

В машинном обучении бывает так: вы загрузили данные, выбрали алгоритм (например, случайный лес или градиентный бустинг), нажали fit(), а качество получилось… ну, так себе. Вы начинаете менять какие-то цифры в скобках при создании модели, и внезапно точность вырастает на 5%.
Эти «цифры в скобках» и есть гиперпараметры. А процесс их подбора — это настоящее искусство, которое отличает новичка от опытного Kaggle-мастера. Сегодня мы разберем эту тему от и до: начиная с простого перебора и заканчивая умной байесовской оптимизацией.
Что такое гиперпараметры
Гиперпараметры в машинном обучении — это настройки модели, которые задаются до начала обучения, а не подбираются автоматически в процессе. Они определяют, как именно модель будет учиться: какая будет скорость (learning rate), глубина дерева, количество слоев в нейросети.

Разберем на аналогии из жизни. Представьте, что вы учитесь играть на гитаре.
- Параметры модели — это ваши мышечные рефлексы, мозоли на пальцах и умение зажимать аккорды. Вы приобретаете их в процессе обучения (тренировок). В ML параметры — это, например, веса признаков в линейной регрессии или структура ветвлений в дереве решений. Алгоритм находит их сам, изучая данные.
- Гиперпараметры — это натяжение струн (настройка гитары), толщина медиатора или высота стула, на котором вы сидите. Вы должны задать их до начала обучения. Алгоритм не может выучить их из данных напрямую. В ML это, например, максимальная глубина дерева (max_depth), скорость обучения (learning_rate) или количество соседей в KNN (n_neighbors).
Почему подбор гиперпараметров важен
Неправильные гиперпараметры могут убить даже самую совершенную модель. Если задать слишком большую глубину дерева, модель просто вызубрит тренировочные данные наизусть, но провалится на новых данных (это называется переобучение, или overfitting). Если задать слишком маленькую — модель не уловит никаких закономерностей (недообучение, или underfitting). Правильный подбор гиперпараметров позволяет найти идеальный баланс и выжать максимум метрики качества (Accuracy, F1, ROC-AUC) из вашего алгоритма.
Как правильно оценивать качество модели
Главное правило ML: никогда не оценивайте качество модели на тех же данных, на которых она обучалась! Иначе вы обманете сами себя.
Для правильного подбора гиперпараметров мы делим данные на три части (Train / Val / Test) или используем кросс-валидацию (Cross-Validation).
Давайте посмотрим на схему кросс-валидации K-Fold (когда данные делятся на K частей, или «фолдов»):
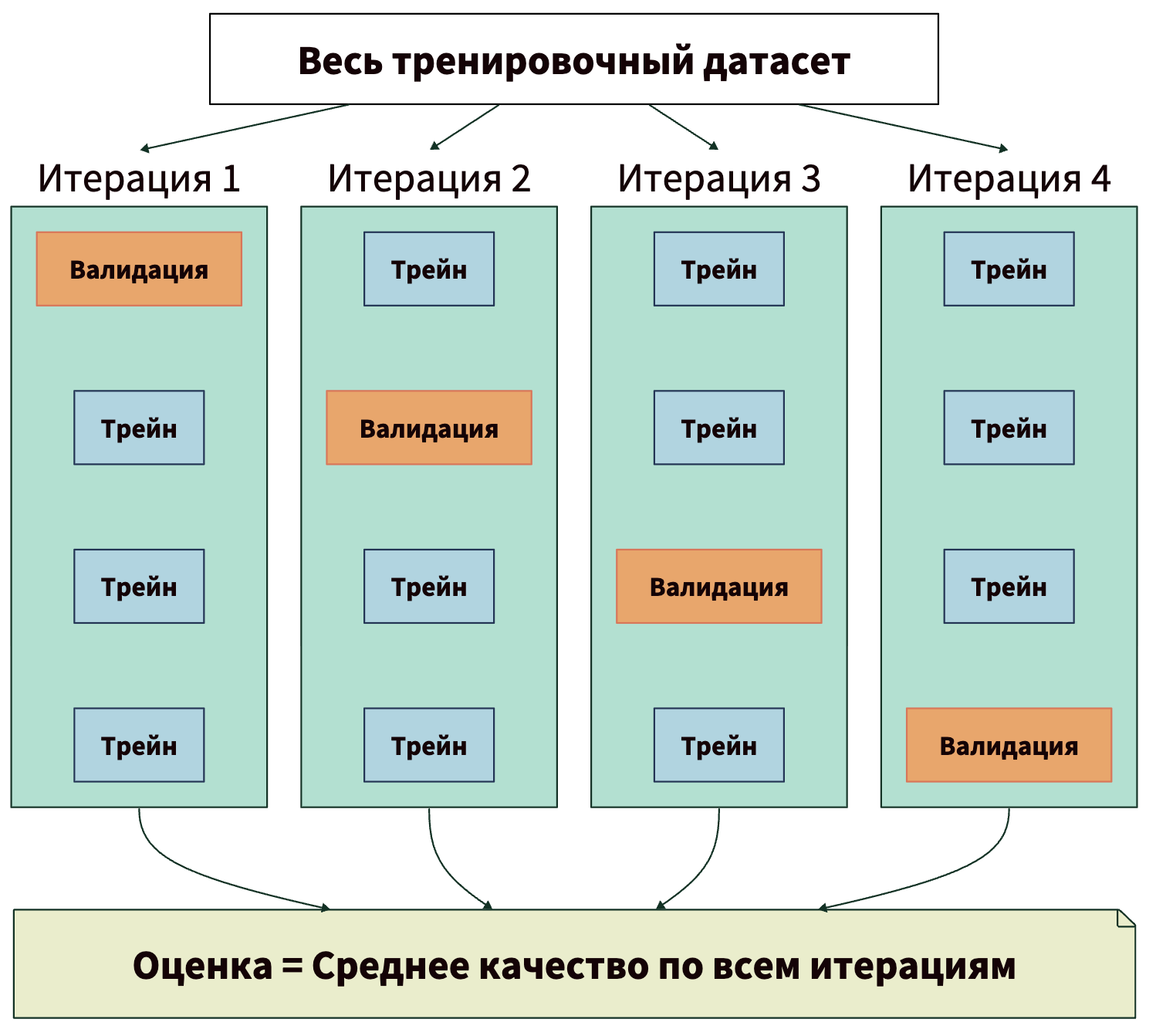
При переборе гиперпараметров для каждой комбинации настроек запускаем кросс-валидацию, получаем среднюю оценку. Выбираем ту комбинацию, которая показала себя лучше всего. В конце проверяем лучшую модель на отложенном Test-сете.
Grid Search — перебор по сетке
Grid Search (поиск по сетке) — это самый прямолинейный подход, метод «грубой силы». Вы задаете списки значений для каждого гиперпараметра, а алгоритм просто перебирает все возможные комбинации.
Пример из жизни. Вы потеряли ключи где-то на футбольном поле. Grid Search означает, что вы разобьете поле на квадраты 1 1 м и будете последовательно, шаг за шагом осматривать каждый квадрат, пока не проверите все поле.
Плюсы и минусы подхода Grid Search
Плюсы
- Простота и понятность: логика элементарна.
- Воспроизводимость: при одних и тех же данных вы всегда получите один и тот же результат.
- Гарантия: если лучшая комбинация есть в вашей сетке, Grid Search ее точно найдет.
Минусы
- Экспоненциальный рост времени («проклятие размерности»): Если у вас пять гиперпараметров и для каждого вы задали по десять значений, то количество комбинаций составит 1010101010=100 000. Если обучение одной модели занимает одну минуту, поиск займет почти 70 дней. Это делает Grid Search абсолютно непригодным для сложных моделей (например, для нейросетей или больших ансамблей градиентного бустинга).
Как в Grid Search помогает логарифмическая шкала
Для некоторых параметров (например, learning_rate или коэффициентов регуляризации C, alpha) нет смысла перебирать значения линейно: [0.1, 0.2, 0.3, 0.4]. Разница между 0.1 и 0.2 огромна, а между 100.1 и 100.2 — ничтожна. В таких случаях нужно использовать логарифмическую шкалу, меняя порядок величины: [0.001, 0.01, 0.1, 1, 10, 100].
Реализация Grid Search в scikit-learn
В Python это делается с помощью класса GridSearchCV (CV означает, что внутри вшита кросс-валидация).
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_breast_cancer
# Загружаем данные
X, y = load_breast_cancer(return_X_y=True)
# Инициализируем базовую модель
rf = RandomForestClassifier(random_state=42)
# Задаем "сетку" гиперпараметров (словарь)
param_grid = {
'n_estimators': [50, 100, 200], # Количество деревьев
'max_depth': [None, 10, 20], # Максимальная глубина
'min_samples_split': [2, 5, 10] # Мин. объектов для разделения узла
}
# Настраиваем Grid Search
# cv=5 означает кросс-валидацию 5-fold
# n_jobs=-1 использует все ядра процессора для ускорения
grid_search = GridSearchCV(estimator=rf, param_grid=param_grid, cv=5, n_jobs=-1, scoring='accuracy')
# Запускаем перебор (это может занять время)
grid_search.fit(X, y)
print(f"Лучшие гиперпараметры: {grid_search.best_params_}")
print(f"Лучшее качество (Accuracy): {grid_search.best_score_:.4f}")
Random Search — случайный поиск
Вместо того чтобы перебирать все комбинации по жесткой сетке, Random Search выбирает случайные значения из заданных вами диапазонов (распределений) определенное количество раз (задается параметром n_iter).
Пример из жизни. Вы все еще ищете ключи на футбольном поле. Но теперь просто закрываете глаза, крутитесь на месте, кидаете дротик в карту поля и идете искать туда, куда он попал, — и так сто раз. Звучит глупо? А вот в математике это зачастую работает лучше, а главное, быстрее!
Почему Random Search эффективнее Grid Search
В 2012 году исследователи Джеймс Бергстра и Йошуа Бенжио опубликовали знаменитую статью, где доказали, что случайный поиск превосходит поиск по сетке. Причина в том, что не все гиперпараметры одинаково важны.
Суть концепции: допустим, у вас есть параметр А (очень важный, сильно влияет на лосс) и параметр Б (почти не влияет). В сетке 33 вы сделаете девять обучений, но проверите только три уникальных значения важного параметра А (потому что для каждого значения А вы трижды проверяете бесполезный параметр Б). В случайном поиске за те же девять обучений вы проверите девять уникальных значений важного параметра А. Вы исследуете пространство гораздо эффективнее.
Задание распределений
Для Random Search мы передаем не списки, а статистические распределения:
- Непрерывные: равномерное распределение от 0.1 до 1.0.
- Дискретные: целые числа от 1 до 100.
- Логарифмические: случайные числа, где чаще выпадают малые значения (для learning_rate).
Реализация в scikit-learn (RandomizedSearchCV)
import scipy.stats as stats
from sklearn.model_selection import RandomizedSearchCV
# Те же данные и модель
rf = RandomForestClassifier(random_state=42)
# Задаем РАСПРЕДЕЛЕНИЯ, а не жесткие списки
param_distributions = {
'n_estimators': stats.randint(50, 500), # Случайное целое от 50 до 500
'max_depth': stats.randint(3, 30),
'min_samples_split': stats.uniform(0.01, 0.1) # Случайная доля от 1% до 11%
}
# n_iter=20 означает, что мы попробуем ровно 20 случайных комбинаций
random_search = RandomizedSearchCV(
estimator=rf,
param_distributions=param_distributions,
n_iter=20,
cv=5,
n_jobs=-1,
random_state=42,
scoring='accuracy'
)
random_search.fit(X, y)
print(f"Лучшие гиперпараметры: {random_search.best_params_}")
print(f"Лучшее качество: {random_search.best_score_:.4f}")

Байесовская оптимизация
Grid и Random Search — это простые, но неоптимальные алгоритмы, так как они не учатся на своих ошибках. Если Random Search попробовал learning_rate = 0.9 и получил ужасный результат, он не сделает вывод «Ага, большие значения тут не работают». В следующей итерации он спокойно может попробовать 0.85.
Байесовская оптимизация — это «умный» поиск, который использует историю предыдущих попыток (априорное знание), чтобы предсказать, какая комбинация гиперпараметров с наибольшей вероятностью улучшит результат.
Пример из жизни. Вы грибник (модель), который ищет поляну с наибольшим количеством белых грибов (максимум метрики) в огромном лесу (пространство гиперпараметров).
- Сначала вы проверяете три-четыре случайных места.
- В одном месте вы нашли поганки, в другом — пару сыроежек, а в третьем — один белый гриб.
- Ваш мозг (байесовский алгоритм) строит мысленную карту леса: «Там, где сыро и ёлки (одни параметры), грибов нет. Там, где березы (другие параметры), — есть шанс».
- Вы решаете, куда идти дальше, основываясь на этой мысленной карте.
Баланс между Exploration и Exploitation
При поиске алгоритм всегда решает дилемму:
- Exploitation (Использование): пойти искать грибы вокруг того места, где мы уже нашли один белый гриб (искать оптимум рядом с известными хорошими параметрами).
- Exploration (Исследование): пойти в неизведанную часть леса, где мы еще не были. Вдруг там целая поляна огромных грибов?
Байесовская оптимизация математически балансирует эти два подхода.
Как работает байесовская оптимизация
- Суррогатная модель (Surrogate Model). Обучать тяжелую нейросеть или бустинг — долго. Поэтому алгоритм строит «легкую» математическую модель (часто это гауссовские процессы — Gaussian Processes, или деревья TPE), которая пытается предсказать качество тяжелой модели в зависимости от гиперпараметров. Суррогатная модель работает доли секунды.
- Функция приобретения (Acquisition Function). Это математическая формула, которая смотрит на предсказания суррогатной модели и решает, какую точку проверить следующей. Популярные функции:
- EI (Expected Improvement). Ожидаемое улучшение по сравнению с текущим лучшим результатом.
- UCB (Upper Confidence Bound). Выбирает точки, где суррогатная модель обещает высокий результат или где она сильно сомневается (стимулирует Exploration).
Реализация в Hyperopt
Hyperopt — классическая библиотека, использующая алгоритм TPE (Tree-structured Parzen Estimator).
from hyperopt import fmin, tpe, hp, STATUS_OK, Trials
from sklearn.model_selection import cross_val_score
# 1. Задаем целевую функцию, которую будем МИНИМИЗИРОВАТЬ
def objective(params):
clf = RandomForestClassifier(
n_estimators=int(params['n_estimators']),
max_depth=int(params['max_depth']),
random_state=42
)
# Считаем accuracy
score = cross_val_score(clf, X, y, cv=5, scoring='accuracy').mean()
# Поскольку Hyperopt ищет МИНИМУМ, возвращаем отрицательное качество
return {'loss': -score, 'status': STATUS_OK}
# 2. Задаем пространство поиска (Search Space)
space = {
'n_estimators': hp.quniform('n_estimators', 50, 500, 1), # от 50 до 500 с шагом 1
'max_depth': hp.quniform('max_depth', 3, 30, 1)
}
# 3. Запускаем оптимизацию
trials = Trials() # Объект для хранения истории
best = fmin(
fn=objective,
space=space,
algo=tpe.suggest, # Используем алгоритм TPE
max_evals=20, # Количество попыток
trials=trials
)
print(f"Лучшие параметры (Hyperopt): {best}")
Реализация в Optuna (современный стандарт)
Сегодня Optuna де-факто стала стандартом в ML-индустрии и в соревнованиях Kaggle. Она удобнее, быстрее, поддерживает визуализацию из коробки и умеет останавливать безнадежные эксперименты на полпути (Pruning).
import optuna
# Отключаем лишние логи для чистоты вывода
optuna.logging.set_verbosity(optuna.logging.WARNING)
def objective(trial):
# Optuna сама предлагает значения прямо внутри функции. Это очень удобно
n_estimators = trial.suggest_int('n_estimators', 50, 500)
max_depth = trial.suggest_int('max_depth', 3, 30)
min_samples_split = trial.suggest_float('min_samples_split', 0.01, 0.1)
clf = RandomForestClassifier(
n_estimators=n_estimators,
max_depth=max_depth,
min_samples_split=min_samples_split,
random_state=42
)
score = cross_val_score(clf, X, y, cv=5, scoring='accuracy').mean()
return score # Optuna по умолчанию может максимизировать
# Создаем исследование (Study)
study = optuna.create_study(direction='maximize')
# Запускаем оптимизацию
study.optimize(objective, n_trials=20)
print(f"Лучшие параметры (Optuna): {study.best_params}")
print(f"Лучшее качество: {study.best_value:.4f}")
Как выбрать метод подбора гиперпараметров
Чтобы вам было проще выбирать, я составил сводную таблицу:
| Критерий | Grid Search | Random Search | Bayesian Optimization (Optuna) |
| Принцип работы | Полный перебор сетки | Случайные точки из распределений | Умный поиск на основе истории |
| Скорость поиска | Очень медленно | Быстро | Умеренно быстро (тратит время на вычисление суррогатной модели) |
| Качество результата | Гарантирует оптимум только в рамках сетки | Часто лучше Grid Search при том же времени | Наивысшее, находит нетривиальные комбинации |
| Сложность настройки | Элементарно | Очень просто | Требует написания функции (чуть сложнее) |
| Для скольких параметров | 1–3 гиперпараметра | 3–10 гиперпараметров | 5 и более гиперпараметров |
| Масштабируемость | Плохая (проклятие размерности) | Отличная | Отличная |
Когда какой метод применять: практические рекомендации
- У вас всего один-два параметра, и модель учится за секунду? Используйте GridSearchCV. Быстро написали, быстро получили результат, пошли пить кофе.
- Вы только начали исследовать новую модель и не знаете примерных диапазонов? Запустите RandomizedSearchCV с очень широкими диапазонами на ночь. Утром вы увидите, в каких областях лежат лучшие значения.
- Вы участвуете в соревновании, выжимаете последние сотые доли процента метрики, а модель учится долго (например, CatBoost или нейросеть)? Только Optuna (байесовская оптимизация).
Обзор Python-библиотек для подбора гиперпараметров в ML
Помимо базового scikit-learn, экосистема Python предлагает мощные инструменты для дата-сайентистов.
Scikit-learn (GridSearchCV, RandomizedSearchCV)
- Плюсы: не нужно ничего устанавливать дополнительно. Идеально интегрируется с Pipeline (можно подбирать параметры не только модели, но и методов предобработки данных одновременно, например метод заполнения пропусков + параметры бустинга).
- Минусы: нет умного поиска, нет ранней остановки (pruning).
Hyperopt
- Плюсы: проверенная временем библиотека. Поддерживает распределенные вычисления (можно запустить поиск на кластере из десяти компьютеров, используя MongoDB для синхронизации очереди задач). Мощный синтаксис пространств поиска hp.choice, hp.loguniform.
- Минусы: устаревший и довольно громоздкий синтаксис. Отладка ошибок бывает болезненной.
Optuna (мой личный фаворит)
- Плюсы:
- Потрясающий API (trial.suggest_* прямо в коде).
- Pruning (Обрезка): если Optuna видит, что после десяти эпох обучения нейросети лосс огромный по сравнению с предыдущими запусками, она прерывает обучение этой комбинации, экономя вам часы работы.
- Интеграция: есть готовые интеграторы для PyTorch, XGBoost, CatBoost, LightGBM.
- Визуализация: optuna.visualization.plot_optimization_history(study) нарисует вам красивые интерактивные графики прямо в Jupyter.
- Минусы: практически нет для большинства задач.
Другие инструменты
- scikit-optimize (skopt): хорошая библиотека для байесовской оптимизации (через гауссовские процессы), синтаксис похож на sklearn. Сейчас обновляется редко.
- Ray Tune: инструмент для распределенного подбора гиперпараметров. Если у вас кластер на сотни GPU и вы обучаете огромные deep-learning-модели, Ray Tune — ваш выбор.
- Weights & Biases (W&B) Sweeps: отличный инструмент, если вы уже используете W&B для логирования экспериментов. Позволяет управлять перебором из красивого веб-интерфейса.
Практический пример end-to-end
Давайте сведем все воедино. Решим реальную задачу классификации вина (Wine Dataset) с помощью градиентного бустинга (HistGradientBoostingClassifier — аналог LightGBM в sklearn) и сравним все три метода в равных условиях: дадим каждому алгоритму ровно 30 попыток (итераций).
import time
import pandas as pd
from sklearn.datasets import load_wine
from sklearn.model_selection import cross_val_score, RandomizedSearchCV
from sklearn.ensemble import HistGradientBoostingClassifier
import optuna
import scipy.stats as stats
# 1. Подготовка данных
X, y = load_wine(return_X_y=True)
model = HistGradientBoostingClassifier(random_state=42)
print("Начинаем соревнование алгоритмов: 30 итераций для каждого!\n" + "="*50)
# --- 1. RANDOM SEARCH ---
start_time = time.time()
param_dist = {
'learning_rate': stats.loguniform(0.001, 0.5),
'max_iter': stats.randint(50, 300),
'max_depth': stats.randint(3, 15),
'l2_regularization': stats.uniform(0.0, 5.0)
}
rs = RandomizedSearchCV(model, param_dist, n_iter=30, cv=3, scoring='accuracy', random_state=42)
rs.fit(X, y)
rs_time = time.time() - start_time
rs_best_score = rs.best_score_
print(f"Random Search | Качество: {rs_best_score:.4f} | Время: {rs_time:.2f} сек")
# --- 2. OPTUNA (BAYESIAN) ---
start_time = time.time()
optuna.logging.set_verbosity(optuna.logging.WARNING)
def objective(trial):
# Задаем те же самые диапазоны
lr = trial.suggest_float('learning_rate', 0.001, 0.5, log=True)
max_iter = trial.suggest_int('max_iter', 50, 300)
max_depth = trial.suggest_int('max_depth', 3, 15)
l2 = trial.suggest_float('l2_regularization', 0.0, 5.0)
clf = HistGradientBoostingClassifier(
learning_rate=lr, max_iter=max_iter,
max_depth=max_depth, l2_regularization=l2, random_state=42
)
return cross_val_score(clf, X, y, cv=3, scoring='accuracy').mean()
study = optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=30)
optuna_time = time.time() - start_time
optuna_best_score = study.best_value
print(f"Optuna | Качество: {optuna_best_score:.4f} | Время: {optuna_time:.2f} сек")
# --- 3. GRID SEARCH (Для справки: сделаем небольшую сетку на 36 комбинаций) ---
from sklearn.model_selection import GridSearchCV
start_time = time.time()
param_grid = {
'learning_rate': [0.01, 0.1, 0.3],
'max_iter': [100, 200],
'max_depth': [5, 10],
'l2_regularization': [0.0, 1.0, 3.0]
} # 3 * 2 * 2 * 3 = 36 комбинаций
gs = GridSearchCV(model, param_grid, cv=3, scoring='accuracy')
gs.fit(X, y)
gs_time = time.time() - start_time
gs_best_score = gs.best_score_
print(f"Grid Search | Качество: {gs_best_score:.4f} | Время: {gs_time:.2f} сек (36 итер.)")
Примерный вывод, который вы получите:

Как видите, за сопоставимое время и количество попыток Optuna смогла найти более удачную комбинацию параметров, потому что она фокусировала поиск в перспективных зонах, а не распылялась вслепую.
Гиперпараметры в Machine Learning: коротко о главном
Подбор гиперпараметров — это обязательный этап построения качественных моделей. Давайте подведем итог:
- Не используйте Grid Search, если у вас больше двух-трех параметров. Это трата электричества и вашего времени.
- Random Search — отличный базовый метод (baseline). Он легко настраивается и часто дает хороший результат за счет исследования большего числа уникальных значений важных параметров.
- Байесовская оптимизация (Optuna) — ваш лучший друг в реальных проектах. Она учится на истории, находит лучшие метрики и позволяет прерывать неудачные эксперименты.
О чем почитать дальше?
Индустрия не стоит на месте. Сейчас активно развиваются два направления, которые пытаются автоматизировать вообще все:
- AutoML (Automated Machine Learning). Фреймворки вроде LightAutoML, H2O или AutoGluon. Они не просто подбирают гиперпараметры, но и сами генерят новые фичи, выбирают тип модели (сравнивая нейросети с бустингами) и строят ансамбли. Вы просто даете им файл .csv, а на выходе получаете готовую модель.
- NAS (Neural Architecture Search). В глубоком обучении (Deep Learning) подбор количества слоев, типов активаций и связей — это адский труд. NAS — это алгоритмы (часто основанные на обучении с подкреплением), которые сами проектируют архитектуру нейросети под вашу задачу. Знаменитая сеть EfficientNet была создана именно с помощью NAS.
Надеюсь, эта статья помогла вам разложить все по полочкам. Пробуйте внедрять Optuna в свои проекты, экспериментируйте с распределениями, и пусть ваши модели никогда не переобучаются!