

Распознавание изображений — область практически бесконечного применения. Его используют и небольшие стоковые сервисы, и крупные соцсети, чтобы сортировать крупные объемы графических данных и фильтровать пользовательский контент. В этом материале мы расскажем, как своими руками сделать бот в Telegram, который сможет распознавать изображения, используя нейронные сети.
Зачем это нужно?
Автоматизация помогает пользователям найти изображение по теме и экономит их время: у стока Unsplash есть функция поиска, которая находит картинки по ключевому слову.
Системы распознавания нужны владельцам системы, чтобы, например, фильтровать контент, на котором присутствуют обнаженные тела. Варианты приложения подобных технологий бесконечны.


Но какое решение выбрать для задачи распознавания? Есть очень много готовых решений и столько же проприетарного (которое находится в собственности правоообладателя) и open-source программного обеспечения, на базе которых можно создать свое собственное решение.
Есть много провайдеров, которые предоставляют услуги по распознаванию изображений и видео с помощью API: Google Vision, Amazon Rekognition, Clarifai. Но если для вас важен вопрос прав на владение данными и конфиденциальности, то лучше будет создать собственный инструмент для распознавания изображений на базе существующих технологий. Стоит отдельно упомянуть ряд open-source решений: TensorFlow, Darknet, MLpack и Keras, которые позволят лучше контролировать то, что происходит с вашими изображениями.
Сначала мы сосредоточимся на создании нашего собственного классификатора изображений, используя Darknet. Затем мы напишем на Python бот для Telegram и разместим его на платформу для разработчиков Glitch для взаимодействия с классификатором.
Внешне процесс будет выглядеть следующим образом: пользователь выбирает изображение и отправляет его боту в Telegram. Бот классифицирует и распознает объекты на изображении, а потом отправляет пользователю результат.

Шаги
1. Строим скелет бота
Используйте пошаговую инструкцию из этого поста. Выполните первые два шага и измените имя приложения по своему вкусу. Не зацикливайтесь на дескрипторах бота, позже мы добавим нужный нам дескриптор для обработки полученных изображений.
2. Подключаем Darknet
Для того, чтобы проанализировать изображения, отправленные боту, нам нужно подключить Darknet. Все команды установки доступны в файле install.sh в проекте на Glitch.
Для ввода команд выберите в нашем проекте на Glitch Tools > Full Page Console.
Выберите Full Page Console, чтобы установить Darknet
Чтобы установить Darknet, перейдите в папку .data в Glitch. Это важно, потому что эта папка будет сохранена, когда Glitch перейдет в спящий режим.
cd .data
git clone https://github.com/pjreddie/darknet.git
cd darknet
make
Важно: Несмотря на то что вы можете обучать свои собственные модели (и должны, в зависимости от того, как вы планируете их использовать), обычно это довольно дорогой вычислительный процесс. Учитывая, что мы будем запускать нашего бота с помощью Glitch с очень ограниченными мощностью и местом (1 CPU, 512 RAM, 200 MB памяти), обучить модель будет совершенно невозможно.
В нашем случае лучшим решением будет использовать предварительно обученную модель. Мы будем задействовать существующие веса, это позволит нам справиться быстрее. Мы загрузим два файла весов: darknet19.weights для классификации изображений и yolov3-tiny.weights для распознавания объектов.
# execute in the ./darkent directory
wget https://pjreddie.com/media/files/darknet19.weights
wget https://pjreddie.com/media/files/yolov3-tiny.weights
Важно: мы выбрали небольшие веса из-за ограничений памяти и мощности процессора, которые доступны в Glitch на данный момент. Вы можете использовать и другие веса (подробнее об этом можно узнать в разделах сайта Darknet о классификации изображений и обнаружении объектов), если вы работаете в среде с большими мощностями. Тогда полученный результат будет еще лучше.
3. Подключаем бот
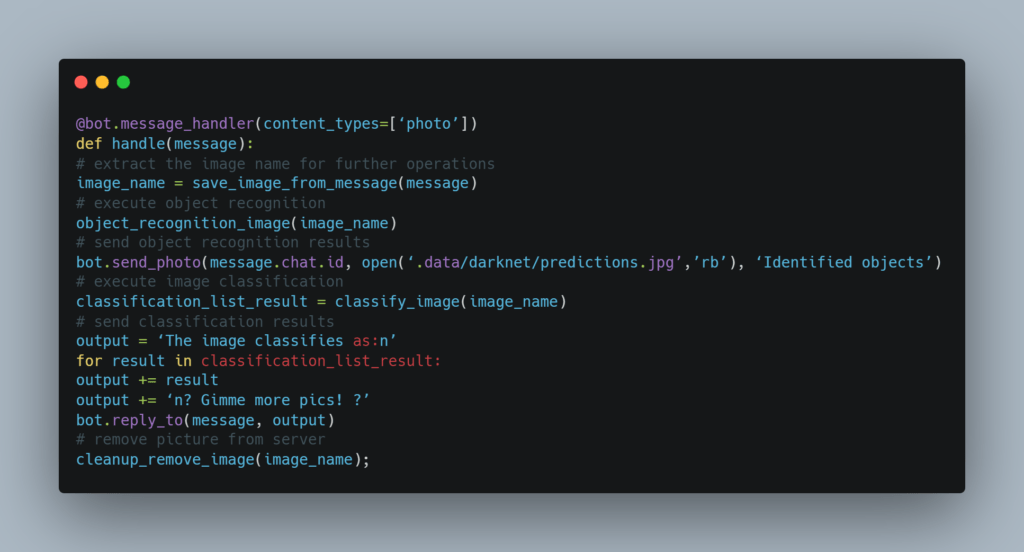
Отлично, скелет нашего бота готов, Darknet установлен, время подключить наш бот. Я не буду пояснять здесь каждую строчку кода ниже, весь код с подробными комментариями вы можете найти в моем проекте на Glitch.
Ниже приведен фрагмент кода основного дескриптора (обратите внимание, что он использует вспомогательные функции). Он срабатывает каждый раз, когда новая картинка отправляется в бот.
Выводы
Использование готовых API для распознавания изображений дает невероятные возможности, но когда конфиденциальность или возможность офлайн обработки имеют решающее значение, создание собственной системы распознавания может быть отличной альтернативой.
Обратите внимание, что наш пример показал только небольшую долю функционала и продуктивности, которых возможно достичь с помощью других тренировочных наборов и подходов.
Ресурсы
- Проект бота на Glitch → https://glitch.com/~telegram-image-classfication-bot
- Документация по Darknet → https://pjreddie.com/darknet/