


Мы тратим недели на сбор данных, часы на обучение моделей и бессонные ночи на отладку кода. Наконец, наш проект — классификатор котиков и собачек, система рекомендаций для фильмов или даже предсказатель цен на недвижимость — готов. Мы с гордостью заливаем его на GitHub, чтобы показать миру, и… тишина. Никто не ставит звездочки, не пишет комментарии, а на собеседовании рекрутер, кажется, даже не открывал ссылку.
В чем же дело? Часто ответ прост и лежит на самой поверхности. В вашем репозитории нет хорошего файла README.md.
Вы можете создать самую гениальную нейронную сеть, но, если никто не сможет понять, что она делает и как ее запустить, для всего остального мира она — просто набор непонятных файлов. Сегодня мы исправим это. Я научу вас создавать README, который станет визитной карточкой вашего проекта, привлечет внимание и докажет, что вы — не просто кодер, а вдумчивый профессионал.
Что такое README-файл и зачем он нужен
Представьте, что вы купили сложный и дорогой конструктор LEGO. Вы открываете коробку, а там… просто гора деталей. Ни инструкции, ни картинки того, что должно получиться. Каковы ваши шансы собрать из этого звездолет «Тысячелетний сокол»? Скорее всего, вы просто закроете коробку и уберете ее подальше.

Код в вашем GitHub-репозитории — это те самые детали. А файл README.md — это одновременно и картинка на коробке, и пошаговая инструкция по сборке.
README.md — это специальный файл в формате Markdown, который GitHub автоматически отображает на главной странице вашего репозитория. Это первое, что видит любой посетитель, будь то ваш коллега, потенциальный работодатель или случайный программист, ищущий решение своей проблемы.
Markdown (.md) — это простой язык разметки, который позволяет форматировать текст (делать его жирным, курсивом, добавлять заголовки, списки, картинки и ссылки), не используя сложные редакторы. Это стандарт де-факто для документации в мире разработки.
Так зачем же на него тратить время? Причин несколько, и каждая из них критически важна.
- Для себя в будущем. Это самая недооцененная причина. Поверьте моему опыту: через полгода вы откроете свой же проект и не сможете вспомнить, как его запустить. Какую версию Python вы использовали? Какие библиотеки нужно установить? Как назывался главный скрипт? Хороший README — это записка самому себе в будущее, которая сэкономит вам часы мучительных воспоминаний.
- Для рекрутеров и тимлидов. Когда вы отправляете свое резюме, ссылка на GitHub — это ваше портфолио. Рекрутер или технический специалист, который его просматривает, не будет скачивать ваш код и разбираться в нем часами. Он откроет репозиторий, пробежится глазами по README за 30 секунд и сделает вывод о вашем профессионализме. Понятный, структурированный README показывает, что вы умеете документировать свою работу, мыслить системно и заботитесь о тех, кто будет работать с вашим кодом. Это огромный плюс.
- Для сообщества. Если вы создаете опенсорс-инструмент или просто делитесь полезным кодом, ваша цель — чтобы люди им пользовались. Без понятной инструкции по установке и использованию 99% посетителей просто уйдут. Хороший README — это проявление уважения к времени других людей и ключ к тому, чтобы ваш проект стал популярным и полезным.
Итак, README — это не формальность, а мощнейший инструмент коммуникации. Давайте научимся им пользоваться.
Основные элементы качественного README-файла
Хороший README, как и хороший код, имеет структуру. Это не поток сознания, а четко организованный документ. Вот обязательные блоки, которые должны быть в каждом вашем ML-проекте.
Название проекта и краткое описание (Elevator Pitch)
Сразу под названием должны идти один-два абзаца, которые мгновенно отвечают на вопрос: «Что это такое и какую проблему оно решает?» Избегайте общих фраз.
- Плохо: «Проект по машинному обучению».
- Хорошо: «Этот репозиторий содержит код для модели классификации изображений на PyTorch, которая способна с точностью 95% отличать рентгеновские снимки легких с пневмонией от здоровых».
Визуальная демонстрация (если применимо)
Картинка или GIF-анимация стоит тысячи слов. Если ваш проект что-то генерирует (картинки, текст) или имеет интерфейс, обязательно вставьте скриншот или гифку, показывающую результат работы. Для модели, распознающей объекты, покажите фото с наложенными рамками. Для системы рекомендаций — скриншот с примером выдачи.
Установка (Installation)
Самый важный практический блок. Человек, который хочет попробовать ваш код, должен иметь возможность сделать это максимально безболезненно.
- Клонирование репозитория:
- git clone https://github.com/your-username/your-project.git
cd your-project
- Создание виртуального окружения (лучшая практика!):
- python -m venv venv
source venv/bin/activate # Для Windows: venv\Scripts\activate
- Установка зависимостей:
- pip install -r requirements.txt
- Обязательно приложите к проекту файл requirements.txt, который можно легко создать командой pip freeze > requirements.txt.
Использование (Usage)
Итак, мы все установили. Что дальше? Дайте четкие, копируемые команды для запуска основных сценариев.
- Обучение модели:
python train.py —data_path data/train —epochs 10 —learning_rate 0.001
- Предсказание на новых данных:
python predict.py —model_path models/best_model.pth —image_path assets/test_image.jpg
Поясните, что означает каждый флаг (—data_path, —epochs и т.д.).
Структура проекта
Этот раздел помогает быстро сориентироваться в вашем коде. Не нужно описывать каждый файл, достаточно показать основную структуру папок и их назначение. Здесь отлично помогают диаграммы!
Например, с помощью Mermaid можно сделать вот такую наглядную схему:
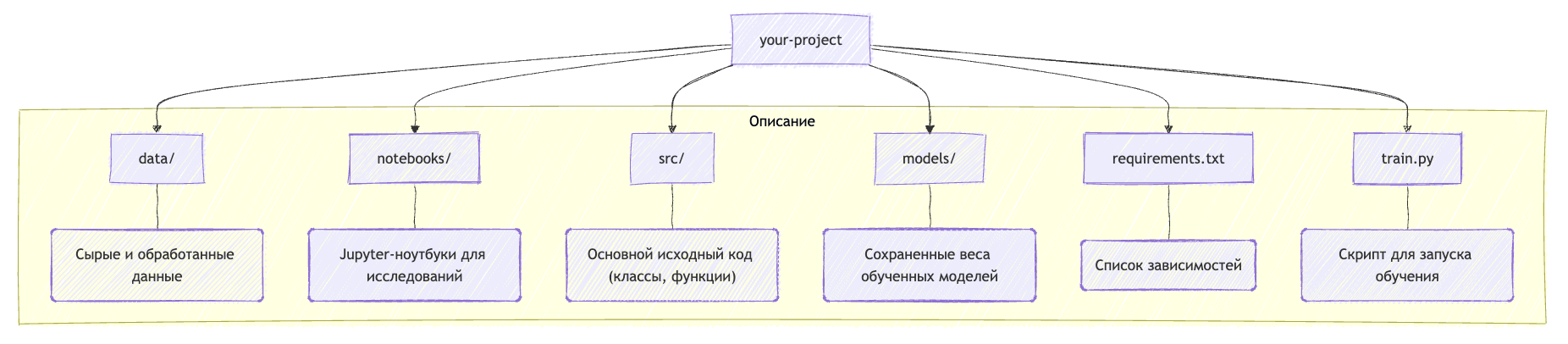
Данные (Data)
Для любого ML-проекта это критически важный раздел.
- Источник: откуда взяты данные? Дайте ссылку (Kaggle, UCI и т.д.).
- Описание: что из себя представляют данные? Сколько в них объектов, какие признаки?
- Получение: если данные нужно скачивать отдельно, дайте инструкцию или скрипт для их загрузки.
Лицензия (License)
Даже если вам кажется, что ваш проект никому не нужен, лицензия — это важно. Она определяет, как другие люди могут использовать ваш код. Самая простая и популярная — MIT License. Она позволяет делать с вашим кодом практически все что угодно, требуя лишь упоминания авторства. Просто добавьте в репозиторий файл LICENSE с текстом лицензии MIT.

Сравнение хорошего и плохого README
Давайте на игрушечном примере «Классификатор спама в SMS» посмотрим разницу.
Пример 1: плохой Readme
# Spam-Classifier Мой проект для классификации спама.
Что не так?
- Нет описания, какую проблему решаем.
- Непонятно, как установить зависимости.
- Неясно, как запустить код.
- Нет информации о данных.
- Я открою такой репозиторий и через пять секунд закрою.
Пример 2: хороший Readme
# Классификатор спама в SMS на основе TF-IDF и Logistic Regression Этот проект представляет собой простую модель машинного обучения для классификации SMS-сообщений на "спам" и "не спам" (ham). Модель использует векторизацию текста с помощью TF-IDF и логистическую регрессию из библиотеки Scikit-learn. Точность на тестовом наборе данных составляет ~97%. ## Установка 1. Клонируйте репозиторий: ```bash git clone https://github.com/your-username/spam-classifier.git cd spam-classifier ``` 2. Создайте и активируйте виртуальное окружение: ```bash python -m venv venv source venv/bin/activate ``` 3. Установите необходимые библиотеки: ```bash pip install -r requirements.txt ``` ## Использование ### Обучение модели Для обучения модели на данных из `data/spam.csv` и сохранения ее в файл `models/model.joblib` запустите: ```bash python train.py ``` ### Предсказание для нового сообщения Чтобы классифицировать новое сообщение, используйте скрипт `predict.py`: ```bash python predict.py --message "Congratulations! You've won a $1000 gift card. Click here to claim." ``` **Ожидаемый вывод:** ``` Сообщение: "Congratulations! You've won a $1000 gift card. Click here to claim." Вердикт: spam ``` ## Структура проекта - `/data/spam.csv`: Исходный датасет. - `/models/`: Папка для сохранения обученной модели. - `src/`: Вспомогательные функции для обработки текста. - `train.py`: Скрипт для обучения и оценки модели. - `predict.py`: Скрипт для предсказания на новых данных. - `requirements.txt`: Список зависимостей. ## Данные Используется публичный датасет [SMS Spam Collection](https://www.kaggle.com/datasets/uciml/sms-spam-collection-dataset) с Kaggle. Он содержит 5,574 SMS-сообщения, помеченных как "spam" или "ham". ## Лицензия Этот проект распространяется под лицензией MIT.
Что хорошо? Чувствуете разницу? Второй README отвечает на все возможные вопросы. Он уважает время читателя и позволяет мгновенно начать работу с проектом.
Разбор реального примера: репозиторий tqdm
Давайте посмотрим на README одного из моих любимых опенсорс-проектов — библиотеки tqdm, которая делает красивые прогресс-бары. Это эталон простоты и информативности.
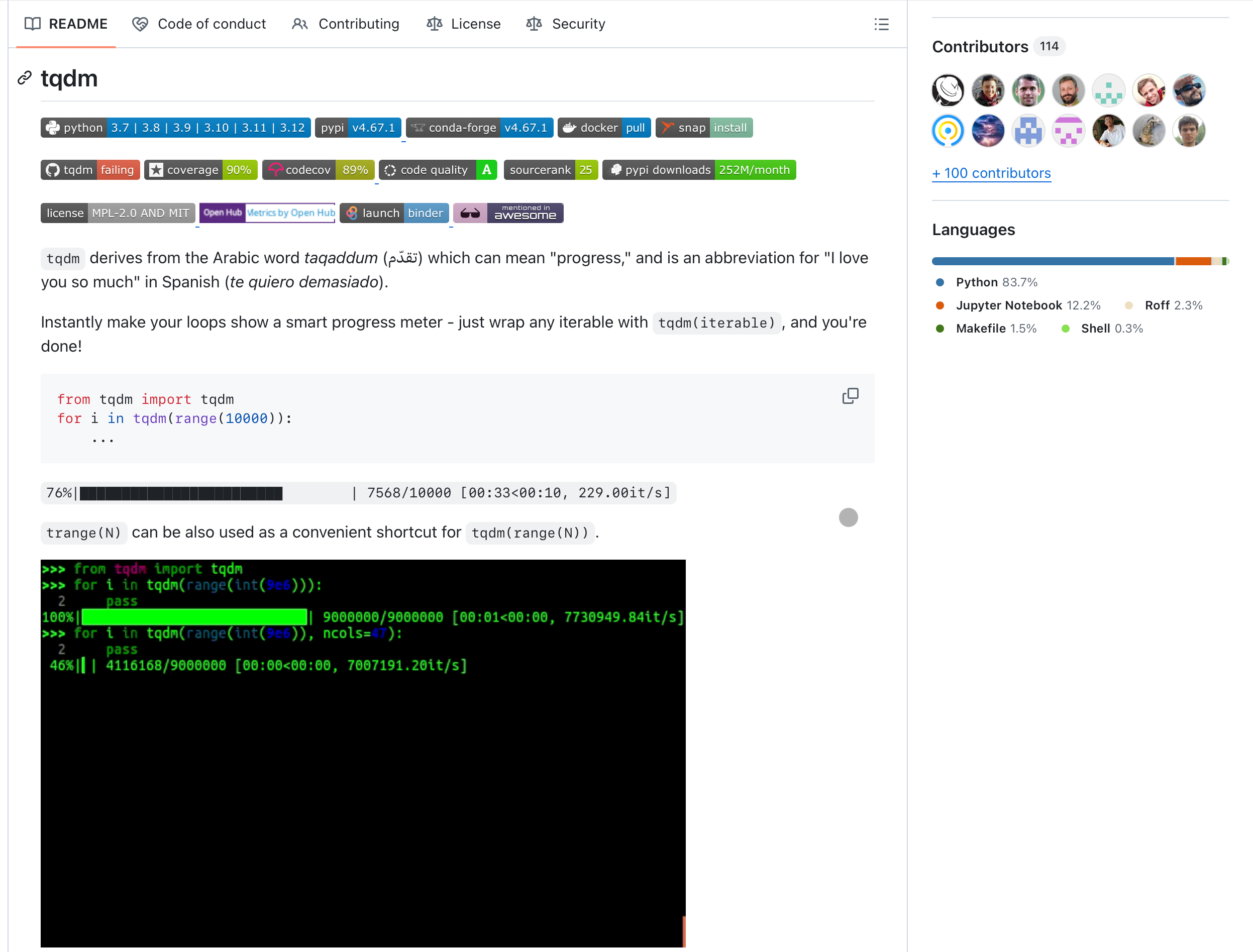
- Название и значки (Badges). Сразу под названием мы видим ряд значков: статус сборки, версия на PyPI, лицензия. Это моментально создает ощущение надежности и поддержки проекта.
- GIF-демонстрация. Первое, что бросается в глаза, — это короткая гифка, которая показывает, как выглядит прогресс-бар tqdm в действии. Вам даже не нужно читать описание, чтобы понять, что делает библиотека. Гениально!
- Краткое описание. Лаконичное объяснение, что tqdm происходит от арабского слова «такаддум» (прогресс) и что это такое.
- Установка. Одна простая команда: pip install tqdm. Ничего лишнего.
- Использование. Сразу же дан простейший, работающий пример кода, который можно скопировать и вставить. Это позволяет пользователю получить «быструю победу» и увидеть результат за секунды.
- Дальнейшие разделы. Далее идут более продвинутые примеры использования, интеграции с другими библиотеками (Pandas, Keras) и детальное описание параметров.
README tqdm — идеальный пример того, как нужно представлять свой проект: от простого к сложному, с упором на визуализацию и быстрый старт.
Коротко о README
Друзья, надеюсь, я убедил вас, что README.md — это не скучная обязаловка, а один из важнейших элементов вашего проекта.
Давайте подытожим:
- README — это лицо вашего проекта. Это первое и, часто, последнее, что увидят люди.
- Пишите для других (и для себя в будущем). Представьте, что ваш код будет читать человек, который ничего о нем не знает.
- Структура — ваш лучший друг. Используйте заголовки, списки и блоки кода, чтобы сделать информацию легко усваиваемой.
- Дайте четкие инструкции. «Как установить?» и «Как запустить?» — два главных вопроса, на которые вы должны ответить.
- Показывайте, а не только рассказывайте. Используйте скриншоты, гифки и диаграммы.
Мой вам совет: прямо сейчас откройте свой самый важный проект на GitHub. Посмотрите на него глазами новичка. Все ли понятно? Можете ли вы его установить и запустить, следуя только инструкциям из README? Если нет — потратьте час. Этот час инвестиций в документацию окупится многократно: в сэкономленном времени, в интересе со стороны коллег и, возможно, в том самом предложении о работе.
Удачного вам кодинга и понятных README!