


Составили список самых важных библиотек Python для машинного обучения и рассказали, для каких задач они могут быть полезны начинающим ML-инженерам и специалистам по Data Science. Собрать подборку помог Кирилл Симонов — ML-разработчик компании IRLIX с экспертизой в компьютерном зрении.
NumPy
NumPy — библиотека для работы с математическими вычислениями, методами линейной алгебры и статистики. Ее используют не только в ML — большинство библиотек для машинного обучения опирается на ее возможности.

NumPy поддерживает множество функций для работы с числовыми данными, представленными в виде N-мерных матриц. N-мерных матрицы — это способ организации данных, который позволяет работать с числами в виде многомерных таблиц или сеток.
Этот формат удобнее и быстрее в работе, чем встроенные в Python структуры данных, такие как списки (list) и кортежи (tuple). Использование матриц повышает производительность вычислений, то есть помогает компьютеру быстрее обрабатывать большие объемы данных.
Как используется в ML
Для удобства работы табличные данные, тексты, картинки и звуки представляются в числовом виде. Если точнее, в виде специальных структур: матриц, векторов, тензоров. NumPy нужен, чтобы работать с этими структурами: видоизменять, преобразовывать, выполнять сложные математические операции.
Чаще всего NumPy применяют вместе с другими библиотеками, например TensorFlow, PyTorch, Pandas. Также она лежит в основе других инструментов для ML. В проектах NumPy часто используется как связующее звено между разными этапами обработки данных.
Пример решения задачи
Простой пример работы с NumPy — математические операции над двумерными матрицами. Код ниже рассчитывает скалярное произведение двух матриц. Это одна из базовых операций, которые используются в ML и построении нейросетей.

Pandas
Pandas — скорее библиотека для анализа данных, но ее часто используют для предварительной обработки информации перед загрузкой в ML-модель. С помощью Pandas можно выполнять разные операции с данными: считывать их, фильтровать и приводить к единому виду, собирать в единообразные структуры и готовить к загрузке в модель.
Как используется в ML
Pandas применяют для предварительной подготовки и обработки информации. Библиотека позволяет:
- быстро считывать сведения из разных источников — от Excel-документов до реляционных баз данных — где информация представлена в виде связанных таблиц;
- индексировать данные — отслеживать их по определенному признаку, соотносить и объединять их между собой;
- изучать информацию, удалять ошибки или ненужные части, изменять формат данных для загрузки в модель;
- манипулировать сложными структурами данных, используя несколько строк кода;
- работать с временными рядами (например, финансовыми котировками) и т.д.
Пример решения задачи
Загрузка и обработка данных с помощью библиотеки — относительно простая и удобная. В коде ниже Pandas помогает импортировать данные из CSV-таблицы, а затем отфильтровать и вывести информацию только о сотрудниках с зарплатой выше 50 000.

Кроме загрузки из файла, данные можно взять из структур самого Python — например, списков, словарей или многомерных массивов NumPy.

Scikit-learn
Библиотека основана на NumPy и SciPy, применяется в анализе данных и традиционном машинном обучении, которое не использует нейросети. В Scikit-learn собраны алгоритмы и инструменты для построения моделей, обработки и классификации данных, а также оценки результатов.
Как используется в ML
В крупных проектах Scikit-learn не используют из-за сложностей с оптимизацией вычислений на больших данных. Но ее применяют для быстрой проверки гипотез о данных или способах решения задачи — в библиотеке собрано огромное количество ML-алгоритмов, и протестировать идею можно в несколько строчек.
Еще библиотеку часто рекомендуют новичкам для обучения — ее довольно просто использовать, у нее понятная и подробная документация. Это хороший вариант для тех, кто хочет быстро вникнуть в теоретическую базу ML и попрактиковаться.
Пример решения задачи
В Scikit-learn много готовых функций для основных алгоритмов ML. Например, построить модель линейной регрессии, загрузить в нее данные и протестировать гипотезу с помощью библиотеки можно в три строчки кода. Для каждого из этих действий уже есть своя команда.

XGBoost / LightGBM / CatBoost
Мы объединили три библиотеки машинного обучения в один пункт, потому что они решают одинаковые задачи с помощью одного и того же инструмента — градиентного бустинга. Это техника машинного обучения, при которой результат достигается с помощью структуры из последовательно выстроенных ML-моделей. Для этого процесса нужно много ресурсов, поэтому важно, чтобы алгоритмы работали быстро и эффективно.
Три библиотеки реализуют градиентный бустинг немного по-разному. У каждой свои особенности:
- XGBoost считается одной из наиболее быстрых и производительных ML-библиотек. Она появилась раньше других и до сих пор считается основной, используется в том числе в высоконагруженных системах;
- LightGBM известен своей высокой скоростью работы и особенностью построения ML-алгоритмов деревьев решений, которые лежат в основе бустинга. Деревья решение — это метод разделения данных на меньшие подгруппы по определенному условию или критерию на каждом шаге или «узле» дерева. Также для некоторых задач LightGBM дает более точные результаты на больших объемах данных;
- CatBoost дает высокую точность при работе с категориальными данными, то есть такими, которые могут принимать ограниченное количество значений.
Как используются в ML
До развития нейросетевых технологий эти библиотеки считались State-of-the-art, то есть лучшими инструментами в своей сфере (классификации и регрессии). Сейчас их продолжают применять в продакшне — коммерческой разработке, — где они до сих пор успешно конкурируют с нейросетями.
Пример решения задачи
Так выглядит простейшая модель для решения задачи классификации, созданная с помощью XGBoost. В этом примере используется стандартный набор тестовых данных Pima Indians Dataset — он содержит информацию о разных группах пациентов и о риске диабета у них. Модель будет определять, с какой вероятностью новое значение относится к тому или иному классу — болен человек диабетом или нет.

PyTorch
Библиотека для искусственного интеллекта и нейросетей. PyTorch может строить классические архитектуры нейросетей с помощью готовых блоков, а при необходимости решать более низкоуровневые задачи, например оптимизировать вычисления на графическом процессоре GPU.
Как используется в ML
Эта библиотека считается основой для решения целой экосистемы задач: компьютерного зрения, обработки естественного языка, обучения роботов и агентов в виртуальной и реальной средах.
Пример решения задачи
С помощью PyTorch можно легко создавать простые модели нейронных сетей. Например, код ниже описывает нейросеть из двух линейных слоев с функцией активации для каждого слоя. Эта сеть классифицирует входные данные — относит или к одной, или к другой категории.

Более сложные сети моделируются с помощью классов. Внутри класса можно описать основные структурные части нейросети, а затем создать модель — объект этого класса.

TensorFlow
Это одна из самых известных библиотек для нейросетей на Python. Она представляет данные как многомерные массивы, а операции с ними — как графы, которые строятся перед запуском программы. В TensorFlow реализовано множество методов для создания, развертывания, обучения и запуска нейросетей и ML-моделей.
Как используется в ML
TensorFlow чаще всего используют для построения нейронных сетей и моделей глубокого обучения. Библиотеку применяют для классификации изображений, текстов и звуков, а также для NLP — обработки естественного языка. В последние версии TensorFlow по умолчанию включили библиотеку Keras, которая помогает создавать те же модели с меньшим количеством кода.
Кроме того, библиотека адаптирована под разные типы вычислительных платформ, включая мобильные, поэтому ее используют в кросс-платформенной разработке ML-решений.
TensorFlow часто сравнивают с PyTorch. При этом некоторые специалисты считают, что последняя лучше подходит для решения академических задач, а TensorFlow — для продакшна. Впрочем, и ту, и другую библиотеку используют в обеих отраслях. Считается, что PyTorch чуть проще в освоении, чем TensorFlow, но эксперты обычно советуют попробовать обе библиотеки и выбрать ту, которая понравится больше.

Пример решения задачи
TensorFlow ценят за высокий уровень абстракции: можно написать одну понятную команду, а не расписывать технические аспекты реализации. Благодаря этому ML-инженер может сосредоточиться на логике работы модели, а не на мелких деталях. Например, код ниже создает нейросеть, которая распознает изображения из набора данных MNIST — классического датасета с образцами написания рукописных цифр.
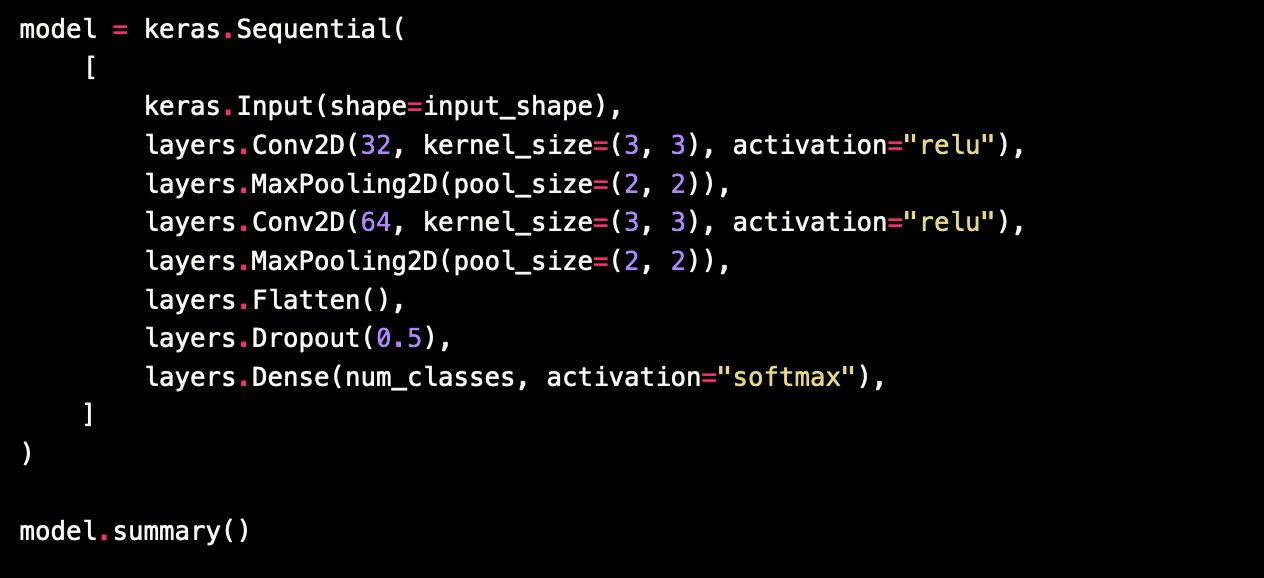
Затем остается только скомпилировать модель и обучить ее на подготовленных данных. Это тоже можно сделать парой команд, просто подставить нужные параметры. Нужно указать количество эпох, то есть полных прохождений датасета через модель, а также размер батча — «групп», на которые делится набор данных.

NLTK
Библиотека NLTK для Python специализируется на конкретной отрасли ML — обработке естественного языка. Строить свои модели с помощью NLTK не получится, но в ней есть много заранее реализованных, в том числе нейросетевых. Кроме того, библиотека содержит большое количество функций для обработки текста.
Как используется в ML
NLTK применяют для быстрой и гибкой работы с текстом: при обработке естественного языка, в компьютерной лингвистике и смежных сферах.
С помощью библиотеки проводят первичный анализ, например классифицируют текст по темам или определяют тональность. Также данные фильтруют и преобразуют в нужный формат. Кроме того, библиотека предоставляет доступ к огромным базам текстовых данных для обучения моделей.
Пример решения задачи
С помощью NLTK можно в несколько строчек удалить из текста стоп-слова. Код ниже загружает список стоп-слов для русского языка, затем разбивает введенный текст на слова и отфильтровывает — удаляет те, которые есть в стоп-списке.
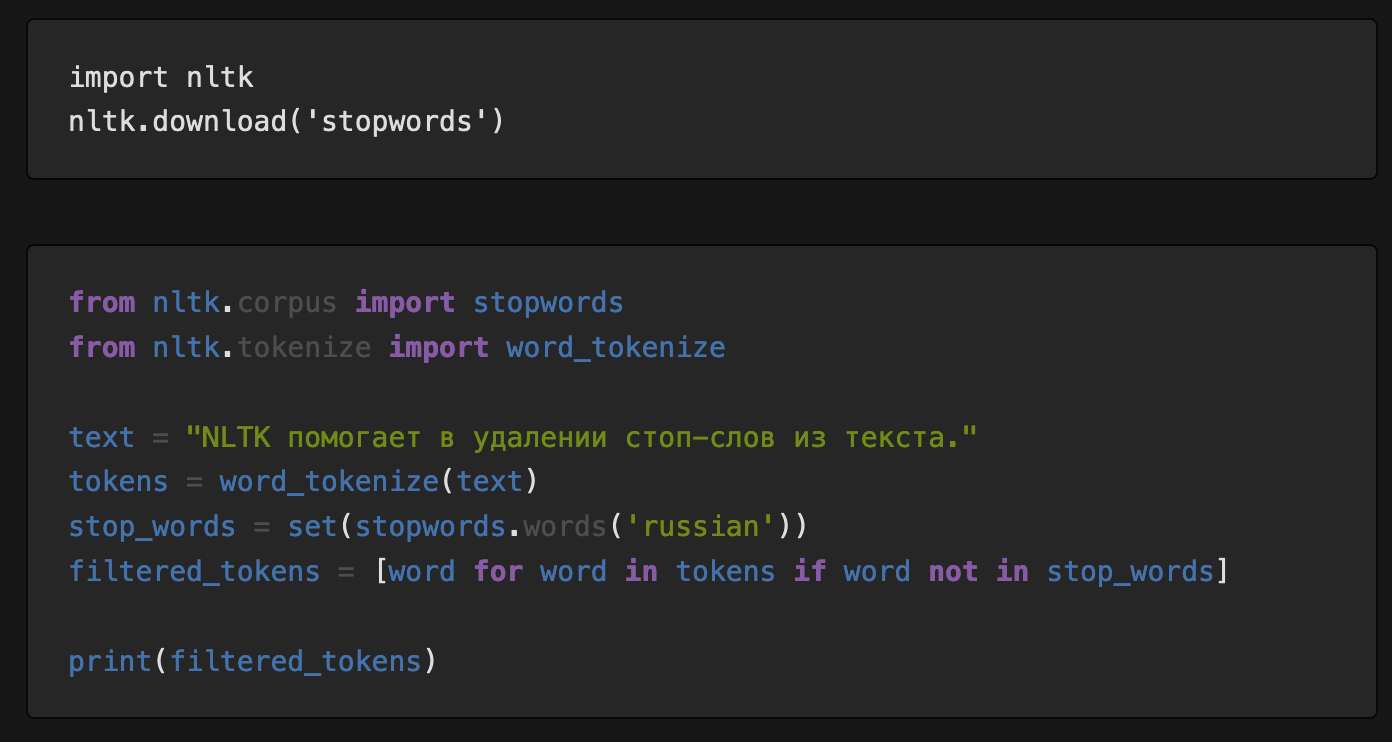
OpenCV
Закончим подборку на OpenCV — самой известной библиотеке Python для компьютерного зрения. В нее входят функции для построения моделей, инструменты обработки изображений, распознавания и выделения объектов и многое другое.
Как используется в ML
OpenCV применяют в компьютерном зрении — эта библиотека подходит для всех направлений этой сферы. Например, ее можно использовать для обработки фото и видео, создания систем распознавания лиц и сегментации сосудов на медицинских сканированиях. Также библиотека лежит в основе многих алгоритмов для робототехники — ее возможности помогают роботам «видеть» окружающий мир.
С помощью OpenCV можно преобразовывать изображения, фильтровать их элементы и отсекать ненужное, обнаруживать и извлекать объекты с заданными свойствами. Кроме работы с классическими «плоскими» двумерными изображениями, есть отдельный набор функций для калибровки камеры и работы с 3D-объектами.
Пример решения задачи
В коде ниже OpenCV в одну строчку разделяет картинку на цветовые каналы H, S и V. Остальной код — визуализация с помощью библиотеки Matplotlib.
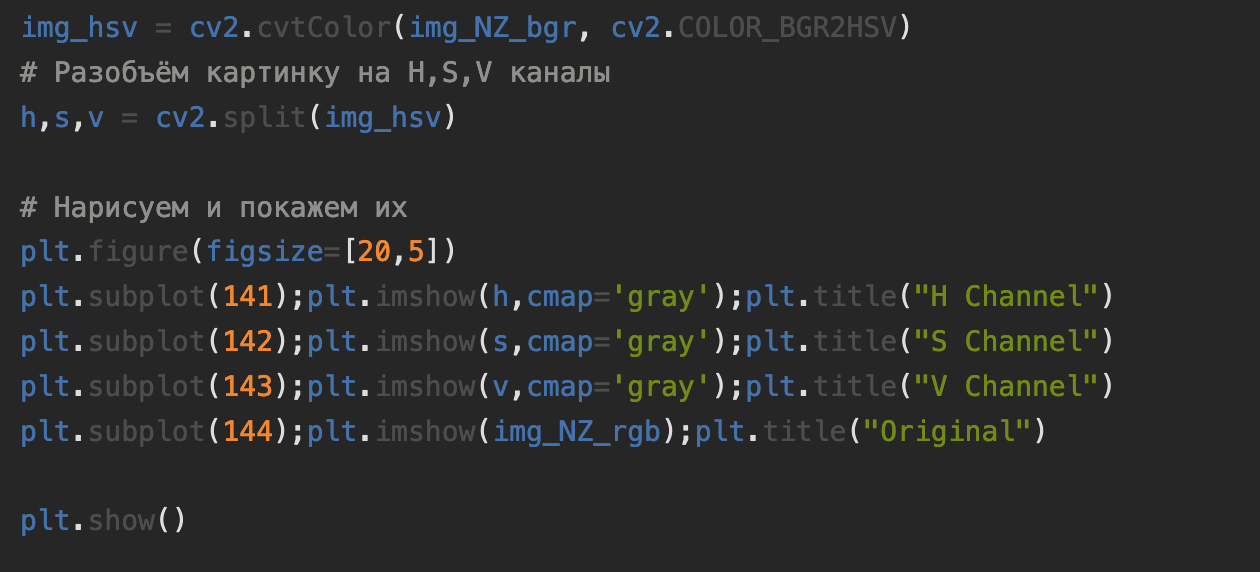
Так будет выглядеть результат. С каждым каналом можно работать по отдельности, например модифицировать интенсивность цветов, менять оттенки и так далее. И это только малая часть возможностей OpenCV.

Инструментов для ML намного больше, начиная от библиотек для построения моделей и заканчивая визуализацией. Но эта подборка поможет сделать первые шаги в освоении машинного обучения и Python.
Как изучать прикладное машинное обучение — алгоритм
- Начните с представления данных с помощью NumPy и их первичного анализа в Pandas.
- Затем проверьте гипотезы из разнообразного пула алгоритмов, реализованных в Sklearn.
- Если вам нужно использовать классические ML-подходы, близкие к SOTA, на промышленных данных (или хочется выиграть соревнование на Kaggle) — попробуйте одну из трех библиотек: Xgboost, LightGBM или Catboost. Либо переходите к нейросетевым архитектурам в PyTorch или TensorFlow.
- После этого можно выбрать конкретную специализацию, например анализ изображений с помощью OpenCV или анализ текстов в NLTK. И продолжить изучение разнообразных алгоритмов, подходов, теорий и библиотек, которые их реализуют.