


Разбираемся, как работает группировка в SQL на уровне синтаксиса, в каких случаях она вам пригодится, а также рассказываем, чем GROUP BY отличается от ORDER BY.
Что такое GROUP BY и для чего он нужен
GROUP BY — это оператор, который используют в SQL-запросах в составе SELECT. Он собирает строки в группы по общему признаку и затем считает итог по каждой группе с помощью агрегатных функций (COUNT, SUM).
Например, с его помощью можно узнать количество заказов по клиентам, сумму продаж по месяцам, среднюю цену по категориям и другие агрегированные показатели.

Базовый синтаксис GROUP BY
GROUP BY используют внутри запроса SELECT. Обычно он стоит после WHERE и до HAVING и ORDER BY, если они присутствуют в запросе.
Как составить запрос с GROUP BY
Структура классического запроса с группировкой выглядит так:
SELECT [1] FROM [2] WHERE [3] GROUP BY [4];
[1] — что именно выводим в результате. Обычно это:
- поле или поля группировки (они же перечислены в GROUP BY), по которым считается результат;
- итоговые значения по каждой группе через агрегатные функции — например, COUNT(*), SUM(amount), AVG(price).
[2] — таблица (или несколько таблиц через JOIN), из которой берем данные.
[3] — условие фильтрации строк до группировки, если оно нужно (например, заказы только за текущий год).
[4] — поле или поля, по которым строки объединяются в группы.
Пример
Есть таблица orders, которая состоит из двух столбцов — customer_id (id клиента) и amount (сумма заказа). Посчитаем, сколько заказов у каждого клиента и на какую сумму:
SELECT customer_id, COUNT(*) AS orders_count, SUM(amount) AS total_amount FROM orders GROUP BY customer_id;
Здесь customer_id задает группы, а COUNT(*) и SUM(amount) считают итоги внутри каждой группы.
Важно: в SELECT должен быть либо агрегат, либо поле из GROUP BY
Если в запросе есть GROUP BY, то в списке SELECT можно указывать только два типа выражений:
- Поля, по которым вы группируете (то есть перечисленные в GROUP BY).
- Агрегатные функции, которые считают итог по группе: COUNT, SUM, AVG, MIN, MAX.
Например, мы группируем заказы по customer_id. У одного клиента может быть много заказов, у которых разные order_date и status. Если написать так:
SELECT customer_id, order_date, SUM(amount) FROM orders GROUP BY customer_id;
то для одного customer_id найдется несколько order_date. Запрос в этом случае неоднозначен: будет непонятно, какую именно дату вывести в одной строке результата — первую, вторую или последнюю.
В таком случае нужно либо добавлять поле в GROUP BY, либо превращать его в итог через агрегат (например, MIN(order_date) или MAX(order_date)).
Как использовать агрегатные функции с GROUP BY
Агрегатные функции считают итог по группе строк. Чаще всего их используют вместе с GROUP BY, но некоторые из них можно применять и без группировки, если нужен общий итог по всей таблице.
В примерах будем использовать таблицу orders с таким содержимым:
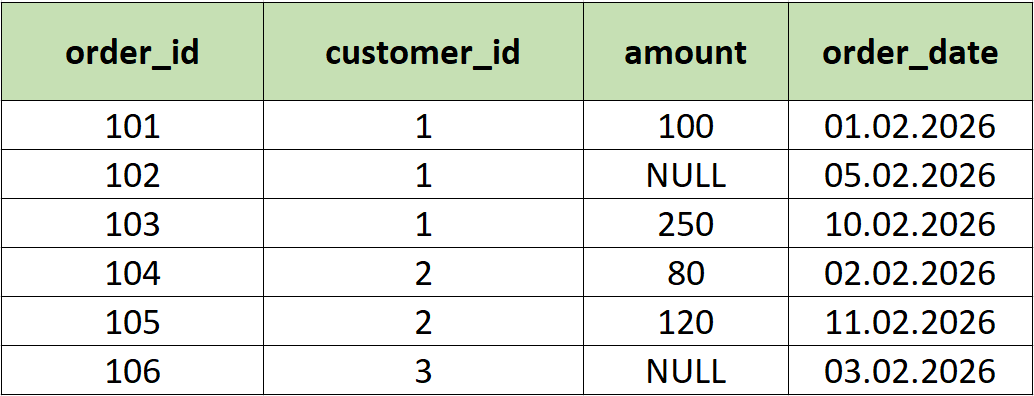
COUNT()
COUNT() считает количество элементов в группе:
- COUNT(*) считает все строки, которые попали в группу.
- COUNT(column) считает только строки, где column не равен NULL.
Пример 1
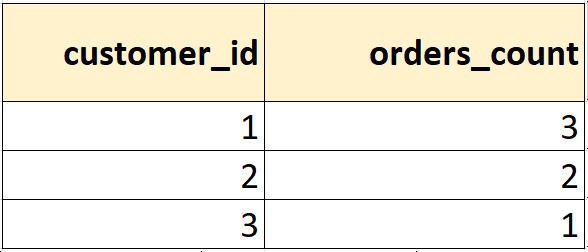
Посчитаем, сколько заказов у каждого клиента:
SELECT customer_id, COUNT(*) AS orders_count FROM orders GROUP BY customer_id;
Результат:
Пример 2
Рассмотрим разницу между COUNT(*) и COUNT(amount).
SELECT customer_id, COUNT(*) AS orders_total, COUNT(amount) AS orders_with_amount FROM orders GROUP BY customer_id;
Результат:
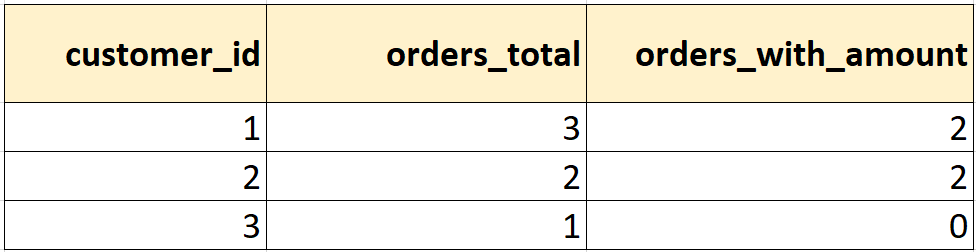
У клиента 1 одна запись с amount = NULL (order_id 102), поэтому COUNT(amount) показывает результат на 1 меньше, чем COUNT(*). У клиента с id 3 единственная запись с NULL, поэтому COUNT(amount) = 0.
SUM()
SUM(column) считает сумму значений столбца (обычно числового).
Пример
Общая сумма заказов по каждому клиенту:
SELECT customer_id, SUM(amount) AS total_amount FROM orders GROUP BY customer_id;
Результат:
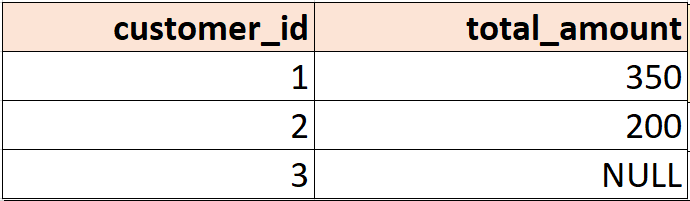
Важно: SUM игнорирует NULL. Если у части строк amount = NULL, то они не будут участвовать в сумме.
Например, у клиента 1 сумма 100 + 250 = 350, и строка с NULL просто не учитывается. Если в группе все значения NULL (как у клиента 3), то итог будет NULL. Но можно выводить и ноль (0). Для этого используем COALESCE:
SELECT customer_id, COALESCE(SUM(amount), 0) AS total_amount FROM orders GROUP BY customer_id;
AVG()
AVG(column) считает среднее значение.
Пример
Средняя сумма заказа по клиентам:
SELECT customer_id, AVG(amount) AS avg_amount FROM orders GROUP BY customer_id;
Результат:
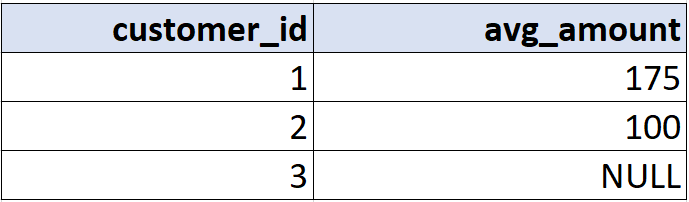
Важно: как и SUM, AVG не учитывает NULL.
MIN() и MAX()
MIN(column) и MAX(column) возвращают минимальное и максимальное значение в группе.
Пример
Вычислим первую и последнюю дату заказа по клиенту:
SELECT customer_id, MIN(order_date) AS first_order_date, MAX(order_date) AS last_order_date FROM orders GROUP BY customer_id;
Результат:


Риск дубликатов и DISTINCT в COUNT
Если в таблице есть повторяющиеся значения, то COUNT(column) посчитает их все. Когда нужно посчитать уникальные значения — например, уникальные товары в заказах или уникальные даты, — то внутри COUNT используют DISTINCT.
Представим, что в таблице orders_with_dates у клиента с id 1 было два заказа в один день:
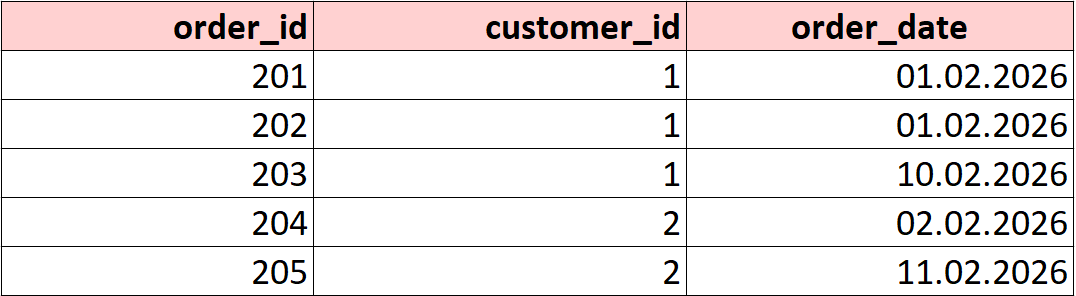
Сравним количество заказов и количество уникальных дней, когда были заказы:
SELECT customer_id, COUNT(*) AS orders_total, COUNT(DISTINCT order_date) AS unique_order_days FROM orders GROUP BY customer_id;
Результат будет таким:

Здесь мы считаем и общее количество заказов, и количество уникальных дней, когда клиент делал заказ. Например, у клиента № 1 три заказа, но только два разных дня.
Группировка по одному столбцу
Группировка по одному столбцу нужна, когда вы хотите получить итог по каждой категории. Например, по клиенту, статусу заказа или городу доставки. Выше мы уже рассматривали такую группировку, когда выводили общее количество заказов по категории customer_id. Для большего понимания рассмотрим и другие примеры.
Создадим таблицу orders_with_status со столбцами order_id, status, amount и order_date и рассмотрим на ней сценарии группировки.
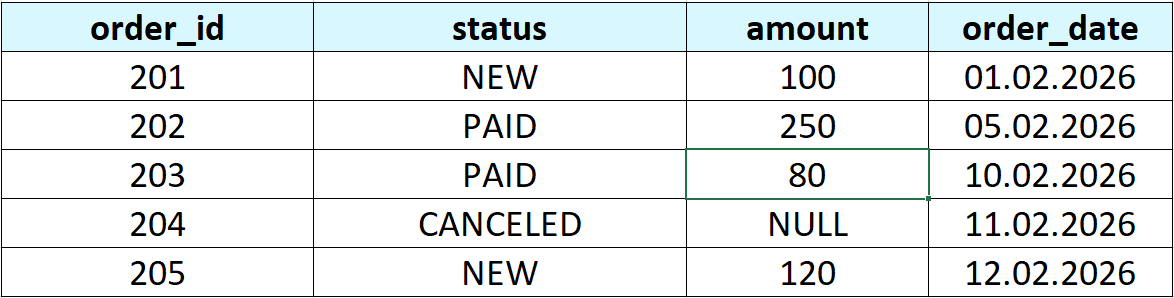
Количество записей в каждой группе
Нужно посчитать, сколько строк относится к каждому значению выбранного столбца.
Пример
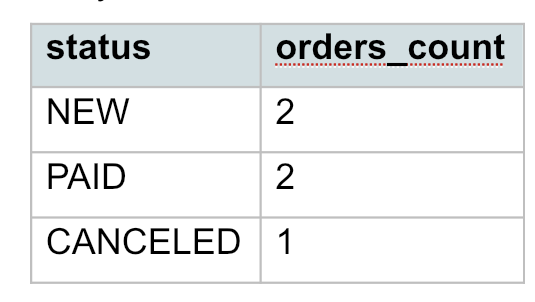
Посчитаем, сколько заказов в каждом статусе.
SELECT status, COUNT(*) AS orders_count FROM orders GROUP BY status;
Получим:
Сумма и среднее значение по группам
По каждому статусу нужно посчитать количество заказов, просто сумму (SUM) и среднюю сумму (AVG).
Пример
SELECT status, COUNT(*) AS orders_count, SUM(amount) AS total_amount, AVG(amount) AS avg_amount FROM orders GROUP BY status;
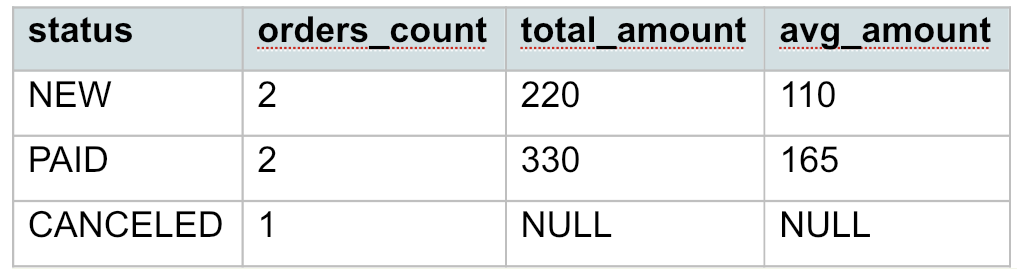
Как считаются показатели по каждой группе:
- статус NEW — две строки (201 и 205):
orders_count = 2
total_amount = 100 + 120 = 220
avg_amount = (100 + 120) / 2 = 110
- статус PAID — две строки (202 и 203):
orders_count = 2
total_amount = 250 + 80 = 330
avg_amount = (250 + 80) / 2 = 165
- статус CANCELED —: одна строка (204), но amount = NULL:
orders_count = 1 (строка есть, поэтому COUNT(*) ее учитывает);
total_amount = NULL (суммировать нечего);
avg_amount = NULL (среднее тоже не из чего считать).
В результате получим:
Важно: как говорили ранее, преобразовать NULL в 0 можно через COALESCE. То есть если вы хотите, чтобы эти значения участвовали в расчетах, нужно явно прописать:
SUM(COALESCE(amount, 0)) AS total_amount, AVG(COALESCE(amount, 0)) AS avg_amount
Группировка по нескольким столбцам
GROUP BY может группировать сразу по нескольким столбцам. Рассмотрим для примера таблицу orders_with_payment_methods.
Можно сгруппировать только по status. Тогда мы получим итоги по статусам. А если добавить payment_method, мы увидим итоги по каждой паре «статус + способ оплаты».
Что считается группой и как ее получить
Группа при GROUP BY status, payment_method — это уникальное сочетание значений этих столбцов.
Пример
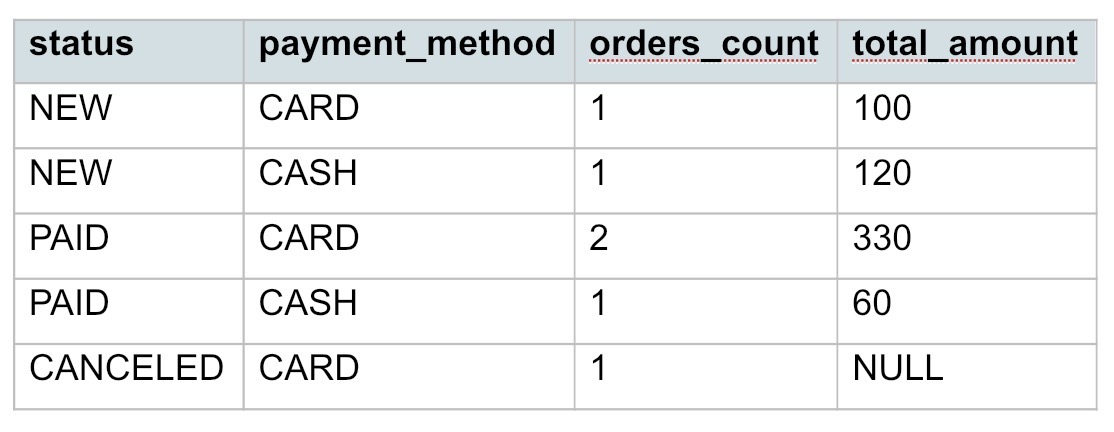
SELECT status, payment_method, COUNT(*) AS orders_count, SUM(amount) AS total_amount FROM orders GROUP BY status, payment_method;
Как будут образованы группы:
- (NEW, CARD) одна строка (301);
- (NEW, CASH) одна строка (302);
- (PAID, CARD) две строки (303, 304);
- (PAID, CASH) одна строка (305);
- (CANCELED, CARD) одна строка (306).
Получится такой результат:
Фильтрация с WHERE и HAVING
В запросах с GROUP BY фильтровать данные можно двумя способами — через WHERE и через HAVING.
Возьмем для примера еще одну таблицу orders_with_status_and_dates.
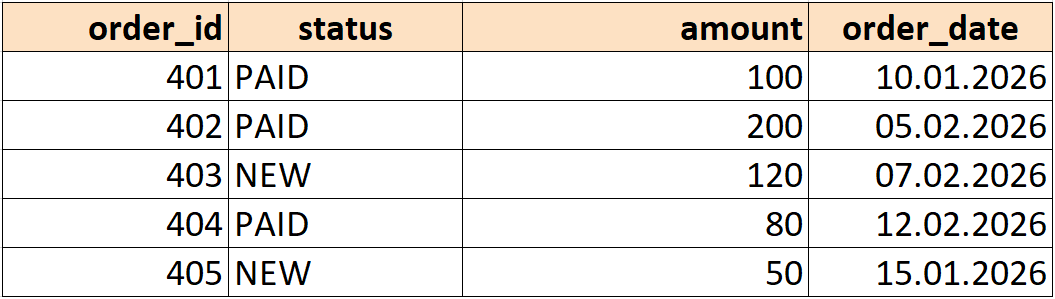
WHERE фильтрует строки до группировки
WHERE работает с отдельными строками таблицы. Сначала база отбирает строки по условию WHERE, и только потом из оставшихся строк формируются группы.
Пример
Нужно посчитать количество заказов по статусам за февраль 2026 года.
SELECT status, COUNT(*) AS orders_count FROM orders WHERE order_date >= '2026-02-01' AND order_date < '2026-03-01' GROUP BY status;
Тогда в группировку попадут только строки за февраль.
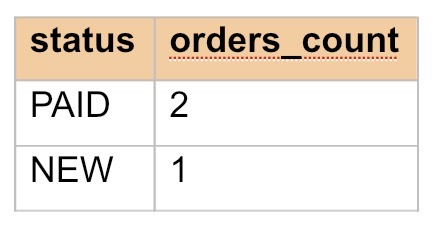
HAVING фильтрует группы после группировки
HAVING применяют, когда нужно отфильтровать уже посчитанные группы. Чаще всего в HAVING используют агрегатные функции (COUNT, SUM, AVG).
Пример
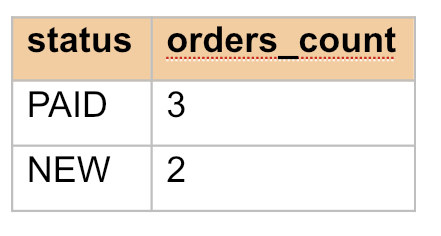
Нужно показать только те статусы, где заказов не менее 2.
SELECT status, COUNT(*) AS orders_count FROM orders GROUP BY status HAVING COUNT(*) >= 2;
Сначала формируются группы по status, затем для каждой группы считается COUNT(*), и только потом группы, которые не подходят условию, убираются из результата. Получится:
Пример с WHERE и HAVING
Часто используют оба условия: WHERE фильтрует нужные строки, а HAVING фильтрует нужные группы.
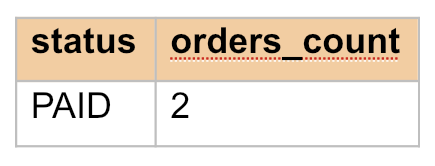
Возьмем только февраль 2026 года и покажем статусы, где заказов не менее 2.
SELECT status, COUNT(*) AS orders_count FROM orders WHERE order_date >= '2026-02-01' AND order_date < '2026-03-01' GROUP BY status HAVING COUNT(*) >= 2;
Получим:
Разница между GROUP BY и ORDER BY
GROUP BY и ORDER BY часто встречаются в одном запросе, но решают разные задачи.
- GROUP BY объединяет строки в группы и позволяет считать итоги по каждой группе.
- ORDER BY сортирует уже готовый результат (строки, которые вернул SELECT).
Снова возьмем таблицу orders_with_payment_methods и рассмотрим, как работают GROUP BY и ORDER BY в связке и по отдельности.
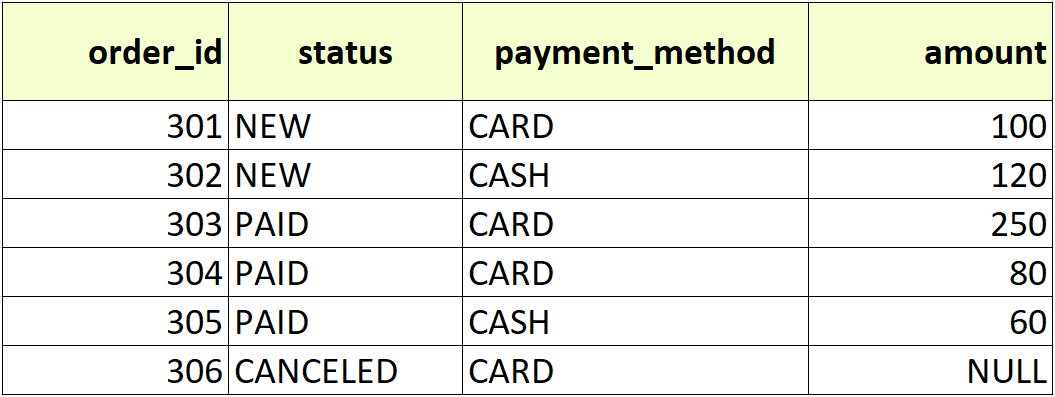
Пример 1
Получим итоги по статусам
SELECT status, COUNT(*) AS orders_count, SUM(amount) AS total_amount FROM orders GROUP BY status;
Результат:
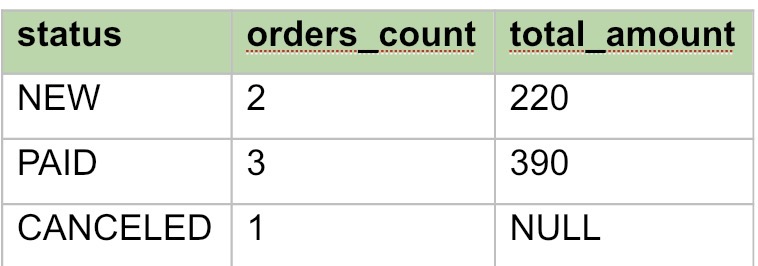
Без ORDER BY порядок строк результата не гарантирован.
Пример 2
ORDER BY отсортирует уже посчитанные группы.
SELECT status, SUM(amount) AS total_amount FROM orders GROUP BY status ORDER BY total_amount DESC;
Получим:
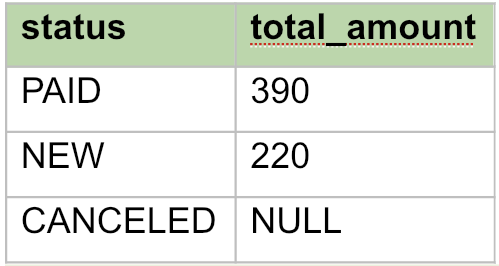
В разных СУБД NULL при сортировке может оказаться в начале или в конце. Если нужно отправлять NULL, например, вниз, можно сделать так:
ORDER BY (total_amount IS NULL), total_amount DESC
Также бывает, что целевые значения у двух строк равны. Тогда их порядок может быть любым. Для конкретики можно добавить дополнительный критерий сортировки.
ORDER BY total_amount DESC, status ASC;
Если в таблице попадутся значения с одинаковым total_amount, то они отсортируются по status.
Сокращение GROUP BY 1
В SQL иногда используют сокращение GROUP BY 1, GROUP BY 2 и т. д. Вместо названий столбцов указывают номер выражения из списка SELECT.
Хотя в учебных примерах лучше писать запросы явно, коротко расскажем и про сокращения.
Например, «Запрос 1» и «Запрос 2» выполняют одно и то же:
Запрос 1
SELECT status, COUNT(*) AS orders_count FROM orders_with_payment_methods GROUP BY status;
Запрос 2
SELECT status, COUNT(*) AS orders_count FROM orders_with_payment_methods GROUP BY 1;
GROUP BY 1 означает «группировать по первому выражению в SELECT». В нашем случае первым выражением является status, поэтому результат будет одинаковым.
Коротко о GROUP BY
- GROUP BY объединяет строки в группы по одному или нескольким столбцам и позволяет считать итоги по каждой группе.
- В SELECT при наличии GROUP BY можно указывать только поля из GROUP BY и агрегатные функции (COUNT, SUM, AVG, MIN, MAX).
- COUNT(*) считает строки, а COUNT(column) — только значения, где column не равен NULL.
- SUM и AVG не учитывают NULL. Если нужно считать NULL как 0, используйте COALESCE.
- COUNT(DISTINCT …) считает уникальные значения и помогает избежать неверных подсчетов из-за дубликатов.
- WHERE фильтрует строки до группировки, HAVING фильтрует группы после группировки и обычно использует агрегаты.
- ORDER BY сортирует уже готовый результат и часто применяется после группировки для сортировки групп по сумме или количеству.
- GROUP BY 1 и похожие сокращения работают через позицию выражения в SELECT. При этом они могут ухудшить читаемость.