Корпоративные системы и программы генерируют огромное количество информации: логов, записей о работе, отчетов об ошибках. Всеми этими данными нужно управлять и хранить их, чтобы они не терялись, а доступ к ним оставался удобным. Один из вариантов, как этого добиться, — использовать стек ELK.
Рассказываем, что такое ELK-стек, из каких компонентов состоит, как работает и чем заслужил популярность среди разработчиков.
Из каких компонентов состоит ELK-стек
ELK — это аббревиатура от трех названий: Elasticsearch, Logstash, Kibana. Так называются инструменты от компании Elastic, которые часто используют в связке. Тем самым образуется стек технологий, когда несколько программ работают вместе ради одной и той же задачи. Вот за что отвечает каждый из компонентов стека.
Elasticsearch. Это главная составляющая ELK-стека — программное решение, которое работает как база данных, поисковая и аналитическая система. С ее помощью выполняют несколько задач:
- ищут нужную информацию — система может быстро находить результаты в базе, даже если речь идет об огромных объемах данных;
- анализируют журналы логов — это возможно благодаря аналитическим функциям Elasticsearch;
- хранят информацию — как в NoSQL-базе данных;
- распределяют нагрузку — Elasticsearch умеет шардировать данные, то есть распределять их хранение по разным узлам так, чтобы не перегружать серверы.
Эта система — гибкая, легко масштабируется и настраивается, поддерживает JSON и другие популярные форматы. Фактически она лежит в основе всего стека, а остальные технологии дополняют ее.
Logstash. Это сервис, который называют конвейером, — он собирает информацию из источников, разделяет и передает в Elasticsearch для хранения и анализа. Чаще всего его используют, чтобы собирать логи различных систем и сервисов. Logstash выполняет три основных операции:
- Input — получение информации из источника в исходном виде;
- Filter — фильтрация и парсинг данных, приведение их к единому формату по заданным параметрам;
- Output — отправка отфильтрованных данных дальше, как правило, в хранилище Elasticsearch.

Есть простые системы, где Logstash не используют, а информацию передают напрямую. Но такой подход работает, только если объем данных относительно небольшой. Если система распределенная и информация в ней разнородная, без предварительной подготовки данных не обойтись.
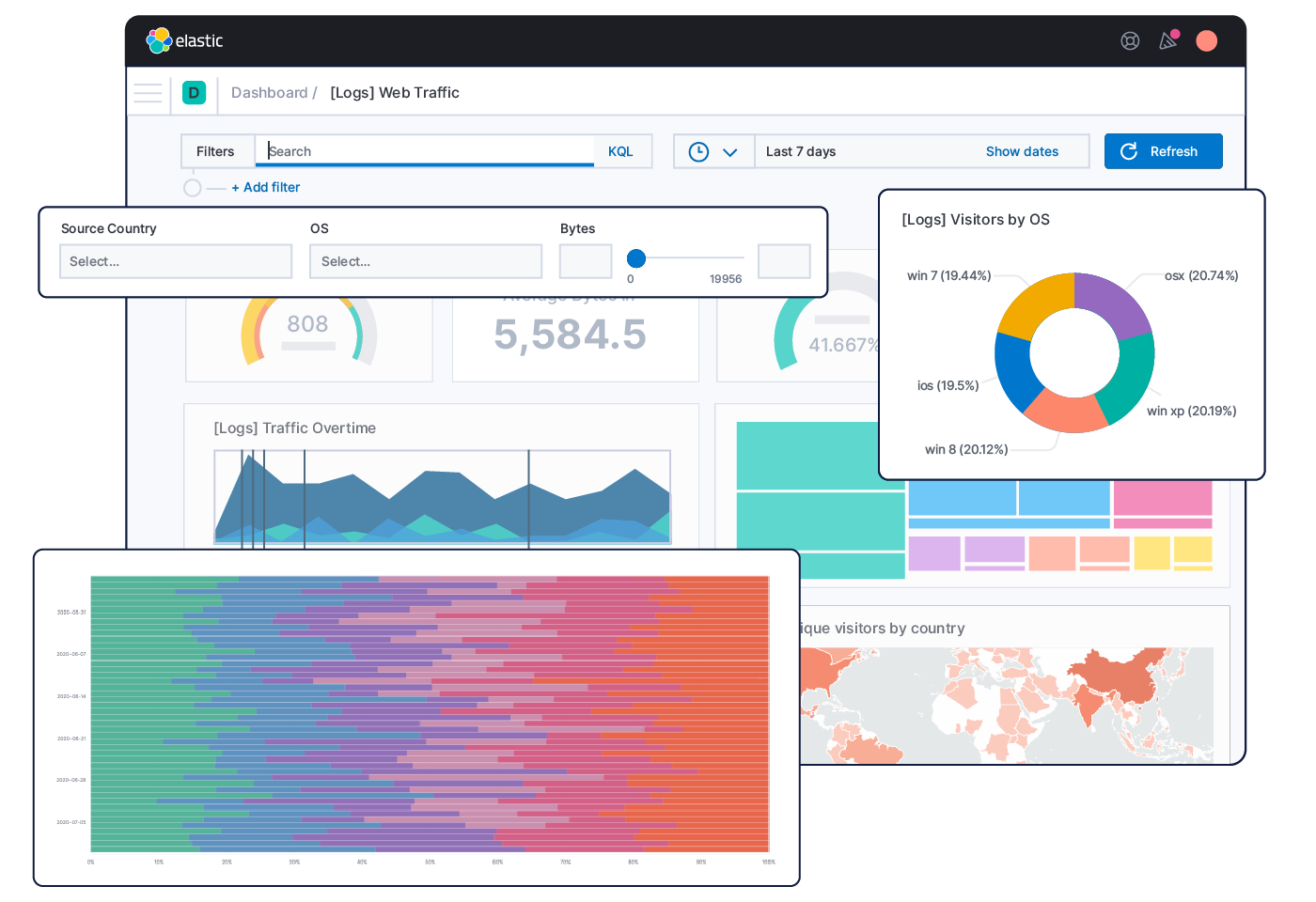
Kibana. Эта система — фактически интерфейс для пользователя, чтобы работать с информацией было удобнее. Она показывает собранные логи на одной странице, визуализирует данные, формирует отчеты и дашборды. Сама по себе она не собирает информацию — только показывает ее так, чтобы человеку было комфортнее ориентироваться.
Beats. Это опциональный компонент — его используют не всегда, поэтому не упоминают в названии стека. Фактически это несколько агентов, в названии каждого из которых есть слово beat. Они подключаются к исходным источникам данных: серверам, приложениям, процессам — и собирают информацию, которую отправляют в Logstash или сразу в Elasticsearch. Вот несколько примеров таких утилит:
- Filebeat — отвечает за текстовые файлы логов;
- Metricbeat — сообщает о системных метриках вроде нагрузки на процессор;
- Winlogbeat — собирает системные логи событий в Windows;
- Auditbeat — собирает сведения о безопасности системы.
Некоторые определения называют стек с использованием Beats расширенной версией ELK-стека, или полноценным elastic stack. Но часто эти названия используют как взаимозаменяемые синонимы.
Как работает стек ELK
Мониторинг с ELK-стеком можно представить как последовательность. Данные сначала попадают в одну из систем, затем переходят в другую и используются третьей. Часто их путь изображают в виде схемы: она показывает, что делает каждый из компонентов стека.
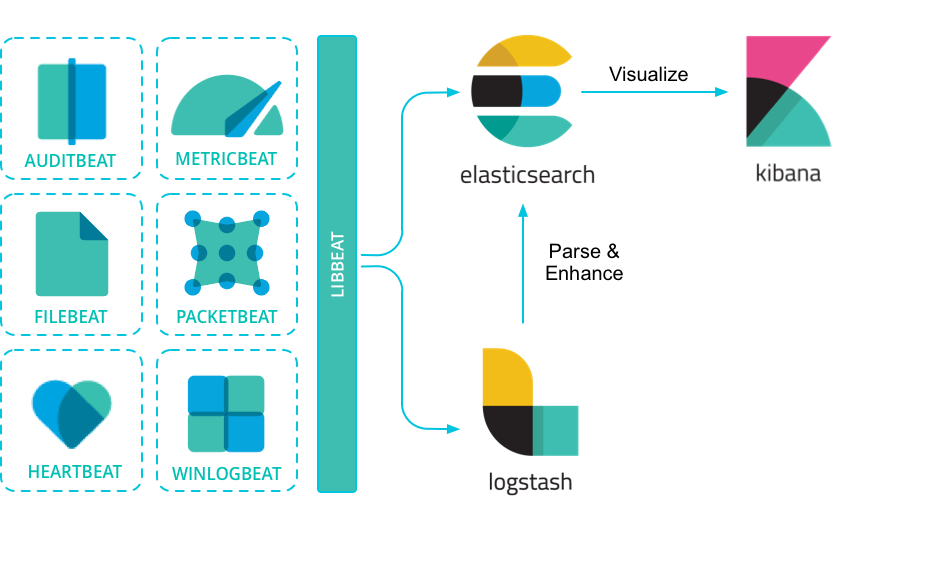
Последовательно работа с данными выглядит так.
- Различные приложения и системы генерируют логи — записи о событиях, отчеты об ошибках, информацию о своем состоянии и так далее. Некоторые сами пишут логи о своей работе. За других это делают подключенные к ним Beats, которые периодически запрашивают нужную информацию.
- Beats передают собранные логи в другие компоненты системы. Обычно — в Logstash, чтобы преобразовать и привести к единому виду, более понятному для восприятия. Если преобразование не нужно — данные сразу передают в Elasticsearch.
- Logstash получает от Beats «сырые» логи различных систем и парсит их — выделяет важную информацию, фильтрует по параметрам, которые ему задали. Так логи становятся более понятными для восприятия, и после обработки Logstash отправляет их в Elasticsearch.
- Elasticsearch в свою очередь получает данные из Logstash — или сразу из Beats, если их передали в исходном виде. Движок распределяет их внутри хранилища, анализирует и позволяет проводить по ним поиск. Внутри базы Elasticsearch разработчик может найти любые данные, которые туда передали.
- К Elasticsearch подключена Kibana: она помогает визуализировать данные и представить их в удобном формате. Например, в виде графиков, дашбордов или таблиц. Она предоставляет интерфейс, с помощью которого можно удобно перемещаться по базе Elasticsearch.
Зачем все это нужно разработчику
При разработке, отладке, развертывании и поддержке любой программы важно иметь доступ к логам. Ведь именно благодаря им и системным сообщениям можно:
- обнаружить источник проблемы или бага;
- найти узкие места, которые снижают производительность всей системы;
- проверить, точно ли приложение работает как надо;
- отследить какие-то системные параметры, важные для корректной работы, и так далее.
Если не использовать системы для хранения логов — их легко потерять или забыть. Более того, чтобы прочитать сообщения от нескольких приложений, нужно заходить в несколько файлов, которые расположены в разных местах. Это попросту неудобно. Чтобы облегчить жизнь разработчикам и аналитикам, и существуют системы, которые собирают все в одном месте.
Для маленьких систем порой достаточно какого-то одного инструмента для сбора и хранения логов. Но в корпоративных системах данных обычно очень много. Даже одно приложение может генерировать немало логов, а когда таких приложений десятки, а то и сотни, — ситуация осложняется.
Чем больше данных, тем сложнее их хранить — и тем более мощные решения нужны для работы с ними. Именно поэтому в крупных системах используют ELK-стек или другие похожие сочетания систем и утилит.

Преимущества стека ELK
Комбинация систем от производителя Elastic — довольно распространенное решение для логирования. ELK имеет несколько достоинств, благодаря которым его удобно использовать в корпоративных системах. Вот что это за достоинства.
Open source. Все системы в стеке имеют открытый исходный код. Это значит, что при необходимости можно изменить их изнутри и адаптировать под свою систему. Для этого не нужно получать разрешение вендора, то есть производителя системы, или запрашивать решение у него. Кроме того, если размещать системы на собственных серверах, пользоваться ими можно бесплатно.
Гибкость. Стек легко развернуть и настроить: он адаптируется под любые мощности, размеры и технические особенности системы. Управлять поисковыми фильтрами можно довольно гибко — самостоятельно выбирать, что, как и в каком формате показывать. Например, Elasticsearch поддерживает нечеткий поиск и запросы на разных языках, в том числе азиатских.
Универсальность. ELK-стек подходит для работы с различными базами данных, приложениями, серверами и другими инструментами. Фактически его можно использовать для сбора и хранения какой угодно информации в любом формате. До нее легко добраться и отобразить в удобном для себя виде.
Централизация. Разработчикам не приходится искать разрозненные логи по разным компонентам. Вся информация так или иначе приходит в Elasticsearch и отображается в Kibana: все можно посмотреть в едином интерфейсе. Например, сравнить данные по нескольким серверам из одного окна.
Недостатки ELK-стека
У каждой системы есть свои недостатки, и ELK не исключение. Обычно среди его минусов выделяют несколько основных:
- Требовательность к ресурсам. Компоненты ELK-стека написаны на Java и требуют довольно больших мощностей. Чтобы поддерживать такую систему, нужно иметь мощное железо — иначе запросы будут выполняться медленно.
- Сложность в обслуживании. ELK — довольно масштабный стек, и на его поддержку может уходить немало человеческих ресурсов. К тому же внутренний язык запросов в стеке, QueryDSL, считается не самым простым в изучении.
- Отсутствие системы ограничения доступа. В ELK по умолчанию нет возможности разграничить права доступа для разных пользователей. Elasticsearch по сути открывает доступ к базе данных для всех, кто знает пароль от нее. Такое может привести к проблемам с безопасностью: в 2019 году в Америке из-за этой особенности случилась крупная утечка банковских данных.
Это не значит, что пользоваться ELK-стеком не стоит. Просто есть задачи, для которых лучше подходят более легковесные решения. А еще есть особенности вроде доступа к базе, которые стоит учитывать при выборе системы и ее развертывании.
Как пользоваться ELK-стеком
Развернуть стек можно на собственном сервере или с помощью мощностей Elastic. Вторая опция — платная и подходит в первую очередь для крупных компаний. Так что тестировать установку и настройку ELK лучше на своем сервере. Для теста хватит обычного компьютера, лучше всего — с операционной системой семейства Linux.
Первым делом нужно установить компоненты — это можно сделать через консоль операционной системы. В документации есть инструкции для каждой из программ. Главное — выбрать правильный вариант установки, который называется self-management.
В процессе установки нужно подключиться к репозиторию Elastic. Сейчас он недоступен из России — чтобы его использовать, на сервере должен работать прокси. Второй вариант — вручную скачать нужные пакеты с сайта Elastic и переместить на свой сервер.
Коротко процесс установки выглядит так:
- Установка Beats — тех, которые понадобятся вам в конкретном проекте.
- Установка Elasticsearch — ядра, на котором строится весь стек. Нужно будет подключиться к репозиторию, скачать и установить оттуда пакет системы.
- Настройка Elasticsearch — нужно указать, откуда он будет забирать информацию, включить автозагрузку и настроить конфигурацию.
- Установка Kibana — чтобы управлять Elasticsearch через визуальный интерфейс. Ее тоже можно скачать в виде пакета из репозитория Elastic. А запустить — прямо в браузере: в качестве URL нужно указать IP-адрес сервера и порт Kibana 5601. Перед первым включением стоит учесть, что запускаться она может долго.
- Настройка Kibana — подключение к Elasticsearch и настройка безопасного соединения. Можно передавать данные напрямую или через прокси-сервер. В его роли часто используют nginx.
- Установка Logstash — чтобы парсить и модифицировать логи. Эта система устанавливается так же, как и предыдущие: с помощью пакетов из репозитория.
- Настройка конфигурации Logstash — чтобы показать, откуда получать информацию и куда ее передавать.
После этого можно настроить, какие данные будет собирать и обрабатывать система, назначить для них правила и фильтры. А затем — смотреть, что именно произошло в ваших приложениях, в интерфейсе Kibana.
Стек ELK — краткие выводы
- ELK-стек — это комбинация из нескольких инструментов от компании Elastic: поискового движка Elasticsearch, парсера логов Logstash и веб-интерфейса Kibana. Стек нужен, чтобы хранить в одном месте, быстро искать и анализировать логи и другие данные приложений.
- Обычно ELK используют в корпоративных системах, которые каждый день генерируют огромное количество информации. Стек помогает не терять данные, держать их под рукой, быстро находить нужные и использовать — например, для дебага.
- Компоненты стека имеют открытый исходный код, а развернуть их на своем сервере можно бесплатно. Кроме того, стек очень гибкий и масштабируется под любые системы и задачи.
- Среди недостатков ELK-стека выделяют ресурсоемкость и возможные сложности с безопасностью — по умолчанию там нет разграничения прав доступа. Если не озаботиться дополнительной защитой, есть риск утечки данных.