


Возможно, вы слышали легенду о мудреце, которому персидский царь предложил любую награду за изобретение шахмат. Мудрец попросил зерно: одно зернышко на первую клетку доски, два на вторую, четыре на третью, и так далее. Сначала царь обрадовался, поскольку просьба казалась ничтожной.
Но когда придворные математики подсчитали, оказалось, что для выполнения обещания потребуется около 18 квинтиллионов зерен — больше, чем все зерно, выращенное человечеством за всю историю. Царь так и не смог расплатиться.

Эта история показывает, что характер роста важнее абсолютных величин. В программировании происходит то же самое: алгоритм может обрабатывать 100 элементов за долю секунды — и зависать на 100 000. Причина не в конкретных числах, а в том, как быстро растет время работы при увеличении объема данных.
Чтобы описывать и сравнивать этот характер роста, существует нотация Big O — математический способ выразить, как меняется производительность алгоритма в зависимости от размера входных данных. Давайте выясним, как это работает.
Что такое Big O и как ее понимать
Представьте, что вам нужно найти в телефонном справочнике номер Линуса Торвальдса. Можно пойти длинным путем и пролистать все страницы — от «А» до «Т». Так работает линейный алгоритм: чем толще книга, тем дольше поиск.
Чтобы не открывать каждую страницу, вы можете поступить иначе: открыть середину и сразу понять, в какой половине искать — до буквы «Т» или после. Затем повторить то же самое с оставшейся половиной, и так далее. Если вы поступите подобным образом — это будет бинарный поиск, логарифмический алгоритм, который справляется в разы быстрее обычного линейного перебора.
Оба подхода работают, но ведут себя по-разному при росте данных. И нотация Big O как раз помогает определить эту разницу. Она показывает характер роста времени выполнения алгоритма — не абсолютные миллисекунды, а то, как меняется производительность при увеличении объема данных. Если данных станет в десять раз больше, то что произойдет со временем работы? Оно тоже вырастет в десять раз, как при перелистывании? Или увеличится всего на несколько шагов, как при бинарном поиске? А может, изменится как-то иначе?
Big O описывает худший случай — ситуацию, когда алгоритму придется выполнить максимальное количество операций. Например, если вы ищете элемент в массиве из миллиона элементов, может повезти — и он окажется первым. Однако Big O исходит из того, что элемент находится в самом конце, и алгоритму потребуется проверить все миллион позиций для его поиска.
Нотация Big O записывается как O(n), где n — размер входных данных, а выражение внутри скобок показывает, как растет сложность при увеличении n. Например, O(n) означает линейный рост: в два раза больше данных — в два раза больше операций. O(n²) означает квадратичный рост: в два раза больше данных — в четыре раза больше операций. А вот константы и младшие члены при записи отбрасываются: O(2n + 5) упрощается до O(n), а O(n² + n) — до O(n²).
В зависимости от своего поведения алгоритм попадает в один из классов сложности, которые упорядочены от лучшего к худшему: O(1), O(log n), O(n), O(n log n), O(n²), O(2ⁿ), O(n!). Подробнее о каждом из них мы поговорим далее.
Но прежде вы должны понимать, что Big O описывает не только временную сложность (как быстро выполняется алгоритм), но и пространственную — сколько дополнительной памяти нужно для его работы. Принцип анализа тот же, просто измеряются разные ресурсы. В статье мы сосредоточимся на временной сложности, поскольку ее чаще всего спрашивают на собеседованиях.
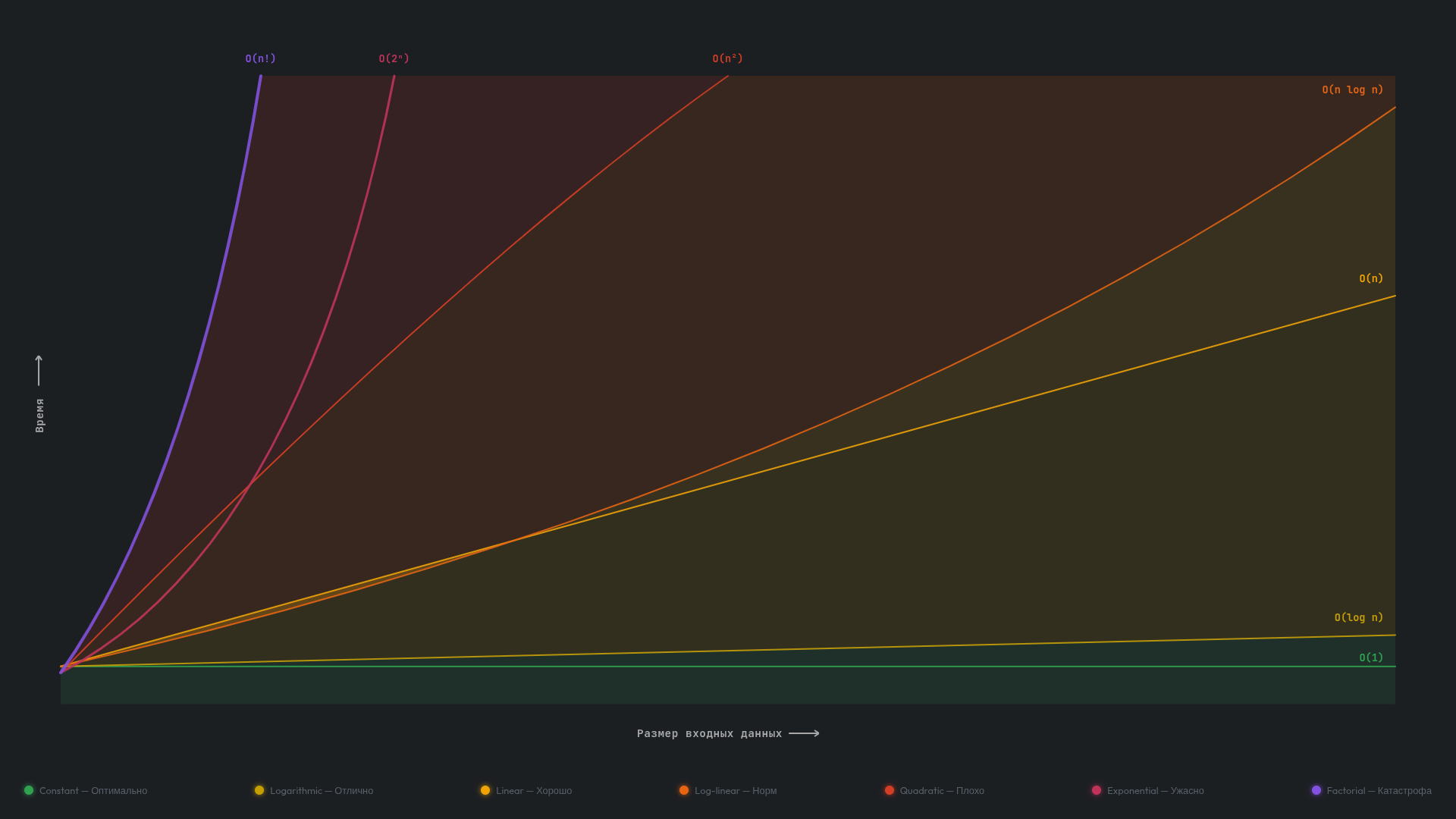
Классы сложности алгоритмов
Теперь пройдемся по каждому классу сложности: разберем, что он означает, как его распознать в коде, и рассмотрим конкретные примеры на языке JavaScript.
O(1) — константная
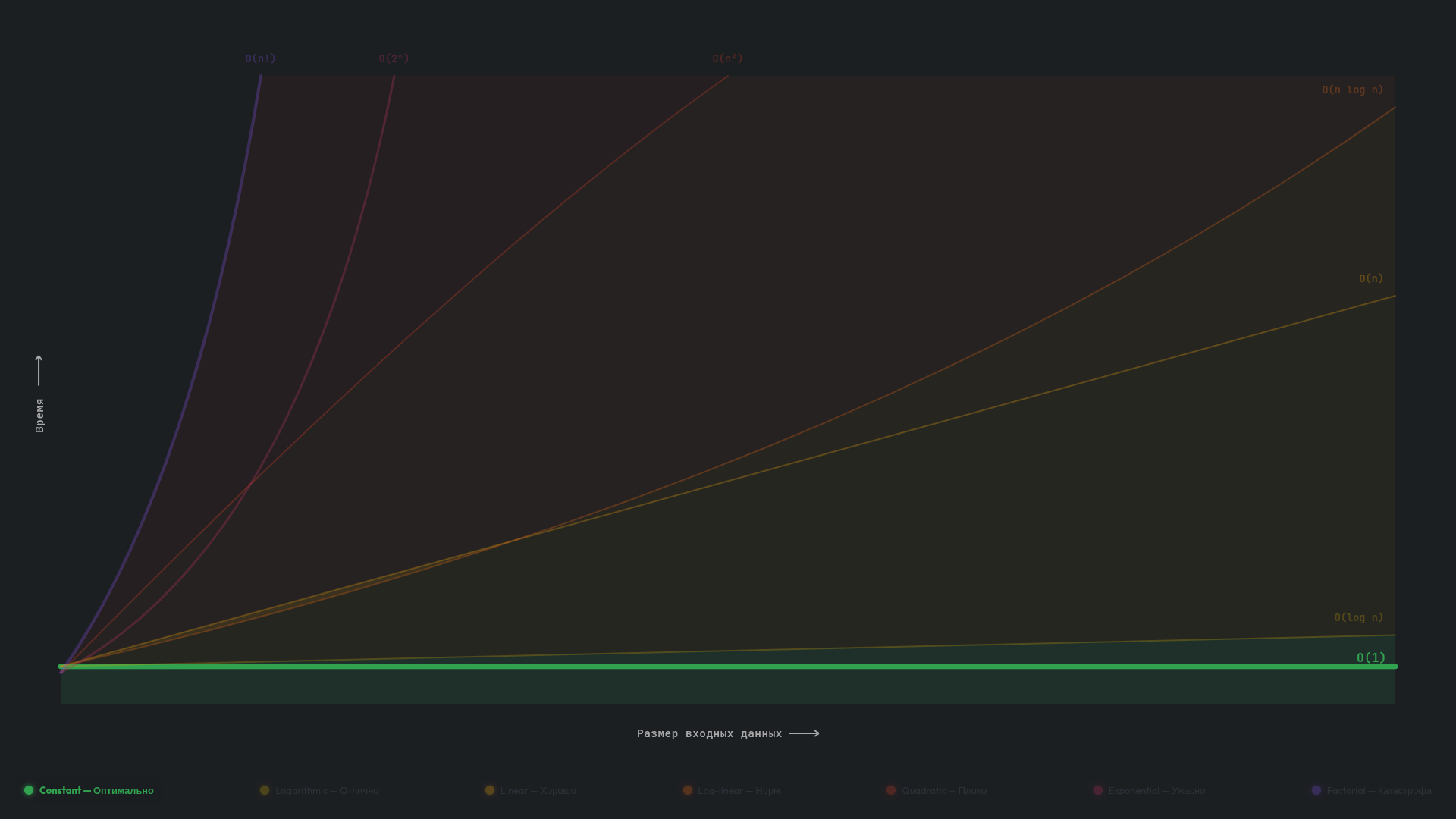
Алгоритм с константной сложностью O(1) выполняет одно и то же количество операций независимо от размера входных данных. Представьте, что вы знаете номер страницы и можете одним движением открыть книгу на ней. В этом случае толщина книги не важна: в ней может быть 100 страниц или 10 000, вы все равно выполняете ровно одно действие для перехода к нужному месту.
В коде O(1) узнается по тому, что алгоритм делает фиксированное число шагов и не перебирает входные данные целиком. Чаще всего это «прямой доступ» к нужному месту: взять элемент массива по индексу, прочитать свойство объекта, проверить условие if или выполнить несколько арифметических операций. Как только появляется цикл for или while, рекурсия или проход по коллекции, количество операций начинает зависеть от размера данных — и это уже не O(1).
Создадим два массива: один из 10 элементов, другой из 10 000. В первом обратимся к первому элементу, а во втором — к последнему. В обоих случаях операция выполняется за одно действие, независимо от размера массива:
const small = [3, 7, 1, 9, 4, 2, 8, 6, 5, 0]; const large = new Array(10000).fill(0).map((_, i) => i); console.log(small[0]); // 3 console.log(large[9999]); // 9999
O(log n) — логарифмическая
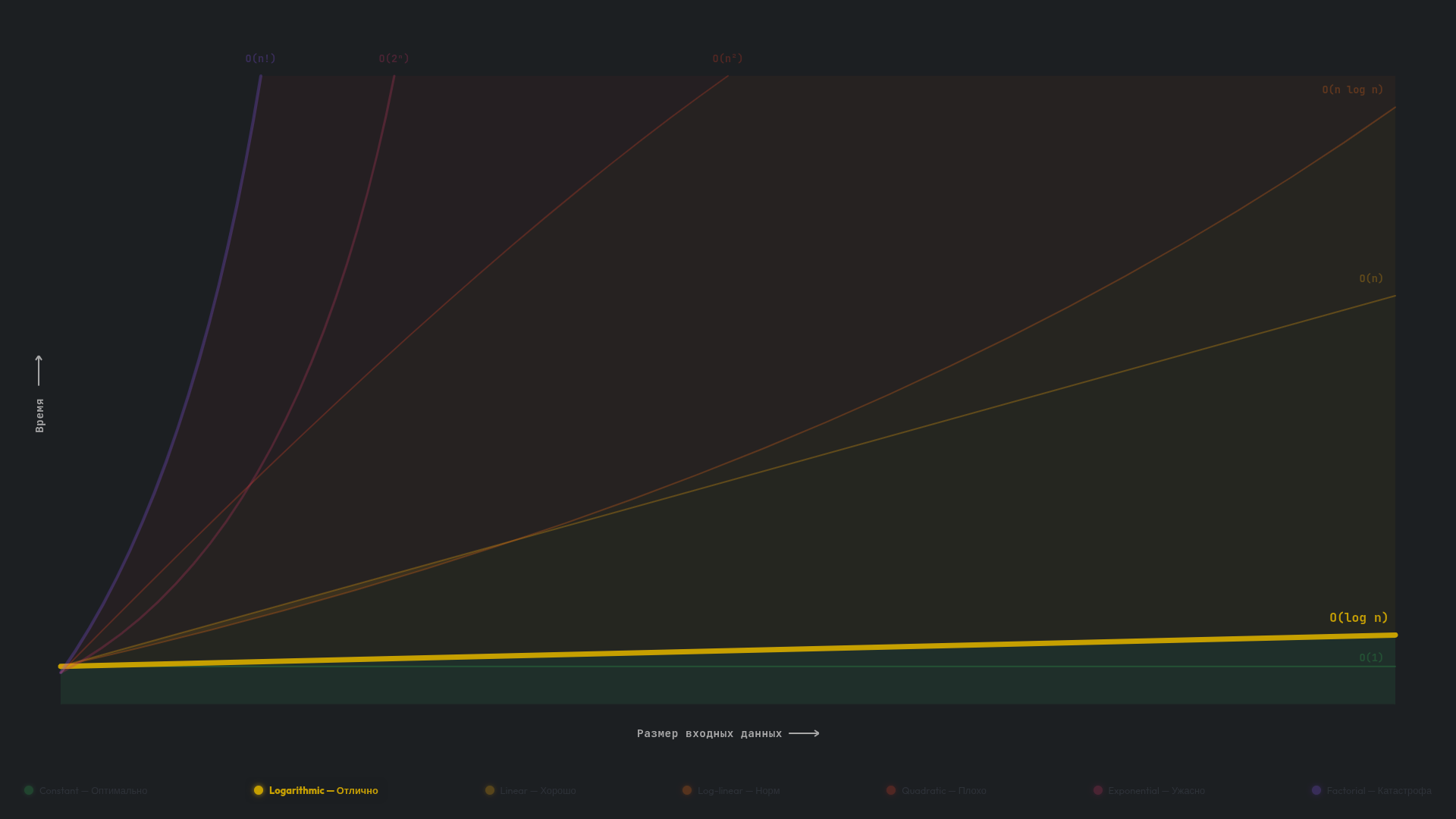
Алгоритм с логарифмической сложностью O(log n) с каждым шагом уменьшает количество оставшихся данных в несколько раз. Вспомните наш пример со справочником: вы открываете середину, отсекаете лишнюю половину и так повторяете процесс с оставшейся частью. Даже если в справочнике будет миллион записей, вам понадобится около 20 шагов (log₂ 1 000 000 ≈ 20).
В коде O(log n) распознается по тому, что на каждом шаге алгоритм делит пространство поиска пополам (или на другие части) и не проходит по всем элементам подряд. Раз мы уже упоминали про бинарный поиск, давайте его и реализуем: создадим отсортированный массив из миллиона элементов, найдем в нем число 999999 и выведем, сколько шагов нам для этого понадобилось:
const binarySearch = (arr, target) => {
let left = 0;
let right = arr.length - 1;
let steps = 0;
while (left <= right) {
steps++;
const mid = Math.floor((left + right) / 2);
if (arr[mid] === target) {
console.log(`Найдено за ${steps} шагов`);
return mid;
}
if (arr[mid] < target) left = mid + 1;
else right = mid - 1;
}
return -1;
};
const arr = new Array(1000000).fill(0).map((_, i) => i); // [0, 1, 2, ..., 999999]
binarySearch(arr, 999999); // Найдено за 20 шагов
O(n) — линейная
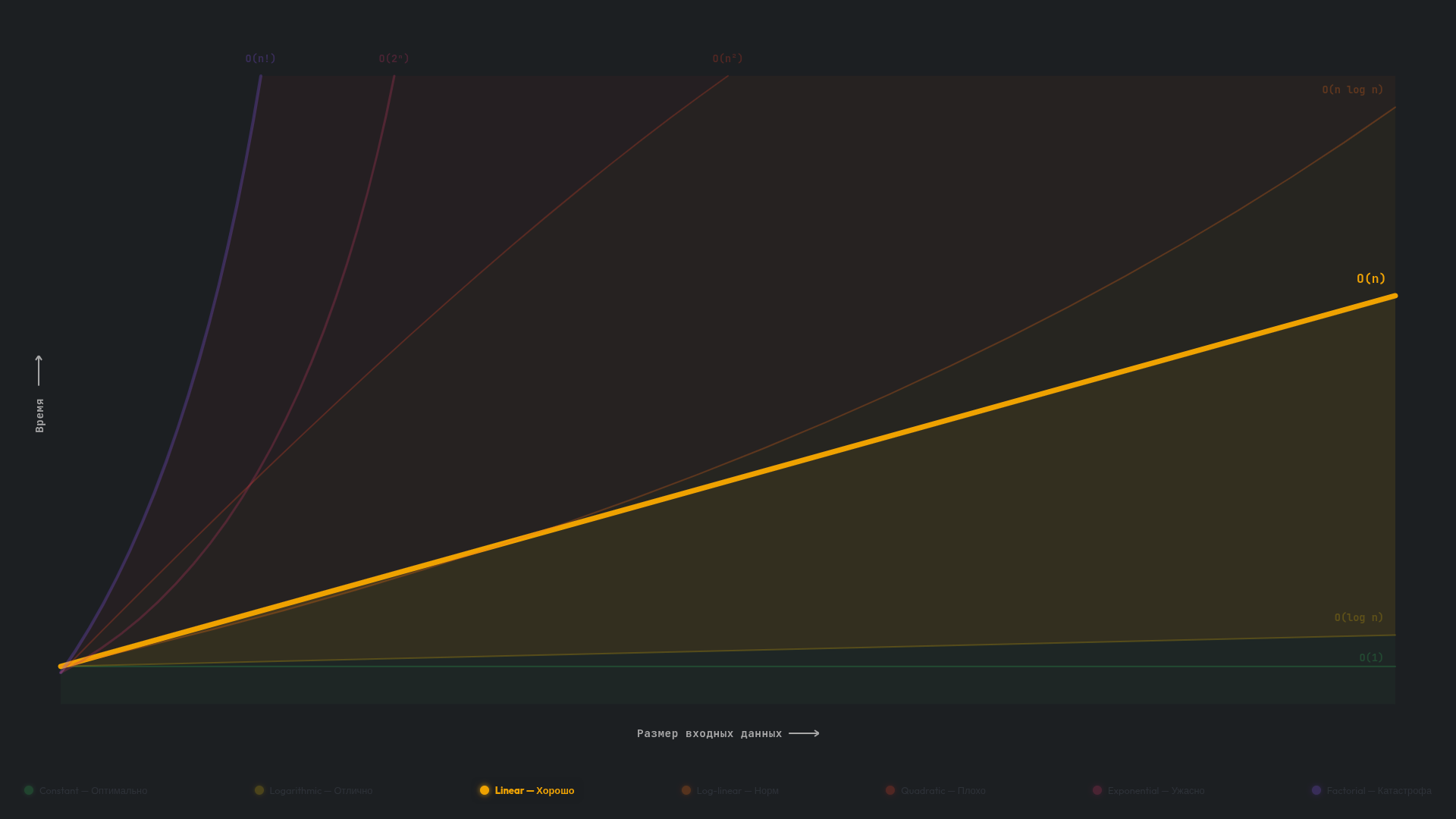
Алгоритм с линейной сложностью O(n) выполняет количество операций, пропорциональное размеру входных данных. Если данных становится вдвое больше, алгоритм выполнит вдвое больше операций. Например, для массива из 100 элементов нужно 100 операций, а для массива из 1000 элементов — 1000 операций. Это как читать книгу страница за страницей и ничего не пропускать — чем больше материал вам нужно изучить, тем больше времени это займет.
В коде линейная сложность O(n) узнается по одному циклу, который проходит по всем элементам входных данных ровно один раз. Главное отличие от других классов в том, что здесь нет вложенных циклов и деления пространства поиска пополам — алгоритм просто последовательно обрабатывает каждый элемент от начала до конца. Например, создадим массив из миллиона целых чисел от 0 до 999 999 и найдем в нем максимальное значение, пройдя по всем элементам:
const arr = new Array(1000000).fill(0).map((_, i) => i);
const findMax = (arr) => {
let max = arr[0];
for (let i = 1; i < arr.length; i++) {
if (arr[i] > max) max = arr[i];
}
return max;
};
console.log(findMax(arr)); // 999999 — максимальное число в массиве
O(n log n) — линейно-логарифмическая
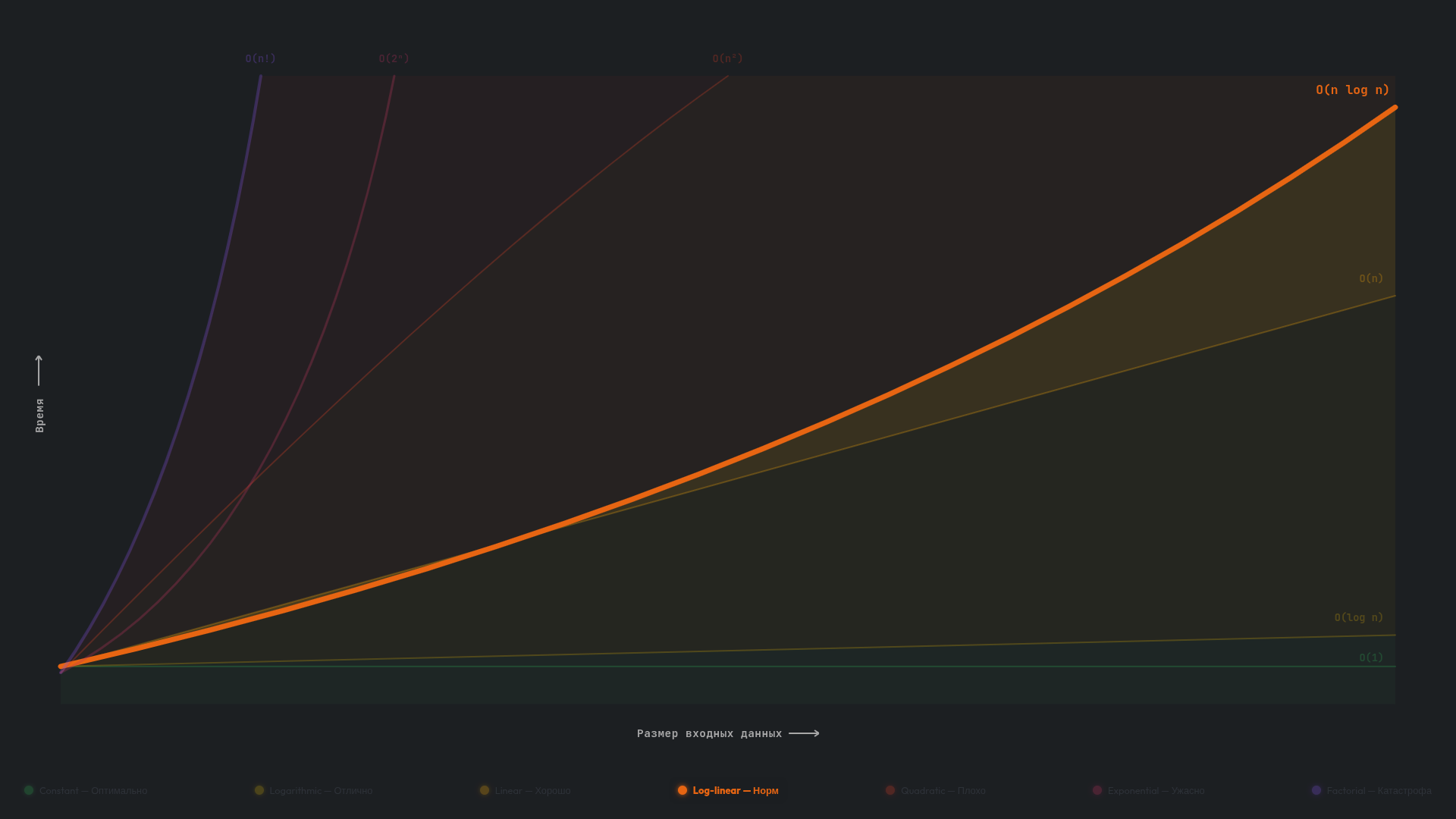
Алгоритмы с линейно-логарифмической сложностью O(n log n) обычно устроены так: они обрабатывают каждый элемент входных данных (поэтому есть множитель n), но делают это эффективно — многократно разделяют задачу на мелкие подзадачи, решают их независимо, а затем объединяют результаты.
Представьте, что вам нужно разложить миллион карточек по алфавиту. Вместо того чтобы каждый раз искать место для карточки перебором, вы действуете «пачками»: делите стопку на две части, сортируете каждую часть по отдельности, а затем складываете две уже отсортированные стопки в одну.

Миллион карточек сначала делится на две стопки по 500 000, затем каждая снова делится пополам — получается четыре стопки по 250 000, и так далее. Таких шагов нужно немного: для миллиона элементов хватает примерно 20 делений (2²⁰ ≈ 1 000 000). Эти 20 шагов — это и есть логарифмическая составляющая, то есть множитель log₂(n). А n появляется потому, что на каждом из этих 20 уровней деления нужно обработать все элементы. Получаем следующее: 20 уровней × миллион операций = 20 миллионов операций, что и дает n log n.
В программировании O(n log n) часто встречается в тех алгоритмах, которые работают по принципу «разделяй и властвуй»: они рекурсивно делят данные на части, обрабатывают каждую часть независимо друг от друга, а затем объединяют результаты. Так устроены многие сортировки, например merge sort и quick sort. В JavaScript встроенный метод .sort() тоже обычно работает примерно за O(n log n). Давайте рассмотрим это на примере — создадим массив из миллиона случайных чисел, отсортируем его и засечем скорость выполнения:
const arr = Array.from({ length: 1_000_000 }, () => Math.random());
console.time('Сортировка');
arr.sort((a, b) => a - b);
console.timeEnd('Сортировка');
console.log('min:', arr[0], 'max:', arr[arr.length - 1]); // Минимальное и максимальное значения
После запуска кода сортировка заняла примерно 977 мс. Так же мы получили минимальный и максимальный элементы: min ≈ 4,69×10⁻⁷, max ≈ 0,9999993. У вас при запуске значения и время будут другими, потому что массив заполняется случайными числами, а результат зависит от среды выполнения.
O(n²) — квадратичная
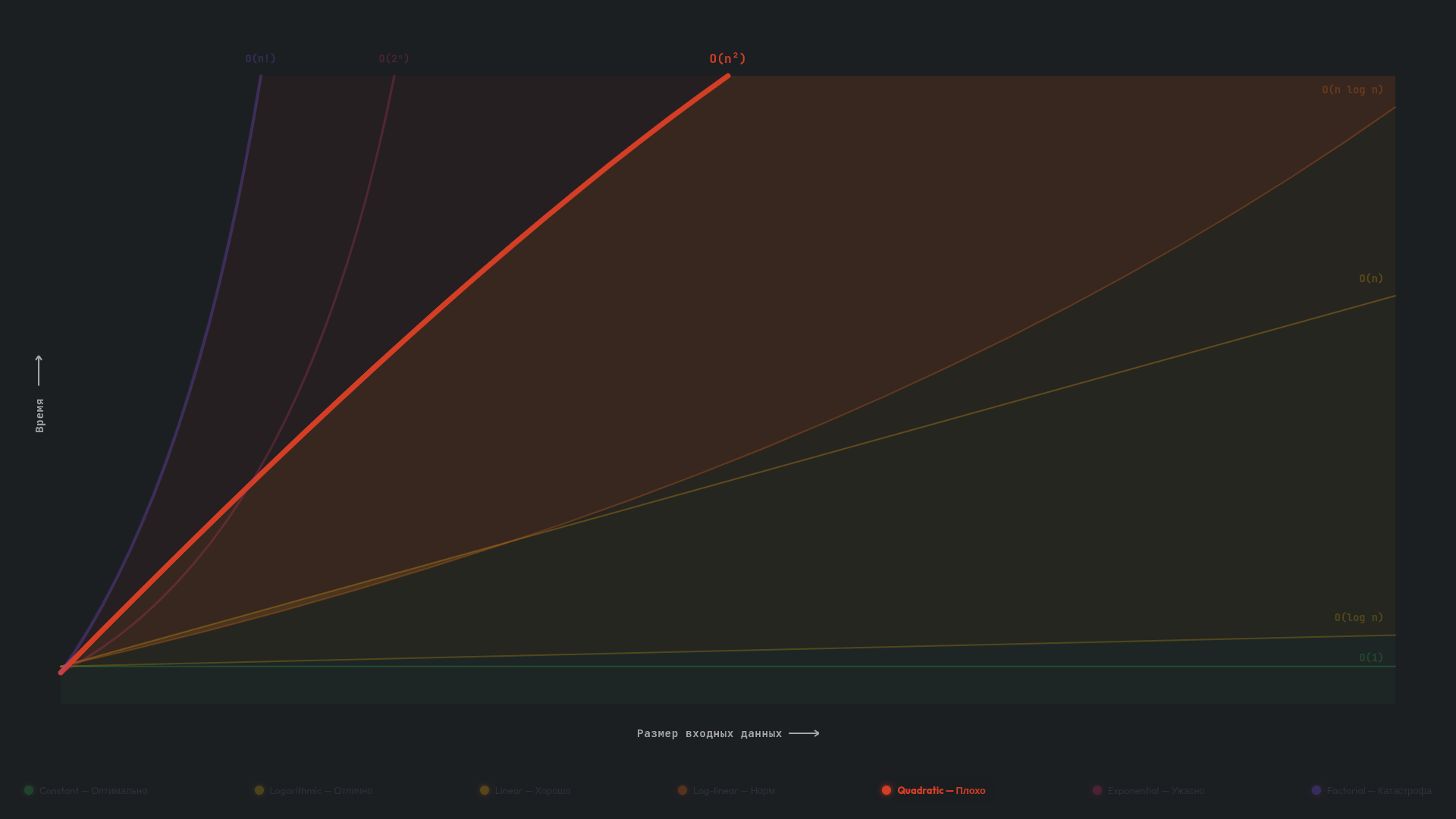
Алгоритм с квадратичной сложностью O(n²) выполняет такое количество операций, которое равно квадрату размера входных данных. Вдвое больше данных — вчетверо больше операций. На малых данных это незаметно, но при росте n квадратичные алгоритмы быстро становятся слишком медленными.
В программах O(n²) распознается по двум вложенным циклам: внешний проходит по массиву, а внутренний для каждого элемента снова проходит по всем (или почти всем) элементам. Если внешний цикл делает n итераций и на каждой из них внутренний цикл тоже делает n итераций, то в сумме получается n × n = n² операций. При n = 1 000 это примерно 1 000 000 проверок.
Давайте возьмем массив чисел и проверим, есть ли в нем дубликаты. Наш внешний цикл будет выбирать элемент arr[i], а внутренний для каждого i проходит по всем элементам и сравнивает каждый arr[j] с текущим arr[i]. Если какие-то значения совпадают — функция вернет true:
const noDuplicates = [1, 2, 3, 4];
const withDuplicates = [1, 2, 3, 2, 4];
const hasDuplicates = (arr) => {
for (let i = 0; i < arr.length; i++) {
for (let j = i + 1; j < arr.length; j++) {
if (arr[i] === arr[j]) return true;
}
}
return false;
};
console.log(hasDuplicates(noDuplicates)); // false
console.log(hasDuplicates(withDuplicates)); // true
В результате мы получили сначала false, а затем true. Это значит, что в массиве noDuplicates повторов не оказалось, а в withDuplicates двойка встречается дважды. Но это простейший пример с малым количеством данных.
На задачах с большими массивами квадратичная сложность становится серьезной проблемой — она может привести к замедлению программы или ее полному зависанию. Например, если вы попытаетесь проверить на дубликаты массив из 100 000 элементов, то алгоритм выполнит около 10 миллиардов сравнений (100 000²), что может занять несколько секунд или даже минут. В то время как линейный подход с использованием Set справится за миллисекунды.
O(2ⁿ) и O(n!) — экспоненциальная и факториальная
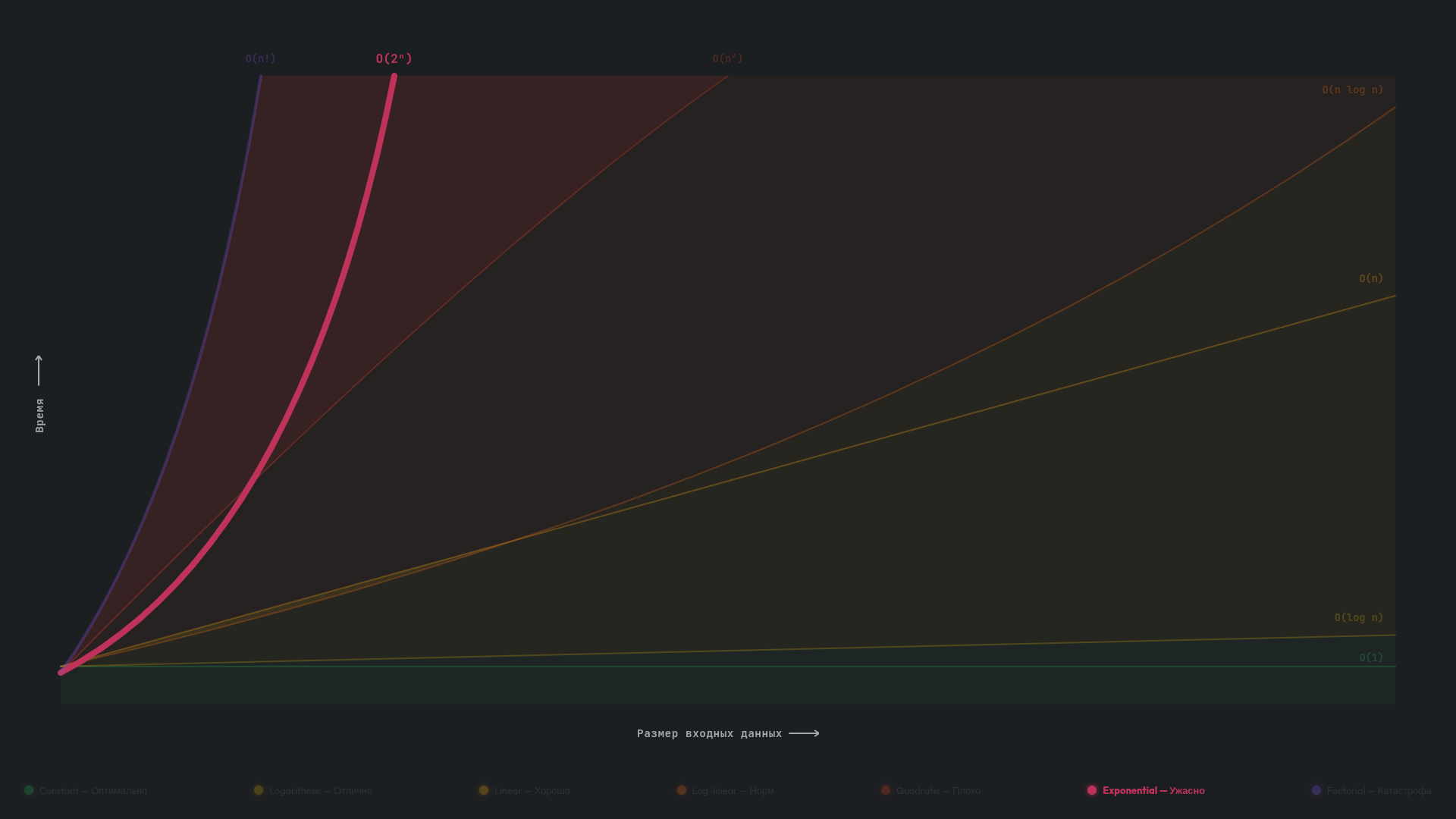
Нам осталось рассмотреть два самых медленных класса сложности, которые на практике применимы к маленьким входным данным (n < 20–30 элементов). Мы их рассмотрим вместе и не будем подробно вдаваться в детали их описания.
При экспоненциальной сложности O(2ⁿ) каждый новый элемент удваивает количество операций. Например, при n = 5 алгоритм выполняет 32 операции (2⁵ = 32), при n = 6 — уже 64 (2⁶ = 64), а при n = 10 — целых 1024 (2¹⁰ = 1024). Вспомните легенду про шахматную доску и зерна из начала статьи или заклинание удвоения из «Гарри Поттера» — это тот же принцип роста.
При факториальной сложности O(n!) число операций растет как количество перестановок из n элементов. Факториал — это произведение 1 × 2 × 3 × … × n, и он увеличивается с очень большой скоростью. Представьте, что вам нужно расставить n книг на полке во всех вариантах. Для 3 книг есть всего 6 вариантов расстановки, для 5 книг — 120, а для 10 книг — более 3,6 миллиона. Если продолжать, то перебор всех вариантов быстро становится невыполнимым.
Напишем функцию, которая генерирует все возможные перестановки массива. В примере ниже будет всего три элемента — это 6 вариантов. Можете попробовать добавить больше элементов, но будьте осторожны: уже для 10 элементов количество перестановок превысит 3,6 миллиона, и браузер может зависнуть.
const permutations = (arr) => {
const result = [];
const backtrack = (i) => {
if (i === arr.length) {
result.push([...arr]);
return;
}
for (let j = i; j < arr.length; j++) {
[arr[i], arr[j]] = [arr[j], arr[i]];
backtrack(i + 1);
[arr[i], arr[j]] = [arr[j], arr[i]];
}
};
backtrack(0);
return result;
};
console.log(permutations([1, 2, 3])); // 6 вариантов = 3!
Как отвечать про Big O на собеседованиях и где тренироваться
На технических собеседованиях вопросы про Big O вам будут задавать не ради проверки знания формул или определений. Интервьюеру важно увидеть, что вы понимаете, как поведет себя ваше решение при увеличении объема данных.
Мы рекомендуем придерживаться такой стратегии: сначала дайте любое рабочее решение, даже если оно не оптимально по времени или памяти. Главное — покажите, что можете решить задачу. И только после этого, если интервьюер попросит, предлагайте способы улучшить решение — например, снизить сложность с O(n²) до O(n log n) с помощью более эффективного алгоритма, или воспользоваться дополнительной структурой данных вроде хеш-таблицы.
Частая ошибка новичков — пытаться вспомнить готовый ответ по Big O, вместо того чтобы объяснить свой ход мысли. Лучше проговорить вслух, что считается размером входных данных (это n) и какие части решения от него зависят. Обычно достаточно одной фразы про время и одной — про память: используете ли вы дополнительные структуры данных и сколько места они занимают.
А если вы сомневаетесь в оценке, никогда не пытайтесь угадывать. Скажите, откуда она берется: «здесь один проход по массиву — значит O(n)», «здесь два вложенных цикла — значит O(n²)», «здесь делим диапазон пополам — значит O(log n)», «здесь есть сортировка — значит примерно O(n log n)». Такой ответ выглядит намного увереннее, чем «мне кажется, тут O(n log n)».
И еще один важный момент: Big O описывает не миллисекунды, а рост сложности. На маленьких примерах разница между O(n) и O(n²) может быть вообще незаметна, но на больших объемах данных она становится критичной. Поэтому на собеседовании ценится не только правильная оценка сложности, но и понимание того, когда решение перестанет масштабироваться — и как его улучшить. Или, наоборот, когда оптимизация не нужна: если задача — просто получить рабочее решение в разумные сроки, даже не самое эффективное.
Чтобы подобные рассуждения стали привычкой, нужно регулярно тренироваться. Одна из лучших площадок для этого — LeetCode. Там собраны сотни типовых задач, которые часто встречаются на технических интервью в крупных компаниях. Но самое ценное в том, что после решения вы будете видеть примерные показатели времени выполнения и потребления памяти кода, сравнивать их с результатами других участников и улучшать свой код.
Про LeetCode у нас есть отдельная статья, которую мы подготовили для новичков. Посмотрите — там подробно описан весь процесс: от регистрации на платформе до решения задач. Рекомендуем прочитать и начать практиковаться.
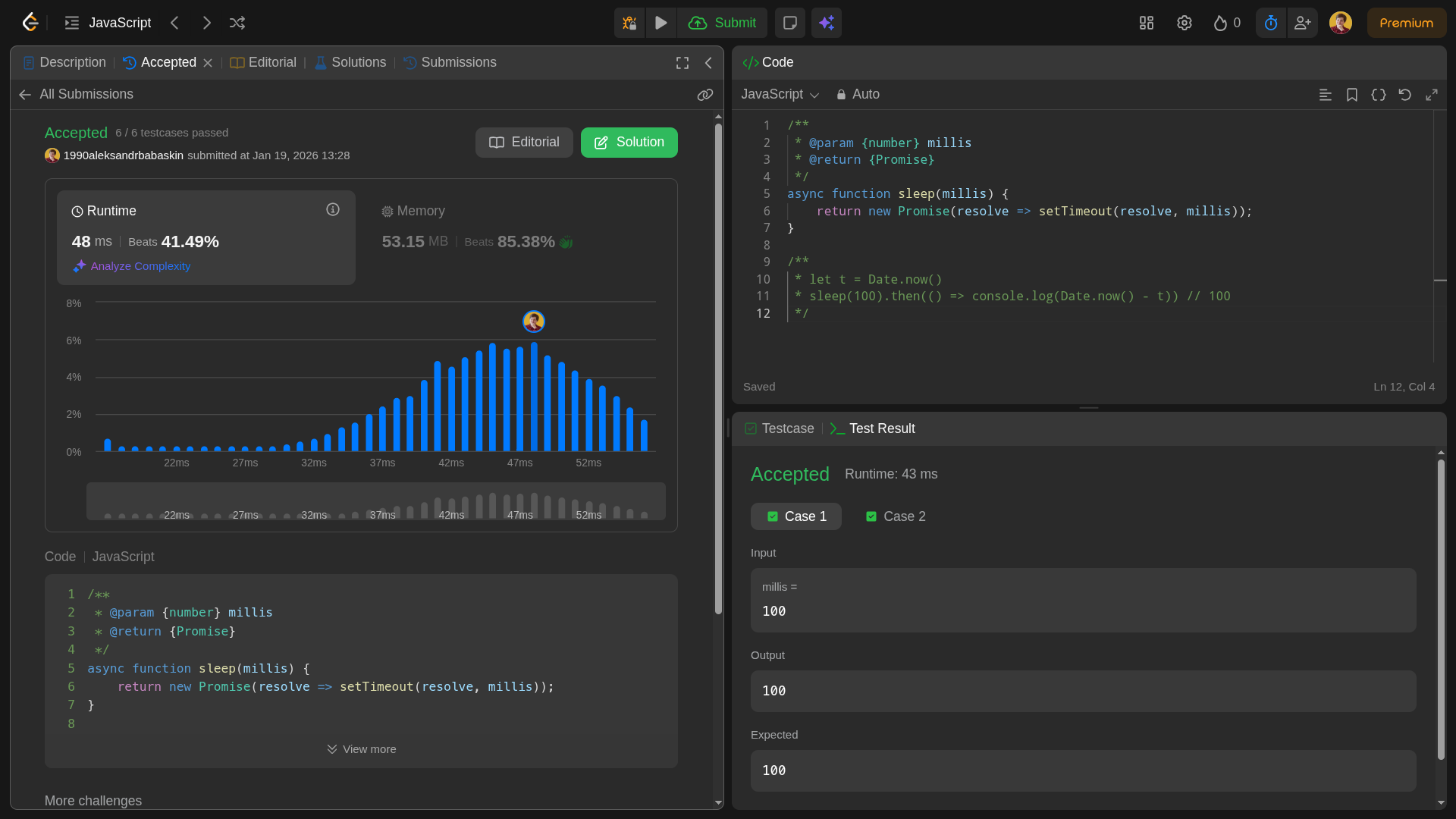
Пример решенной задачи с LeetCode с показателями времени и памяти выполнения кода. Есть куда оптимизировать. Источник: автор статьи
Полезное по теме
- Что такое LeetCode и как им наконец начать пользоваться
- Что такое алгоритм, из чего он состоит и зачем нужен
- Циклические алгоритмы в программировании
- Алгоритмы сортировки в программировании: виды, описания и сравнения
- Что такое бинарный поиск и зачем он нужен
- 10 задач на логику из реальных собеседований
