

Язык Python часто применяется в Data Science, потому что, во-первых, по сравнению с другими языками код для сложных задач на Python проще и короче. А во-вторых, есть много мощных прикладных библиотек для решения разных задач: первичной обработки и анализа данных, обработки естественного языка и визуализации. Эта подборка будет полезна аналитикам данных, математикам и тем, кто занимается Data Science на разных уровнях. Составить ее нам помогли эксперты старший аналитик «Ростелеком» Константин Башевой, руководитель отдела аналитики в Mail.ru Петр Ермаков и ментор курса SkillFactory Анна Агабекян.
Библиотеки Python — это файлы с шаблонами кода. Их придумали для того, чтобы людям не приходилось каждый раз заново набирать один и тот же код: они просто открывают файл, вставляют свои данные и получают нужный результат. В этом материале вы найдете описание библиотек, которые используются чаще всего для анализа данных на Python.
Основные библиотеки Python
Вот базовые библиотеки, которые делают из языка программирования Python инструмент для анализа и визуализации данных. Иногда их называют SciPy Stack. На них основываются более специализированные библиотеки.

Jupyter
Интерактивная оболочка для языка Python. В ней есть дополнительный командный синтаксис; она сохраняет историю ввода во всех сеансах, подсвечивает и автоматически дополняет код. Если вы когда-либо пользовались Mathematica или MATLAB, то разберетесь и в Jupyter.
Интерфейс библиотеки подходит для исследования и первичной обработки данных, тестирования первых версий кода и его улучшения. Используя язык разметки Markdown для форматирования текста и библиотеки для визуализации, можно формировать аналитические отчеты в браузере или преобразовать отчет в презентацию. С помощью JupyterHub можно настроить совместную работу команды на сервере.
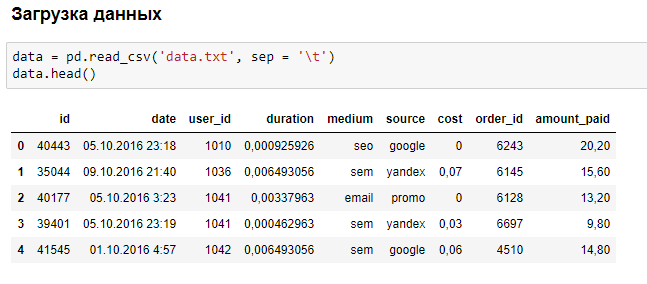
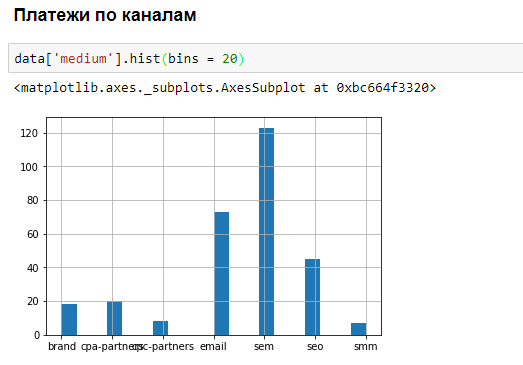
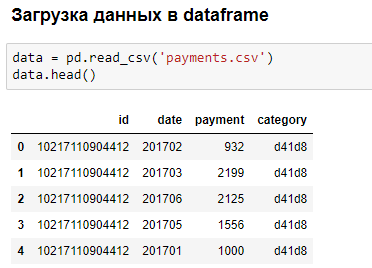
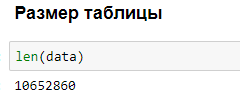
Пример небольшого анализа данных в браузере:



NumPy
NumPy — основная библиотека Python, которая упрощает работу с векторами и матрицами. Содержит готовые методы для разных математических операций: от создания, изменения формы, умножения и расчета детерминанта матриц до решения линейных уравнений и сингулярного разложения. Например, возьмем такую систему уравнений:
Чтобы ее решить, достаточно воспользоваться методом lialg.solve:

SciPy
Библиотека SciPy основывается на NumPy и расширяет ее возможности. SciPy похожа на Matlab. Включает методы линейной алгебры и методы для работы с вероятностными распределениями, интегральным исчислением и преобразованиями Фурье.
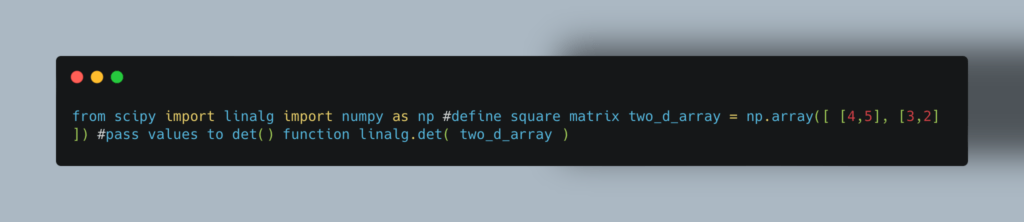
Пример расчета определителя двумерной матрицы:
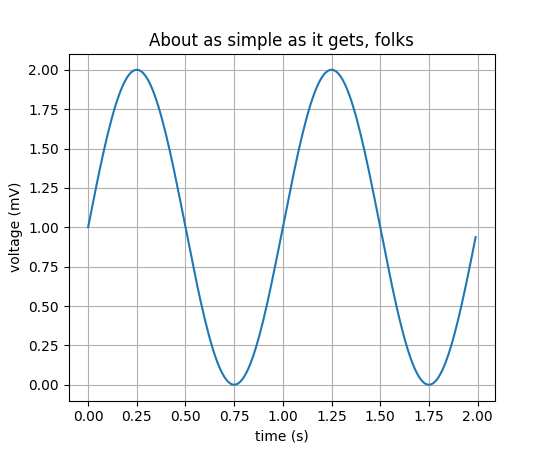
Matplotlib
Matplotlib — низкоуровневая библиотека для создания двумерных диаграмм и графиков. С ее помощью можно построить любой график, но для сложной визуализации потребуется больше кода, чем в продвинутых библиотеках.
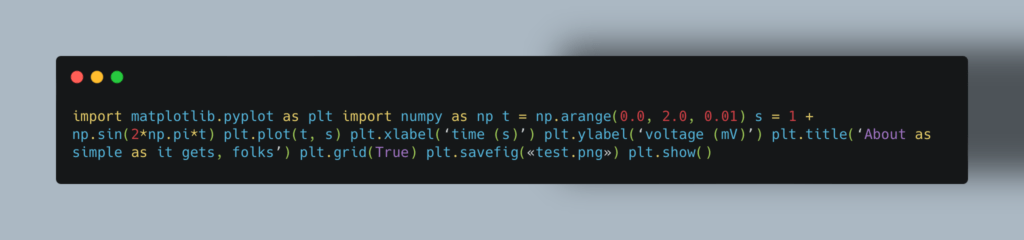
Используемый код:
Библиотеки для работы с данными
Библиотеки Python для анализа данных, Machine Learning и обучения сложных нейронных сетей.
Scikit-learn
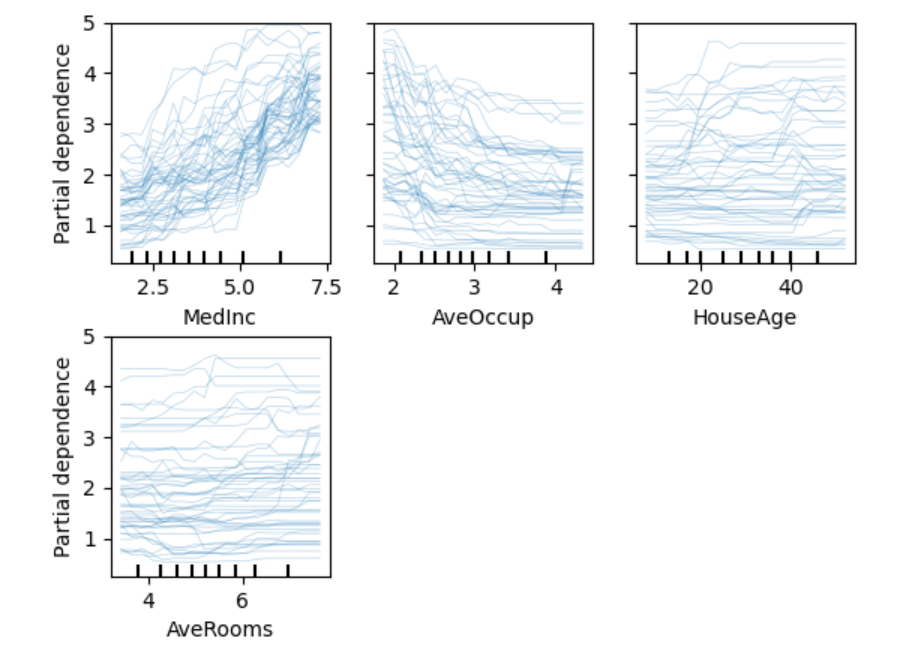
Scikit-learn основана на NumPy и SciPy. В ней есть алгоритмы для машинного обучения и интеллектуального анализа данных: кластеризации, регрессии и классификации. Это одна из самых лучших библиотек для компаний, работающих с огромным объемом данных — ее используют Evernote, OKCupid, Spotify и Birchbox.
Пример визуализации частичной зависимости стоимости домов в Калифорнии в зависимости от особенностей местности:
Используемый код:

TensorFlow
Библиотеку создали в Google, чтобы заменить DistBelief — фреймворк для обучения, настройки и тренировки нейронных сетей. Благодаря этой библиотеке Google может определять объекты на фотографиях, а приложение для распознавания голоса — понимать речь.
Пример архитектуры сверточной нейронной сети:
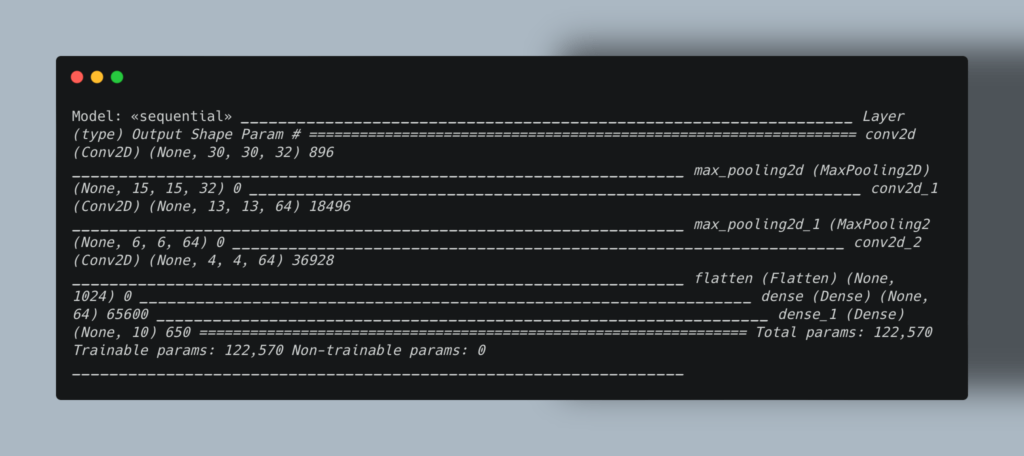
Keras
Библиотека глубокого обучения. Благодаря модульности и масштабированию она позволяет легко и быстро создавать прототипы. Keras поддерживает как сверточные и рекуррентные сети, так и их комбинации.
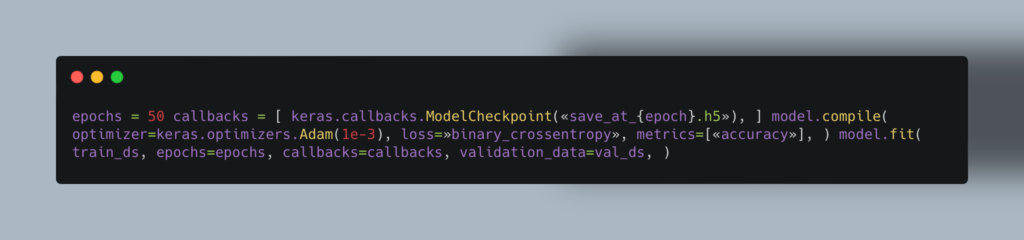
Пример кода обучения модели по классификации изображений:
Библиотеки для интеллектуального анализа и обработки естественного языка
Полезные иблиотеки для работы с текстом, которые используются для извлечения данных из интернет-ресурсов и обработки естественного языка.
Scrapy
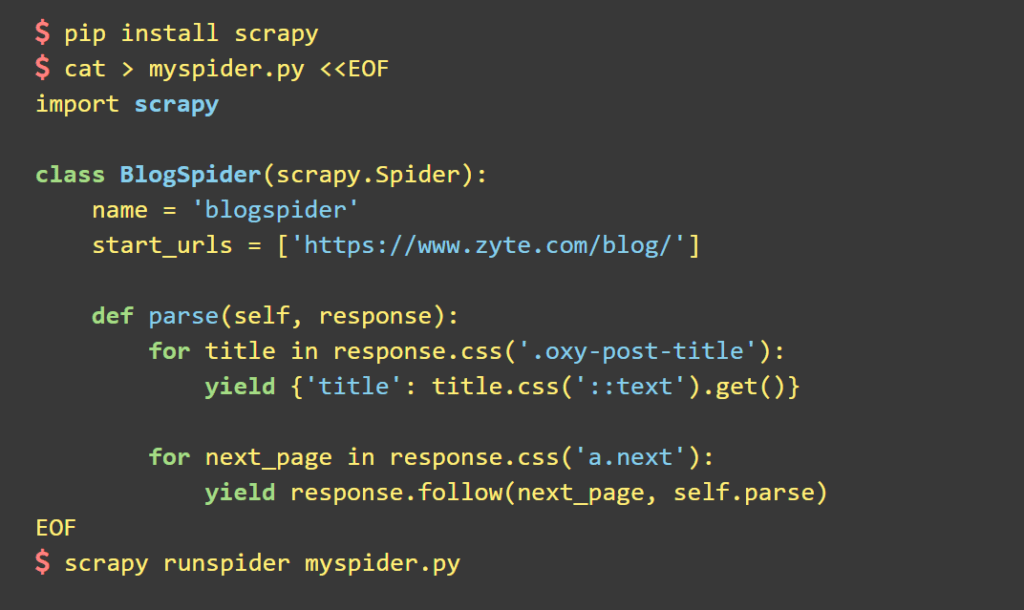
Библиотека используется для создания ботов-пауков, которые сканируют страницы сайтов и собирают структурированные данные: цены, контактную информацию и URL-адреса. Кроме этого, Scrapy может извлекать данные из API.
Пример кода для создания бота-паука:
NLTK (Natural Language Toolkit)
Набор библиотек для обработки естественного языка. Основные функции: разметка текста, определение именованных объектов, отображение синтаксического дерева, раскрывающего части речи и зависимости.
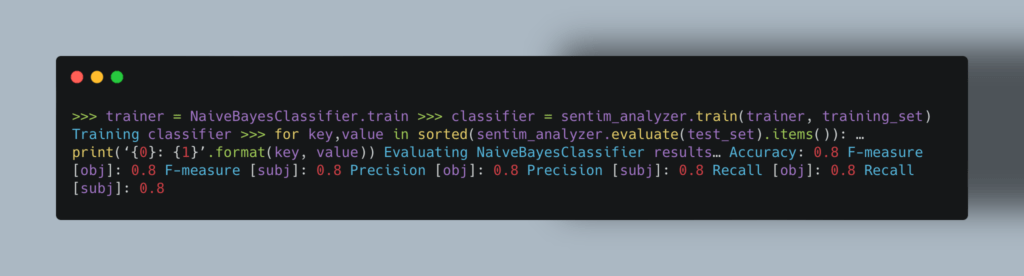
Например, так выглядит обучение классификатора, который будет определять тональность текста:
Pattern
Сочетает функциональность Scrapy и NLTK и предназначена для извлечения данных в интернете, естественной обработки языка, машинного обучения и анализа социальных сетей. Среди инструментов есть поисковик, API для Google, Twitter и Wikipedia и алгоритмы текстового анализа, которые могут выполняться несколькими строками кода.
Пример визуализации графа:
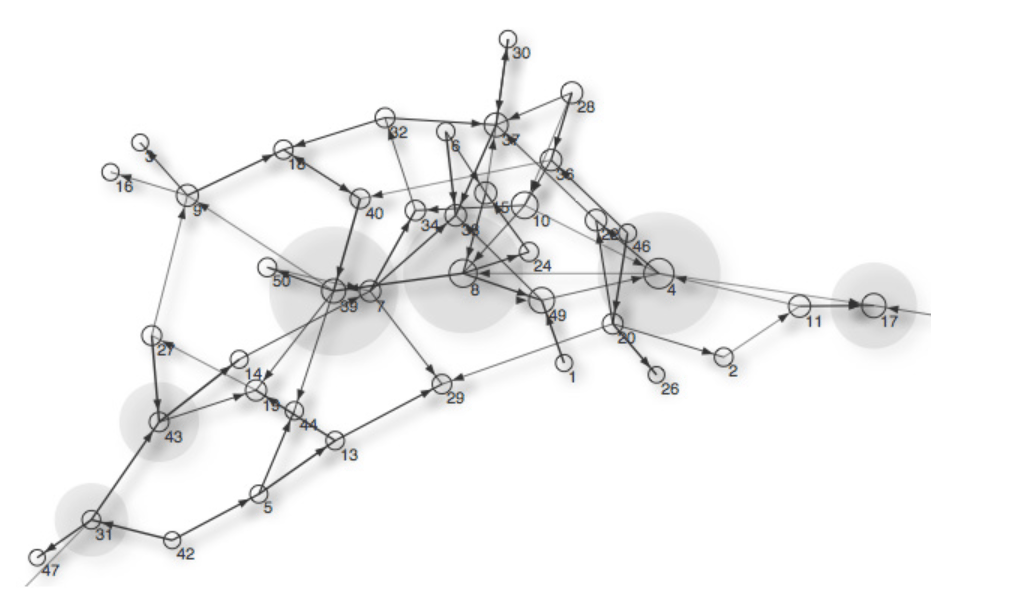
Используемый код:
Библиотеки Python для визуализации
Библиотеки, которые пригодятся в визуализации данных и построении графиков.
Seaborn
Библиотека более высокого уровня, чем matplotlib. С ее помощью проще создавать специфическую визуализацию: тепловые карты, временные ряды и скрипичные диаграммы. Пример визуализации:
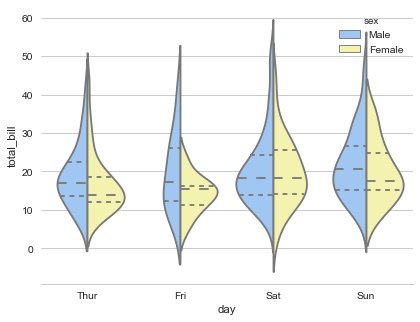
Используемый код:
Bokeh
Создает интерактивные и масштабируемые графики в браузерах, используя виджеты JavaScript. Сложность графиков может быть разная: от стандартных диаграмм до сложных кастомизированных схем. Примеры визуализации:
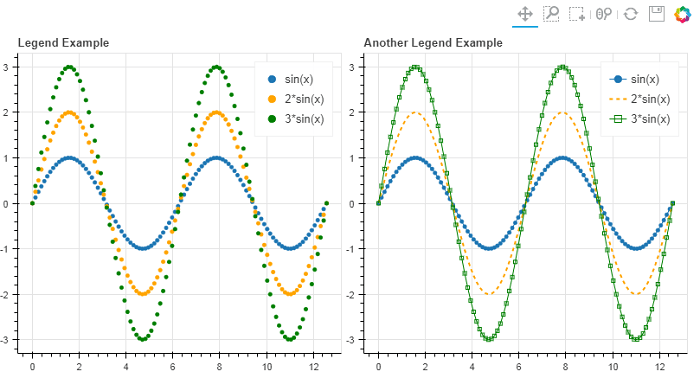
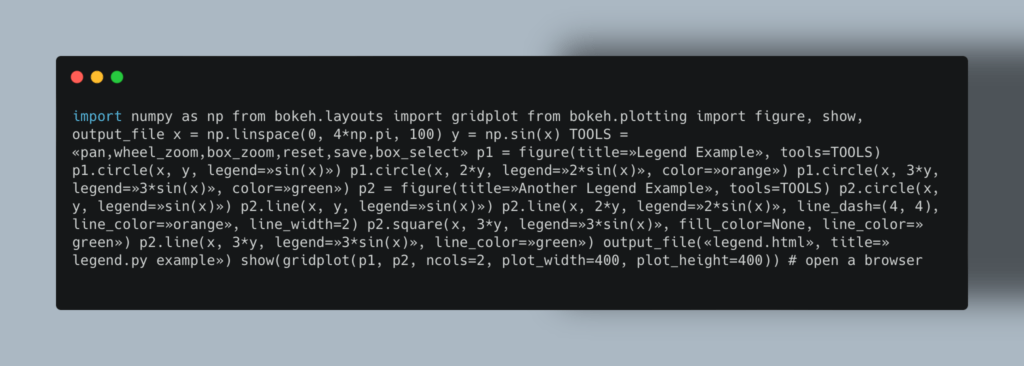
Используемый код:
Basemap
Basemap используется для создания карт. На ее основе сделана библиотека Folium, с помощью которой создают интерактивные карты в интернете. Пример карты:
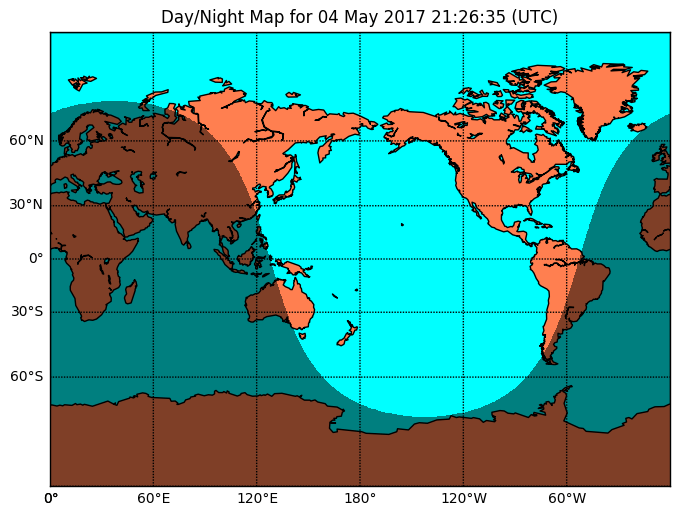
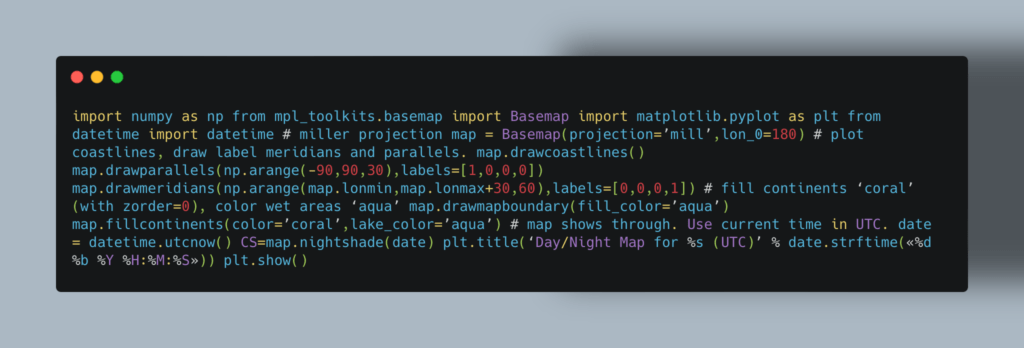
Код:
NetworkX
Используется для создания и анализа графов и сетевых структур. Предназначена для работы со стандартными и нестандартными форматами данных.
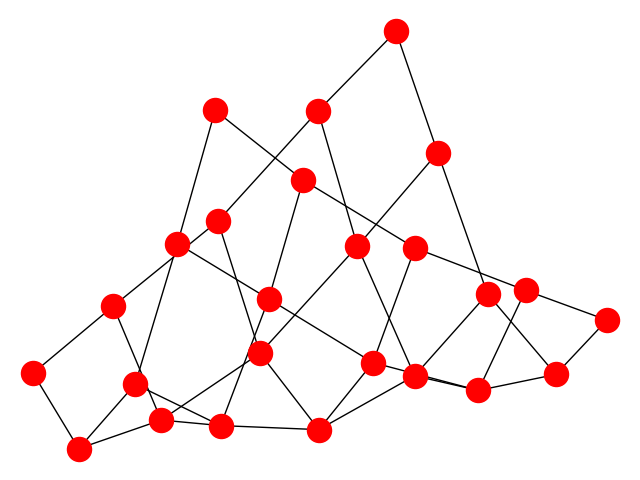
Используемый код:
Это малая часть библиотек Python, но и их достаточно, чтобы на серьезном уровне анализировать данные, создавать и обучать нейронные сети и визуализировать результаты.
