

Обучение с подкреплением помогает системам корректировать свое поведение после каждого действия и становиться умнее. Так беспилотные автомобили учатся избегать столкновений, а игровые алгоритмы создают стратегии для победы. Разобрались, как устроено обучение с подкреплением, а еще спросили руководителя по обучению нейросети GigaChat Викторию Байкову, чем хорош этот метод и где его активно используют.
Что такое обучение с подкреплением
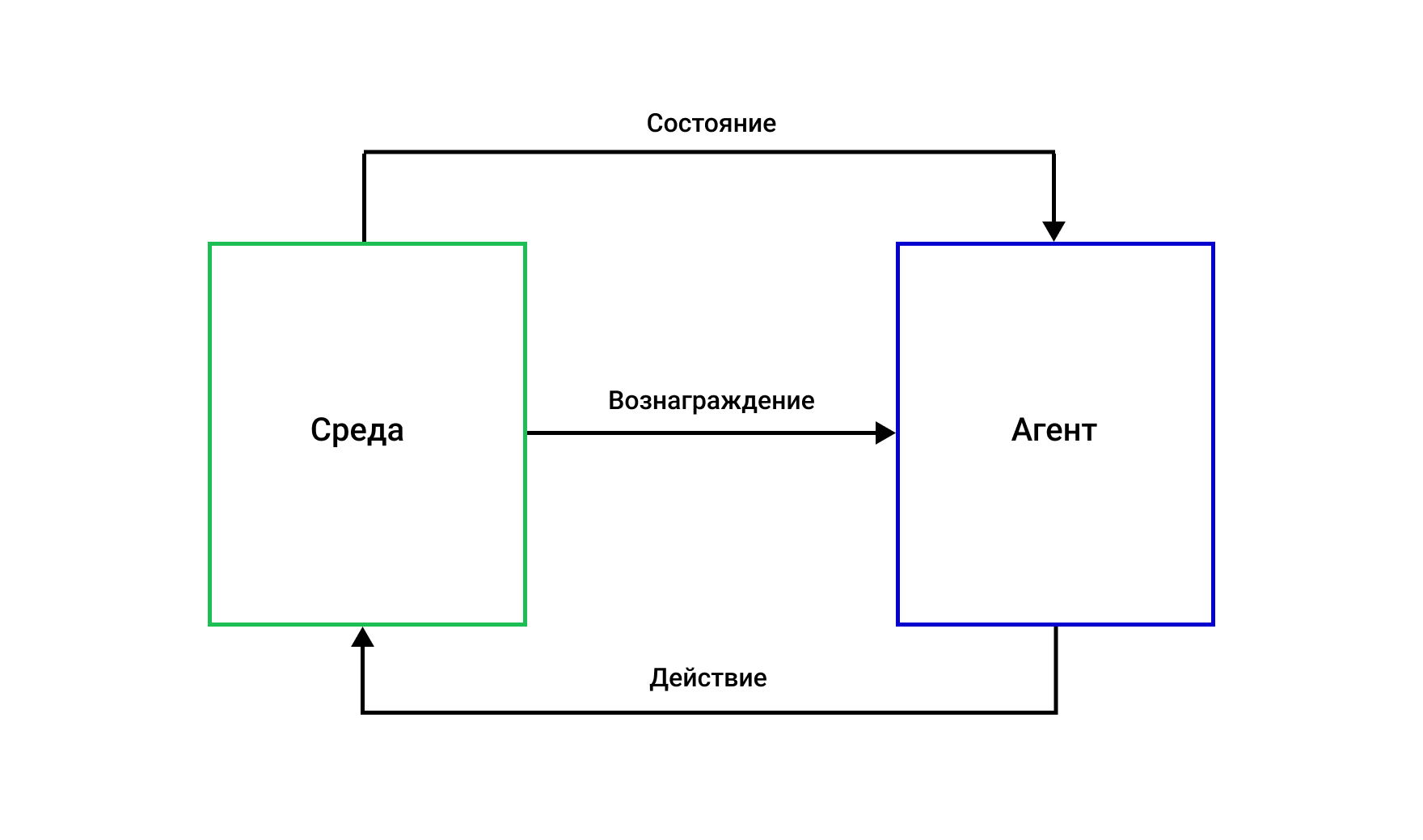
Обучение с подкреплением, или Reinforcement Learning (RL) — это метод машинного обучения, который учит программу взаимодействовать со средой, чтобы получить более высокую награду. Процесс состоит из нескольких компонентов:
- агент — программа машинного обучения или автономная система;
- среда — окружающий мир или виртуальное пространство, в котором агент принимает решение;
- действие — действие, которое агент совершает в среде, чтобы повлиять на ее состояние;
- состояние — конфигурация элементов внутри среды;
- вознаграждение — это положительная, отрицательная или нейтральная оценка за выполненное действие (то есть награда или наказание);
- совокупное вознаграждение — сумма всех наград, которые агент получает за серию действий в определенной задаче.

Разберем на примере: робот учится играть в видеоигру, в которой нужно собирать монеты и избегать врагов. Робот — это агент RL, а пространство игры — среда обучения. За каждую собранную монету он получает очки — награду, а если наткнется на врага, то теряет очки — это наказание. Сначала робот делает много ошибок, но постепенно понимает, какие действия приносят больше очков, и запоминает правильную стратегию.
Как возник и развивался метод
Основы метода лежат в поведенческой психологии, где идеи поощрения и наказания изучались на примере животных. Эти принципы позже были перенесены в информатику: в 1950-х годах психологи и инженеры начали разрабатывать первые математические модели, описывающие поведение при обучении.
В 1989 году обучение с подкреплением получило развитие благодаря работам исследователей искусственного интеллекта Кристофера Уоткинса и Питера Дэйана, которые представили концепцию Q-обучения (Q-learning). Это один из базовых методов RL.
С началом эпохи deep learning обучение с подкреплением вышло на новый уровень. В 2013 году компания DeepMind представила алгоритм Deep Q-Network, который доказал, что RL-агент может превосходить человека в играх Atari. С тех пор методы обучения с подкреплением начали развивать и использовать для решения сложных задач, например автономного вождения.
Как устроено машинное обучение с подкреплением
RL напоминает человеческое обучение, потому что оно также основано на методе проб и ошибок и системе вознаграждения. Представьте, как ребенок учится ходить. Каждый раз, когда он делает шаг и не падает, получает похвалу от родителей. Если ребенок упадет, становится больно, и он учится избегать таких действий в будущем. Спустя множество повторений ребенок запоминает правильные движения и начинает ходить уверенно и стабильно. RL работает аналогичным образом, но с использованием алгоритмов и вычислительных методов.
Что лежит в основе метода
Технически обучение с подкреплением основано на трех принципах:
- Марковский процесс принятия решений (MDP) — формальная структура для описания задач обучения. Она помогает понять, как агент должен действовать, чтобы достичь своей цели. MDP включает описание всех возможных ситуаций, в которых может оказаться агент, все возможные действия, которые он может предпринять, и то, как они влияют на ситуацию. Также MDP описывает, какие награды получает агент за свои действия и насколько важны будущие награды по сравнению с текущими.
- Политика — стратегия, которую агент использует для выбора действий в каждом состоянии. Она может быть простой — случайный выбор действий — или сложной, например, при использовании нейросети, обученной выбирать лучшие действия.
- Функция ценности — помогает агенту понять, какие состояния или действия ведут к лучшим результатам в будущем. С помощью политики и функции ценности агент учится на своем опыте и принимает решения, которые максимизируют награду.
Как выглядит обучение по методу RL
- Агент наблюдает текущее состояние среды.
- Затем он выбирает действие исходя из своей политики.
- После выполнения действия агент получает награду и переходит в новое состояние.
- На основе обратной связи он обновляет свои оценки и улучшает политику. Например, если действие привело к высокой награде, агент запоминает это как хорошее действие. А если к низкой — будет стараться избегать его в будущем.

Типы алгоритмов обучения с подкреплением
В машинном обучении с подкреплением существует несколько типов алгоритмов, потому что разные задачи и условия среды требуют различных подходов к обучению.
Алгоритмы на основе ценности
С их помощью агент учится выбирать действия, которые принесут наибольшую награду в долгосрочной перспективе.
Например, робот учится ходить и оценивает каждое действие в разных позах (состояниях). Он хранит таблицу ценностей для всех возможных поз и движений и обновляет их на основе того, насколько успешными были его попытки –– не упал ли он, продвинулся ли вперед.
К таким алгоритмам относятся Q-обучение и SARSA.
Алгоритмы на основе политики
Они обучают стратегию агента, определяя, какое действие следует выбирать в каждом состоянии.
В том же примере с роботом агент выбирает действия исходя из текущей позы. Он хранит вероятности для каждого движения в каждой позе и обновляет их на основе успехов и неудач. Например, если перемещение ноги вперед часто приводит к падению, робот снижает вероятность выбора этого действия.
Пример такого алгоритма: REINFORCE.
«Актор-критик» алгоритмы
Сочетает оба типа алгоритмов. Состоит из двух компонентов: «актор» предлагает агенту действия на основе политики, а «критик» оценивает, насколько то или иное действие выгодно.
К такому типу RL относятся алгоритмы Advantage Actor-Critic и Deep Deterministic Policy Gradient.
Преимущества обучения с подкреплением
Экономия на обучении. В отличие от машинного обучения с учителем (supervised learning), для оценки ответов и обучения модели методом RL не нужно привлекать экспертов. Агенты сами «дообучаются» и оценивают решения, и это сильно экономит расходы.
Простые нейронные сети. Для RL часто используют простые нейросети, которым нужны небольшие вычислительные мощности. Это экономит затраты на оборудование. А еще такие модели обучаются быстрее, потому что у них меньше параметров и слоев по сравнению с большими сетями.
Не требуется разметка данных. Разметка — это процесс добавления аннотаций или меток к данным, которые помогают сделать их более понятными для моделей. Например, если нужно обучить систему находить в предложениях имена людей, специалист отмечает, где они находятся в разных текстах. Это выглядит так: «Вася [имя] поехал в Москву». Даже если автоматизировать задачу, она занимает много времени. Но для RL-алгоритмов разметка не нужна. Агенты используют необработанные данные из среды, в которой они будут работать.
Решает задачи с отложенным вознаграждением. RL может решать задачи, в которых мы не можем сразу узнать последствие каждого действия. Например, в шахматах правильность хода можно оценить только после завершения партии. В этом случае RL-агент не анализирует каждый ход отдельно, а рассматривает всю партию как последовательность действий. Победа дает высокое вознаграждение, и модель учится выбирать ходы, которые увеличивают шансы на победу, даже если краткосрочные результаты не всегда положительны.
Адаптивные и гибкие агенты. RL-модель получает обратную связь от окружающей среды и корректирует свои действия для адаптации к новым условиям. Благодаря этому системы могут работать в динамичных средах.
Где используют обучение с подкреплением
Рекомендательные системы
В электронной коммерции и поисковых системах обучение с подкреплением используется для создания персонализированных рекомендаций. Алгоритмы RL изучают поведение пользователя, его предпочтения и историю поисков, чтобы предложить именно те товары или контент, которые будут ему интересны. Например, так работает подборка видеороликов на YouTube.
Роботы
RL обучает роботов навигации в сложных и динамичных средах. Агенты получают обратную связь из окружающей среды и корректируют свои действия для выполнения задач. Так роботы-пылесосы учатся передвигаться по квартире и обходить препятствия. А промышленные роботы — контролировать перемещение множества деталей по линиям и сборку изделий.
Машины с автопилотом
С помощью RL автономные машины учатся адаптироваться к дорожным условиям, оптимизировать маршруты и парковаться в ограниченных пространствах.
Автомобили Tesla используют RL для обучения в реальных условиях вождения. Система получает данные от сенсоров и камер, анализирует их и принимает решения на основе накопленного опыта.
Боты для игр
RL обучает ботов реагировать на поведение других игроков. Агенты получают обратную связь на основе игровых результатов и корректируют свои стратегии. Например, компания DeepMind создала бота AlphaGo, который с помощью RL обыграл чемпионов мира по игре го.
Коротко о методе RL
- Обучение с подкреплением — это метод машинного обучения, в котором программа учится взаимодействовать с окружающей средой для получения максимальной награды через систему проб и ошибок.
- Процесс RL похож на обучение человека, а его основы лежат в поведенческой психологии.
- Существуют различные алгоритмы RL, например Q-обучение и SARSA, которые используют в зависимости от сложности задачи и среды обучения.
- RL — простой и экономный метод. Для обучения агентов не нужно размечать данные или привлекать экспертов.
- Методы RL особенно полезны в задачах с отложенным вознаграждением, где нужно оценивать последствия серии действий, а не отдельных шагов.
- Машинное обучение с подкреплением используется во многих сферах, например для обучения игровых ботов, роботов, автономных машин и рекомендательных систем.