


Современный ИИ стоит на фундаменте классической математики и статистики. Один из важных элементов в этом фундаменте — Метод наименьших квадратов (МНК, или Ordinary Least Squares — OLS).
Сегодня мы разберем, как именно алгоритмы учатся проводить подходящие линии через хаос данных, почему математики так любят возводить числа в квадрат и как написать свою первую модель машинного обучения с нуля. Наливайте кофе, мы начинаем!
Метод наименьших квадратов: контекст
Представьте, что вы пришли к портному, чтобы сшить костюм на заказ. Портной снимает с вас мерки: рост, обхват груди, длину рук. Ваши параметры уникальны, но портной знает, что в целом у людей с высоким ростом обычно более длинные руки. Эта закономерность не идеальна (бывают невысокие люди с длинными руками и наоборот), но она существует.

В машинном обучении мы постоянно занимаемся тем, что пытаемся найти такие закономерности. У нас есть данные (рост и длина рук, площадь квартиры и ее цена, расходы на рекламу и итоговая прибыль), и мы хотим создать математическую модель, которая свяжет эти переменные.
Самая простая и понятная модель — это прямая линия. Но если вы просто нарисуете точки данных на графике, вы увидите, что они образуют не идеальную линию, а скорее вытянутое облако. Как провести линию так, чтобы она лучше всего описывала это облако? На глаз? Можно, но если мы хотим автоматизировать процесс и доверить его компьютеру, нам нужен строгий математический критерий качества.
Именно этот критерий связан с работами Карла Фридриха Гаусса и Адриена Мари Лежандра. Это метод наименьших квадратов — сердце алгоритма линейной регрессии.
Зачем нужна аппроксимация данных
Прежде чем бросаться в формулы, давайте поймем саму суть проблемы. Зачем нам вообще что-то приближать, то есть аппроксимировать?
Жизненный пример: покупка квартиры
Допустим, вы решили купить квартиру в определенном районе города. Вы открываете сайт с объявлениями и выписываете данные: площадь в квадратных метрах (X) и цену в миллионах рублей (Y).
У вас получается табличка:
- 30 кв. м — 5 млн рублей;
- 32 кв. м — 5,5 млн рублей;
- 40 кв. м — 6,8 млн рублей;
- 40 кв. м — 7,2 млн рублей (ого, площади одинаковые, а цены разные);
- 55 кв. м — 9,5 млн рублей.
Если вы нанесете эти точки на график, они не выстроятся в одну прямую линию. Почему? Потому что в реальном мире на цену влияет не только площадь. Влияет этаж, качество ремонта, вид из окна, срочность продажи и даже настроение продавца. Все эти неучтенные факторы в статистике называются шумом или погрешностью наблюдений.
Ловушка «соедини точки»: переобучение
Новичок может сказать: «Давайте просто проведем сложную кривую линию, которая пройдет ровно через каждую точку на нашем графике!»
В машинном обучении это называется переобучением (overfitting), и это одна из типичных ошибок дата-сайентиста. Если вы проведете линию через каждую точку, ваша модель выучит не только полезную закономерность (чем больше площадь, тем выше цена), но и весь случайный шум (что квартира с синими обоями почему-то стоит на 200 тысяч дороже).
Если вы потом спросите такую модель, сколько должна стоить квартира в 45 квадратных метров, она выдаст вам абсолютно неадекватную цену, потому что кривая между точками будет скакать как сумасшедшая.
Ищем сигнал в шуме
Нам не нужно проходить через все точки. Нам нужно найти общий тренд — сигнал — и проигнорировать случайные отклонения, то есть шум. Мы хотим заменить сложное и хаотичное облако точек простой функцией, например прямой линией. Этот процесс замены сложных или зашумленных данных простой функцией называется аппроксимацией.
Аппроксимация позволяет нам:
- Понимать данные. Мы можем сказать: «Каждый дополнительный квадратный метр увеличивает цену в среднем на 150 тысяч рублей».
- Делать предсказания. Мы можем подставить в формулу линии любую площадь и получить адекватную прогнозную цену.
Но линий можно провести бесконечно много. Какая из них лучшая?
Что такое метод наименьших квадратов
Метод наименьших квадратов (МНК) — это математический подход, который позволяет найти ту самую идеальную линию или кривую, лучше всего описывающую данные.
Давайте введем несколько ключевых понятий, чтобы говорить на языке профессионалов.
Остатки (residuals)
Представьте, что мы провели какую-то случайную линию через наши данные о квартирах. Берем конкретную квартиру: ее реальная площадь 40 кв. м, а реальная цена — 7,2 млн рублей. Наша линия (модель) предсказывает, что квартира в 40 кв. м должна стоить 6,5 млн рублей.
Разница между реальным значением и предсказанием модели называется остатком, или ошибкой. В нашем случае остаток: 7.2-6.5=0.7 млн рублей
Остаток есть у каждой точки в нашем наборе данных. Если точка лежит выше линии, остаток положительный. Если ниже — отрицательный. Если точка лежит ровно на линии, остаток равен нулю.
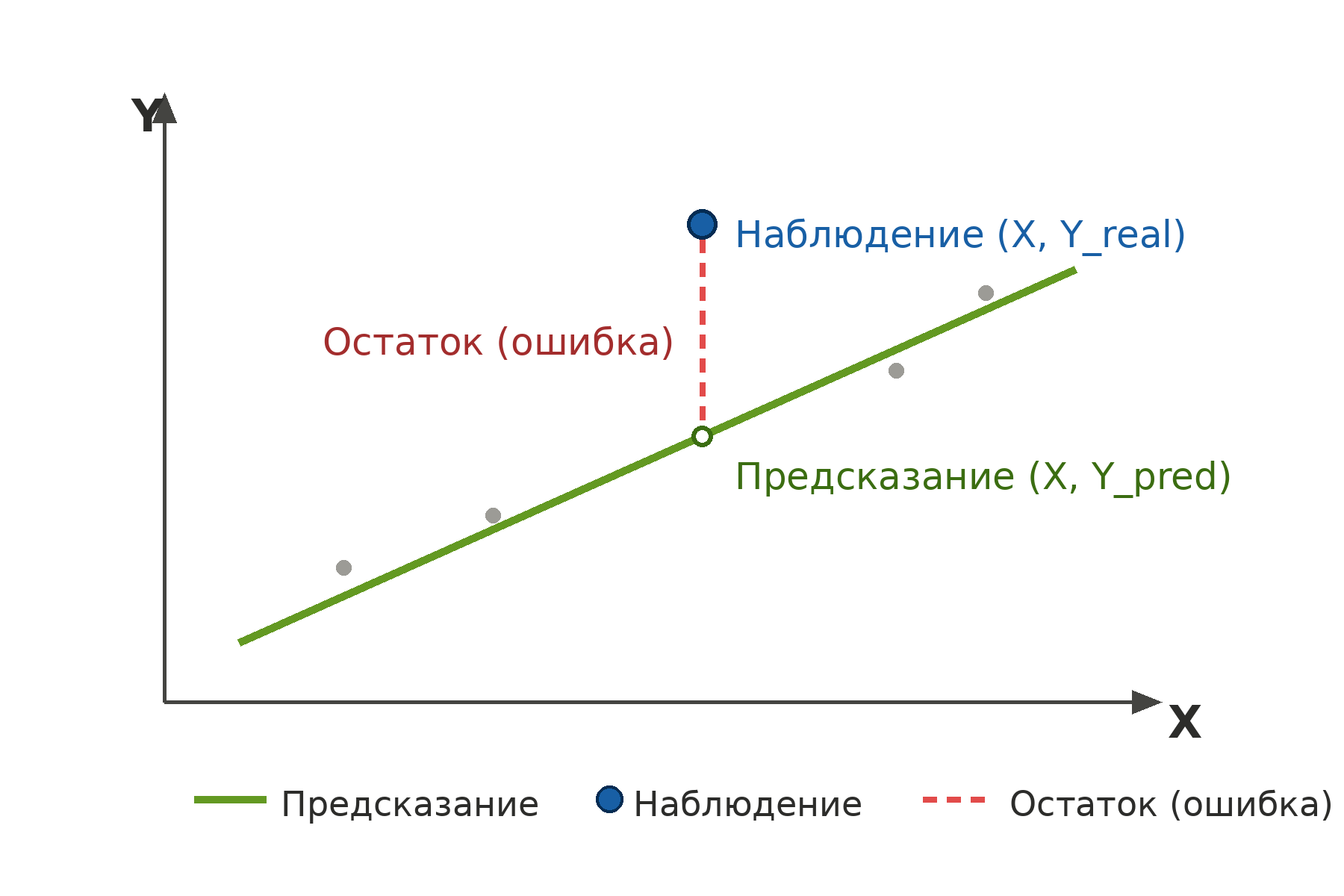
Критерий минимизации
Логично предположить, что лучшая линия — это та, у которой эти остатки минимальны. Но как их суммировать?
Если мы просто сложим все остатки, то положительные ошибки (точки над линией) компенсируют отрицательные (точки под линией). В итоге сумма может оказаться равной нулю даже для очень плохой линии, которая проходит сквозь облако данных под неверным углом.
Чтобы избавиться от отрицательных знаков, у нас есть два пути:
- Брать модуль (абсолютное значение) каждого остатка.
- Возводить каждый остаток в квадрат.
Почему именно квадраты? МНК против модулей
Метод, который минимизирует сумму модулей отклонений, связан с метрикой Mean Absolute Error — MAE. А метод, который минимизирует сумму квадратов, — это наш сегодняшний герой, связанный с Mean Squared Error — MSE.
Почему МНК победил в исторической перспективе и стал стандартом? На это есть две причины: математическая и практическая.
1. Гладкость функции. Функция модуля (|x|) выглядит на графике как буква V. В самой нижней точке у нее острый угол. Математики не любят острые углы, потому что в них нельзя вычислить производную (школьное правило: функция не дифференцируема в точке излома). А функция квадрата (x2) выглядит как буква U — парабола. Она гладкая на всем своем протяжении. Гладкие функции легко дифференцировать, а значит, легко найти их минимум — дно этой U — с помощью алгебры. Во времена Гаусса, когда не было компьютеров, возможность решить задачу аналитически на листке бумаги была критически важна.
2. Штраф за крупные ошибки. Возведение в квадрат обладает интересным свойством: оно слабо наказывает за маленькие ошибки, но сильно штрафует за большие.
- Ошибка 0.1 в квадрате 0.01 (стала еще меньше).
- Ошибка 10 в квадрате 100 (взлетела до небес).
МНК заставляет линию располагаться так, чтобы не было точек с гигантскими отклонениями. Модель как бы говорит: «Лучше немного ошибиться на нескольких точках, чем допустить большую ошибку на одной». Во многих бизнес-задачах это именно то, что нам нужно.
Итоговое определение: метод наименьших квадратов — это способ найти оптимальные параметры модели, при которых сумма квадратов отклонений реальных данных от предсказанных значений достигает минимума.

Как работает метод наименьших квадратов: математика под капотом
Давайте заглянем под капот и посмотрим, как работает эта магия. Не бойтесь формул, я объясню каждую из них.
Шаг 1. Постановка задачи
Мы хотим построить прямую линию. Вспомним школьное уравнение прямой:
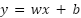
Где:
- y — то, что мы предсказываем (цена квартиры);
- x — то, на основе чего мы предсказываем (площадь);
- w — вес (weight), или коэффициент наклона — показывает, насколько круто линия идет вверх или вниз;
- b — смещение (bias), или свободный член. — показывает, где линия пересекает вертикальную ось.
Наша цель — найти такие конкретные числа w и b, чтобы линия лучше всего легла на наши данные.
Шаг 2. Составление функционала потерь (loss function)
У нас есть набор из n точек: (x1,y1),(x2,y2),…,(xn,yn). Для каждой точки наша линия сделает предсказание:
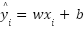
Крышечка над y означает, что это предсказание, а не реальное значение.
Остаток для одной точки:
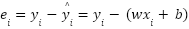
Теперь составим функцию потерь (loss function) — ту самую сумму квадратов, которую нам нужно минимизировать. Назовем ее L:
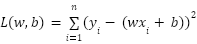
Эта функция L зависит от двух переменных — w и b. Представьте себе трехмерный ландшафт (как горы и долины), где координаты на земле — это w и b, а высота гор — это величина ошибки L. Наша задача — спуститься в самую глубокую впадину этого ландшафта, где ошибка минимальна.
Шаг 3. Магия производных
Как найти дно впадины? С помощью производных. Производная функции показывает скорость ее изменения, или наклон поверхности. Если вы стоите на склоне горы, производная подскажет, в какой стороне спуск. А на самом дне впадины поверхность абсолютно плоская, то есть наклон — производная — равен нулю!
Чтобы найти минимум функции L(w,b), нужно взять частные производные по w и по b и приравнять их к нулю.
- Производная по b (считаем w константой):
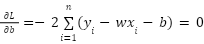
- Производная по w (считаем b константой):
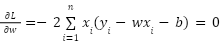
Шаг 4. Система нормальных уравнений
Если мы раскроем скобки в уравнениях выше и перенесем неизвестные (w и b) в одну сторону, а известные данные (x и y) — в другую, получится система нормальных уравнений:
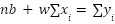
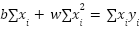
Это обычная система линейных уравнений (уровня седьмого класса школы), которую можно решить методом подстановки. В результате мы получим готовые формулы для вычисления оптимальных параметров:
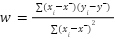
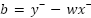
Где x‾ и y‾ — это средние значения площади и цены соответственно.
Что это значит простыми словами? Формула для w — это отношение ковариации, то есть того, как x и y изменяются вместе, к дисперсии, то есть к тому, как x изменяется сам по себе. Если площадь и цена сильно растут вместе, наклон линии w будет большим. А формула для b гарантирует, что наша идеальная линия обязательно пройдет через центр данных — точку с координатами (x‾,y‾).
Примечание для продвинутых: если у нас не один признак (только площадь), а много (площадь, этаж, расстояние до метро), то формулы с суммами становятся слишком громоздкими. Тогда МНК записывают в элегантном матричном виде:
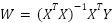
Суть остается абсолютно той же.
Шаг 5. Оценка качества: коэффициент детерминации R²
Отлично, мы нашли идеальную линию! Но насколько она хороша? Вдруг наши данные — это просто случайное круглое облако точек, и любая линия там бесполезна?
Для оценки качества в линейной регрессии используют метрику R2— R-квадрат, или коэффициент детерминации.
Представьте самую глупую модель машинного обучения. На любой вопрос о цене квартиры она отвечает: «Средняя цена по городу такая-то». Эта модель вообще не смотрит на площадь. Ошибка такой модели называется общей суммой квадратов (Total Sum of Squares, TSS).
А теперь возьмем ошибку нашей умной модели с линией — остаточную сумму квадратов (Residual Sum of Squares, RSS).
Метрика R2 показывает, какую долю ошибок простой модели смогла устранить наша умная модель:
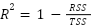
- Если R2=1, это значит, что наша линия прошла идеально через все точки. Модель объяснила 100% разброса данных.
- Если R2=0, то модель с площадью работает так же плохо, как предсказание просто по среднему значению.
- Если R2<0, наша модель работает хуже, чем простое среднее. Такое бывает, если мы сильно ошибемся в расчетах или возьмем не ту модель.
Обычно R2 от 0.7 до 0.9 считается отличным результатом в реальных задачах.
Применяем МНК на практике
Хватит теории! Давайте запачкаем руки в коде. Представим, что мы собрали небольшую статистику по ценам на квартиры.
Для начала импортируем необходимые библиотеки:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
# Сделаем графики красивыми
plt.style.use('ggplot')
Создадим наш игрушечный набор данных (X — площадь в кв. м, Y — цена в млн рублей):
# Площадь квартир
X = np.array([30, 32, 40, 45, 50, 55, 60, 65, 70, 80])
# Цены (добавим немного случайного шума для реалистичности)
Y = np.array([5.1, 5.4, 6.8, 7.5, 8.2, 9.0, 9.8, 10.5, 11.0, 12.5])
Сейчас мы решим задачу аппроксимации тремя разными способами: от самого хардкорного до профессионального.
Способ 1. Вручную по формулам нормальных уравнений
Мы применим формулы для w и b, которые вывели в шаге 4. Это полезно, чтобы понять: никакой магии в ML нет, только арифметика.
def manual_ols(X, Y):
# 1. Находим средние значения
x_mean = np.mean(X)
y_mean = np.mean(Y)
# 2. Считаем числитель (ковариацию) и знаменатель (дисперсию X)
numerator = np.sum((X - x_mean) * (Y - y_mean))
denominator = np.sum((X - x_mean)**2)
# 3. Вычисляем вес w (наклон)
w = numerator / denominator
# 4. Вычисляем смещение b
b = y_mean - w * x_mean
return w, b
w_manual, b_manual = manual_ols(X, Y)
print(f"Способ 1 (Вручную): Наклон w = {w_manual:.4f}, Смещение b = {b_manual:.4f}")
Вывод: Способ 1 (Вручную): Наклон w = 0.1480, Смещение b = 0.7787
Интерпретация: наш вес w=0.1480. Это значит, что в нашей модели каждый дополнительный квадратный метр площади увеличивает стоимость квартиры в среднем на 0,1480 млн рублей, то есть на 148 тысяч.
Способ 2. Использование numpy.polyfit
Инженеры NumPy уже написали оптимизированную функцию для МНК. Функция polyfit подгоняет полином заданной степени под данные. Прямая линия — это полином первой степени.
# Первый аргумент - X, второй - Y, третий - степень полинома (1 для прямой)
w_np, b_np = np.polyfit(X, Y, 1)
print(f"Способ 2 (NumPy): Наклон w = {w_np:.4f}, Смещение b = {b_np:.4f}")
Вывод: Способ 2 (NumPy): Наклон w = 0.1480, Смещение b = 0.7787
Как видите, результаты сошлись копейка в копейку!
Способ 3. Промышленный стандарт — scikit-learn
В рабочих проектах дата-сайентисты редко пишут формулы руками. Вы будете использовать библиотеку scikit-learn. В ней алгоритмы реализованы максимально эффективно через удобный интерфейс.
# scikit-learn ожидает, что X будет двумерным массивом (матрицей признаков),
# где каждая строка - это отдельный объект. Поэтому делаем reshape.
X_sklearn = X.reshape(-1, 1)
# Создаем модель линейной регрессии
model = LinearRegression()
# Запускаем МНК (обучаем модель)
model.fit(X_sklearn, Y)
# Извлекаем параметры
w_sklearn = model.coef_[0]
b_sklearn = model.intercept_
print(f"Способ 3 (Sklearn): Наклон w = {w_sklearn:.4f}, Смещение b = {b_sklearn:.4f}")
# Сделаем предсказания для наших данных, чтобы посчитать R2
Y_pred = model.predict(X_sklearn)
r2 = r2_score(Y, Y_pred)
print(f"Коэффициент детерминации R²: {r2:.4f}")
Вывод: Способ 3 (Sklearn): Наклон w = 0.1480, Смещение b = 0.7787 Коэффициент детерминации R²: 0.9979
Наш R2=0.9979. Это фантастический результат, потому что данные я сгенерировал искусственно, чтобы они ложились почти на прямую. Это значит, что 99.79% разброса в ценах на наши квартиры объясняется их площадью.
Визуализация результата
Давайте нарисуем наши точки и идеальную линию, которую нашел МНК.
plt.figure(figsize=(10, 6))
# Рисуем реальные данные (точки)
plt.scatter(X, Y, color='blue', label='Реальные данные (наблюдения)', s=100)
# Рисуем линию МНК
# Линия строится по предсказанным значениям
plt.plot(X, Y_pred, color='red', linewidth=3, label=f'Линия МНК: Y = {w_sklearn:.2f}X + {b_sklearn:.2f}')
# Добавляем визуализацию остатков для красоты
for i in range(len(X)):
# Рисуем пунктирную линию от реальной точки до предсказанной на прямой
plt.plot([X[i], X[i]], [Y[i], Y_pred[i]], color='gray', linestyle='--')
plt.title('Аппроксимация цен на квартиры методом МНК')
plt.xlabel('Площадь (кв. м)')
plt.ylabel('Цена (млн руб.)')
plt.legend()
plt.grid(True)
plt.show()
Если вы запустите этот код, вы увидите красивый график.
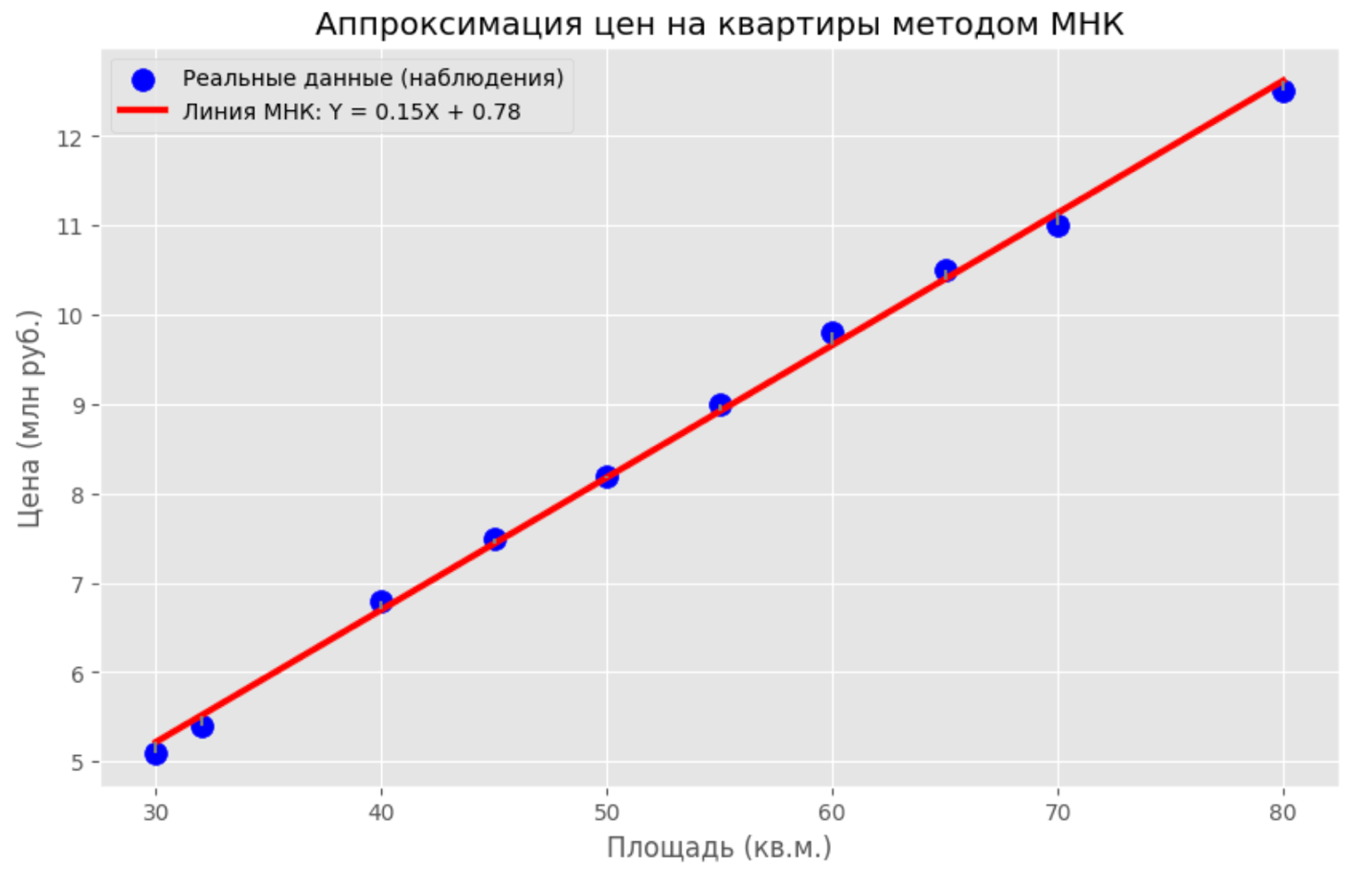
Синие точки будут выстроены в облако, сквозь которое ровно посередине проходит толстая красная линия. А серые пунктиры покажут те самые остатки, сумму квадратов которых мы минимизировали. Это и есть триумф математики над хаосом данных!
Метод наименьших квадратов: коротко о главном
Метод наименьших квадратов (МНК) — это гениальный в своей простоте математический инструмент. Он берет зашумленные, разбросанные данные и находит в них общий тренд.
Коротко о том, как работает МНК:
- Аппроксимация нужна, чтобы найти сигнал в шуме и не допустить переобучения.
- МНК минимизирует сумму квадратов остатков, потому что квадратичная функция гладкая — легко найти минимум через производные — и хорошо штрафует за крупные выбросы.
- Под капотом МНК лежит решение системы уравнений, которое гарантирует аналитически точный результат. В более сложных моделях параметры часто подбирают численно, но идея остается похожей: минимизировать функцию потерь.
- Качество модели оценивается метрикой R2: она показывает, какую долю разброса данных смогла объяснить модель.
Есть ли у МНК недостатки? Да, конечно. Во-первых, из-за возведения в квадрат метод очень чувствителен к выбросам. Если бы в нашем наборе данных оказалась квартира площадью 30 кв. м, но с золотыми унитазами за 50 млн рублей, эта единственная точка сильно исказила бы всю линию: линия потянулась бы к ней, чтобы минимизировать огромный квадрат ошибки. Во-вторых, классический МНК ищет только линейные зависимости. Если ваши данные имеют форму параболы или синусоиды, прямая линия им не поможет, хотя МНК можно адаптировать и для полиномов.
Тем не менее линейная регрессия на базе МНК — это базовая модель машинного обучения. С нее часто начинается путь любого специалиста по Data Science. Если понять, как здесь работают функция потерь и минимизация, вы быстрее разберетесь, как обучаются глубокие нейронные сети. Ведь там происходит то же самое, просто масштаб больше, а функции сложнее.
Надеюсь, сегодня математика стала для вас немного понятнее и ближе. Экспериментируйте с кодом, меняйте данные, смотрите, как меняется линия, ведь практика — лучший способ закрепить теорию.