


Машинное обучение помогает бизнесу ориентироваться в больших массивах хаотичных данных, проводить аналитику и находить ответы на вопросы. Например, за короткое время ML-алгоритм может обработать большое количество отзывов о продукте или постов в соцсетях, провести аналитику и найти точки роста для разработки.
С похожим запросом пришла к студентам программы «Прикладной анализ данных и машинное обучение» от Skillfactory и МИФИ компания «Норси-Транс». Рассказываем, как команда студентов обучила нейросеть.
С каким запросом пришли партнеры
Компания «Норси-Транс» разрабатывает и производит серверное оборудование, продукты для информационной безопасности, мониторинга сети, аналитических комплексов и платформ бизнес-аналитики.

На хакатон они принесли задачу: создать оригинальную систему семантического (смыслового) поиска, которая сможет понимать смысл вопросов, находить релевантные ответы в базе текстов.

Хакатон длился один месяц, в нем приняло участие 12 команд. Победителем стала одна команда «БИДВА», для которой этот опыт участия в хакатоне был первым. Команда состояла из пяти человек: тимлид со специализацией Backend-разработчик, Data-инженер, web-разработчик и два аналитика данных.
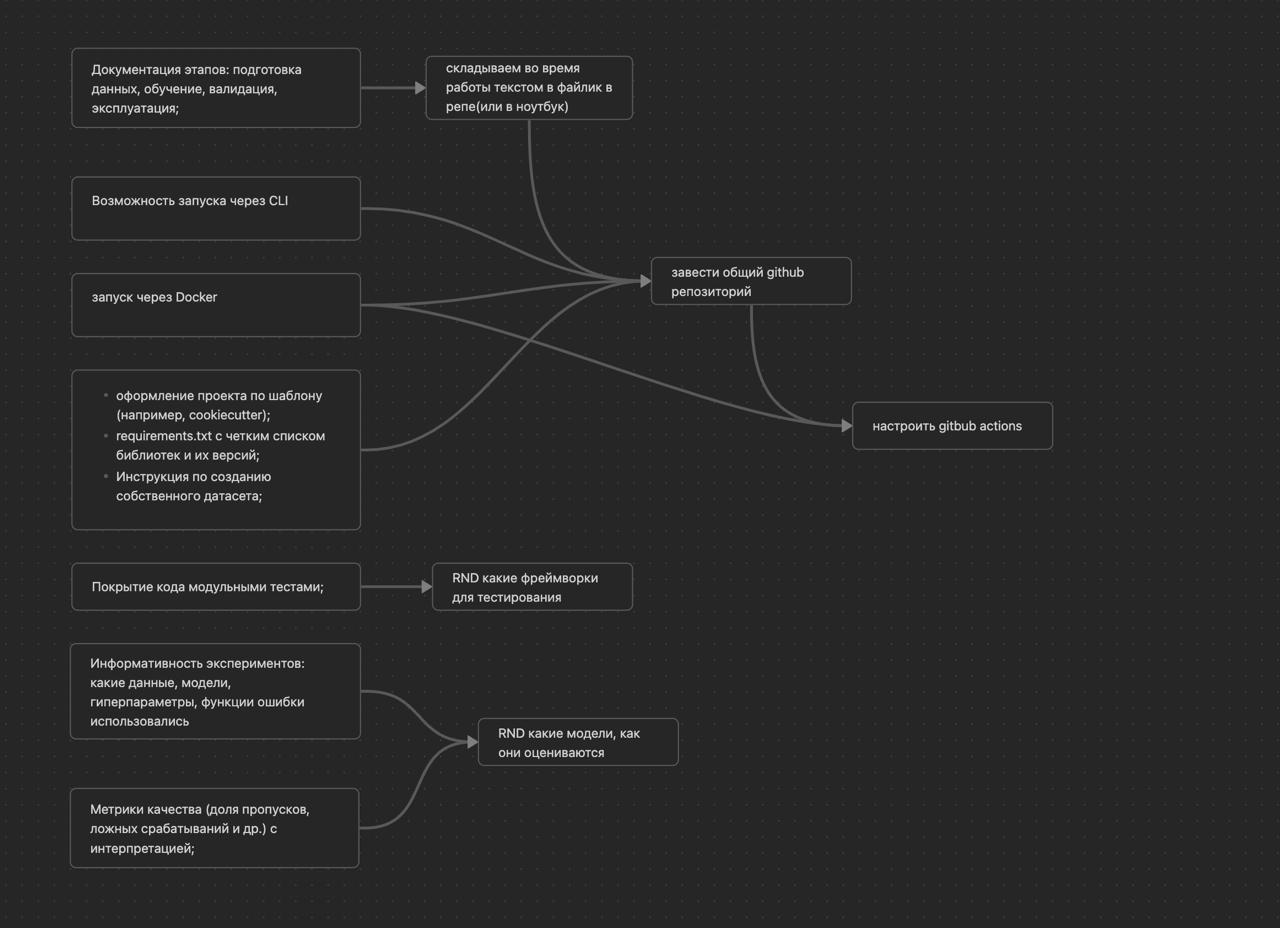
До хакатона никто из членов команды не занимался созданием моделей, способных понимать смысл текста, интерпретировать его и выдавать результаты. Участие усложнялось тем, что иногда приходилось изучать матчасть буквально «в моменте», искать специфическую информацию на Хабре.

Обучали нейронную сеть от большого к малому
Условно создание проекта разделили на три этапа:
- Анализ инструментов. На этом этапе команда начала поиск и внедрение рабочей ML-модели для смыслового сравнения текстов.
- Запуск. Подготовка инфраструктуры для локального запуска.
- Взаимодействие. Создание веб-интерфейса для взаимодействия с пользователем.
«БИДВА» предложили решение на основе предварительно обученной модели BERT. Она уже широко известна среди ML-разработчиков за счет высокого качества обработки естественного языка.
Команда не создавала новую нейросетевую модель, а выбрала несколько существующих для тестирования. Каждая из них давала разные результаты, и нужно было найти наиболее подходящую. Студенты вручную создали отдельный датафрейм (таблицу данных) с правильными и неправильными ответами, чтобы протестировать модели BERT. Это заняло много времени, но вручную созданный датафрейм позволил выбрать лучшую модель для эффективного решения.

Работа модели строилась по принципу разделения от целого текста к комбинациям словосочетаний. Вначале модель дробила текст на отдельные фрагменты. Затем шел процесс преобразования каждого фрагмента через модель BERT в числовой массив (вектор). Искомое слово или словосочетание также трансформировалось в векторное представление.
После получения массива словосочетаний из текста и искомого слова в векторном представлении выполняли сравнение по косинусному расстоянию, которое позволяло получить вероятность смыслового сходства между каждым фрагментом и нужным словом. Каждый фрагмент, преобразованный в вектор, поочередно сравнивался с вектором искомого слова.
В результате алгоритм выбирал фрагмент с большей вероятностью совпадения. Для ориентира команда выбрала вероятность в 67%. При таком проценте система выдавала наилучший результат соотношения правильных и неправильных ответов.
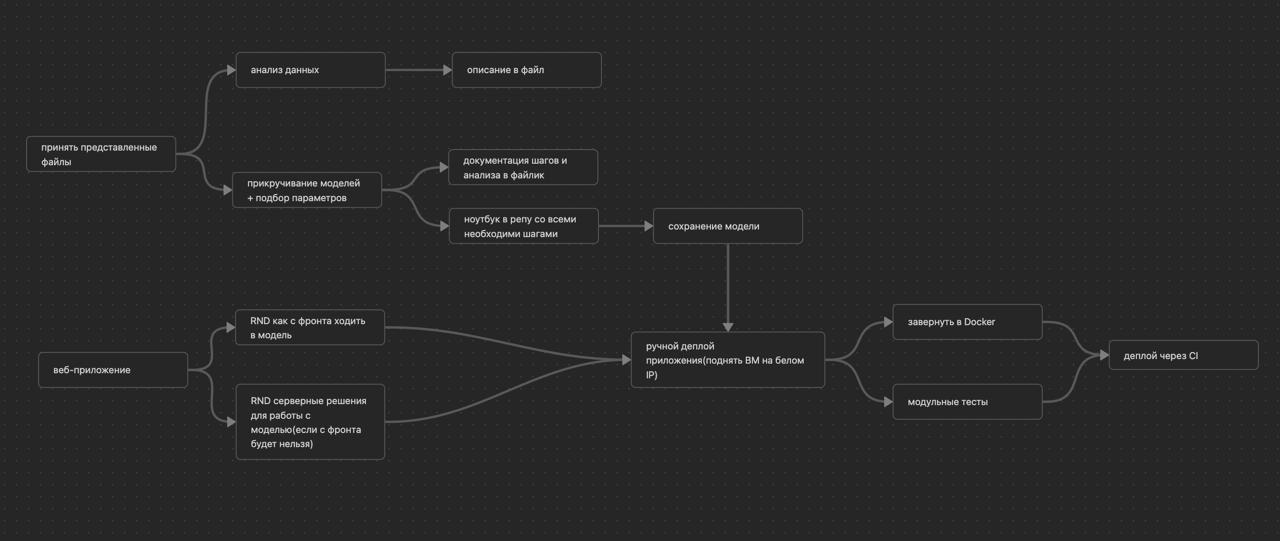
Если вероятность выше 67%, словосочетание начинали дробить, разделяя на отдельные слова. Затем слова, как и фрагменты, преобразовались в числовой массив. Далее сравнивалась вероятность смыслового сходства фрагмента и отдельных слов, из которых этот фрагмент состоит. После чего выбирается наилучшая вероятность. Так получалось находить не только словосочетания, похожие по смыслу, но и отдельные слова в тексте.
Если вероятность была меньше 67%, алгоритм решал, что совпадение не найдено.
Что получилось на выходе
После выбора и настройки модели команда создала инфраструктуры для локального запуска решения. Для разработки пользовательского интерфейса в виде веб-страницы использовали использовали фреймворк React.js с применением TypeScript. Для написания серверной части взяли язык Python. В качестве веб-сервера использовали Uvicorn — максимально релевантный для Python и нужный для запуска приложений. Обработку http-запросов осуществлял фреймворк FastAPI. Сам же локальный запуск веб-страницы осуществлялся при помощи веб-сервера Vite.
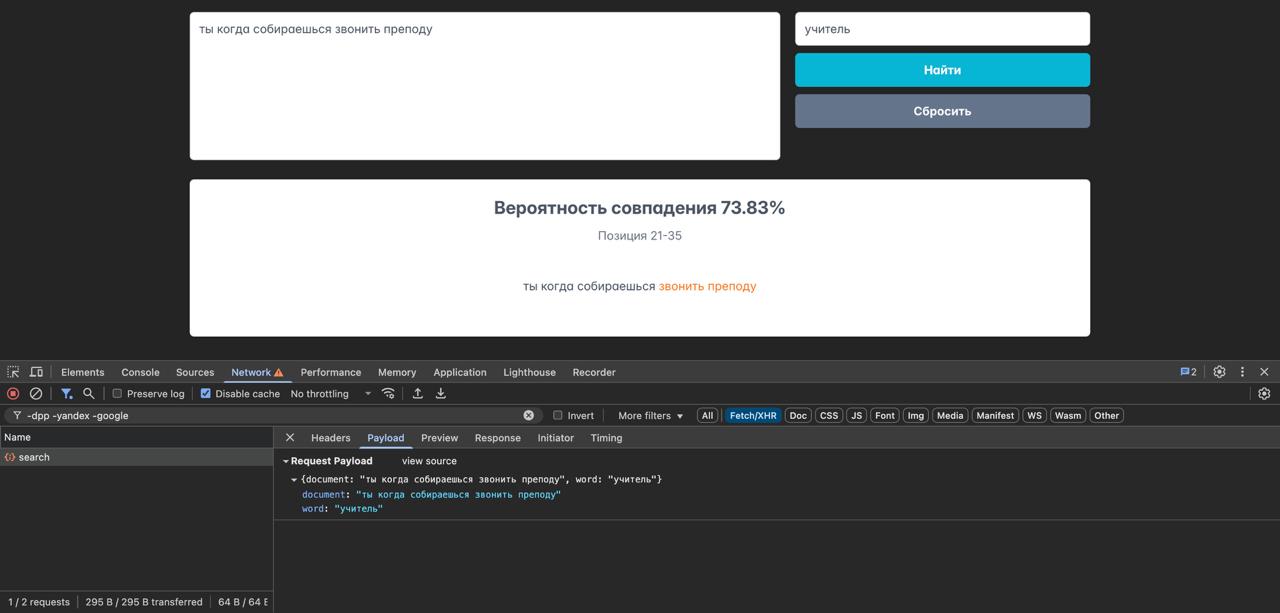
Через месяц 12 команд представили свои решения для «Норси-Транс», в результате «БИДВА» стала победителем хакатона. Нейросетевая модель от команды явно выделилась на хакатоне, и «Норси-Транс» взяли ее для дальнейшей проработки и реализации у клиентов.
Несмотря на то что до хакатона участники не знали друг друга, им удалось сработаться, наладить коммуникацию. Это сформировало ответственный подход к решению с умеренной долей педантизма.