


SQL (Structured Query Language) — это язык запросов, с помощью которого можно управлять данными в реляционных базах данных (БД). SQL-запросы состоят из операторов — специальных символов или ключевых слов, которые формируют команды. Разберемся, из чего состоят запросы SQL и как их писать.
Базовые операторы

Перед изучением структуры SQL-запроса и команд познакомимся с операторами сравнения, арифметическими и логическими операторами, которые понадобятся для работы с запросами.
Операторы сравнения
Арифметические операторы
Логические операторы AND, OR и NOT
AND возвращает TRUE, если оба условия истинны, иначе — FALSE. В некоторых реализациях SQL (например, PostgreSQL) можно использовать ||.
OR возвращает TRUE, если хотя бы одно из условий истинно, иначе — FALSE. В PostgreSQL допускается обозначение ~.
NOT — инвертирует значение условия (делает истинное значение ложным и наоборот).
Структура SQL-запроса
Запрос должен быть правильно сформулирован, чтобы система управления базами данных (СУБД) смогла его обработать.
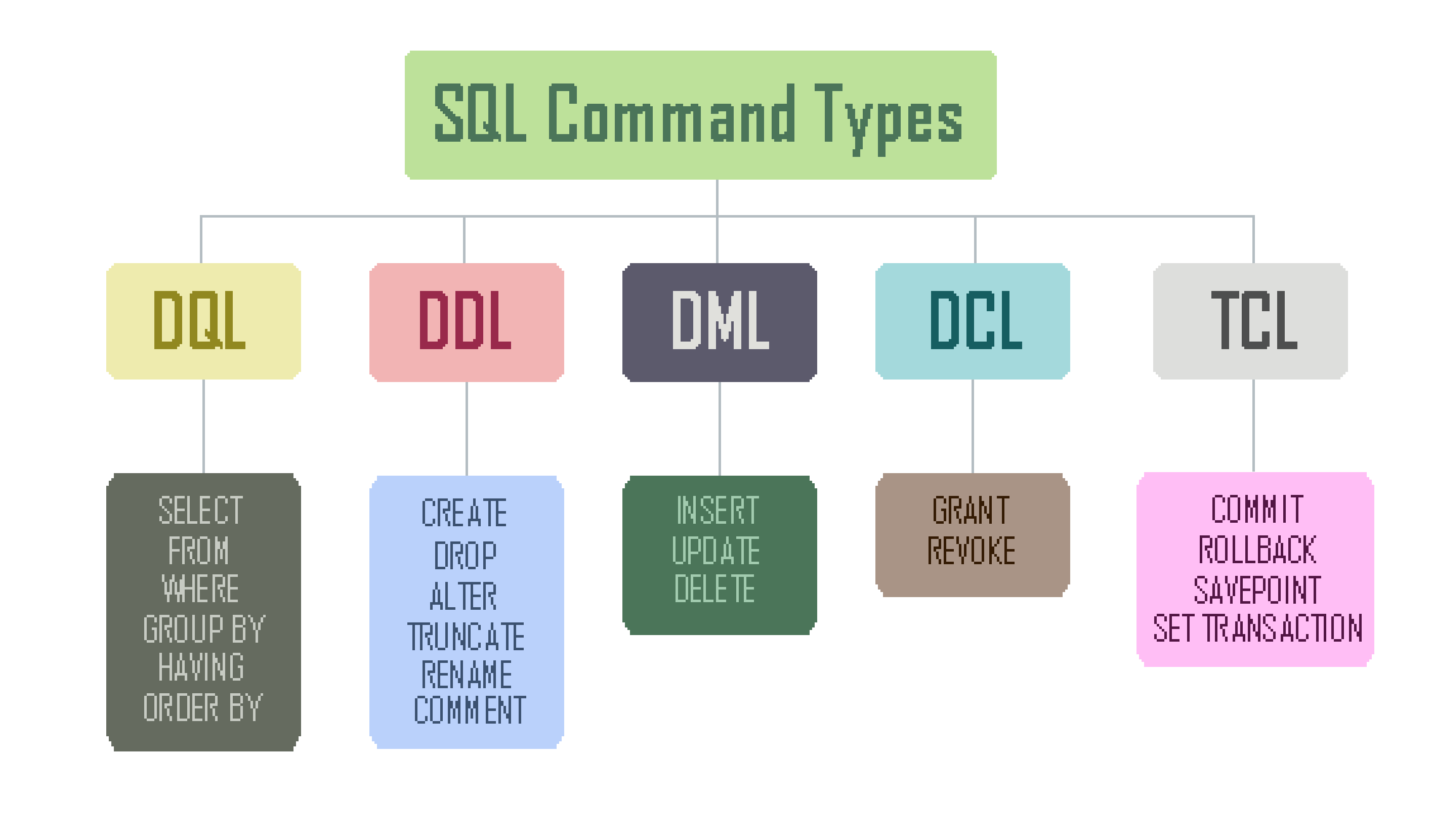
Для этого используют структуру SQL-запроса, которая состоит из обязательных операторов — SELECT и FROM, а также опциональных: WHERE, GROUP BY, HAVING и ORDER BY. Эти операторы относятся к категории команд Data Query Language (DQL).
Для запросов SQL не критично, написаны они в одну строку или в столбик. Главное, чтобы запрос был корректным. Однако для повышения читаемости длинные запросы целесообразно форматировать в столбик.
Категории команд в SQL
Data Query Language (DQL) — язык запросов
Операторы этой категории используются для извлечения данных из БД, их сортировки и группировки.
Если баз данных несколько, а для работы нужна конкретная БД, используется оператор USE:
USE database_name;
Запрос установит БД database_name в качестве активной. Все последующие запросы SQL будут выполнены для нее.
SELECT и FROM
Являются основными и обязательными компонентами SQL-запроса для извлечения данных. Они работают в паре, где SELECT определяет, какие столбцы с данными нужно извлечь, а FROM указывает, из какой таблицы взять эти данные.
SELECT column1, column2, ... FROM table_name;
где:
column1, column2, … — названия столбцов, которые нужно извлечь (можно использовать * для выбора всех столбцов);
table_name — имя таблицы, из которой нужно извлечь данные.
- Запрос для извлечения всех данных из таблицы:
SELECT * FROM employees;
- Запрос для извлечения определенных столбцов из таблицы:
SELECT first_name, last_name, email FROM employees;
SQL-агрегатные функции (COUNT, SUM, AVG, MAX, MIN)
Используются для выполнения вычислений над наборами значений и возвращения единственного результирующего значения.
COUNT вычисляет количество строк в результирующем наборе данных.
- Вернуть количество строк в таблице:
SELECT COUNT(*) FROM table_name;
SUM вычисляет сумму значений в указанном столбце.
- Вернуть общую сумму зарплат всех сотрудников:
SELECT SUM(salary) FROM employees;
AVG вычисляет среднее значение из указанного столбца.
- Вернуть средний возраст работников:
SELECT AVG(age) FROM employees;
MAX возвращает максимальное значение из указанного столбца.
- Вернуть максимальную цену из всех продуктов:
SELECT MAX(price) FROM products;
MIN возвращает минимальное значение из указанного столбца.
- Вернуть минимальное количество товаров в наличии:
SELECT MIN(stock) FROM inventory;
Оператор AS
Задает более читабельный псевдоним столбцу или таблице.
- Присваиваем псевдоним для результата функции:
SELECT SUM(salary) AS total_salary FROM employees;
где:
SUM(salary) — агрегатная функция, которая вычисляет общую сумму значений в столбце salary;
AS total_salary задает псевдоним total_salary результату функции SUM.
WHERE
Этот оператор определяет, над какими данными будут производиться операции. Условия выбора целевых данных должны быть прописаны в предикатах — выражениях, которые оценивают значения как TRUE, FALSE или UNKNOWN.
SELECT column1, column2, ... FROM table_nameWHERE condition;
где:
condition — условие (предикат), которому должны соответствовать данные.
- Например, так можно реализовать запрос на выборку сотрудников с зарплатой выше 50 000:
SELECT first_name, last_name, salary FROM employees WHERE salary > 50000;
Логические операторы BETWEEN, LIKE, IN, IS NULL
BETWEEN
Нужен для выбора значений в пределах заданного диапазона.
- Выборка всех сотрудников с зарплатой в диапазоне от 50 000 до 80 000:
SELECT first_name, last_name, salary FROM employees WHERE salary BETWEEN 50000 AND 80000;
LIKE
Используется для сопоставления строк с шаблоном при использовании специальных символов (например, % для любого количества символов и _ для одного символа).
- Выборка всех клиентов, у которых имя начинается с буквы «A»:
SELECT first_name, last_name FROM customers WHERE first_name LIKE 'A%';
IN
Используется для сравнения значения с набором значений, перечисленных в списке.
- Выборка всех продуктов из категорий «Электроника» и «Одежда»:
SELECT product_name, category
FROM products
WHERE category IN ('Electronics', 'Clothing');
IS NULL
Нужен для выбора строк, в которых отсутствует значение столбца (является NULL).
- Выборка всех клиентов, у которых не заполнен номер телефона:
SELECT first_name, last_name FROM customers WHERE phone_number IS NULL;
GROUP BY
Оператор для группировки строк по значениям определенных столбцов. Это позволяет применять агрегатные функции к каждой группе отдельно.
SELECT column1, column2, ..., aggregate_function(column) FROM table_name GROUP BY column1, column2, ...;
где:
column1, column2, … — столбцы, по которым нужно сгруппировать данные;
aggregate_function(column) — агрегатная функция, применяемая к столбцам для каждой группы.
- Найти общее количество продуктов в каждой категории:
SELECT category, COUNT(*) AS product_count FROM products GROUP BY category;
- Вычислить общую сумму продаж для каждого месяца:
SELECT MONTH(sale_date) AS month, SUM(sale_amount) AS total_sales FROM sales GROUP BY MONTH(sale_date);

HAVING
Применяют для фильтрации результатов запроса, которые были сгруппированы с использованием оператора GROUP BY.
SELECT column1, column2, ..., aggregate_function(column) FROM table_nameGROUP BY column1, column2, ... HAVING condition;
где:
condition — условие, которому должны соответствовать результаты после применения агрегатных функций.
- Выборка категорий продуктов, среднее количество которых превышает 50:
SELECT category, AVG(quantity) AS avg_quantity FROM products GROUP BY category HAVING AVG(quantity) > 50;
- Выборка клиентов, у которых стоимость среднего заказа выше 1000:
SELECT customer_id, AVG(order_amount) AS avg_order_amount FROM orders GROUP BY customer_id HAVING AVG(order_amount) > 1000;
ORDER BY
Он позволяет упорядочить вывод данных в определенном порядке — отсортировать по одному или нескольким столбцам.
SELECT column1, column2, ... FROM table_name ORDER BY column1 [ASC], column2 [ASC], ...;
где:
ASC (или DESC) — необязательное ключевое слово, которое определяет порядок сортировки. По умолчанию используется ASC (порядок возрастания), но можно указать DESC (порядок убывания).
- Сортировка заказов по дате в порядке убывания:
SELECT order_id, order_date, customer_id FROM orders ORDER BY order_date DESC;
Ограничительные конструкции LIMIT и OFFSET
Эти операторы нужны для ограничения количества строк, возвращаемых запросом.
LIMIT
Определяет количество строк, которые нужно вернуть. Если оно равно нулю, запрос возвращает пустой набор результатов.
SELECT column1, column2, ... FROM table_nameLIMIT number_of_rows;
где:
number_of_rows — количество строк, которые нужно вернуть. Если значение равно нулю, запрос вернет пустой набор результатов.
OFFSET
Указывает, сколько строк нужно пропустить перед возвратом результата. Если не определять OFFSET, запрос возвращает данные, начиная с первой строки, указанной в SELECT.
SELECT column1, column2, ... FROM table_name OFFSET number_of_rows_to_skip;
где:
number_of_rows_to_skip — количество строк, которые нужно пропустить перед возвратом результата.
Операторы LIMIT и OFFSET лучше всего использовать вместе с ORDER BY. Это упорядочит возвращаемый результат.
Data Definition Language (DDL) — язык определения данных
Эти команды используются для определения и управления структурой БД и их объектов, таких как таблицы, индексы и т. д.
CREATE
Используется для создания БД и ее объектов.
CREATE DATABASE — создание БД.
CREATE DATABASE my_database;
CREATE TABLE — создание таблицы.
CREATE TABLE employees ( employee_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50), hire_date DATE );
где:
name VARCHAR(50) создает столбец с именем name, который будет содержать строковые значения (VARCHAR) длиной не более 50 символов;
date DATE создает столбец с именем date, который будет содержать даты.
CREATE INDEX — создание индекса.
Присвоение индекса одному или нескольким столбцам ускоряет поиск данных.
CREATE INDEX idx_last_name ON employees(last_name);
Оператор ON указывает на то, что индекс будет создан на столбце last_name таблицы last_name.
CREATE VIEW — создание представления.
Представление (view) — это виртуальная таблица, основанная на результате запроса. Представления не хранят данные самостоятельно, они определяются SQL-запросами, которые извлекают данные из одной или нескольких таблиц.
CREATE VIEW employee_view AS SELECT first_name, last_name FROM employees;
CREATE SCHEMA — создание схемы.
Схема — это контейнер для хранения объектов БД, таких как таблицы, представления и индексы, которые могут быть организованы и управляться вместе.
CREATE SCHEMA my_schema;
После создания схемы в нее можно добавлять объекты, например таблицу:
CREATE TABLE my_schema.my_table
CREATE TRIGGER — создание триггера.
Триггер — это набор инструкций SQL, который автоматически выполняется при наступлении определенного события в БД, такого как вставка, обновление или удаление записи из таблицы SQL.
CREATE TRIGGER trigger_name BEFORE INSERT ON table_name FOR EACH ROW --тело триггера (код, который будет выполнен после срабатывания триггера)
где:
BEFORE (или AFTER) — указание времени срабатывания триггера (до или после выполнения операции);
INSERT (или UPDATE, DELETE) — определение операции, до или после которой сработает триггер;
ON table_name — указание таблицы, к которой привязан триггер;
FOR EACH ROW (или STATEMENT) — условие, будет ли триггер выполняться для каждой строки (FOR EACH ROW) или для каждого оператора (FOR EACH STATEMENT). Эта часть синтаксиса может отсутствовать в некоторых СУБД.
CREATE PROCEDURE
Процедура представляет собой набор инструкций SQL, которые выполняют определенную задачу или набор задач в БД. Она может принимать параметры, обрабатывать данные и возвращать результаты.
Создание процедуры
CREATE PROCEDURE get_employee_count() BEGIN SELECT COUNT(*) FROM employees; END;
Оператор BEGIN обозначает начало транзакции (совокупности операций), а END — ее завершение.
Вызов процедуры
CALL get_employee_count();
CALL вызывает набор инструкций из процедуры или функции.
DROP
Используется для удаления объектов.
DROP TABLE my_table;
Аналогично DROP можно применять и с другими объектами, в том числе и с БД.
ALTER
Используется для изменения структуры существующих объектов БД.
ALTER TABLE my_table ADD COLUMN age INT;
Добавляем столбец (COLUMN) с именем age и форматом данных INT.
TRUNCATE
Нужен для удаления всех записей из таблицы, при этом сохранив структуру таблицы.
TRUNCATE TABLE my_table;
RENAME
Оператор для переименования объектов БД.
RENAME TABLE old_table TO new_table;
Оператор TO указывает на новое значение (новое имя или местоположение).
COMMENT
Используется для добавления комментариев к объектам БД.
COMMENT ON TABLE employees IS 'Таблица для хранения информации о сотрудниках'
Оператор IS указывает на объект команды. В данном случае — на текст, который будет являться комментарием к таблице.
Data Manipulation Language (DML) — язык манипулирования данными
Используется для работы с данными внутри таблиц. К DML относятся операторы INSERT, UPDATE и DELETE. Сюда можно также отнести SELECT и FROM, но они являются частью DQL.
INSERT
Добавляет новые строки данных в таблицу.
INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...);
где:
INTO указывает место, куда нужно поместить данные;
VALUES указывает значения, которые будут вставлены в соответствующие столбцы таблицы.
UPDATE
Обновляет существующие строки данных в таблице.
UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition;
где:
SET — оператор для присвоения значения переменной (в данном случае столбцам).
DELETE
Удаляет строки данных из таблицы.
DELETE FROM table_nameWHERE condition;
Data Control Language (DCL) — язык управления данными
Используется для управления правами доступа к данным и контролем над БД.
GRANT
Предоставляет пользователю или роли определенные привилегии на объект БД.
Роль можно создать с помощью команды CREATE ROLE role_name. Вместо того чтобы назначать привилегии отдельным пользователям, их можно назначать ролям.
GRANT SELECT, INSERT ON employees TO user1;
Пользователь user1 получает привилегии SELECT и INSERT на таблицу employees.
REVOKE
Отменяет определенные привилегии у пользователя или роли на объект БД.
REVOKE SELECT, INSERT ON employees FROM user1;
У пользователя user1 отзываются привилегии SELECT и INSERT на таблицу employees.
Transaction Control Language (TCL) — язык управления транзакциями
Он позволяет контролировать, сохранять или отменять изменения, сделанные в рамках транзакции — совокупности операций.
COMMIT
Фиксирует все изменения, сделанные в рамках текущей транзакции. После выполнения команды COMMIT все изменения становятся видимыми для других пользователей.
ROLLBACK
Отменяет все изменения, сделанные в рамках текущей транзакции, и возвращает БД в состояние, в котором она была до начала транзакции.
SAVEPOINT
Создает точку сохранения внутри транзакции, к которой можно откатиться без отката всей транзакции.
RELEASE SAVEPOINT
Удаляет ранее созданную точку сохранения. После удаления точки сохранения к ней больше нельзя откатиться.
SET TRANSACTION
Устанавливает характеристики транзакции.
Здесь устанавливается уровень изоляции (ISOLATION LEVEL) самого высокого уровня — SERIALIZABLE. Уровни изоляции влияют на возможность других транзакций вносить изменения в те же данные.
Внешние и внутренние запросы
Внешние (основные) и внутренние запросы (подзапросы) позволяют выполнять один запрос внутри другого. Подзапрос выполняется первым, а его результат используется основным запросом.
SELECT name FROM employees WHERE department_id = ( SELECT id FROM departments WHERE name = 'Sales' );
Внутренний запрос (подзапрос)
SELECT id FROM departments WHERE name = 'Sales';
Этот запрос выполняется первым. Он находит id отдела, где name равно Sales. Допустим, результатом будет id = 3.
Внешний запрос
SELECT name FROM employees WHERE department_id = 3;
Внешний запрос использует результат подзапроса (id = 3) для фильтрации данных в таблице employees.
Он выбирает имена сотрудников, у которых department_id = 3.
Работа с внешними и внутренними запросами с использованием оператора EXISTS
Оператор EXISTS используется для фильтрации строк основного запроса на основе результатов подзапроса. Нужен, чтобы проверить наличие хотя бы одной строки в результате подзапроса.
SELECT name FROM customers WHERE EXISTS ( SELECT * FROM orders WHERE orders.customer_id = customers.id );
Внешний запрос выбирает имена клиентов из таблицы customers.
Подзапрос проверяет, существует ли хотя бы один заказ для каждого клиента в таблице orders, используя условие orders.customer_id = customers.id.
Если для текущего клиента найден хотя бы один заказ, подзапрос выдает строку, оператор EXISTS возвращает TRUE и включает имя клиента в итоговый результат.
Примеры использования команд SQL
Создание и удаление БД
CREATE DATABASE my_database; SHOW DATABASES; USE my_database; DROP DATABASE my_database;
Создание и управление таблицами
Создаем таблицу employees:
CREATE TABLE employees ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50), age INT, department VARCHAR(50) );
Добавляем столбец email:
ALTER TABLE employees ADD COLUMN email VARCHAR(100);
Изменяем тип столбца (MODIFY COLUMN) на INT:
ALTER TABLE employees MODIFY COLUMN age INT UNSIGNED;
UNSIGNED — оператор для указания того, что числовой тип данных не может содержать отрицательные значения.
Ограничение целостности
Операции ограничения целостности применяются для обеспечения точности и надежности данных в таблице.
Создаем структуру таблицы для хранения информации о заказах в БД.
CREATE TABLE orders ( id INT AUTO_INCREMENT PRIMARY KEY, product_id INT, quantity INT, FOREIGN KEY (product_id) REFERENCES products(id), CHECK (quantity > 0) ); id INT AUTO_INCREMENT PRIMARY KEY
Создает столбец id типа INT, который будет автоматически увеличиваться для каждой новой записи. Он также определяется как первичный ключ (PRIMARY KEY), что гарантирует уникальность каждой записи в таблице.
product_id INT
Создает столбец product_id типа INT, который будет содержать идентификатор продукта, связанного с данным заказом.
quantity INT
Создает столбец quantity типа INT, который будет содержать количество продуктов в заказе.
FOREIGN KEY (product_id) REFERENCES products(id)
Устанавливает ограничение внешнего ключа (FOREIGN KEY) на столбец product_id, который ссылается на столбец id в таблице products. Это гарантирует целостность данных: значение product_id в таблице orders будет соответствовать существующему id в таблице products.
CHECK (quantity > 0)
Устанавливает условие проверки (CHECK), которое гарантирует, что значение в столбце quantity всегда будет больше нуля. Это запретит добавление записей с некорректными значениями количества продуктов.
