрессия, этот алгоритм работает с малым числом зависимостей и делит предмет исследования всего на две категории.
Например, задача — разделить абитуриентов на тех, кто прошел пороговое значение баллов по ЕГЭ, и тех, кто не прошел. Если мы задаем значение порога 150 баллов, то модель поделит абитуриентов на категории выше и ниже порога. При этом с помощью логистической регрессии нельзя узнать процент людей, которые написали ЕГЭ на 160–180 баллов, 180–200 баллов, кого было больше среди «успешных» — мальчиков или девочек, жителей городов или деревень.
При этом, классифицируя статистику, мы получаем возможность прогнозировать наступление событий.
Для чего используют: в банковском кредитовании для оценки вероятности дефолта.
Решающие деревья
Решающие деревья, или деревья принятия решений, — более сложный алгоритм. Он старается охватить разные условия и классифицировать данные через «ветви дерева». Звучит сложно, но вы наверняка сталкивались с этим способом не раз. Просто посмотрите на картинку:
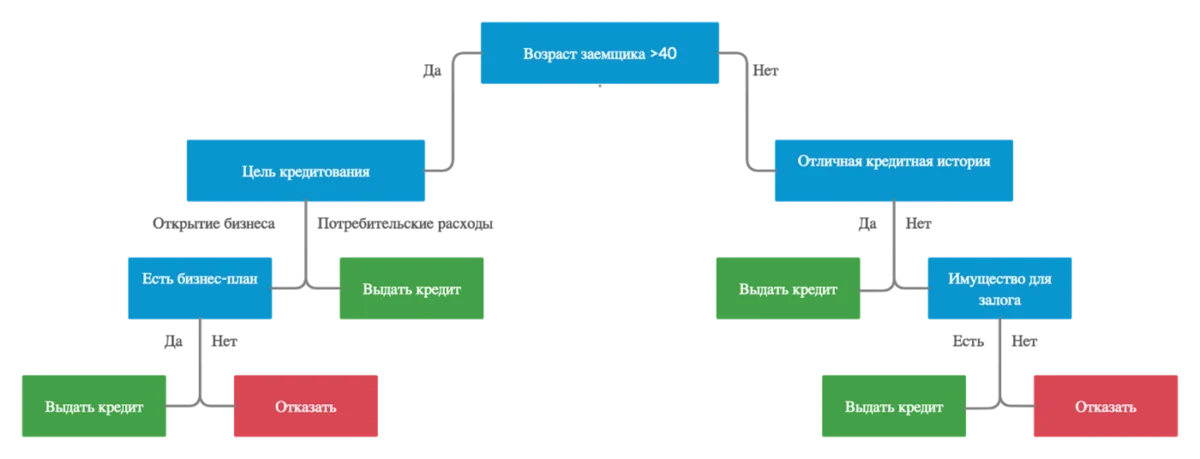
Как человек нередко принимает решения, следуя подобным алгоритмам, так и машина учится делать это автоматически, не привлекая для анализа данных человека.
У метода есть несомненный минус: дерево недостаточно большое, чтобы учесть все тонкости классификации, а значит, приходится упрощать и обобщать данные или же разрабатывать более сложный механизм, например целый лес из деревьев.
Для чего используют: в медицине для диагностических систем.
Случайный лес
Это, как понятно из названия, целый лес деревьев принятия решений. Алгоритм пропускает информацию не через одно дерево, а через сотни похожих с вариативными результатами. Так анализ становится более точным.
Результаты анализа каждого дерева собираются в общее решение, опираясь на самый популярный результат.
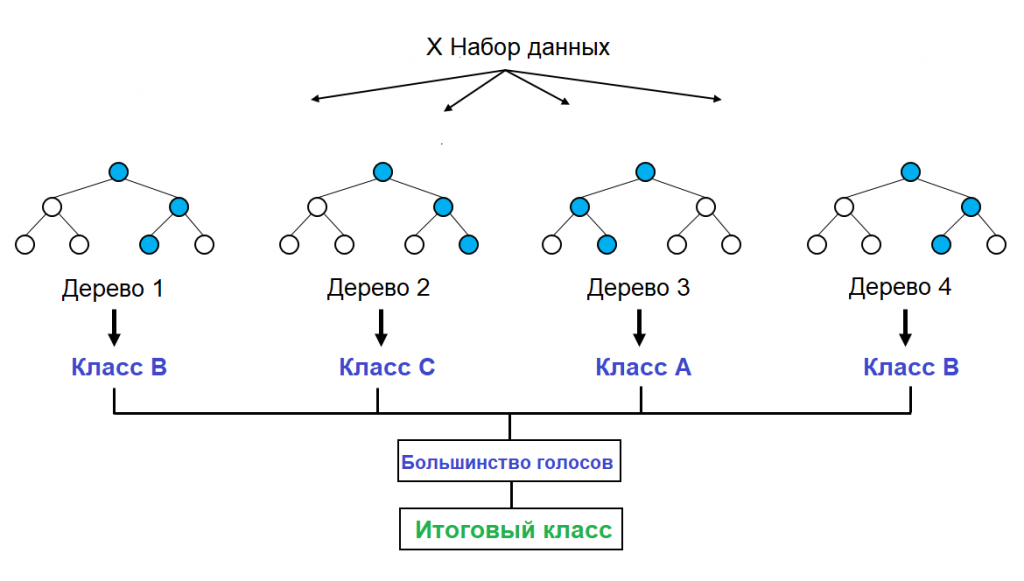
Для чего используют: эффективен для больших наборов данных, например в биоинформатике для геномного анализа.
Бустинг
Если даже целый лес деревьев не дает нужный результат, поможет бустинг. Метод прост в понимании: строим первое дерево, которое совершает ошибку. Опираясь на эту ошибку, строим второе дерево. Оно снова ошибается. Указываем на ошибку и строим третье дерево. Так будет происходить ровно до того момента, пока результат не достигнет максимальной точности.
Как узнать, что результат достиг максимальной точности? Все просто: сначала деревья, анализируя свои ошибки, выдают более точный результат, потом доходят до пика точности и снова начинают совершать больше ошибок.
В этом методе главное — вовремя остановиться.
Для чего используют: активно применяется в финансах для управления рисками.
Метод k-ближайших соседей
Этот алгоритм обучения объединяет объекты с похожими свойствами в группы. Метод строится на гипотезе компактности: все объекты с похожими свойствами находятся рядом друг с другом. То есть смысл метода скрыт в его названии: он объединяет в одинаковые множества объекты, которые соседствуют друг с другом.
При этом алгоритм k-ближайших соседей нередко ошибается. Он не принимает во внимание, что у объектов, которые располагаются близко друг к другу, могут быть разные свойства.
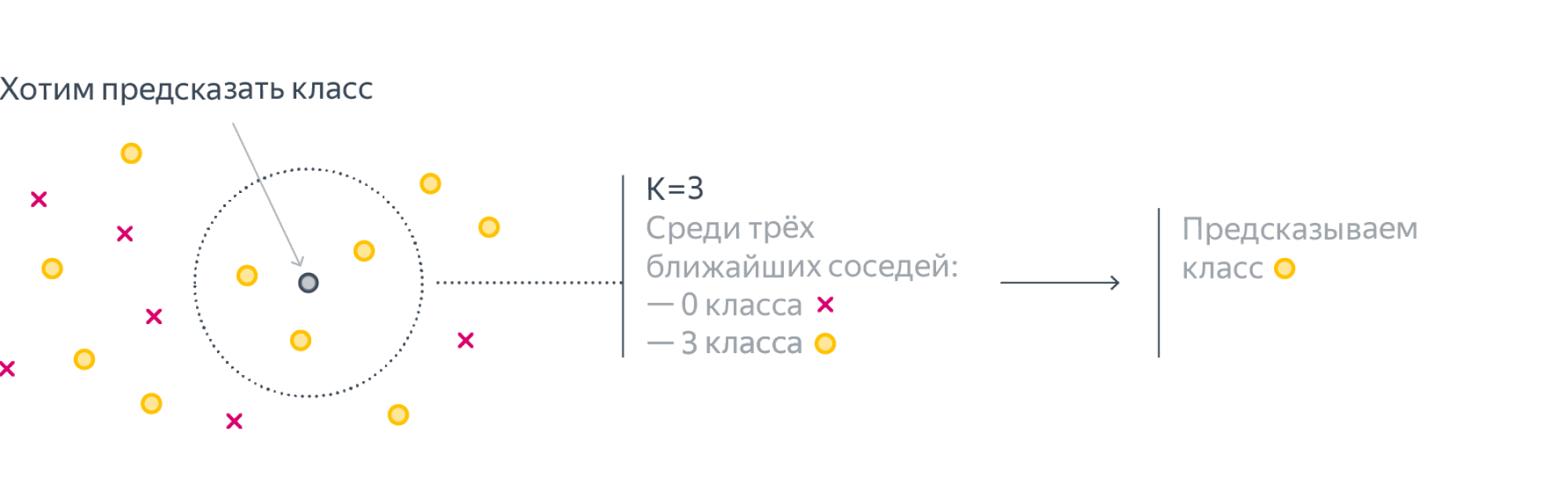
Для чего используют: используется для рекомендательных систем и сегментации клиентов.
Метод опорных векторов
Метод k-ближайших соседей строит плоские границы между объектами. Метод опорных векторов работает в объемной плоскости и делит объекты не по прямым, а по кривым. При этом важно, чтобы каждая группа объектов лежала как можно дальше от плоскости деления.
Для чего используют: эффективен для распознавания образов и текстовой классификации.

Наивный байесовский классификатор
Еще один метод, который помогает классифицировать объекты. О нем подробно мы уже говорили в глоссарии. Метод строится на теореме Байеса — английского математика XVIII века.
Это базовая теорема теории вероятности. Она предсказывает вероятность события на основе других произошедших событий или следствий. Самое популярное использование байесовского классификатора — это фильтрация спама. Каждое письмо оценивается по количеству слов, которые могут быть расценены как спамные. Постепенно алгоритм учится выявлять все новые методы спама.
Для чего используют: полезен в спам-фильтрах и анализе эмоций.
Нейронные сети
Относительно новый алгоритм, который уверенно завоевал интернет за последние годы. Нейронные сети имитируют работу мозга человека, распознают образы, обрабатывают речь и работают автономно.
Попробуем разобраться, как строится работа нейронной сети. Сначала выстраивается классификатор. Например: клубника — красного цвета, а лимон — желтого. Сеть изучает предмет (запоминает цвета пикселей) и далее может оценивать предметы согласно классификатору.
Когда нейрон один — жить сложно. Все красные предметы станут клубникой, желтые предметы станут лимоном, а предметы остальных цветов просто исчезнут из поля зрения нейросети. Поэтому создаются тысячи нейронов, которые связаны между собой.
Примечательно то, что нейросеть сама создает новые нейронные связи, а разработчик может лишь поощрять или наказывать за выданные ответы.
Для чего используют: справляются с комплексными задачами в различных сферах от автономного вождения до автоматизации процесса творчества.
Сверточные нейросети
Это отдельный класс нейросетей, которые специализируются на визуальном контенте — фото, видео, иллюстрации. Однако не стоит думать, что речь идет о нейросетях, которые генерируют картинки.
Все с точностью до наоборот. Сверточные нейросети распознают и классифицируют объект. Например, по очертаниям нейросеть может распознать человека, далее, сконцентрировавшись на отдельных участках лица, классифицировать цвет глаз, волос.
Для чего используют: в компьютерном зрении для распознавания изображений и видеоаналитики.