


Для работы с большими объемами информации дата-инженеры, аналитики и дата-сайентисты используют специальные инструменты. Один из них — Apache Spark. Это движок, который ускоряет вычисления и помогает находить ценные инсайты в данных.
Рассказываем вместе с инженером данных Оксаной Андросюк, что такое Apache Spark и чем он может быть полезен в разных задачах.
Как устроен инструмент
Apache Spark называют многозадачным движком. Он обрабатывает большие объемы структурированных и неструктурированных данных по принципу распределенных вычислений. То есть запускает несколько процессов одновременно, чтобы ускорить обработку данных.

Вот как работает Spark:
- Задачи внутри системы разбиваются на части и выполняются параллельно на нескольких компьютерах — их называют узлами кластера.
- Кластеры обрабатывают данные и хранят промежуточные результаты в оперативной памяти.
- В центре системы находится драйвер — компонент, который управляет процессом, распределяет задачи и собирает результаты.
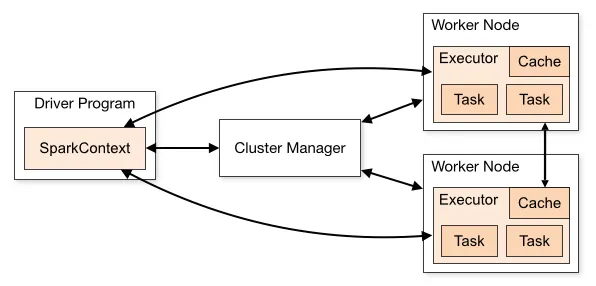
Что происходит с данными после обработки — зависит от задачи, для которой используют Spark. Их могут записать в базу или хранилище, отправить на сервер или загрузить в аналитическую систему. А если информацию обрабатывают в реальном времени, она отправляется в приложения и сервисы, которые автоматически реагируют на события.
Технические возможности Apache Spark
Apache Spark — универсальный инструмент для работы с данными. Он поддерживает все основные операции, которые специалисты выполняют с информацией. Вот что входит в его возможности.
Обработка больших данных (Batch Processing). Spark загружает данные в кластер и разбивает задачи между узлами. Это ускоряет расчеты и подготовку данных для дальнейшего анализа.
Обработка потоков данных (Stream Processing). Модуль Spark Streaming анализирует данные сразу при поступлении. Системы фиксируют события в момент их появления, например изменения в логах серверов или действия пользователей.
Машинное обучение (Machine Learning). Во встроенную библиотеку MLlib входят алгоритмы классификации, регрессии, кластеризации и другие инструменты для построения моделей.
Аналитика с помощью SQL и DataFrames (Spark SQL). Spark выполняет SQL-запросы и помогает работать с большими данными как с привычными таблицами. Это проще и удобнее, чем использовать альтернативные методы — например, низкоуровневый способ работы с данными RDD, который требует написания сложного кода. В случае с SQL к данным можно обращаться напрямую, без трудоемких преобразований.
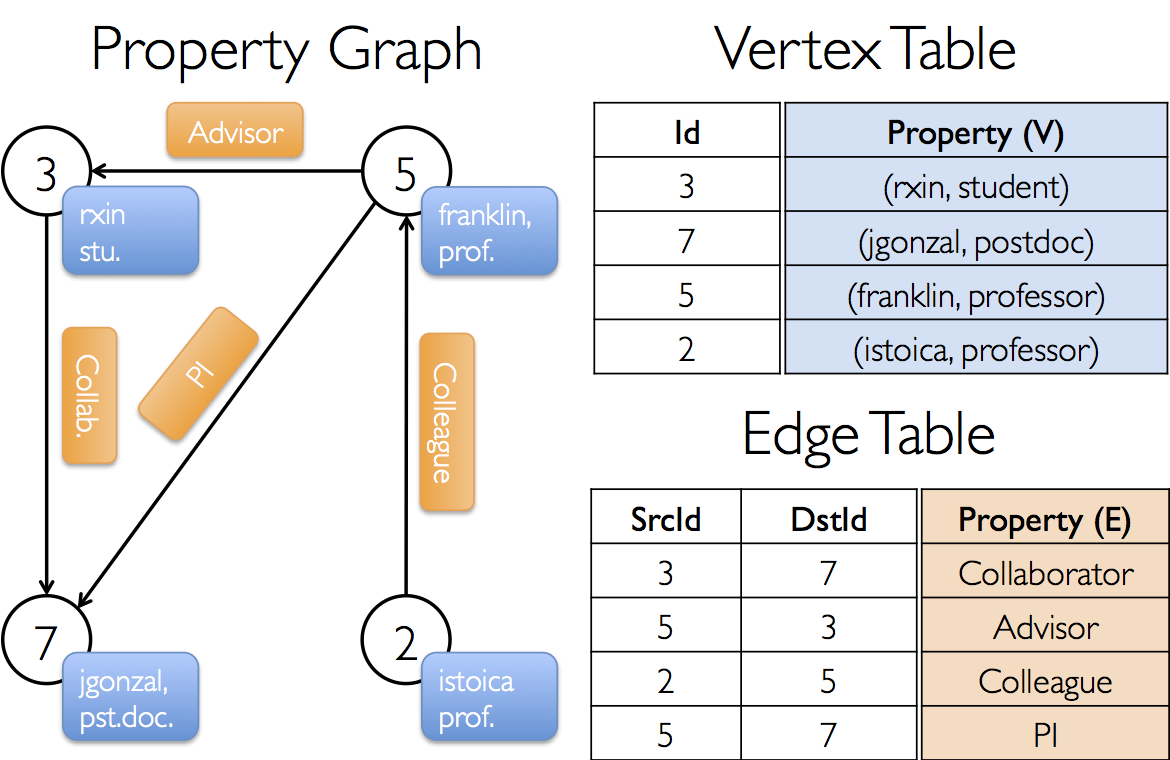
Обработка графов и сетевых данных (Graph Processing). Модуль GraphX анализирует и обрабатывает структуры графов.
Работа с различными источниками данных (Data Source Integration). Платформа поддерживает работу с информацией из множества разных систем, например HDFS, S3, Cassandra, Kafka. С помощью Spark данные можно обрабатывать без переноса в другие хранилища.

Распределенное вычисление и параллелизм (Distributed Computing). Во время работы Spark автоматически распределяет задачи между узлами кластера. Данные обрабатываются параллельно. Благодаря этому инструмент легко масштабируется и работает быстрее, чем традиционные системы обработки данных.
Кэширование и работа в памяти (In-Memory Processing). Промежуточные результаты обработки данных Spark сохраняет в оперативной памяти. Это дополнительно ускоряет его работу.
Управление отказами (Fault Tolerance). Spark использует механизм DAG — Directed Acyclic Graph, или ориентированный ациклический граф. С помощью этой структуры данных Spark автоматически восстанавливает работу после сбоев и остается устойчивым к ошибкам.
Расширение и кастомизация (Extensibility). Специалисты могут создавать пользовательские функции (UDF) и интегрировать Spark с языками программирования — Scala, Java, Python и R. Это помогает настроить платформу под задачи конкретного проекта или компании.
Для чего бизнес использует Apache Spark
Фреймворк применяют в любых сферах, где работают с большими данными. Его часто используют банки и финансовые компании, крупные ритейлеры, медиаплатформы и телеком-операторы.
Spark помогает бизнесу решать сразу несколько задач.
- Анализ больших данных. Spark обрабатывает терабайты и петабайты данных намного быстрее, чем традиционные инструменты. Благодаря этому бизнес вовремя получает информацию для принятия решений.
Например, ритейлеры используют большие данные, чтобы анализировать предпочтения покупателей. На основе результатов компании формируют ассортимент и определяют, какие товары предлагать в первую очередь.
- Обработка и интеграция данных. Инструмент легко подключают к хранилищам и источникам информации. Его часто используют для построения ETL-процессов — извлечения, преобразования и загрузки данных.
- Аналитика в реальном времени. В платформе есть модуль Spark Streaming. Он обрабатывает данные по мере их поступления, поэтому можно мониторить события и реагировать на них в реальном времени.
Например, банки используют такую аналитику, чтобы замечать сомнительные операции и пресекать мошенничество. Система сразу блокирует подозрительную транзакцию, и клиент не теряет деньги.
- Задачи машинного обучения. Spark помогает подготовить данные перед обучением моделей, а встроенная библиотека MLlib — обучать и масштабировать их.
Например, стриминговые сервисы анализируют поведение пользователей, чтобы предлагать музыку и фильмы, которые им понравятся.
- Поиск связей в структурах данных. Spark помогает разбирать сложные структуры и находить важные зависимости. Бизнес использует эту информацию для оптимизации процессов и принятия решений.
Например, можно изучить с помощью Spark базу данных по клиентам и их взаимодействия, чтобы понять, какие из них самые ценные. Или посмотреть на цепочку поставок, чтобы увидеть, где возникают задержки.
Ограничения инструмента
Распределенная работа и возможность хранить данные в оперативной памяти дают Spark преимущества перед традиционными системами. Но есть и особенности, которые стоит учитывать при работе с ним.
Главное ограничение — ресурсоемкость. Для стабильной работы требуется много оперативной памяти, а при обработке больших данных нагрузка на систему возрастает. С небольшими объемами информации Spark не всегда оправдан: в таких случаях проще использовать Pandas или SQLite.
Еще один минус — ограниченный контроль над низкоуровневыми операциями. В некоторых задачах это критично, например при оптимизации работы с памятью и детальном управлении распределением данных по узлам кластера.
Кроме того, Spark — довольно сложный инструмент. Развертывание и настройка кластера требуют опыта, а для работы с ним нужны квалифицированные разработчики и администраторы.

Какие инструменты используют вместе с Apache Spark
Spark часто применяют в связке с другими технологиями для работы с данными. Среди них:
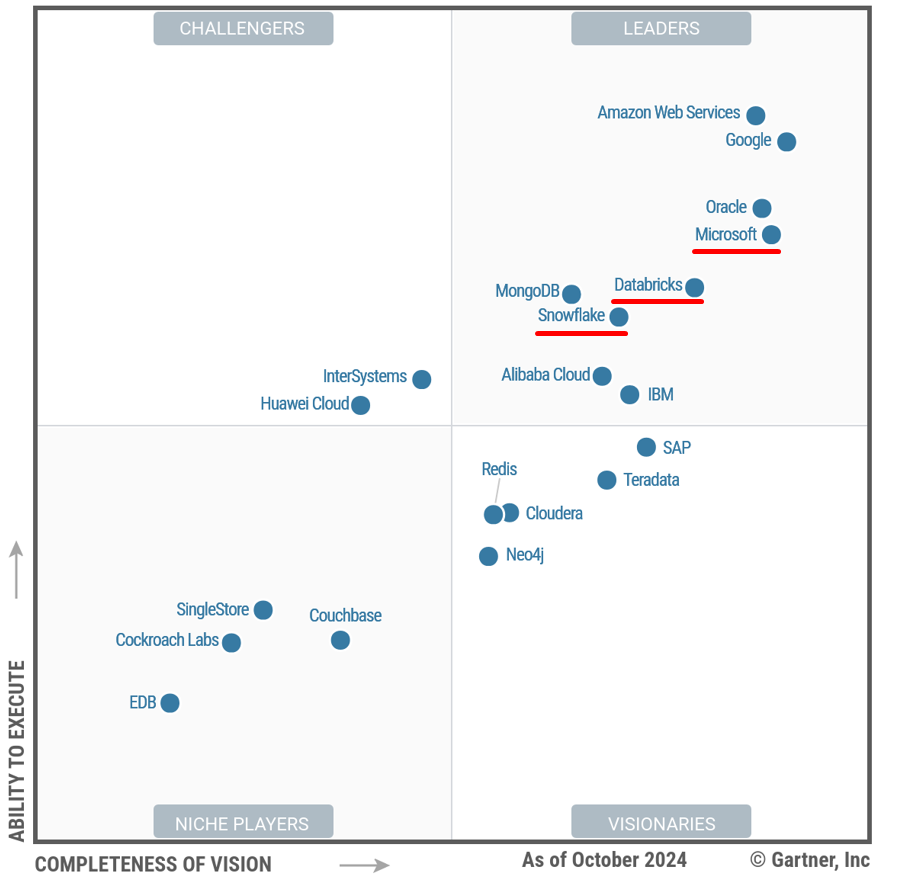
- Databricks — облачная платформа, предназначенная для работы с большими данными и машинным обучением. Она основана на Apache Spark и предоставляет удобные инструменты для разработки, анализа данных и создания моделей ИИ;
- Snowflake — облачная платформа для хранения и обработки данных, которая позволяет компаниям хранить, управлять и анализировать большие объемы информации.
- Microsoft Fabric — платформа для управления данными и аналитики, объединяющая хранилище, обработку потоков, машинное обучение и интеграцию с Microsoft Power BI;
- Apache Kafka — система помогает обрабатывать потоковые данные, которые анализируют в реальном времени.
В этих средах Spark работает как вычислительный движок — ядро, где происходят распределенные вычисления. Он обрабатывает данные, которые потом передаются в другие инструменты для аналитики, хранения и дальнейшей обработки. Получается инфраструктура, где множество систем строится вокруг Apache Spark.
Databricks, Snowflake и Microsoft Fabric являются аналогами друг друга с некоторыми отличиями, за счет которых стараются получить лидерство на рынке.
Что нужно знать для работы с Apache Spark
С Apache Spark работают дата-инженеры, дата-сайентисты, разработчики больших данных, аналитики и инженеры по машинному обучению.
Чтобы использовать Apache Spark, нужны конкретные знания и скилы, среди которых:
- Базовые знания в области обработки данных и распределенных вычислений. Нужно понимать, по какому принципу работают кластерные вычисления, как обрабатывать большие объемы данных и масштабировать задачи для разных узлов.
- Языки программирования. Специалист должен хорошо владеть хотя бы одним из языков, которые используют для работы с данными: Python, Scala, Java или R.
- Знания в SQL. Чтобы составлять SQL-запросы к хранилищам с помощью Spark, специалист должен владеть этим языком и уметь работать с базами данных.
- Навыки работы с другими платформами. Обычно Spark используют вместе с Databricks, Snowflake, Microsoft Fabric — нужно уметь работать и с ними. Многие платформы выпускают обучающие материалы: например, у Databricks есть подробное руководство по работе со Spark.
Любому специалисту важнее всего понимать, как использовать Spark для решения конкретно своих задач. Например, ML-специалисту пригодится библиотека MLlib, а дата-аналитику — Apache Spark SQL.
Краткие выводы
- Apache Spark — это в первую очередь инструмент для обработки больших данных. Выполняет параллельную обработку данных, что позволяет работать c большими объемами информации.
- Spark используют для решения разных задач, связанных с обработкой больших данных, включая их подготовку перед загрузкой в хранилища, API или системы аналитики и др.
- Поддерживает пакетную и потоковую обработку (то есть может работать с данными в реальном времени).
- Включает модули для машинного обучения, работы с графами и SQL-запросов.
- Spark обеспечивает быструю обработку данных, но достаточно ресурсоемкий, поэтому при небольших данных лучше посмотреть альтернативы. Чаще всего используется вместе с Apache Kafka, Databricks и другими системами, выполняя вычисления и выступая в роли основного движка обработки данных.