

Реляционные базы данных структурируют информацию в виде таблиц, строк и столбцов. О том, какие бывают запросы SQL и как использовать операторы, писали в статье «Полное руководство по запросам SQL: основные команды, операторы и примеры для начинающих», а сегодня разберемся, как связывать таблицы между собой.

Зачем нужны связи между таблицами в базе данных?
Связи между таблицами помогут нам решить сразу несколько задач.
Избежать дублирования данных
Связанные данные будут распределены по разным таблицам без дублирования. Например, вместо хранения адреса клиента в каждой записи заказа можно создать отдельную таблицу «Клиенты» с адресами и связать ее с таблицей «Заказы».
Сделать данные целостными
Информация в базе данных будет корректна и согласована между собой.
Например, если клиент отсутствует в таблице «Клиенты», он не сможет сделать заказ.
Оптимизировать запросы
Можно будет создавать сложные запросы для выборки данных, объединяя информацию из нескольких таблиц. Например, если связать таблицы «Клиенты» и «Заказы», можно с помощью одного запроса получить список всех клиентов вместе с заказанными ими товарами.
Повысить производительность
Разделение больших объемов данных на связанные таблицы ускорит поиск и управление информацией. Например, вместо хранения всех данных о клиентах и их заказах в одной огромной таблице данные можно разделить на отдельные связанные таблицы «Клиенты» и «Заказы». Запросы будут выполняться быстрее за счет меньшего объема данных в каждой таблице.
Что такое ключи (keys)
Перед тем как мы рассмотрим типы связей между таблицами, познакомимся с понятием ключей (keys).
Ключ (key) — это значение, которое позволяет идентифицировать уникальные записи в таблице или установить связь между различными таблицами. Существует несколько типов ключей.
Первичный ключ (Primary Key)
Связывает какую-либо запись в таблице с уникальным значением. Он обеспечивает целостность данных и гарантирует, что каждая запись в таблице уникальна.
Особенности:
Может быть только один такой ключ. Каждое значение первичного ключа должно быть уникальным в пределах таблицы. Это значит, что не может существовать две записи с одинаковым значением первичного ключа.
Не NULL. Значение первичного ключа не может быть NULL (пустым). Каждая запись должна иметь уникальный идентификатор.
Индекс обычно кластеризован (сгруппирован) по умолчанию. Это означает, что данные в таблице упорядочены в соответствии с первичным ключом, что ускоряет доступ к данным при выполнении запросов.
Пример:
Таблица Students, где в качестве первичного ключа — значения в столбце StudentID.

Создание таблицы с ключом в MySQL:
CREATE TABLE Students ( StudentID INT PRIMARY KEY, Name VARCHAR(50), ... );
Зная первичный ключ студента, мы сможем получить доступ к остальной информации о нем.
SELECT * FROM Students WHERE StudentID = 1;
Этот запрос вернет всю информацию о студенте с StudentID = 1.
Составной ключ (Composite Key)
Является разновидностью первичного ключа и состоит из двух или более столбцов, значения которых в комбинации обеспечивают уникальность записи.
Особенности:
Может быть несколько таких ключей. И комбинации, из которых они состоят, должны быть уникальными.
Состоит из значений нескольких столбцов. Уникальность записи обеспечивается комбинацией значений этих столбцов.
Не NULL. Значение каждого столбца в составном ключе не может быть NULL.
Кластеризованный индекс (по умолчанию в большинстве СУБД). Также зачастую имеет кластеризованный индекс: данные в таблице располагаются по порядку в соответствии с комбинацией значений столбцов составного ключа.
Пример:
Таблица Enrollments (в данном случае означает «зачисление студента на курс»), где в качестве составного первичного ключа используются комбинации значений в столбцах StudentID и CourseID.

Создание таблицы с ключом в MySQL:
CREATE TABLE Enrollments ( StudentID INT, CourseID INT, EnrollmentDate DATE, PRIMARY KEY (StudentID, CourseID) );
Один студент может быть записан на несколько курсов, но каждая запись о зачислении уникальна.
SELECT * FROM Enrollments WHERE StudentID = 1 AND CourseID = 101;
Этот запрос вернет запись о зачислении, соответствующую студенту с StudentID = 1, на курс с CourseID = 101.
Уникальный ключ (Unique Key)
Так же, как и первичный ключ, связывает уникальное значение с определенными данными. Но есть отличия:
Может быть несколько таких ключей. Но каждый из них должен быть уникальным.
Состоит либо из значения одного столбца, либо из значений нескольких столбцов. Отдельные значения и комбинации должны быть уникальными.
Может содержать NULL. Уникальные ключи могут содержать пустое значение.
Индекс не кластеризован по умолчанию. Строки могут храниться в таблице в произвольном порядке, а не в порядке значений ключа.
Пример:
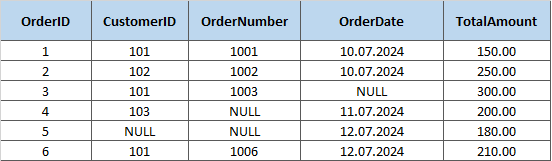
Таблица Orders в базе данных интернет-магазина, в которой есть один первичный ключ OrderID и два уникальных ключа в виде комбинаций — (OrderNumber, OrderDate) и (CustomerID, TotalAmount).
Создание таблицы с ключом в MySQL:
CREATE TABLE Students ( StudentID INT, UNIQUE KEY (StudentID), Name VARCHAR(50), ... );
Например, если нам известно, что CustomerID равен 101 и сумма равна 150,00, то мы сможем найти соответствующий заказ.
SELECT * FROM Orders WHERE CustomerID = 101 AND TotalAmount = 150.00;
Этот запрос найдет запись из таблицы Orders, соответствующую заданному ключу.
Внешний ключ (Foreign Key)
Связывает записи в одной таблице с записями в другой через общее поле, которое является первичным ключом в другой таблице.
Особенности:
Может быть несколько таких ключей. В одной таблице может быть несколько внешних ключей, связывающих ее с другими таблицами.
Может содержать NULL-значения, но только если это разрешено правилами целостности данных.
Обычно не кластеризуется. Как правило, не определяет порядок хранения данных в таблице.
Пример:
Таблица Customers содержит информацию о клиентах. Таблица Orders содержит информацию о заказах. Поле CustomerID в таблице Orders является внешним ключом, который ссылается на первичный ключ CustomerID в таблице Customers.
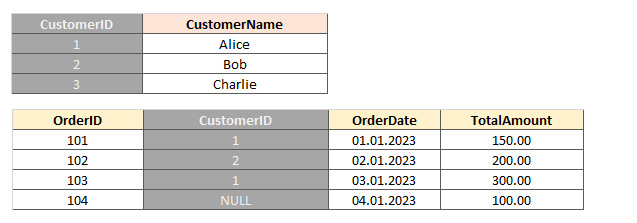
Создание таблицы с ключом в MySQL:
CREATE TABLE Orders ( OrderID INT PRIMARY KEY, CustomerID INT, OrderDate DATE, TotalAmount DECIMAL(10, 2), FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID) );
Поиск по внешнему ключу будет выглядеть так:
SELECT * FROM Orders WHERE CustomerID = 1;
Здесь мы ищем покупателя по CustomerID = 1.
Немного о правилах целостности
В 1970 году математик и информатик Эдгар Ф. Кодд разработал правила целостности для реляционных баз данных. Они обеспечивают корректность и согласованность данных.
Целостность сущности (Entity Integrity)
Нужно, чтобы каждая таблица имела первичный ключ и ни одно из значений первичного ключа не могло быть NULL. Каждая запись в таблице должна быть уникальна.
Ссылочная целостность (Referential Integrity)
Каждое значение внешнего ключа в одной таблице должно соответствовать существующему значению первичного ключа в другой таблице.
Целостность домена (Domain Integrity)
Должны быть определены допустимые значения для данных в столбце, основываясь на типе данных, логических ограничениях и правилах.
Пользовательские ограничения целостности (User-Defined Integrity)
Пользователи могут создавать специфические правила для работы. Например, ввести ограничение на максимальную сумму заказа в таблице Orders.
Какие бывают типы связей между таблицами
Один-к-одному (One-to-One)
Отношение «Один-к-одному» в реляционных базах данных описывает связь между двумя таблицами, где каждая запись в одной таблице имеет только одну соответствующую запись в другой таблице.
Применение
Применяется для разделения данных с целью повышения безопасности и производительности, а также для организации данных по логическим группам и избегания дублирования. Например, личная информация пользователя может храниться в отдельной таблице для ограничения доступа.
Как создать связь «Один-к-одному»
Для установки связи «Один-к-одному» между таблицами используют первичные и внешние ключи.
- Определяем первичный ключ. В одной из таблиц устанавливаем первичный ключ, который идентифицирует соответствующую запись.
- Создаем внешний ключ. В другой таблице создаем внешний ключ, который ссылается на первичный ключ первой таблицы. Это обеспечивает связь между двумя таблицами.
Пример:
Рассмотрим пример связи «Один-к-одному» для таблиц Employee и EmployeeDetails.
Визуализация связи между БД:
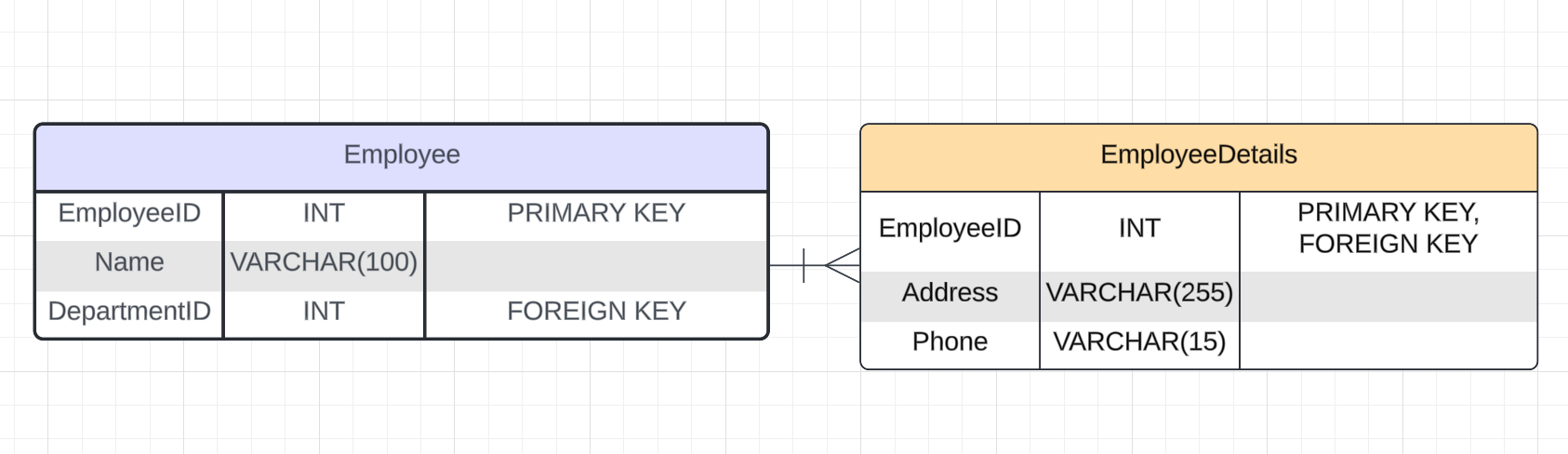
Код в MySQL:
— Таблица Employee (Родительская таблица)
CREATE TABLE Employee ( EmployeeID INT PRIMARY KEY, Name VARCHAR(100), DepartmentID INT, CONSTRAINT FK_Employee_Department FOREIGN KEY (DepartmentID) REFERENCES Department(DepartmentID) );
— Таблица EmployeeDetails (Дочерняя таблица)
CREATE TABLE EmployeeDetails ( EmployeeID INT PRIMARY KEY, Address VARCHAR(255), Phone VARCHAR(15), CONSTRAINT FK_EmployeeDetails_Employee FOREIGN KEY (EmployeeID) REFERENCES Employee(EmployeeID) );
В этом примере таблица EmployeeDetails имеет первичный ключ EmployeeID, который также является внешним ключом в таблице Employee и устанавливает связь «Один-к-одному» между сотрудниками и их личной информацией.
Особенности
- Можно создавать связь «Один-к-одному» внутри одной таблицы.
- Как писали ранее, внешний ключ может содержать NULL-значения, если это не нарушит правила целостности.
Один-ко-многим (One-to-Many)
Применятся, когда каждый элемент одной сущности может иметь отношение с несколькими элементами другой сущности, но каждый элемент второй сущности может иметь отношение только с одним элементом первой сущности.
Применение
Используется для моделирования иерархий и зависимостей в данных. Например, каждый клиент может иметь несколько заказов, но каждый заказ относится только к одному клиенту. Либо один отдел может иметь множество сотрудников, но каждый сотрудник принадлежит только одному отделу.
Как создать связь «Один-ко-многим»
Для установки связи «Один-ко-многим» между таблицами также используются первичные и внешние ключи.
- Определяем первичный ключ в родительской таблице, который идентифицирует каждую запись.
- Создаем внешний ключ в дочерней таблице, который ссылается на первичный ключ родительской таблицы. Это позволит каждой записи в дочерней таблице ссылаться на одну запись в родительской таблице, но одна запись в родительской таблице может иметь много связанных записей в дочерней.
Пример:
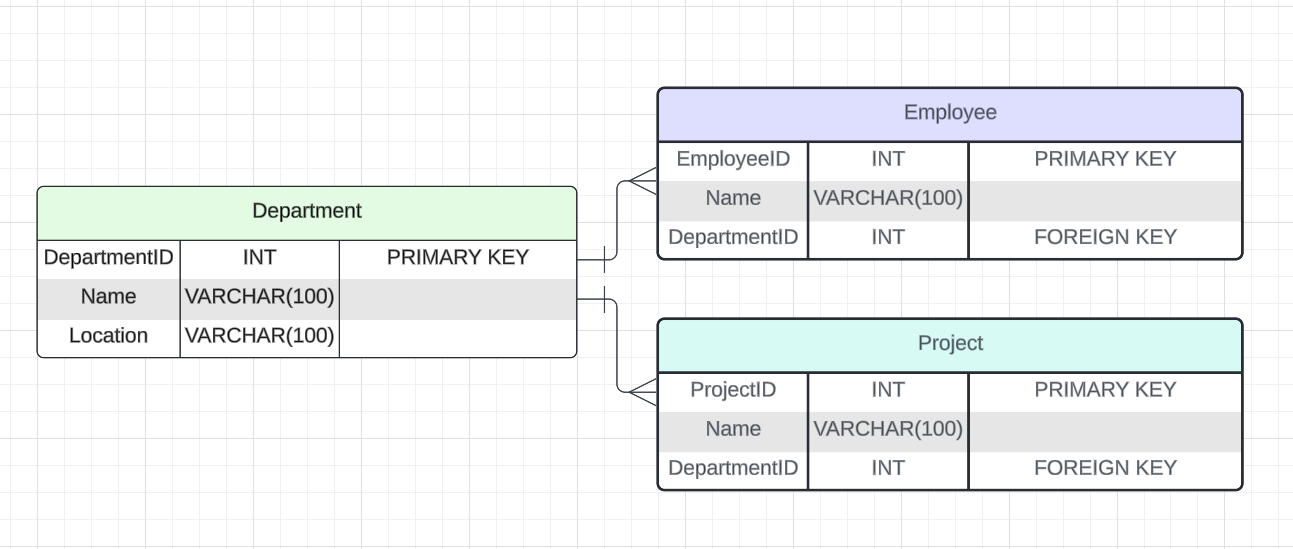
Рассмотрим пример связи «Один-ко-многим» для таблиц Department, Employee и Project. У отдела есть сотрудники и проекты.
Визуализация связи между БД:
Код в MySQL:
— Таблица Department (Родительская таблица)
CREATE TABLE Department ( DepartmentID INT PRIMARY KEY, Name VARCHAR(100), Location VARCHAR(100) );
— Таблица Employee (Дочерняя таблица)
CREATE TABLE Employee ( EmployeeID INT PRIMARY KEY, Name VARCHAR(100), DepartmentID INT, CONSTRAINT FK_Employee_Department FOREIGN KEY (DepartmentID) REFERENCES Department(DepartmentID) );
— Таблица Project (Дочерняя таблица)
CREATE TABLE Project ( ProjectID INT PRIMARY KEY, Name VARCHAR(100), DepartmentID INT, CONSTRAINT FK_Project_Department FOREIGN KEY (DepartmentID) REFERENCES Department(DepartmentID) );
Таблица Department хранит информацию о подразделениях компании, каждое из которых идентифицируется уникальным DepartmentID. Таблица Employee связана с таблицей Department через внешний ключ DepartmentID и содержит информацию о сотрудниках компании, каждый из которых имеет уникальный EmployeeID. Таблица Project также связана с таблицей Department через DepartmentID и содержит данные о проектах компании, каждый из которых идентифицируется уникальным ProjectID.

Многие-ко-многим (Many-to-Many)
Каждая запись в одной таблице может соотноситься с несколькими записями в другой таблице, и наоборот.
Применение
Используется для моделирования сложных взаимосвязей между данными. Например, обучающийся может записаться на множество курсов, а на курсе может учиться множество студентов; или каждый автор может написать несколько книг, и каждая книга может быть написана несколькими авторами.
Как создать связь «Многие-ко-многим»
Для создания связи «Многие-ко-многим» между двумя таблицами в реляционной базе данных необходимо использовать дополнительную таблицу, которая будет служить промежуточным звеном между этими двумя сущностями. В этой промежуточной таблице будут храниться пары идентификаторов (ключей) записей из обеих таблиц, устанавливая связь между ними.
- Создаем две основные таблицы. Определяем первичные ключи в них.
- Формируем промежуточную таблицу. Она будет содержать внешние ключи, ссылающиеся на первичные ключи обеих основных таблиц.
- Устанавливаем связи внешних ключей. Через ключи будут связаны промежуточная и основные таблицы.
Пример:
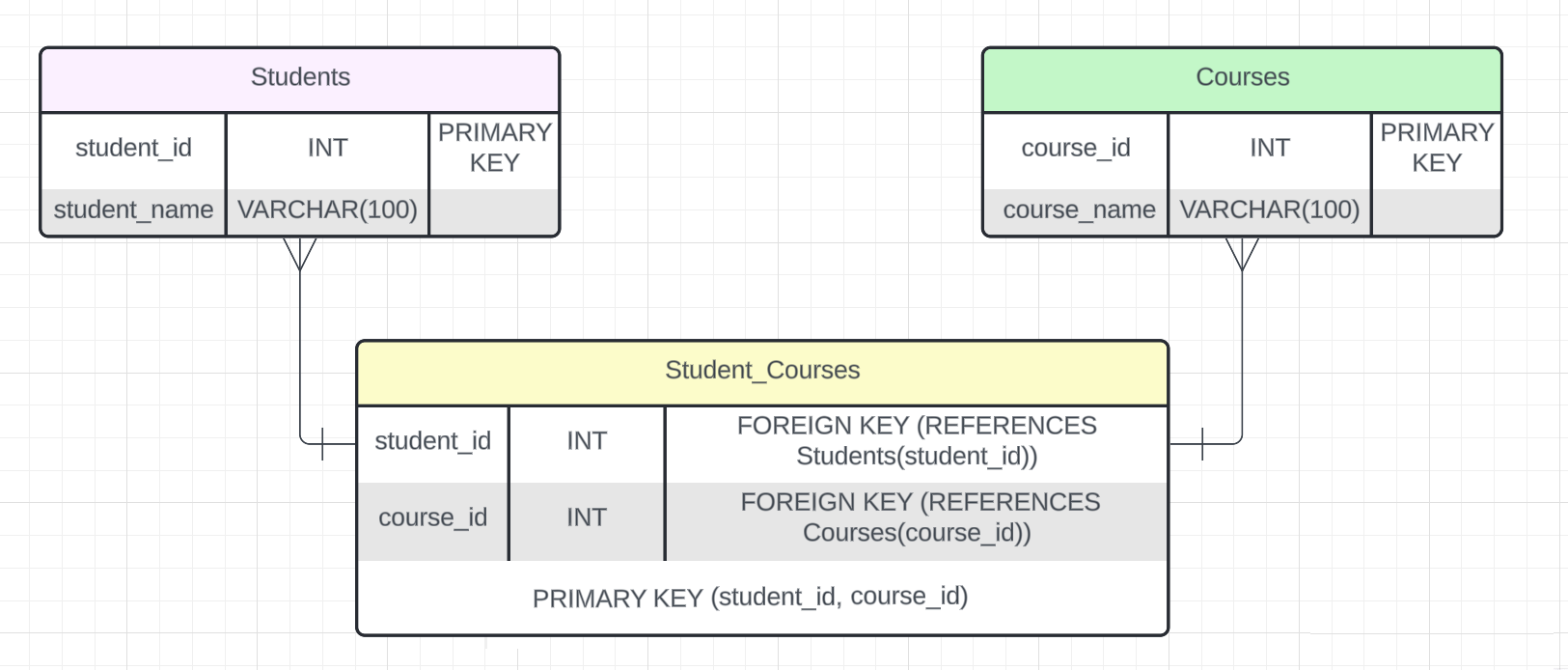
Рассмотрим пример связи «Многие-ко-многим» для таблиц Students и Courses, где каждый студент может записаться на несколько курсов и каждый курс может включать нескольких студентов.
Визуализация связи между БД:
Код в MySQL:
CREATE TABLE Students ( student_id INT AUTO_INCREMENT PRIMARY KEY, student_name VARCHAR(100) ); CREATE TABLE Courses ( course_id INT AUTO_INCREMENT PRIMARY KEY, course_name VARCHAR(100) ); CREATE TABLE Student_Courses ( student_id INT, course_id INT, FOREIGN KEY (student_id) REFERENCES Students(student_id), FOREIGN KEY (course_id) REFERENCES Courses(course_id), PRIMARY KEY (student_id, course_id) );
В этом примере таблица Students хранит информацию о студентах, каждый из которых идентифицируется уникальным student_id. Таблица Courses содержит данные о курсах с уникальным course_id. Таблица Student_Courses связывает студентов и курсы через внешние ключи student_id и course_id.
Команды JOIN для связывания таблиц
Команды JOIN в SQL используются для объединения данных из различных таблиц на основе определенных условий. Это позволяет комбинировать информацию из нескольких источников.
Разберем типы JOIN-команд и как их применять на практике.
INNER JOIN
Команда для соединения данных из разных таблиц на основе общего значения в определенном столбце или нескольких столбцах. Она позволяет получить только те строки данных, которые имеют соответствие в обеих таблицах. Так можно получить информацию, основанную на совпадении значений ключевых столбцов.
Пример:
Предположим, у нас есть две таблицы Employees и Departments.
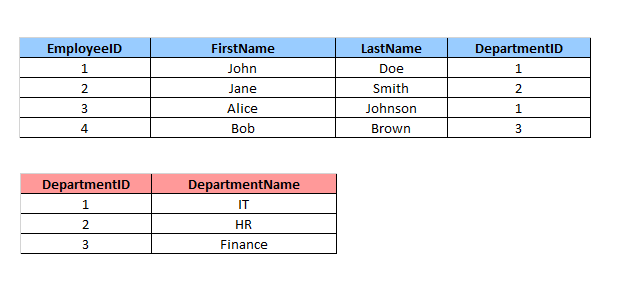
Чтобы объединить эти таблицы, используем запрос с INNER JOIN:
SELECT Employees.EmployeeID, Employees.FirstName, Employees.LastName, Departments.DepartmentName FROM Employees INNER JOIN Departments ON Employees.DepartmentID = Departments.DepartmentID;
Результат будет следующим:
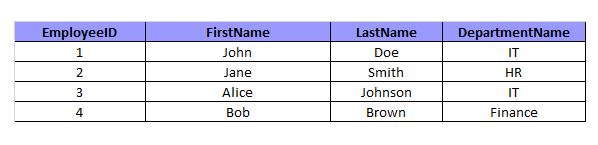
INNER JOIN объединяет данные из таблиц Employees и Departments на основе равенства значений в столбцах Employees, DepartmentID и Departments, DepartmentID. В результате мы получим новую таблицу со столбцами из обеих таблиц, где каждая строка содержит информацию о сотруднике и его отделе.
LEFT JOIN
LEFT JOIN (или LEFT OUTER JOIN) объединяет данные из двух таблиц на основе условия, которое включает все строки из левой таблицы (LEFT) и только соответствующие строки из правой таблицы (JOIN). Если в правой таблице нет соответствующих строк, то в результирующей таблице будут NULL-значения для столбцов правой таблицы.
Пример:
Допустим, мы хотим получить список всех сотрудников вместе с их отделами, используя LEFT JOIN. Возьмем таблицы Employees и Departments из предыдущего примера, но уберем из Departments отдел Finance.
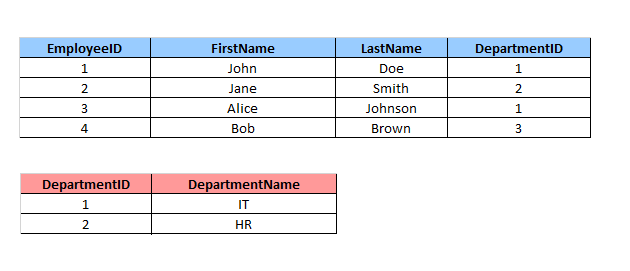
Запрос LEFT JOIN для объединения таблиц Employees и Departments будет выглядеть так:
SELECT Employees.EmployeeID, Employees.FirstName, Employees.LastName, Departments.DepartmentName FROM Employees LEFT JOIN Departments ON Employees.DepartmentID = Departments.DepartmentID;
Результат получится таким:
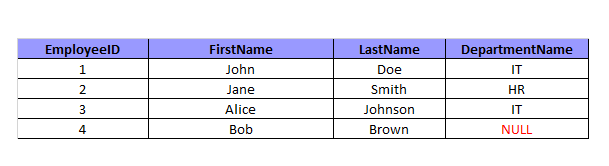
Для сотрудника с EmployeeID = 4, которому ранее соответствовал DepartmentID = 3, в столбце DepartmentName теперь содержится NULL, потому что соответствующая запись в таблице Departments отсутствует.
LEFT JOIN возвращает все строки из левой таблицы Employees, включая строки, для которых нет соответствующих записей в правой таблице Departments.
Если бы мы использовали INNER JOIN вместо LEFT JOIN, то не получили бы последнюю строку. Ведь в отличие от LEFT JOIN, INNER JOIN возвращает только строки, для которых существует соответствие в обеих таблицах по условию объединения.
RIGHT JOIN
RIGHT JOIN (или RIGHT OUTER JOIN) повторяет принцип LEFT JOIN, но в обратную сторону: он объединяет данные из двух таблиц, включая все строки из правой таблицы (RIGHT) и только соответствующие строки из левой таблицы (JOIN). Если в левой таблице нет соответствующих строк, то в результирующей таблице будут NULL-значения для столбцов левой таблицы.
Пример:
Допустим, мы хотим получить список всех отделов вместе с их сотрудниками, используя RIGHT JOIN. Пусть структура таблиц будет такой же, как в предыдущих примерах, но мы уберем четвертого сотрудника.
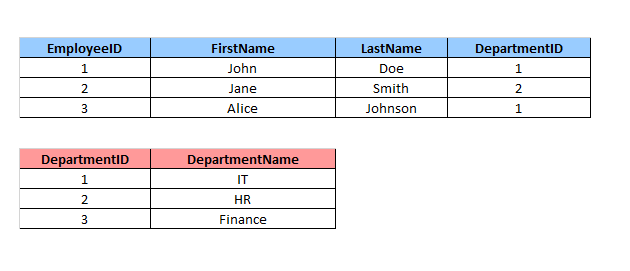
Теперь выполним SQL-запрос с RIGHT JOIN:
SELECT Employees.EmployeeID, Employees.FirstName, Employees.LastName, Departments.DepartmentName FROM Employees RIGHT JOIN Departments ON Employees.DepartmentID = Departments.DepartmentID;
Результат этого запроса будет следующим:
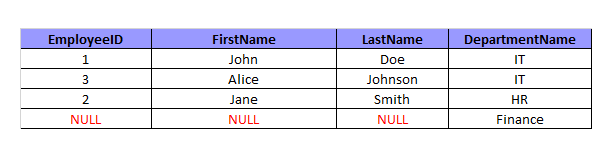
RIGHT JOIN объединяет данные из таблиц Employees и Departments на основе равенства значений в столбцах Employees, DepartmentID и Departments, DepartmentID. В результирующей таблице содержатся все строки из таблицы Departments, и для каждой строки находится соответствующая строка из таблицы Employees. Так как для DepartmentID = 3 не было сотрудника, значения соответствующих ячеек в Employees содержат NULL.
FULL OUTER JOIN
Используют для объединения данных из двух таблиц, включая все строки из обеих таблиц. Если в одной из таблиц нет соответствующих строк, то в результирующей таблице будут NULL-значения для столбцов этой таблицы.
Пример:
Допустим, мы хотим получить список всех сотрудников и всех отделов, используя FULL OUTER JOIN. Пусть структура таблиц будет такой же, как в предыдущих примерах. Но мы изменим отдел последнего в списке сотрудника на несуществующий четвертый отдел.
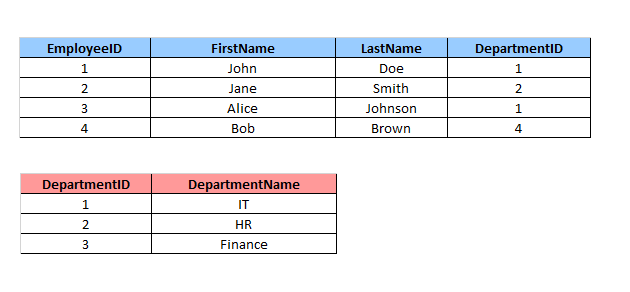
Выполним запрос с FULL OUTER JOIN:
SELECT Employees.EmployeeID, Employees.FirstName, Employees.LastName, Departments.DepartmentName FROM Employees FULL OUTER JOIN Departments ON Employees.DepartmentID = Departments.DepartmentID;
Получим такой результат:
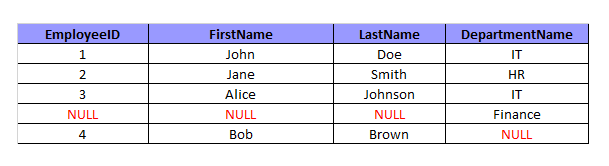
FULL OUTER JOIN объединяет данные из таблиц Employees и Departments на основе равенства значений в столбцах Employees, DepartmentID и Departments, DepartmentID. В результирующей таблице содержатся все строки из обеих таблиц:
- Сотрудники с EmployeeID = 1, 2, и 3 имеют соответствующие отделы, поэтому данные из обеих таблиц объединяются.
- Отдел с DepartmentID = 3 (Finance) не имеет соответствующих сотрудников, поэтому для этой строки столбцы из таблицы Employees содержат NULL.
- Сотрудник с EmployeeID = 4 (Bob Brown) не имеет соответствующего отдела, поэтому для этой строки столбец DepartmentName содержит NULL.
Агрегатные функции и группировка
Команды JOIN можно использовать с агрегатными функциями (например, COUNT, SUM, AVG) и группировкой (GROUP BY), чтобы не просто объединять данные из нескольких таблиц, но и выполнять над ними такие операции, как подсчет суммы значений, определение максимума и минимума для каждой группы данных и т.д.
Подведем итоги
- SQL позволяет связывать таблицы с помощью ключевых полей, которые соединяют записи одной таблицы с записями другой.
- Связи обеспечивают эффективное хранение и организацию данных, позволяют избежать дублирования информации, поддерживают целостность данных.
- Ключи — это поля в таблицах, используемые для уникальной идентификации записей.
- Основные типы ключей: первичные, составные, уникальные и внешние.
- Принцип «Один-к-одному» (One-to-One): каждая запись в одной таблице соответствует одной записи в другой таблице.
- Принцип «Один-ко-многим» (One-to-Many): каждая запись в одной таблице может иметь несколько соответствующих записей в другой таблице.
- Принцип «Многие-ко-многим» (Many-to-Many): множество записей в одной таблице может соответствовать множеству записей в другой таблице через промежуточную таблицу.
- INNER JOIN возвращает только строки, которые имеют соответствие в обеих таблицах. Используйте его, когда вам нужны только совпадающие записи.
- LEFT JOIN (LEFT OUTER JOIN) возвращает все строки из левой таблицы и соответствующие строки из правой таблицы. Если нет совпадения, результат содержит NULL для столбцов правой таблицы. Это полезно, когда вы хотите сохранить все строки из левой таблицы.
- RIGHT JOIN (RIGHT OUTER JOIN) возвращает все строки из правой таблицы и соответствующие строки из левой таблицы. Если нет совпадения, результат содержит NULL для столбцов левой таблицы. Используйте его, когда вам нужны все строки из правой таблицы.
- FULL OUTER JOIN возвращает все строки, где есть совпадение хотя бы в одной из таблиц. Если нет совпадения, результат содержит NULL для столбцов отсутствующей таблицы. Это позволяет получить полное представление о данных из обеих таблиц.
