Автор Skillfactory, любит технологии и рассказывать о них.
Машинное обучение в бизнесе помогает предсказывать загрузку компании, проводить исследование клиентов и рынка. Особенно это актуально для крупных компаний, которые собирают огромное количество данных о своих рабочих процессах и аудитории. Чтобы сделать эти данные полезными, нужна работа Data Science команды.
Компании «Билайн» и ПЭК принесли свои задачи на Мегахакатон для студентов магистратуры «Науки о данных» от Skillfactory и МФТИ. Студенты получили доступ к реальным данным и попробовали свои силы в обучении ML-моделей. Рассказываем, что из этого получилось, на примере кейсов-победителей.
Кейс «Билайн»: фильтр для транскрибации
«Билайн» предложили командам сделать модуль-фильтр для модели распознавания речи. Программа должна анализировать транскрипции аудиофайлов и отсеивать текст, который расшифрован некачественно, с ошибками.
24 месяца
Онлайн-магистратура с МИФИ по машинному обучению
Станьте востребованным ML-инженером с дипломом МИФИ и опытом в индустрии
Исходные заказчика показали, что качество обучения их собственной модели распознавания речи напрямую зависит от точности текста расшифровки аудиофайлов. Чем больше в модель загружают верно транскрибированных данных, тем выше показатели их нейросети.
Одним из вызовов проекта было создать классификатор, который только по исходящему тексту должен определить, насколько входящий аудиофрагмент верно транскрибирован. То есть у нашего разработанного модуля-фильтра не было доступа к аудиофрагменту, в какой-то степени он работал «вслепую».
Вячеслав Самаковский, тимлид команды победителей. студент магистратуры «Науки о данных» Skillfactory x МФТИ
Команда победителей состояла из старых знакомых: большинство из них уже работали вместе на других хакатонах и встретились снова. Каждый участник принес свой вклад в разработку общего решения: проект собрали как конструктор из предложений команды.
Презентация решения команды
Мы вдохновлялись уже известными кейсами компаний. Затем стали вникать, какие инструменты и модели они использовали в работе. В результате оказалось, что почти все успешные решения сделаны с помощью известных моделей в общем доступе. Поэтому в своей работе мы опирались на целый список инструментов для работы с текстом, причем некоторые из них не были нейросетевыми: t5-russian-spell, ruRoBERT, Catboost classifier, CNN EfficientNet-v2, Perceptron.
Вячеслав Самаковский, тимлид команды победителей, студент магистратуры «Науки о данных» Skillfactory x МФТИ
На проекте команда поняла, что в такой задаче их решение может ничем не отличаться от решения команды-соперника. Поэтому только высокая степень проработки модели принесет победу.
В этом хакатоне я осознал, что есть два пути. Первый — ты берешь известный пайплайн действий и пытаешься выжать из него максимум. Второй — придумываешь что-то новое, свое. В первом случае придется бороться с соперниками буквально за каждый балл. Во втором — нет никаких гарантий, что твое новое решение принесет успех и победу.
Вячеслав Самаковский, тимлид команды победителей, студент магистратуры «Науки о данных» Skillfactory x МФТИ
Кейс ПЭК: предсказание грузоперевозок
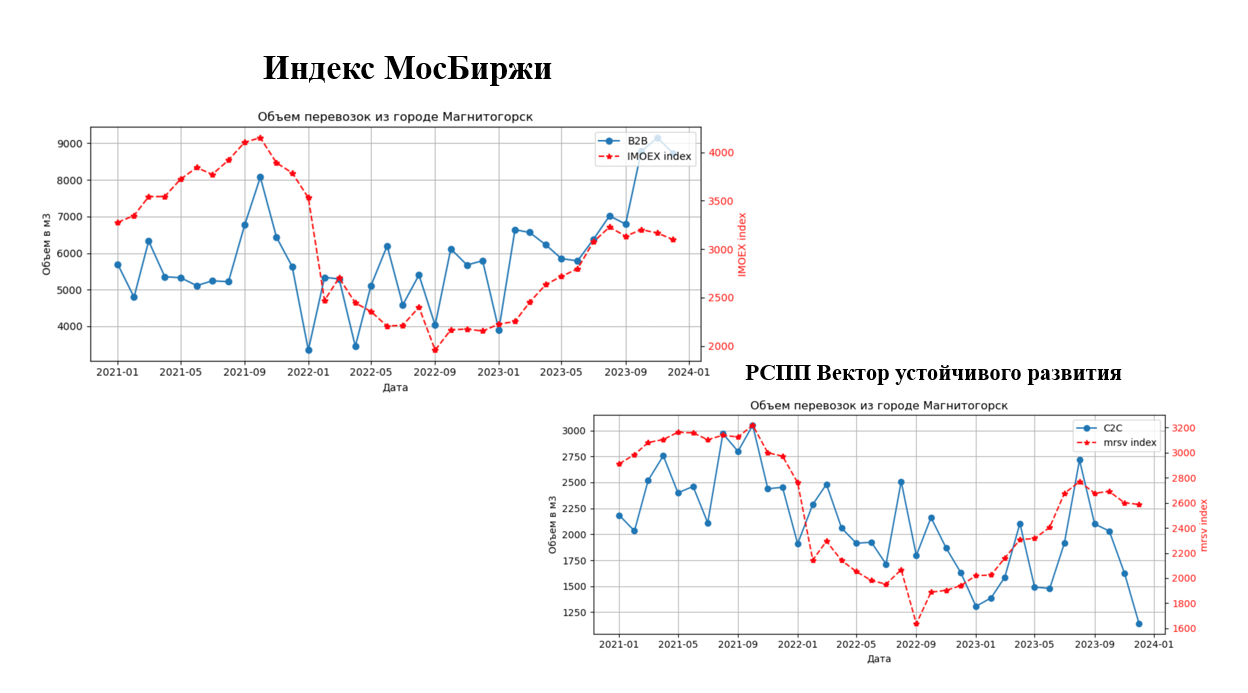
Команда ПЭК поделилась брифом по созданию модели машинного обучения. Назначение модели — предсказать объемы грузоперевозок на следующие месяцы. При этом модель должна была выдавать прогноз, опираясь на макроэкономические показатели.
Для команды победителей этот хакатон стал первым. Группа разработчиков состояла из незнакомых между собой людей, поэтому поначалу были сложности, притирки. Однако регулярные онлайн-встречи с брейнштормами, обсуждением работы и трекинг задач постепенно структурировали работу.
Нам было сложно с точки зрения коммуникации: люди друг друга почти не знали, задача была объемной и без четких границ в решении, но мы не отступили от работы. За три недели мы научились ставить честные дедлайны, не замалчивать проблемы, а сразу решать их. Кроме того, я укрепился в мысли: выбирать надо интересную вам тему. Благодаря этому вы будете выходить за рамки, учиться и постоянно генерить что-то новое.
Игорь Климов, тимлид команды победителей, студент магистратуры «Науки о данных» Skillfactory x МФТИ
Участники начали с проверки гипотезы «Объем грузоперевозок напрямую зависит от макроэкономической ситуации и глобальных процессов в экономике». После подтверждения этой гипотезы команда начала строить модель на значимых переменных.
Сбор факторов проводили в разных официальных источниках. Скрин от команды
Профессиональным вызовом для меня и команды стал сбор факторов, которые бы показывали высокую корреляцию с целевой переменной. Вначале мы не понимали, где и какие данные искать. Мы обратились к официальным источникам, статистике, к сайтам крупных компаний, на которых они выкладывают информацию о своих клиентах, сайтам с прогнозом погоды. Мы собирали макроэкономические показатели, индексы ММВБ, данные о климатической и демографической ситуации, а также тренды в поисковых системах. Выгрузку данных проводили вручную — это оказалось быстрее, чем автоматизировать процесс.
Игорь Климов, тимлид команды победителей, студент магистратуры «Науки о данных» Skillfactory x МФТИ
В разработке использовали модели Linear regression и Random Forest regression из библиотеки sklern, а также Catboost regressor из одноименной библиотеки. Оценивали модели по метрикам R-квадрат, RMSE и MAE, выбирая наиболее устойчивую и точную модель. Также студенты отбирали признаки для модели в процессе ее обучения, используя регуляризацию и итеративный отбор с контролем метрик, чтобы минимизировать шум в данных.
Изучите машинное обучение с нуля до продвинутого уровня и разработайте нейросеть на магистратуре с МИФИ. Теория от ведущих преподавателей России и практика на реальных задачах
Еще один бриф на хакатон принес отдел маркетинга ПЭК. Глобальной задачей было увеличить открываемость email-рассылок компании. Для этого партнер попросил команды Skillfactory создать рекомендательную модель, которая поможет разделить базу рассылки на сегменты и отправлять разным группам пользователей письма с разными маркетинговыми предложениями. Так вместо пятидесяти писем клиент будет получать пять. Но эти пять писем точно откроют и прочитают, а значит, повысится эффективность рассылки.
Мне очень понравилось задание: оно было прикладным, применимым на практике. Недостающую информацию для разработки мы искали в общем доступе: документация на библиотеки и различные статьи, в том числе на Хабре. Для разработки решения команда глубоко погрузилась в ML. Например, провели продвинутый feature-инжиниринг, который увеличил количество разрабатываемых алгоритмов и предусматривал превращение разрозненных данных в понятные модели. Отмечу, к готовому решению мы пришли не сразу, часть гипотез “сломалось” при более глубокой проработке или тестировании. Но набить шишки — это тоже опыт.
Баир Вамбуев, тимлид команды победителей, студент магистратуры «Науки о данных» Skillfactory x МФТИ
Основной костяк команды победителей сформировался еще в 2023 году. Поэтому распределение нагрузки прошло быстро. Участники не ограничивались пулом только своих задач, они заменяли и помогали друг другу. В основном коммуникация по проекту шла в чатах и GitHub. Однако были и сложности: один участник покинул проект — не получилось найти компромисс.
Главное, чему научил этот проект, — не опускать руки. У всех задач есть решения, просто иногда на их поиск нужно больше времени. Кроме того, мы научились внимательно читать бриф заказчика. Как оказалось, в нем можно найти наводки на готовое решение. А еще на практике осознали, что надо обязательно соблюдать правила написания на Python с помощью документа PEP8 и держать в порядке репозитарии на GitHub. Упорядоченность бережет время и нервы.
Баир Вамбуев, тимлид команды победителей, студент магистратуры «Науки о данных» Skillfactory x МФТИ
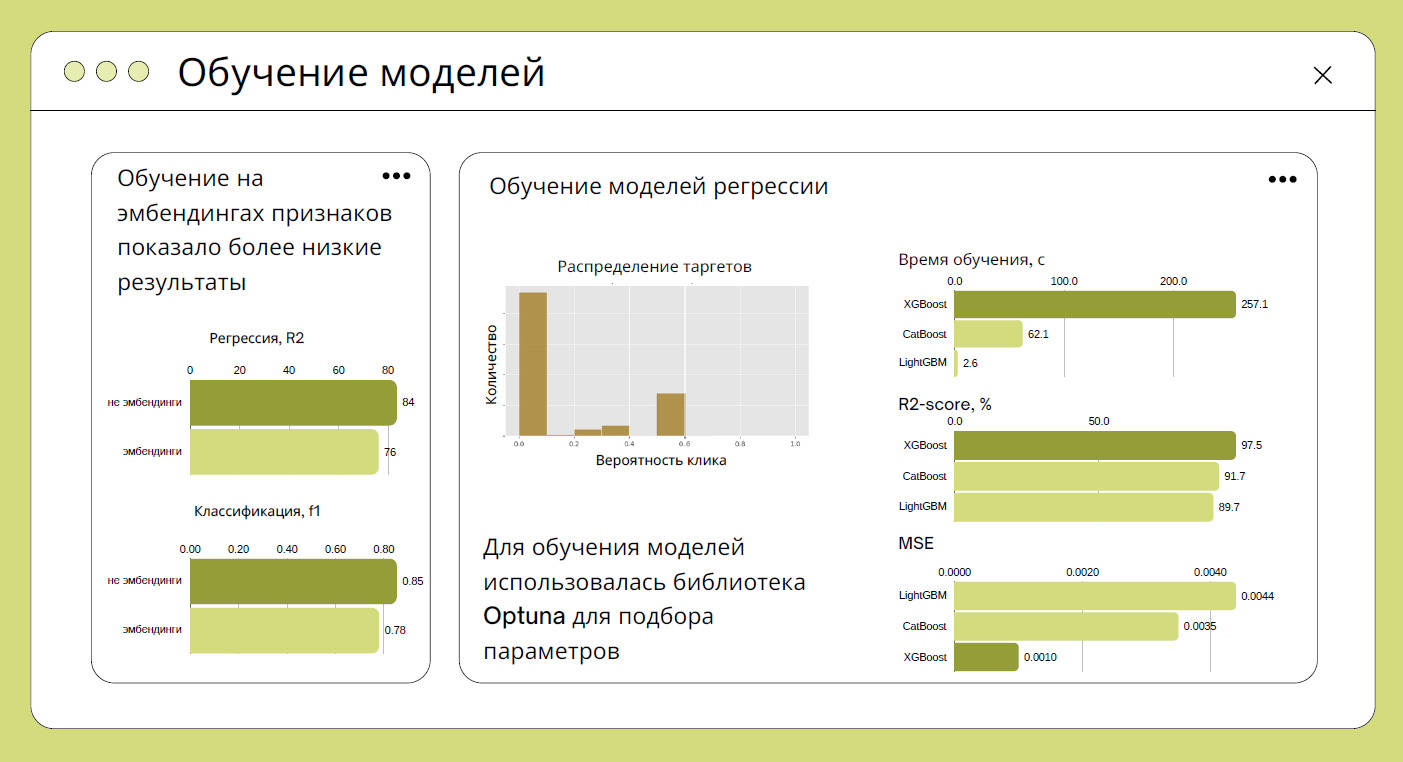
Для разработки участники использовали стандартные библиотеки для обработки, анализа и визуализации данных: Pandas, NumPy, Matplotlib, Seaborn, Statsmodels.
Так выглядит процесс обучения модели
Для создания итогового датасета работали с Scikit-learn, Torch. Для обучения рекомендательной модели взяли библиотеки с открытым исходным кодом: XGBoost, Catboost, Lightgbm. Кроме того, использовали Optuna — фреймворк для автоматизированного поиска оптимальных гиперпараметров.
Онлайн-магистратура с МИФИ по машинному обучению
Освойте Machine Learning на онлайн-магистратуре Skillfactory и НИЯУ МИФИ и станьте востребованным специалистом с опытом в индустрии. Пройдите дополнительный трек по MLOps и научитесь внедрять модели в продакшен. Знания от экспертов вуза и практиков из IT + интенсивная практика.