


Важный подготовительный шаг при работе с данными — их очистка, или Data Cleaning. Ее применяют в дата-аналитике, Big Data, при работе с моделями машинного обучения и нейросетями. Зачем это нужно и что значит «очистить данные» — давайте разбираться.

Зачем и от чего очищают данные
Представьте, что вам нужно найти в сети ответ на какой-то вопрос. Но половина статей в поиске — на другую тему, а еще во многих сведения устарели или неверны. В таких обстоятельствах будет сложно отыскать корректный ответ.
Модели в Data Science и машинном обучении сталкиваются с такой же проблемой. Среди данных, на которых они обучаются, может быть немало «мусора»: некорректных значений, ошибок, дублей. Они возникают, потому что информацию обычно собирают из множества разных источников — в каждом свое представление сведений. Из-за этого данные в выборке получаются разнородными, а порой и некорректными.
Модель способна обучаться и на «грязных» данных, но это может сильно снизить ее точность. Если не очистить информацию перед загрузкой в модель, велик риск, что в итоге она будет давать некорректные результаты — скажем, прогнозы, далекие от истины.
Поэтому, чтобы модель работала точно, перед ее обучением нужно очистить данные от «мусора»:
- удалить ошибки и несоответствия, которые встречаются в выборке данных;
- привести данные к единому виду, например объединить одинаковые признаки;
- заполнить недостающие значения, убрать дубли;
- избавиться от шумов и выбросов — случайных значений, которые резко отличаются от большинства.
Какими бывают ошибки в данных
Обычно информация содержится в специальных хранилищах — базах данных. Они могут быть устроены по-разному, но чаще всего сущности в базах можно разделить на две категории:
- записи — строки в таблице, какие-то объекты, которые состоят из множества признаков;
- признаки — значения в ячейках таблицы, которые описывают какие-то характеристики объекта.
Например, у нас есть запись о пользователе misha. Эта запись — строка таблицы, в которой собраны все признаки пользователя misha. Признаками могут быть никнейм, возраст, пол, данные об активности и так далее. Вместе они и составляют запись.
Ошибки в данных могут относиться или к признаку, или к записи. Для каждой категории выделяют несколько распространенных видов «загрязнений».
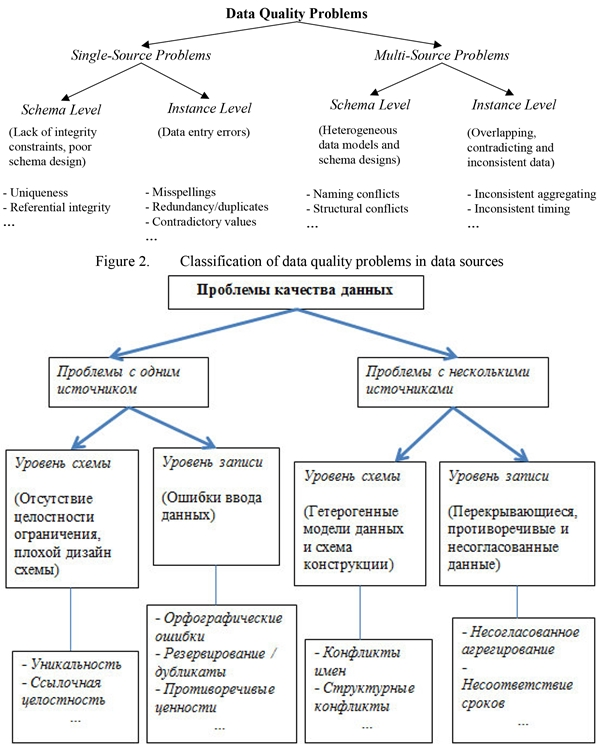
Ошибки в записях. На уровне целой записи может встретиться четыре вида ошибок:
- неуникальность — какое-то значение должно быть уникальным, но повторяется в нескольких разных записях. Например, у двух человек одинаковый номер паспорта;
- дублирование — какой-то объект описан дважды, например в базе есть два абсолютно одинаковых пользователя;
- противоречия — данные об одном объекте в разных местах различаются, к примеру фамилия человека пишется то как Балашев, то как Балашов;
- неверные ссылки — связи между признаками в одной записи нарушены, например имя и фамилия перепутаны между собой.
Ошибки в признаках. На уровне одного признака возможных ошибок больше — вот несколько основных видов:
- отсутствие значения — какая-то ячейка остается пустой — например, у человека нет имени или набор нулей вместо телефона;
- некорректное значение — в ячейке есть информация, но она не подходит по формату — скажем, возраст 2О вместо 20;
- орфографические ошибки — слово написано неверно, например «Санктпетербург» вместо «Санкт-Петербург»;
- многозначность — одно и то же значение в разных признаках называется по-разному — скажем, «медсестра» и «медицинская сестра»;
- аномальные значения — информация в признаке не может быть реальной — например, возраст живого человека указан как 271 год, а дата — как 34 марта;
- перестановка слов — слова в значении в разных местах имеют разный порядок — к примеру, «материал строительный» и «строительный материал»;
- вложенность значений — в одном признаке оказывается несколько значений — скажем, город «Пермь, Пенза».
В данных, которые отражают показания каких-то приборов, также встречаются шумы — помехи, например шорох на звуковой дорожке или полосы на видео. А если информацию собирали из разных источников, может возникнуть проблема разнотипных данных: в одном месте дата пишется как 7 апреля, а в другом — как 07.04.
Если ошибки останутся в выборке, модель может воспринять их неправильно и позже выдавать неверные ответы. Скажем, она действительно будет считать «Санктпетербург» отдельным городом, не имеющим отношения к Санкт-Петербургу. Или запомнит, что в марте 34 дня.

Как устроена очистка данных
Данные для аналитики или обучения моделей — это огромные выборки. Удалять «мусор» из сотен тысяч значений вручную сложно, а порой и невозможно, поэтому чаще всего процесс автоматизируют.
Поговорим о том, что такое «очистить данные» с технической точки зрения. Существует три основных подхода к очистке.
- Полностью автоматизированная очистка — специалист использует инструменты для Big Data, которые встроены в систему управления базой данных, например Apache Hive. Либо очищает данные с помощью аналитических систем, таких как SAS или IBM SPSS.
- Очистка с помощью скриптов — специалист самостоятельно пишет скрипты, например на языке Python. Эти скрипты обрабатывают данные и очищают их по заданным правилам.
- Очистка вручную — специалист сам просматривает выборку и удаляет ошибки. Этот способ применяется очень редко, обычно на небольших выборках или как вспомогательный.
При очистке специалист или программа применяет разные методы — скажем, какие-то данные исправляются, какие-то стираются из базы. Вот несколько примеров, что можно сделать с данными в ходе очистки.
Удалить. Если данные дублируются или противоречат друг другу, их удаляют по какому-либо алгоритму. Например, для дублей можно оставлять только первый или только последний экземпляр записи. А для противоречий — только одно из значений.
Сравнить. Этот метод используется, если информация различается в разных местах. Данные сравниваются по ряду критериев — в итоге выбирается значение, похожее на реальное, и подставляется вместо некорректного.
Скажем, телефон одного и того же пользователя в двух разных местах записан по-разному. Можно посмотреть, как этот телефон указан в третьем месте, и понять, какое из значений верное.
Исправить. Чтобы заменить данные, не всегда нужно сравнивать их с другими значениями из базы. Например, опечатки в словах исправляют с помощью словаря — в нем описано, как правильно пишется то или иное слово. А очевидные «выбросы» заменяют на какое-либо среднее значение.
Скажем, вместо имени человека в одном месте стоит скобка. Это явно ошибка — неверно считались данные. Можно подставить какое-то среднестатистическое значение имени, например «Татьяна Кузнецова».
Выбранный метод должен качественно очищать выборку от ошибок — и если она собрана из одного источника, и если данные взяты с разных каналов. Важно, чтобы этот метод поддерживался инструментами, с которыми работает специалист, и мог адаптироваться к изменениям — например, другим источникам данных.
Как происходит очистка данных: этапы
Перечисленные здесь этапы очистки — приблизительные. В зависимости от выборки, метода очистки и других факторов процесс может отличаться. Этот пример нужен, чтобы дать представление, как в целом выглядит работа с очисткой.
Анализ данных. Перед началом очистки специалист анализирует выборку, чтобы понять, насколько она загрязнена и какие ошибки в ней встречаются. Частично он может проанализировать ее вручную, но обычно для этого используются специальные сервисы — они определяют и выводят свойства данных в выборке. Например, показывают диапазон значений в поле «Цена»: аномальные значения будет видно сразу.
Продумывание процесса. Когда специалист получает метаданные — то есть данные о данных, — он может решить, как именно будет очищать выборку. На этом этапе он определяет, какие преобразования понадобятся, какие использовать правила и методы.
Преобразования. Специалист использует инструменты или пишет скрипты, которые изменяют данные. Самое главное — задать логику. Например, автоматизированные инструменты СУБД могут выполнять преобразования сами, если указать для них правила. Но для этого преобразования должны быть четко описаны.
Кроме того, если для каких-то ошибочных данных нужны точные значения, их иногда приходится получать вручную. Например, заново запрашивать большой объем информации, которая передалась некорректно.
Проверка. Специалист должен убедиться, что преобразования выполнены верно. Поэтому еще до работы с полной выборкой он может протестировать скрипт или набор правил на какой-то небольшой группе записей. Это поможет ему убедиться, что очистка происходит корректно. А если в логике обнаружатся ошибки — устранить их.
Запуск очистки. Проверенный алгоритм запускают на полной выборке, и тот выполняет все необходимое: удаляет лишнее, приводит данные к единому виду, корректирует значения.
Загрузка очищенных данных. Очищенную выборку загружают в базу и сохраняют. При этом нужно убедиться, что все инструменты, которые пользуются этой выборкой, имеют доступ к очищенной версии. Например, изменить путь к данным в модели так, чтобы он вел к новой версии выборки.
Что учитывать при очистке данных
- Полноценная очистка — довольно сложный процесс, который требует участия человека. Поэтому не стоит всегда полагаться только на автоматику. Куда лучше, если специалист и сам анализирует имеющиеся у него сведения — например, метаданные.
- Желательно не просто находить ошибки, а узнавать причины их появления. Например, информация повредилась при первоначальной загрузке в базу или неверно считалась. Если выявить причины — можно создать более совершенные методы очистки.
- Помните, что каждая выборка индивидуальна. Поэтому и методы, и количество шагов в очистке данных могут различаться от случая к случаю. Не стоит использовать для всего один и тот же способ — выбирайте то, что лучше подходит в конкретной ситуации.
Выводы
- Очистка — это изменение набора данных, чтобы удалить или исправить ошибки в нем. Это важно для анализа данных и обучения ML-моделей — с неочищенными данными результаты будут неточными.
- В данных встречаются разные типы ошибок, например опечатки, шумы, неверные значения или некорректный формат информации. Все их нужно выявить и исправить, привести сведения к единому виду.
- Очищать данные можно вручную, с помощью скриптов или полностью автоматически — за счет специальных аналитических платформ и СУБД. Какой метод выбрать для конкретной выборки, зависит от ситуации.
- Иногда при очистке данных нужно ручное вмешательство человека, например чтобы обнаружить причину появления ошибки или запросить корректные сведения.
