


Представьте, что вы готовите данные для рекомендательной системы. У вас есть огромная таблица с профилями пользователей, и каждый день прилетают новые логи действий. Вам нужно обновить старых пользователей и добавить новых. Если делать это «в лоб», вы напишете кучу кода. Но есть другой, быстрый и элегантный способ.
Разберем инструмент, который лично мне сэкономил сотни часов отладки пайплайнов и километры нервов. Речь пойдет об SQL-операторе MERGE.
Кошмар обновляющихся данных
Начнем с простой жизненной аналогии — представьте, что вы ведете список гостей на свадьбу в Excel. Каждый день ваша мама звонит и диктует изменения:
- «Тетя Люба приедет, но не одна, а с мужем» (нужно обновить существующую запись).
- «Дядя Вася не приедет» (нужно удалить или пометить как «отказ»).
- «Появился троюродный брат Коля, которого мы забыли» (нужно добавить новую запись).

В мире баз данных это классическая задача синхронизации двух таблиц:
- Target (Целевая таблица): ваш основной список гостей (или Feature Store).
- Source (Источник): список изменений от мамы (или дневной батч данных).
Как это решают новички?
Обычно пишут скрипт на Python или сложную процедуру в SQL, которая делает примерно следующее:
- SELECT всех из источника.
- В цикле проверяем: есть ли такой user_id в целевой таблице?
- Если есть -> делаем UPDATE.
- Если нет -> делаем INSERT.
В чем минусы такого подхода?
- Скорость. Это медленно. Очень медленно. Вы гоняете базу туда-сюда.
- Атомарность. Что, если скрипт упадет посередине? У вас половина данных обновилась, половина нет. Данные «разъехались».
- Сложность кода. Вам нужно поддерживать логику, которая легко ломается при изменении схемы.
Именно здесь на сцену выходит MERGE. Это «швейцарский нож» в SQL, который позволяет вставлять, обновлять и удалять данные за один проход (в рамках одной транзакции). В мире ML-инжиниринга это стандарт де-факто для построения инкрементальных обновлений витрин данных.
Оператор MERGE в SQL и его логика
Оператор MERGE (в некоторых диалектах его называют UPSERT, от слов UPdate + inSERT, хотя MERGE мощнее) входит в стандарт SQL:2003. Он сравнивает данные из источника (Source) с целевой таблицей (Target) по определенному ключу и выполняет действия в зависимости от результата сравнения.
Глобально у MERGE есть три ветки логики (три типа состояний), в которые может попасть каждая строка:
- MATCHED (Совпадение). Ключ (например, user_id) есть и в источнике, и в целевой таблице.
- Действие: Обычно мы обновляем (UPDATE) поля в целевой таблице новыми данными.
- Пример: Пользователь был в базе, вчера он совершил покупку -> обновляем его total_spend.
- NOT MATCHED [BY TARGET] (Не найдено в целевой). Ключ есть в источнике, но его нет в целевой таблице.
- Действие: Это новый объект, его нужно вставить (INSERT).
- Пример: Пришел совершенно новый пользователь -> добавляем его в базу.
- NOT MATCHED BY SOURCE (Не найдено в источнике). Ключ есть в целевой таблице, но его нет в источнике.
- Действие: Это самый интересный пункт. В зависимости от задачи мы можем либо ничего не делать, либо удалить (DELETE) запись, либо пометить ее как неактивную.
- Пример: Мы синхронизируем список активных товаров. Если товара нет в свежем прайс-листе, значит, он снят с продажи -> ставим флаг is_active = False.
Важное замечание про диалекты: Синтаксис MERGE поддерживается в MS SQL Server, Oracle, PostgreSQL (начиная с 15 версии), BigQuery, Snowflake. В MySQL есть аналог INSERT … ON DUPLICATE KEY UPDATE, который проще, но менее гибок. Мы будем рассматривать стандартный синтаксис, применимый к большинству серьезных DWH (Data Warehouses).
Синтаксис MERGE
Давайте разберем анатомию этого запроса. Она может показаться громоздкой, но она очень логична.
Общая структура выглядит так:
MERGE INTO target_table AS T -- Куда вливаем (Цель) USING source_table AS S -- Откуда берем (Источник) ON (T.id = S.id) -- Условие стыковки (Ключ) -- Ветка 1: Если нашли совпадение WHEN MATCHED THEN UPDATE SET T.col1 = S.col1, T.updated_at = NOW() -- Ветка 2: Если в Цели нет, а в Источнике есть WHEN NOT MATCHED THEN INSERT (id, col1, created_at) VALUES (S.id, S.col1, NOW()) -- Ветка 3: Если в Цели есть, а в Источнике нет (опционально) WHEN NOT MATCHED BY SOURCE THEN DELETE; -- Или UPDATE
Чтобы лучше понять логику, давайте посмотрим на диаграмму процесса. Я нарисовал ее специально для вас, чтобы визуализировать потоки данных.
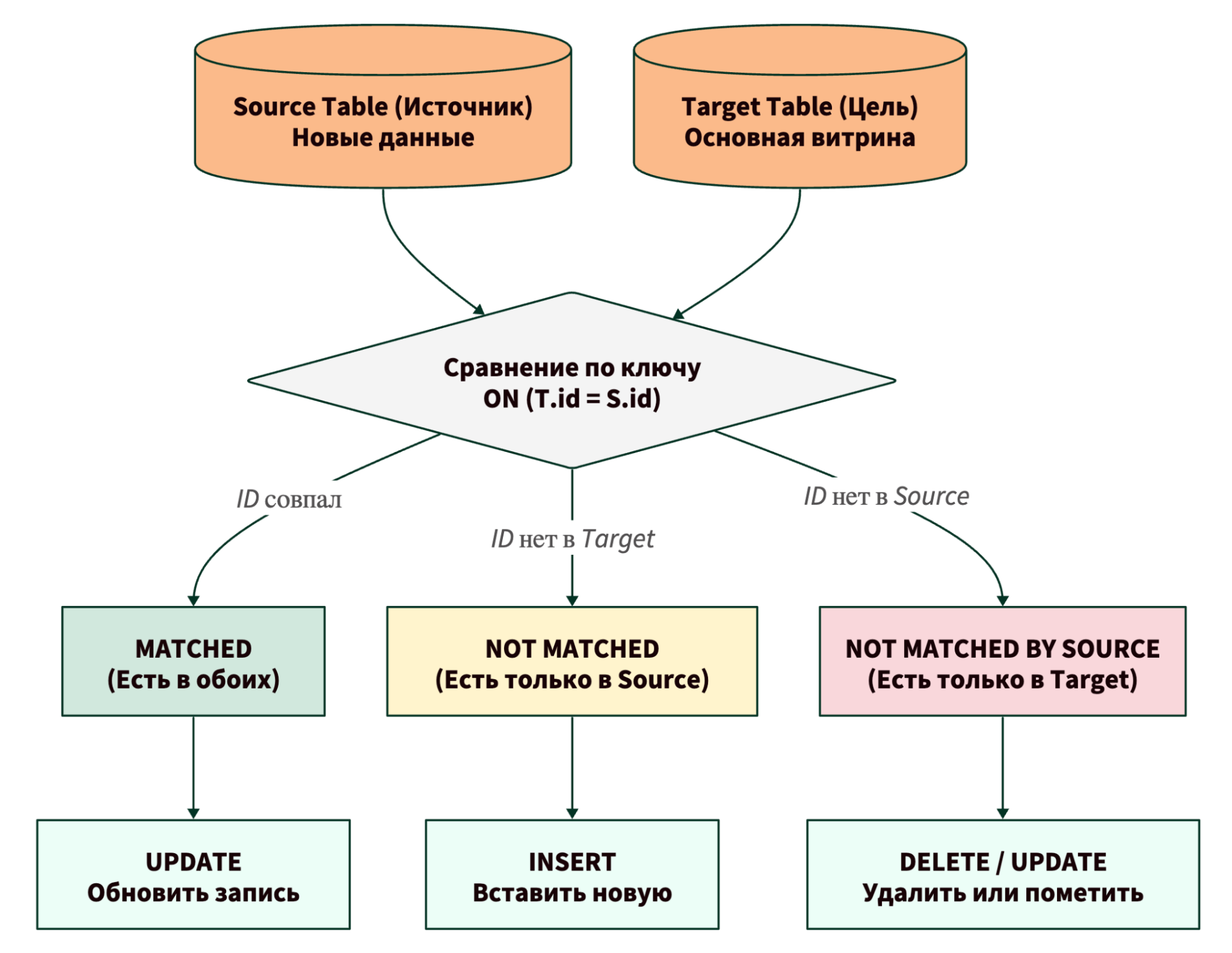
Разбор диаграммы:
- Данные из Source и Target встречаются в блоке сравнения.
- SQL-движок проверяет условие ON.
- Потоки разделяются на три рукава, каждый из которых выполняет свою DML (Data Manipulation Language) операцию.
Это невероятно мощно для ML, потому что гарантирует консистентность. Вы не можете случайно вставить дубликат пользователя, если правильно настроили условие ON.

Пример использования оператора MERGE на практике
Перейдем от теории к реальной задаче из жизни ML-инженера.
Задача: Мы строим Feature Store для модели предсказания оттока клиентов (Churn Prediction). У нас есть таблица customer_features (наша Target), где хранятся агрегированные данные по каждому клиенту. Раз в сутки нам приходит таблица daily_transactions (наша Source), содержащая активность за вчерашний день.
Нам нужно:
- Если клиент уже есть в базе и совершал действия вчера -> обновить его сумму трат (total_spent) и дату последней активности (last_active). (MATCHED)
- Если это новый клиент -> добавить его в базу. (NOT MATCHED)
- Если клиент есть в базе, но вчера ничего не делал (его нет в daily_transactions) -> мы хотим обновить поле days_since_last_active, увеличив его на 1. Это критически важная фича для модели оттока! (NOT MATCHED BY SOURCE)
Обратите внимание: мы используем все три ветки логики в одном запросе. Это высший пилотаж оптимизации.
Подготовка данных (DDL)
Представим, что мы работаем в PostgreSQL 15+ или BigQuery.
-- Целевая таблица (Feature Store) CREATE TABLE customer_features ( customer_id INT PRIMARY KEY, total_spent DECIMAL(10, 2), last_active DATE, days_since_last_active INT, status VARCHAR(20) ); -- Наполним ее начальными данными INSERT INTO customer_features VALUES (1, 100.00, '2023-10-01', 0, 'active'), -- Вася (2, 500.00, '2023-09-25', 6, 'active'); -- Петя -- Таблица-источник (Дневной батч за 2023-10-02) CREATE TABLE daily_transactions ( customer_id INT, day_spent DECIMAL(10, 2), transaction_date DATE ); -- Данные за день INSERT INTO daily_transactions VALUES (1, 50.00, '2023-10-02'), -- Вася снова что-то купил (3, 200.00, '2023-10-02'); -- Новый клиент Маша -- Петя (id 2) ничего не купил
Магия MERGE
Теперь напишем запрос, который обновит наше состояние.
MERGE INTO customer_features AS T USING daily_transactions AS S ON (T.customer_id = S.customer_id) -- 1. Сценарий: Клиент активен (Вася) WHEN MATCHED THEN UPDATE SET T.total_spent = T.total_spent + S.day_spent, -- Накапливаем сумму T.last_active = S.transaction_date, -- Обновляем дату T.days_since_last_active = 0, -- Сбрасываем счетчик простоя T.status = 'active' -- 2. Сценарий: Новый клиент (Маша) WHEN NOT MATCHED THEN INSERT (customer_id, total_spent, last_active, days_since_last_active, status) VALUES (S.customer_id, S.day_spent, S.transaction_date, 0, 'new') -- 3. Сценарий: Клиент "молчит" (Петя) -- Внимание: этот синтаксис (NOT MATCHED BY SOURCE) специфичен -- для MS SQL / Oracle / Delta Lake. -- В Postgres это реализуется чуть сложнее, но для примера логики -- мы используем стандартный подход. WHEN NOT MATCHED BY SOURCE THEN UPDATE SET T.days_since_last_active = T.days_since_last_active + 1;
Примечание: Если ваша СУБД не поддерживает NOT MATCHED BY SOURCE (как чистый PostgreSQL до недавних версий или старые версии Spark SQL), третью часть логики часто выносят в отдельный простой UPDATE после MERGE. Однако современные облачные хранилища (Snowflake, Databricks Delta, BigQuery) поддерживают этот синтаксис полностью.
Что произошло после выполнения?
Давайте посмотрим на таблицу customer_features:
| customer_id | total_spent | last_active | days_since_last_active | status | Комментарий |
| 1 (Вася) | 150.00 | 2023-10-02 | 0 | active | Был 100, добавили 50. Счетчик сброшен. (MATCHED) |
| 2 (Петя) | 500.00 | 2023-09-25 | 7 | active | Не было в источнике. Счетчик вырос 6 -> 7. (NOT MATCHED BY SOURCE) |
| 3 (Маша) | 200.00 | 2023-10-02 | 0 | new | Вставлена новая запись. (NOT MATCHED) |
Почему это круто для ML? Мы только что одним запросом обновили фичи для трех разных групп пользователей. Нам не пришлось выгружать данные в Python, делать pd.merge, пересчитывать столбцы и заливать обратно. База данных сделала это сама, используя оптимизированные алгоритмы Join’а и блокировок.
Коротко об операторе MERGE
Оператор MERGE должен стать вашим лучшим другом при подготовке данных для машинного обучения. Вот почему:
- Чистота кода. Вместо «спагетти-кода» из кучи SELECT, IF, UPDATE и INSERT, вы получаете одну декларативную конструкцию. Вы говорите базе, что вы хотите получить, а не как это делать пошагово.
- Производительность. СУБД читает данные источника и цели всего один раз (в идеальном случае). При работе с миллионами строк (что для ML норма) это дает колоссальный прирост скорости по сравнению с построчной обработкой.
- Целостность данных. Все изменения происходят атомарно. Вы не получите ситуацию, когда фичи пользователя обновились наполовину, исказив предсказания модели.
- Гибкость. Возможность обрабатывать случаи, когда данных нет в источнике (NOT MATCHED BY SOURCE), позволяет легко реализовывать логику устаревания данных (TTL) или подсчета дней неактивности прямо внутри базы.
Совет напоследок: Хотя MERGE — мощный инструмент, помните про индексы. Чтобы слияние работало быстро, поле, по которому вы соединяете таблицы (в нашем примере customer_id), обязательно должно быть проиндексировано и в источнике, и в цели. Иначе база данных свалится в полный перебор (Full Table Scan), и магия исчезнет.
Надеюсь, эта статья поможет вам наводить порядок в ваших данных быстрее и элегантнее. Пишите чистый SQL, тренируйте точные модели — и до встречи в новых статьях!