

Когда нужно посчитать нарастающий итог, определить место записи в рейтинге или сравнить текущую строку с предыдущей, обычных агрегатных функций SQL уже недостаточно. Для таких задач используют оконные функции. Разберем, как устроено окно расчета, зачем нужны OVER и PARTITION BY и как применять ROW_NUMBER, RANK, LAG и LEAD на практике.
Что такое оконные функции SQL и как они работают
Оконные функции в SQL позволяют выполнять вычисления для заданного набора строк. База данных берет запись, определяет для нее окно данных и записывает рядом результат расчета. Так можно получить номер записи, место в рейтинге, сумму на текущую дату или значение из соседней строки.

Если при группировке c GROUP BY база данных собирает несколько записей в итог по группе, то оконная функция сохраняет построчную детализацию и добавляет расчет отдельным столбцом.
Из чего состоит оконная функция
Оконная функция состоит из двух частей: самой функции и выражения OVER. Функция показывает, что нужно посчитать — сумму, номер строки, рейтинг, предыдущее значение или следующее значение. OVER показывает, по каким строкам нужно выполнить расчет.
Пример:
SELECT customer_id, payment_date, amount, SUM(amount) OVER () AS total_amount FROM payment;
Здесь функция SUM(amount) OVER () считает сумму всех платежей из таблицы payment, которые попали в результат запроса.
В результате у каждой строки появляется новый столбец total_amount с общей суммой, например:
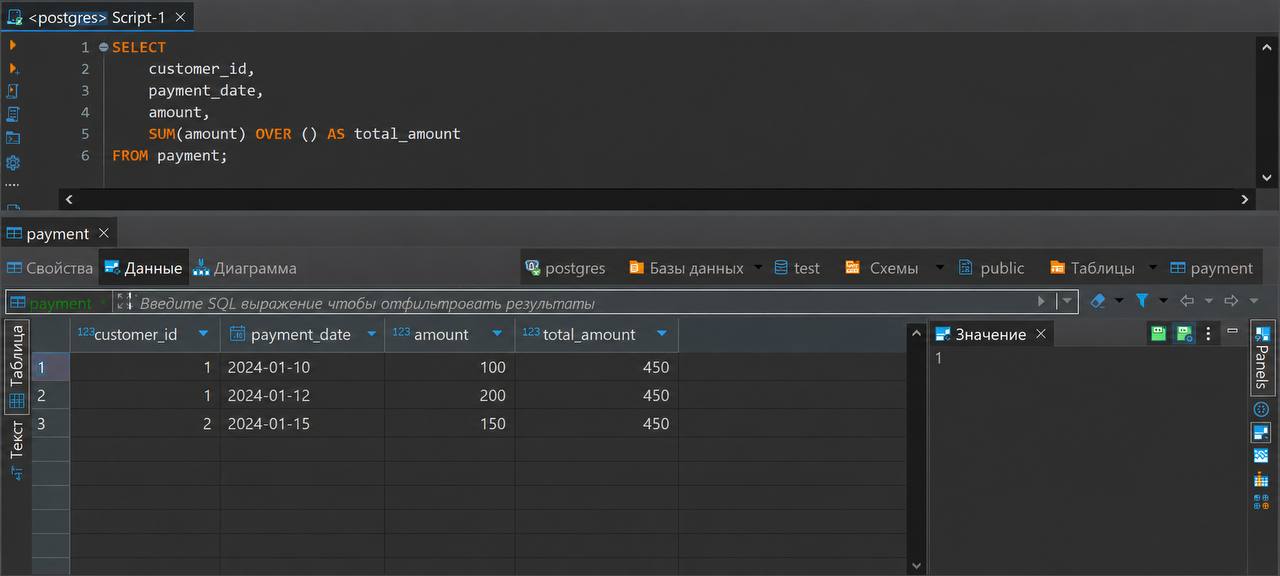
Так как в этом примере после OVER пустые скобки, функция учитывает всю выборку. Поэтому в каждой строке столбец total_amount содержит одно и то же значение — общую сумму всех платежей.
Если нужно уточнить, какие строки участвуют в расчете и в каком порядке, внутри OVER(...) задают правила окна: PARTITION BY, ORDER BY, ROWS BETWEEN, RANGE BETWEEN.
Разберем эти правила на примерах с функцией SUM().
PARTITION BY
PARTITION BY делит выборку на группы внутри оконного расчета. Например, можно посчитать сумму платежей отдельно для каждого клиента:
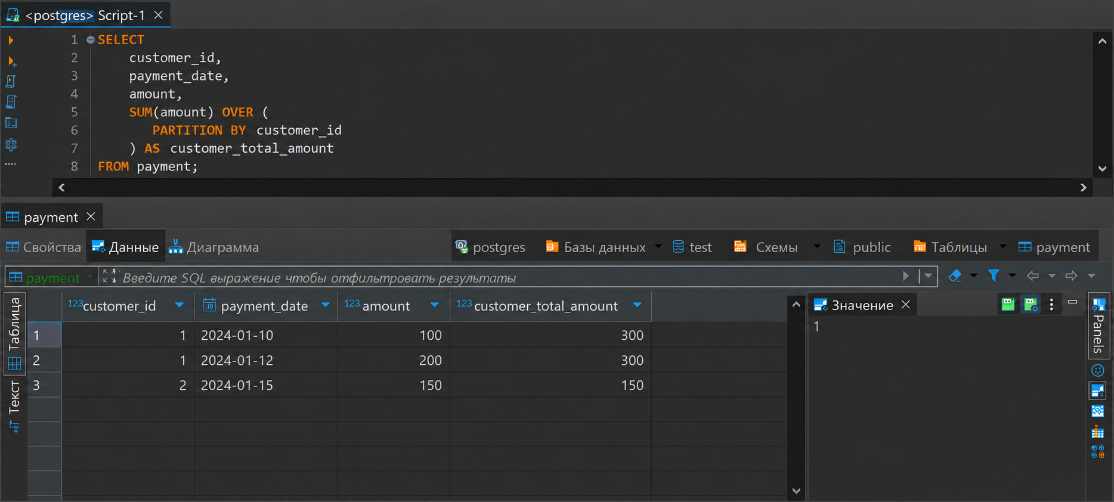
SELECT customer_id, payment_date, amount, SUM(amount) OVER ( PARTITION BY customer_id ) AS customer_total_amount FROM payment;
Здесь расчет суммы начинается заново для каждого customer_id. Сначала база данных распределяет строки по клиентам, затем считает сумму внутри каждой группы.
В результате каждая строка остается в таблице, а в новом столбце появляется сумма платежей именно этого клиента.
ORDER BY
ORDER BY внутри OVER(…) задает порядок строк для оконного расчета. Он нужен, когда результат зависит от последовательности строк — например, от даты платежа, суммы продажи или времени события.
Пример:
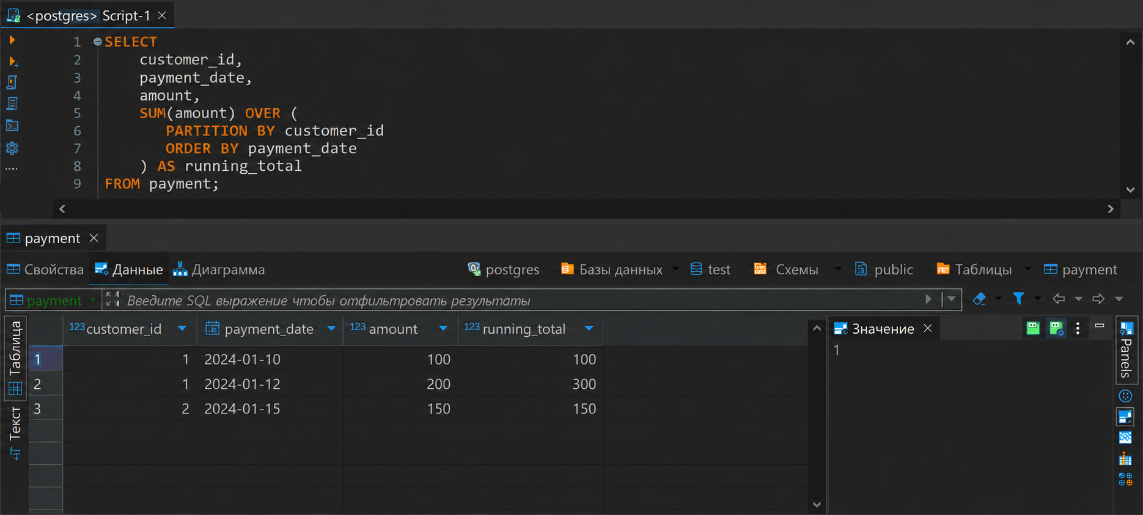
SELECT customer_id, payment_date, amount, SUM(amount) OVER ( PARTITION BY customer_id ORDER BY payment_date ) AS running_total FROM payment;
Здесь сумма считается отдельно по каждому клиенту и накапливается по дате платежа.
Для первого платежа клиента в столбце running_total получим сумму первого платежа. Для второго платежа того же клиента получим сумму первого и второго платежа. Такой расчет называют нарастающим итогом.
ROWS BETWEEN и RANGE BETWEEN
ROWS BETWEEN и RANGE BETWEEN уточняют, какие строки внутри окна участвуют в расчете. Обычно эти конструкции используют вместе с ORDER BY, когда нужно посчитать значение по части строк, а не по всему разделу целиком.
Пример:
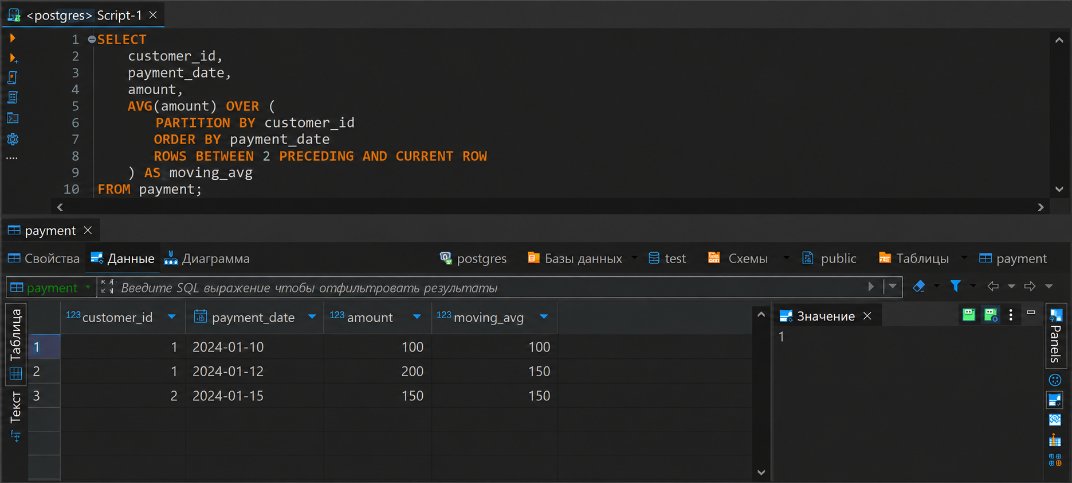
SELECT customer_id, payment_date, amount, AVG(amount) OVER ( PARTITION BY customer_id ORDER BY payment_date ROWS BETWEEN 2 PRECEDING AND CURRENT ROW ) AS moving_avg FROM payment;
Здесь ROWS BETWEEN 2 PRECEDING AND CURRENT ROW означает, что для каждой строки база данных берет текущую строку и две предыдущие строки в пределах того же клиента, а затем считает среднее значение amount.
Если строк меньше, чем указано в условии, то используются только те строки, которые есть. Например, для первого платежа клиента среднее будет посчитано только по одной строке, для второго — по двум строкам.
В этом запросе результат будет таким:
- Для первого платежа клиента 1 среднее равно 100;
- Для второго платежа клиента 1 среднее равно (100 + 200) / 2 = 150;
- Для клиента 2, у которого только один платеж, среднее равно 150.
Важно различать ROWS и RANGE:
- ROWS считает строки по их количеству — например, две предыдущие строки, одна следующая строка, текущая строка;
- RANGE ориентируется на значение в ORDER BY — то есть в расчет попадают строки, которые входят в заданный диапазон значений.
Какие функции можно использовать с OVER
Выше мы разбирали правила окна на примерах с SUM(), потому что сумму легко проверить по строкам. Но OVER работает и с другими функциями.
Дальше разберем основные функции, которые чаще всего встречаются в аналитических запросах.
Агрегатные функции SUM, COUNT, AVG, MIN, MAX
Обычные агрегатные функции считают итоговое значение. Если добавить к ним OVER, то они начинают работать как оконные функции, то есть считают итог по заданному окну и добавляют результат к каждой строке.
Например, COUNT(*) считает количество строк в итоговой выборке или группе. А COUNT(*) OVER (…) добавляет количество строк к каждой записи.
Пример:
SELECT customer_id, payment_date, amount, COUNT(*) OVER ( PARTITION BY customer_id ) AS customer_payments_count, MAX(amount) OVER ( PARTITION BY customer_id ) AS customer_max_amount FROM payment;
Здесь COUNT(*) OVER (PARTITION BY customer_id) считает количество платежей каждого клиента. MAX(amount) OVER (PARTITION BY customer_id) показывает самый крупный платеж этого клиента.
Если у клиента два платежа, в обеих строках этого клиента будет одно и то же количество платежей и один и тот же максимум. При этом сами строки платежей останутся в результате.
ROW_NUMBER
ROW_NUMBER() нумерует строки внутри окна. Функция возвращает порядковый номер строки. Обычно ROW_NUMBER() используют вместе с ORDER BY, потому что номер зависит от порядка строк. Если добавить PARTITION BY, то нумерация будет начинаться заново внутри каждой группы.
SELECT customer_id, payment_date, amount, ROW_NUMBER() OVER ( PARTITION BY customer_id ORDER BY payment_date ) AS payment_number FROM payment;
Здесь платежи нумеруются отдельно для каждого клиента. У клиента 1 первый платеж по дате получит номер 1, второй — номер 2. У клиента 2 нумерация начнется заново, поэтому его первый платеж тоже получит номер 1.
Итоговая таблица будет выглядеть примерно так:
| customer_id | payment_date | amount | payment_number |
| 1 | 2024-01-10 | 100 | 1 |
| 1 | 2024-01-12 | 200 | 2 |
| 2 | 2024-01-15 | 150 | 1 |
RANK и DENSE_RANK
RANK() и DENSE_RANK() присваивают строкам места в рейтинге. Их используют, когда нужно отсортировать строки по выбранному показателю и понять, какое место занимает каждая строка.
Эти функции почти всегда используют с ORDER BY, потому что рейтинг строится по заданному порядку — по сумме платежа, количеству заказов, дате события и другим значениям.
Для наглядности возьмем данные, где две строки имеют одинаковую сумму платежа:
| customer_id | payment_date | amount |
| 1 | 2024-01-10 | 200 |
| 2 | 2024-01-12 | 200 |
| 3 | 2024-01-15 | 150 |
| 4 | 2024-01-18 | 100 |
- RANK() присваивает одинаковым значениям одно место. Следующее место считается с учетом количества строк выше, поэтому в рейтинге могут появляться пропуски. Например, если первое место заняли две строки, то следующая строка получит место 3.
Пример:
SELECT customer_id, payment_date, amount, RANK() OVER ( ORDER BY amount DESC ) AS payment_rank FROM payment;
Результат:
| customer_id | payment_date | amount | payment_rank |
| 1 | 2024-01-10 | 200 | 1 |
| 2 | 2024-01-12 | 200 | 1 |
| 3 | 2024-01-15 | 150 | 3 |
| 4 | 2024-01-18 | 100 | 4 |
Два платежа по 200 делят первое место. Следующий платеж получает место 3, потому что первые две строки уже заняли две позиции в рейтинге.
- DENSE_RANK() тоже присваивает одинаковым значениям одно место, но продолжает рейтинг без пропусков.
Пример:
SELECT customer_id, payment_date, amount, DENSE_RANK() OVER ( ORDER BY amount DESC ) AS dense_payment_rank FROM payment;
Результат:
| customer_id | payment_date | amount | dense_payment_rank |
| 1 | 2024-01-10 | 200 | 1 |
| 2 | 2024-01-12 | 200 | 1 |
| 3 | 2024-01-15 | 150 | 2 |
| 4 | 2024-01-18 | 100 | 3 |
Два платежа по 200 также делят первое место. Следующий платеж получает место 2, потому что DENSE_RANK() ведет рейтинг без пропущенных номеров.

LAG и LEAD
LAG() и LEAD() называют функциями смещения. Они позволяют получить значение из соседней строки — предыдущей (LAG) или следующей (LEAD).
Эти функции используют вместе с ORDER BY, потому что базе данных нужно понимать, какая строка считается предыдущей или следующей. Если добавить PARTITION BY, то поиск соседней строки будет выполняться внутри каждой группы.
- LAG() берет значение из предыдущей строки.
Пример:
SELECT customer_id, payment_date, amount, LAG(amount) OVER ( PARTITION BY customer_id ORDER BY payment_date ) AS previous_amount FROM payment;
Находим предыдущий платеж клиента. Здесь previous_amount показывает сумму предыдущего платежа того же клиента. У первого платежа клиента предыдущей строки нет, поэтому в результате будет NULL.
В результате может получиться такая таблица:
| customer_id | payment_date | amount | previous_amount |
| 1 | 2024-01-10 | 100 | NULL |
| 1 | 2024-01-12 | 200 | 100 |
| 2 | 2024-01-15 | 150 | NULL |
- LEAD() берет значение из следующей строки.
Пример:
SELECT customer_id, payment_date, amount, LEAD(amount) OVER ( PARTITION BY customer_id ORDER BY payment_date ) AS next_amount FROM payment;
Здесь next_amount показывает сумму следующего платежа того же клиента. У последнего платежа клиента следующей строки нет, поэтому в результате будет NULL.
Пример результата:
| customer_id | payment_date | amount | next_amount |
| 1 | 2024-01-10 | 100 | 200 |
| 1 | 2024-01-12 | 200 | NULL |
| 2 | 2024-01-15 | 150 | NULL |
CUME_DIST, PERCENT_RANK и NTILE
CUME_DIST(), PERCENT_RANK() и NTILE() помогают оценить положение строки внутри отсортированного набора данных. Их используют реже, чем ROW_NUMBER, RANK, LAG и LEAD, но их можно использовать для анализа распределения платежей, поиска верхней части рейтинга или деления клиентов на сегменты.
Для примера возьмем такую таблицу:
| customer_id | payment_date | amount |
| 1 | 2024-01-10 | 100 |
| 2 | 2024-01-12 | 150 |
| 3 | 2024-01-15 | 200 |
| 4 | 2024-01-18 | 200 |
- CUME_DIST
CUME_DIST() показывает, какая доля строк имеет значение меньше или равное текущему. Результат находится в диапазоне от 0 до 1.
Пример:
SELECT customer_id, payment_date, amount, CUME_DIST() OVER ( ORDER BY amount ) AS amount_distribution FROM payment;
Результат:
| customer_id | payment_date | amount | amount_distribution |
| 1 | 2024-01-10 | 100 | 0.25 |
| 2 | 2024-01-12 | 150 | 0.50 |
| 3 | 2024-01-15 | 200 | 1.00 |
| 4 | 2024-01-18 | 200 | 1.00 |
Здесь платеж 100 находится на первой позиции из четырех, поэтому получает значение 0.25. Платеж 150 находится на второй позиции, поэтому получает 0.50. Два платежа по 200 имеют максимальное значение, поэтому оба получают 1.00.
- PERCENT_RANK
PERCENT_RANK() показывает относительное место строки в рейтинге от 0 до 1. Чем ближе значение к 0, тем ближе строка к началу отсортированного набора. Чем ближе к 1, тем ближе строка к концу.
Пример:
SELECT customer_id, payment_date, amount, PERCENT_RANK() OVER ( ORDER BY amount ) AS amount_percent_rank FROM payment;
Результат:
| customer_id | payment_date | amount | amount_percent_rank |
| 1 | 2024-01-10 | 100 | 0.00 |
| 2 | 2024-01-12 | 150 | 0.33 |
| 3 | 2024-01-15 | 200 | 0.67 |
| 4 | 2024-01-18 | 200 | 0.67 |
Здесь первый платеж получает 0.00, потому что он стоит в начале отсортированного набора. Платежи по 200 получают одинаковое значение, потому что занимают одно место в рейтинге.
PERCENT_RANK() похож на CUME_DIST(), но считает положение иначе. CUME_DIST() учитывает долю строк до текущего значения включительно, а PERCENT_RANK() опирается на ранг строки в отсортированном наборе.
- NTILE
NTILE(n) делит строки на n примерно равных групп. Вместо n указывают количество групп.
Эта функция зависит от порядка строк, поэтому внутри OVER(…) используют ORDER BY. Если в сортировке есть одинаковые значения, то порядок таких строк может быть неочевидным. Чтобы результат был стабильным, можно добавить в ORDER BY еще один столбец.
Пример:
SELECT customer_id, payment_date, amount, NTILE(4) OVER ( ORDER BY amount, customer_id ) AS amount_group FROM payment;
Результат:
| customer_id | payment_date | amount | amount_group |
| 1 | 2024-01-10 | 100 | 1 |
| 2 | 2024-01-12 | 150 | 2 |
| 3 | 2024-01-15 | 200 | 3 |
| 4 | 2024-01-18 | 200 | 4 |
Здесь NTILE(4) делит четыре платежа на четыре группы. Сначала строки сортируются по сумме платежа, а при одинаковых суммах дополнительно упорядочиваются по customer_id. Поэтому два платежа по 200 попадают в предсказуемом порядке: сначала клиент 3, затем клиент 4.
Оконные функции SQL: коротко о главном
- Оконные функции в SQL добавляют к каждой строке расчет, сделанный по заданному набору строк.
- В отличие от GROUP BY, оконные функции сохраняют исходные строки в результате. Расчет добавляется отдельным столбцом.
- Оконная функция состоит из двух частей — из функции и выражения OVER. Функция показывает, что нужно посчитать: сумму, количество, номер строки, место в рейтинге, предыдущее или следующее значение. OVER(…) показывает, по каким строкам нужно выполнить расчет. Если скобки после OVER пустые, то функция учитывает всю выборку.
- PARTITION BY делит строки на группы внутри оконного расчета. Например, с его помощью можно считать сумму отдельно по каждому клиенту.
- ORDER BY задает порядок строк внутри окна. Он нужен для нумерации, рейтингов, поиска соседних записей.
- ROWS BETWEEN и RANGE BETWEEN уточняют границы окна. С их помощью можно считать значение по текущей строке и нескольким соседним строкам.
- Агрегатные функции SUM, COUNT, AVG, MIN, MAX с OVER считают итог по окну и добавляют его к каждой строке.
- ROW_NUMBER() присваивает строкам порядковые номера. Если использовать PARTITION BY, нумерация начинается заново внутри каждой группы.
- RANK() и DENSE_RANK() показывают место строки в рейтинге. RANK() может оставлять пропуски в номерах, а DENSE_RANK() ведет рейтинг без пропусков.
- LAG() берет значение из предыдущей строки, а LEAD() — из следующей. Эти функции используют для сравнения соседних записей.
- CUME_DIST(), PERCENT_RANK() и NTILE() помогают оценить положение строки внутри распределения или разделить данные на группы.