

Ежегодно пользователи соцсетей в шутку поздравляют адвоката Бейонсе, который много лет назад «удалил» неудачную фотографию певицы из интернета. Разумеется, в честь этого они снова и снова публикуют тот самый снимок: ведь всё, что было загружено в сеть, невозможно стереть навсегда.

Это касается не только текстов, фото и видео, но даже устаревшего интерфейса страницы или изменённого дизайна. А сохраняет всю информацию Web Archive. В статье расскажем, как он устроен, и как найти старую версию любимого сайта.
Что такое архив интернета
Архив интернета, «Веб-архив», Wayback Machine или Web Archive — это цифровое хранилище данных, в котором содержатся копии когда-либо существующих веб-страниц, оцифрованные книги, видео и аудио, а также программы и приложения. Благодаря ему любой пользователь может получить доступ к предыдущим интерфейсам конкретного сайта или версии справочника, который в бумажном виде уже не найти.
Сервис создал Брюстер Кейл в 1996 году в Сан-Франциско, США. По его словам, цель архива — сохранить международное культурное наследие и не допустить исчезновения важных материалов. Сегодня Wayback Machine содержит более 946 млрд страниц и доступен по адресу: web.archive.org. В России его можно просматривать без VPN.

Зачем нужен Web Archive
Web Archive необходим тем, кто хочет понять, как менялись сайты, технологии и тренды за многие годы. Также он пригодится людям, которые анализируют контент или решают практические задачи, например пишут научные работы или обновляют ресурсы. Рассмотрим, зачем архив интернета нужен представителям разных профессий:
- Маркетологи. Анализировать эволюцию брендов и стратегий конкурентов. Например, какие офферы работали раньше, как менялись посадочные страницы, структура сайтов и подходы к коммуникации.
- SEO-специалисты. Восстановить утраченные страницы и ссылки. Так, с помощью Web Archive получится вернуть контент, который приносил трафик, но по каким-то причинам исчез.
- Разработчики. Восстановить старую версию проекта или понять, как работали те или иные функции в прошлом.
- Историки и преподаватели. Показывать студентам эволюцию веба: от первых сайтов до современных интерфейсов.
- Журналисты и исследователи. Увидеть страницы до редизайна, старые тексты и другой контент до удаления. Это особенно важно, чтобы проводить расследования, проверять факты и отслеживать историю компаний или продуктов.
Наконец, архив интернета часто используют просто для развлечений. Например, чтобы поностальгировать о прошлом и увидеть, как выглядела любимая соцсеть до масштабного редизайна.
Как информация попадает в архив интернета
Архивация информации в Wayback Machine выглядит так же, как индексация поисковыми системами. Так, у Яндекс или Google есть поисковые роботы, которые сканируют страницы сайтов, а затем сохраняют тексты и ссылки.
У «Веб-архива» тоже есть роботы, которые действуют аналогичным образом и сохраняют на свои серверы всю информацию. При этом сервис не уточняет, как именно они работают. Известно лишь, что архив собирает исключительно общедоступные данные. А если владелец сайта хочет что-то скрыть от Wayback Machine, можно установить пароль и настроить процесс индексирования.
Когда роботы «Веб-архива» попадают на страницу второй и последующие разы, они не удаляют со своих серверов предыдущие версии и делают новые копии. В результате получится посмотреть, как сайт выглядел в разное время. Однако нет гарантии, что вы найдёте в «Веб-архиве» нужный ресурс. Возможно, робот до него так и не дошёл или не сделал копию интересующего вас отрезка времени.
Какие данные хранятся в Web Archive
В Web Archive сохраняются не только сами веб-страницы, но и всё, что делает их полноценной частью интернета:
- HTML-файлы. Это основа архива. Содержат тексты, заголовки, ссылки и метаданные. Вместе с ними сохраняются изображения, таблицы стилей (CSS), скрипты и другие элементы, которые отвечают за оформление и базовую функциональность сайта. Благодаря HTML-файлам многие архивные версии выглядят почти так же, как оригинальные.
- Структура сайта. Включает навигацию, внутренние ссылки, адреса страниц и даже порядок их обновления. Это позволяет восстанавливать не только внешний вид ресурса, но и логику его работы.
- Технические данные. Сюда входят заголовки HTTP, даты последнего обновления, коды ответов сервера. Эти сведения позволяют отслеживать, как менялась производительность или конфигурация сайта. Однако не все страницы в Web Archive содержат технические данные.
Важно помнить, что архив интернета не хранит интерактивные элементы в полном объёме: формы, личные кабинеты, динамические базы данных и платёжные системы, как правило, не сохраняются. Сервис фиксирует лишь то, что доступно публично на момент сканирования.
Как пользоваться Web Archive
Перейдите на сайт Web Archive — web.archive.org. Найдите строку поиска, введите адрес интересующего ресурса и нажмите клавишу Enter:
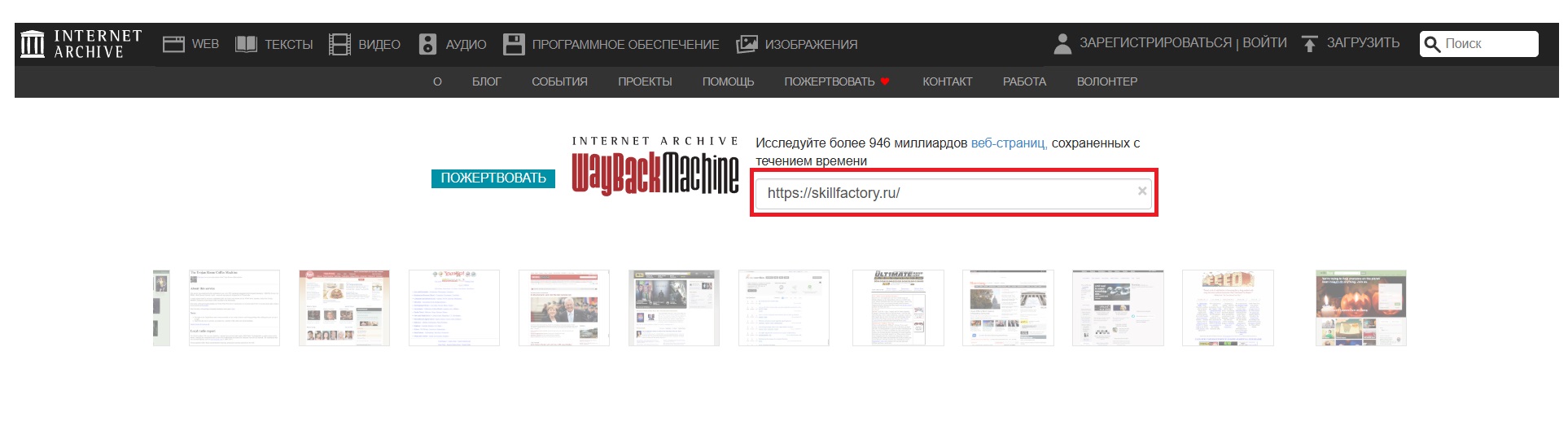
Wayback Machine мгновенно соберёт для вас всю информацию по сайту, которая есть на серверах, и распределит её по нескольким разделам:
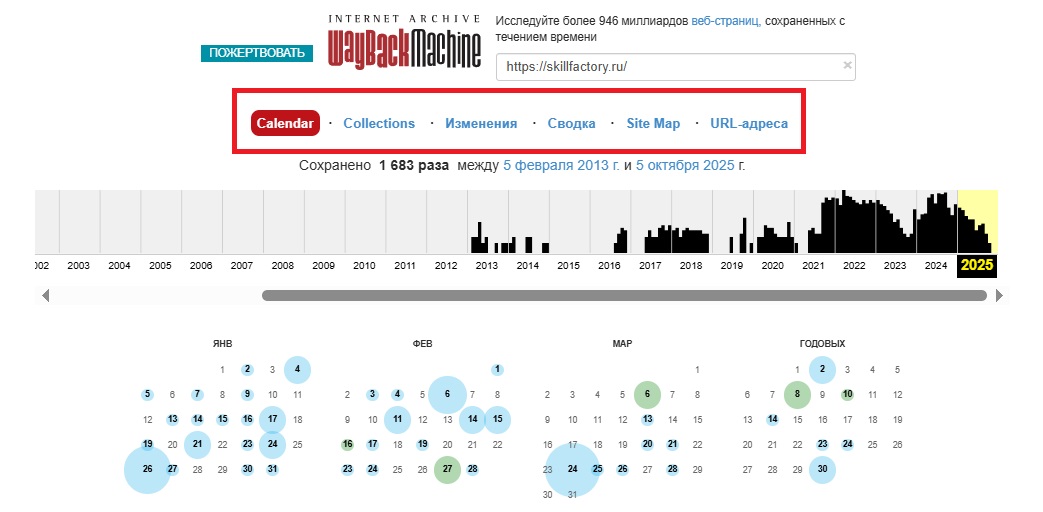
- Календарь (Calendar). Показывает все версии страницы, которые сохранил робот, по датам. Каждая точка на временной шкале — это момент, когда Web Archive зафиксировал состояние сайта. Раздел позволяет «перемещаться во времени» и смотреть, как страница выглядела в разные годы или даже дни.
- Коллекции (Collections). Объединяют сайты и страницы по тематикам, источникам или событиям. Это удобно для исследователей и журналистов, которые изучают цифровые следы по конкретным темам — от выборов до пандемии. Коллекции для конкретного сайта нужны, чтобы понять, в какие тематические группы он входит.
- Изменения (Changes). Показывают, как менялось содержимое страницы между двумя датами — в текстах, ссылках и структуре. Раздел помогает быстро заметить обновления. Например, когда компания изменила дизайн или контент корпоративного сайта.
- Сводка (Summary). Краткий обзор сохранённых версий страницы, в том числе количество снимков, первое и последнее сканирование, частота обновлений. Помогает быстро оценить, насколько активно архивировался ресурс.
- Карта сайта (Site Map). Отображает структуру сохранённого сайта — какие страницы были зафиксированы, как они связаны между собой, какие разделы чаще всего обновлялись в Web Archive.
- Адреса (URLs). Содержит список всех ссылок конкретного сайта. Здесь можно найти старые адреса страниц, которые уже не работают, но остались в архиве.
Рассмотрим разные сценарии использования «Веб-архива».
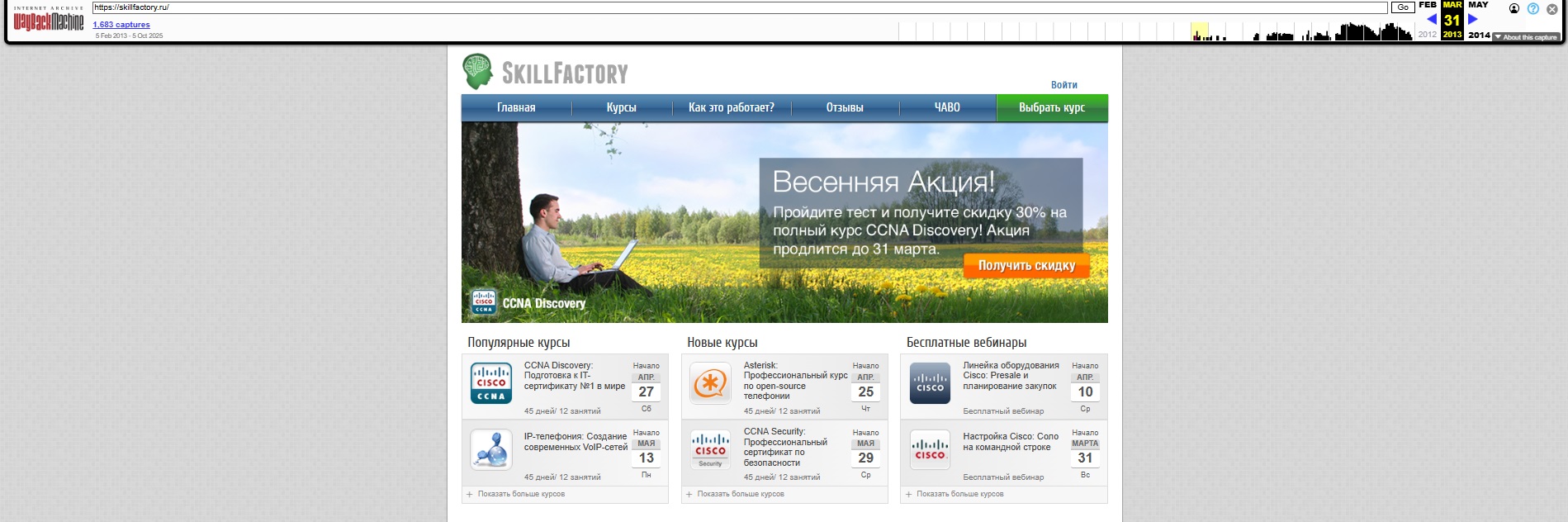
Посмотреть, как выглядел сайт в конкретное время
Воспользуйтесь разделом «Календарь». Дни в нём могут быть отмечены разными цветами в зависимости от результата, который получил Web Archive, когда сканировал сайт:
- Синий. Бот перешёл на сайт и без проблем сохранил его копию. Её можно посмотреть.
- Зелёный. Робот перешёл по ссылке, но попал на другой адрес.
- Красный. Роботу не удалось сделать копию, потому что ресурс не загрузился.
Чтобы увидеть, как страница выглядела в конкретный день, нажмите на дату, выделенную синим цветом. Если снимков несколько, будет и несколько временных отметок — нужно выбрать интересующую.
Сравнить версии одной и той же страницы
Перейдите в раздел «Изменения» (Changes). Выберите две разные даты и кликните на Compare — в новом окне откроются обе версии. Они будут расположены рядом для более удобного сравнения.

Получить сводку по копированию страниц
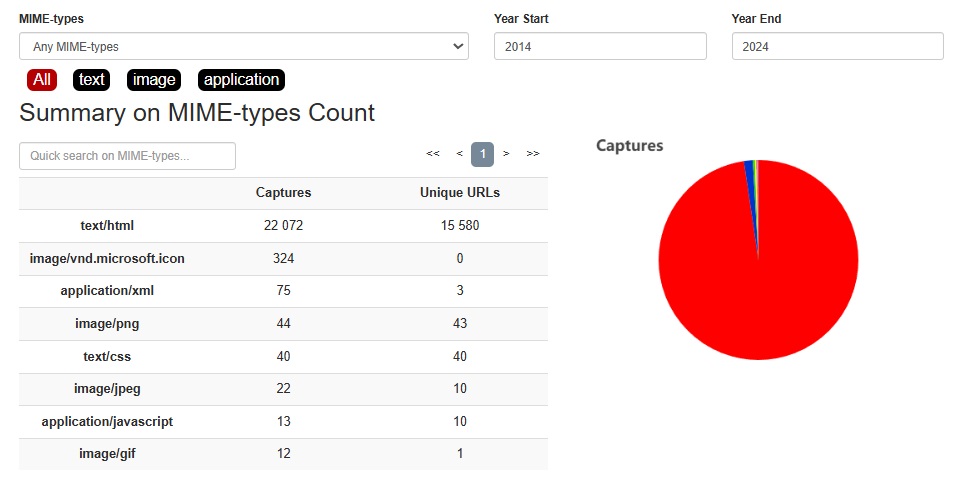
Откройте раздел «Сводка» (Summary), чтобы посмотреть всё, что сервис Wayback Machine собрал о ресурсе. Информация здесь представлена в виде графиков и таблиц, поэтому её удобно анализировать. Сверху можно выбрать нужный период и тип интересующих вас файлов в разделе MIME-types. Это метки, которые обозначают вид файла и его формат. Например, image/png — изображение png.
Допустим, вы установили такие настройки: период — с 2014 по 2024 год. Сервис покажет, что за это время он скопировал с сайта Skillfactory 44 иллюстрации в формате png и 22 072 HTML-страницы.
Уточнить историю сохранений
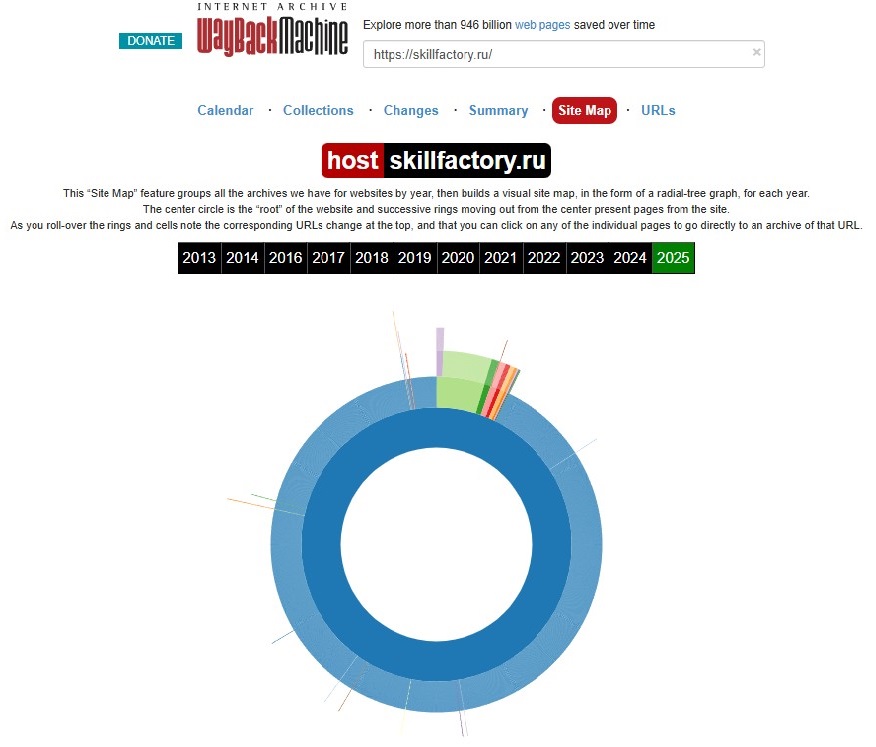
Ещё в «Веб-архиве» можно посмотреть, как часто сервис сохранял информацию с сайта и что именно копировал. Для этого перейдите в раздел «Карта сайта» (Site Map). Откроется круговая диаграмма: она показывает уровни вложенности страниц, которые обнаружил робот Web Archive.
Центральный круг — главная страница сайта. Второй — страницы первого уровня вложенности. Например, у Skillfactory это страницы курсов конкретных профессий: skillfactory.ru/backend-razrabotchik-na-golang или skillfactory.ru/data-analyst-pro. Далее идут следующие по иерархии внутренние страницы. Бывает, на диаграмме мало информации. Значит, Web Archive сохранил мало версий сайта в конкретный год.
Посмотреть даты сохранений
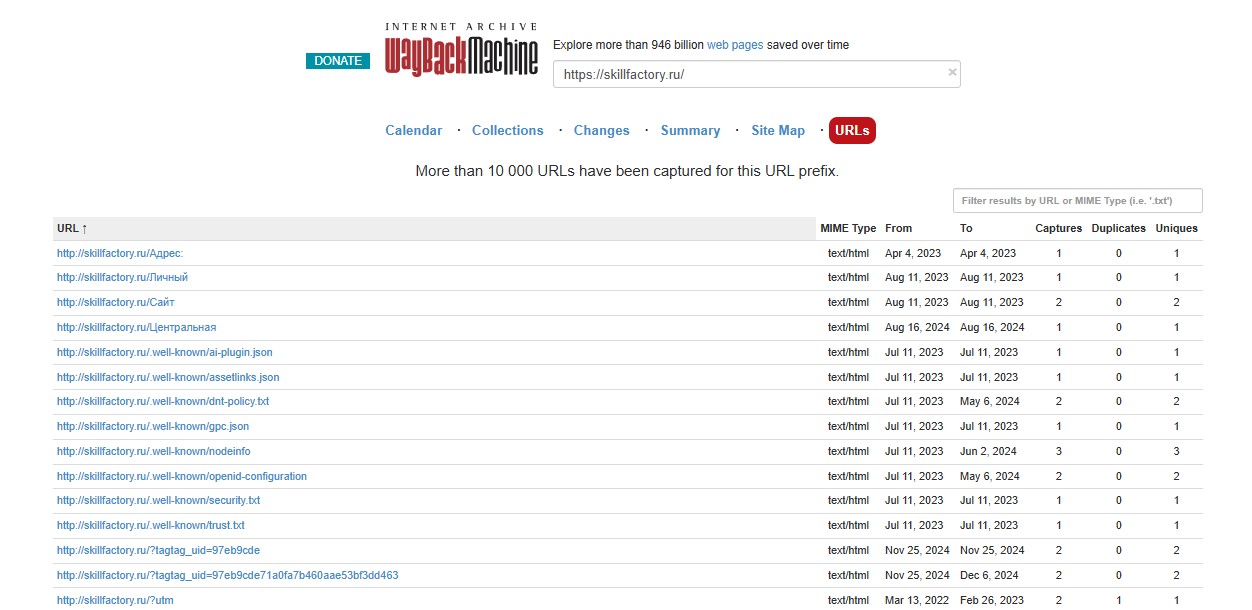
Во вкладке «Адреса» (URLs) есть сводная таблица по каждой странице сайта. В ней содержится подробная информация о сохранениях. Например, тип скопированных данных, дата первого и последнего копирования и общее число сохранений. Также есть пометка, сколько раз робот посещал страницу в целом.
Сверху можно настроить таблицу так, чтобы она показывала информацию за определённый период. Либо сразу указать в поисковой строке нужный адрес, например, не «skillfactory.ru», а «https://skillfactory.ru/python-developer» и добавить к нему символ *.
Аналоги Web Archive
Есть несколько сайтов, похожих по своим функциям и назначению на Wayback Machine. Один из самых известных — Archive.today (ранее известен как archive.ph). Он тоже делает копию страницы и гарантирует, что контент останется доступным даже после удаления оригинала. В отличие от Wayback Machine, Archive.today не полагается на автоматическое сканирование — пользователь сам добавляет ссылки для архивации.
Ещё один инструмент — Perma.cc от Гарвардской библиотеки. Его основная цель — сохранить ссылки научных и юридических публикаций. Пользователи сами могут создавать копии веб-страниц, чтобы предотвратить «битые ссылки» в документах и исследованиях.
Также существует Memento Project, который объединяет различные веб-архивы в одну сеть. Он позволяет искать старые версии сайтов сразу в нескольких хранилищах, включая сам Wayback Machine, национальные архивы и университетские коллекции. Если нужной страницы нет в одном источнике, Memento поможет найти её копию в другом.
Web Archive: коротко о главном
- Web Archive — это онлайн-сервис, который сохраняет копии веб-страниц и позволяет просматривать их так, как они выглядели в прошлом. Также содержит программы и оцифрованные материалы. Платформа используется, чтобы восстанавливать утраченный контент, получать доступ к редким книгам, фотографиям и видео и анализировать изменения сайтов.
- Архив работает через автоматических роботов, которые регулярно сканируют интернет и сохраняют HTML-страницы, изображения, таблицы стилей и часть скриптов. Каждой сохранённой версии присваивается дата и ссылка, что позволяет пользователям «перемещаться во времени». Динамические и закрытые разделы (например, личные кабинеты) при этом не фиксируются.
- Web Archive полезен исследователям и журналистам для проверки фактов, маркетологам — для анализа брендов и конкурентов, разработчикам — для восстановления проектов, а преподавателям — для демонстрации эволюции веб-технологий. По сути, это инструмент для всех, кто хочет увидеть, как интернет менялся и развивался на протяжении лет.
