


BERT (Bidirectional Encoder Representations from Transformers) — это одна из ключевых моделей обработки естественного языка (NLP), построенная на архитектуре трансформера.
Архитектура модели BERT и принцип ее работы
Модель BERT основана на трансформере — нейросетевой архитектуре, которая использует механизм внимания для анализа и понимания текста.

Как работает внимание?
Механизм внимания в контексте NLP позволяет модели сосредоточиться при обработке на наиболее значимых частях текста, чтобы лучше понять его смысл.
Механизм внимания использует три компонента:
- Запросы (Queries, Q) — эмбеддинги текущего слова, которые определяют, на что нужно обратить внимание. Запросы сопоставляются с ключами для выбора подходящих вариантов.
Аналогия: книга, которую человек ищет в библиотеке (например, определенного жанра или автора).
- Ключи (Keys, K) — эмбеддинги всех слов в тексте, которые описывают их свойства, чтобы сопоставить с запросами.
Аналогия: характеристики книги (название, жанр, автор). Они помогают понять, насколько книга соответствует запросу.
- Значения (Values, V) — эмбеддинги, которые содержат информацию о словах, важных для текущего запроса. Когда ключи совпадают с запросами, значения используются для формирования контекста и ответа.
Аналогия: содержание издания, которое человек получает после выбора подходящей книги по запросу.
Эмбеддинг (или векторное представление) — это результат преобразования данных (слов) в числовой вектор, который описывает их в многомерном пространстве.
Этот вектор отражает смысл слова и его связь с другими словами. Например, слова «клубника» и «малина» будут иметь схожие векторные представления, потому что часто встречаются в схожих контекстах.
Как модель вычисляет внимание
Модель измеряет, насколько запросы (Queries) схожи с ключами (Keys), через скалярное произведение. Результаты нормализуются (softmax), чтобы определить вес каждого слова.
В трансформерах используется многоголовое внимание (multi-head attention), где внимание рассчитывается несколько раз (параллельно) с разными параметрами.
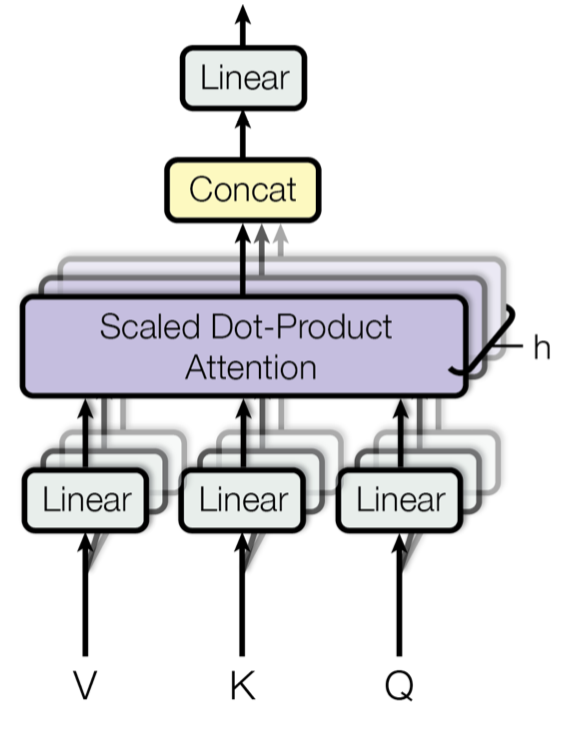
То есть вместо того чтобы один раз определить, какие слова важны для текущего предложения, модель делает это несколько раз параллельно, с разных сторон (точек зрения). Каждая из этих точек зрения называется головой. Одна голова может искать грамматические связи, другая — семантические и т. д.
Например, в предложении «Кошка гонится за мышью»:
— одна голова выделяет слова, связанные с действием: фокус на «гонится»;
— другая голова смотрит на объекты: фокус на «кошка» и «мышью»;
— третья голова анализирует весь контекст, понимает связь всей фразы.
Двунаправленность архитектуры BERT
В классических рекуррентных архитектурах, таких как RNN или LSTM, а также обычных трансформерах с маскированием слов «справа» понимание контекста ограничивалось направлением обработки текста (слева направо или справа налево). BERT же умеет учитывать слова, которые находятся до и после текущего слова, чтобы лучше понять его смысл в контексте.

Обучение BERT
Обучение BERT проходит в два этапа:
— предсказание маскированных слов;
— определение следующего предложения.
Маскированные слова (Masked Language Modeling, MLM)
Это слова, которые намеренно скрываются от модели на этапе обучения, чтобы она научилась восстанавливать их. Вот как это работает:
- На вход модель получает текст, где некоторые слова заменены специальным токеном [MASK]. Например: «Я [MASK] книгу о машинном обучении».
- Модель пытается угадать, какое слово скрыто за маской, опираясь на контекст. Для этого BERT использует свои двунаправленные связи, анализируя, что стоит до и после маски.
Например, модель может определить, что правильное слово — «прочитал», так как это наиболее вероятный вариант в данном контексте.
Как это работает
Чтобы модель не была слишком зависима от одной логики маскирования, используется специальная стратегия.
Во время обучения BERT маскирует только 15% всех слов в тексте, чтобы остальные 85% слов оставались видимыми и помогали сохранять контекст.
Пример: «Сегодня солнечно, но завтра может пойти дождь, поэтому я возьму зонт».
Из предложения случайным образом берется 15% слов, в данном случае это два слова — например, «солнечно» и «завтра».
Далее происходит следующее:
— С вероятностью 80% выбранные слова заменяются на [MASK].
— С вероятностью 10% они остаются без изменений.
— С вероятностью 10% они заменяются на случайные слова из словаря.
Представим, что к слову «солнечно» применили [MASK], к «завтра» — замену на «кот». Получилось: «Сегодня [MASK], но кот может пойти дождь, поэтому я возьму зонт».
Это сделано для того, чтобы модель не слишком привязывалась к конкретному токену [MASK] и научилась работать в более разнообразных ситуациях.
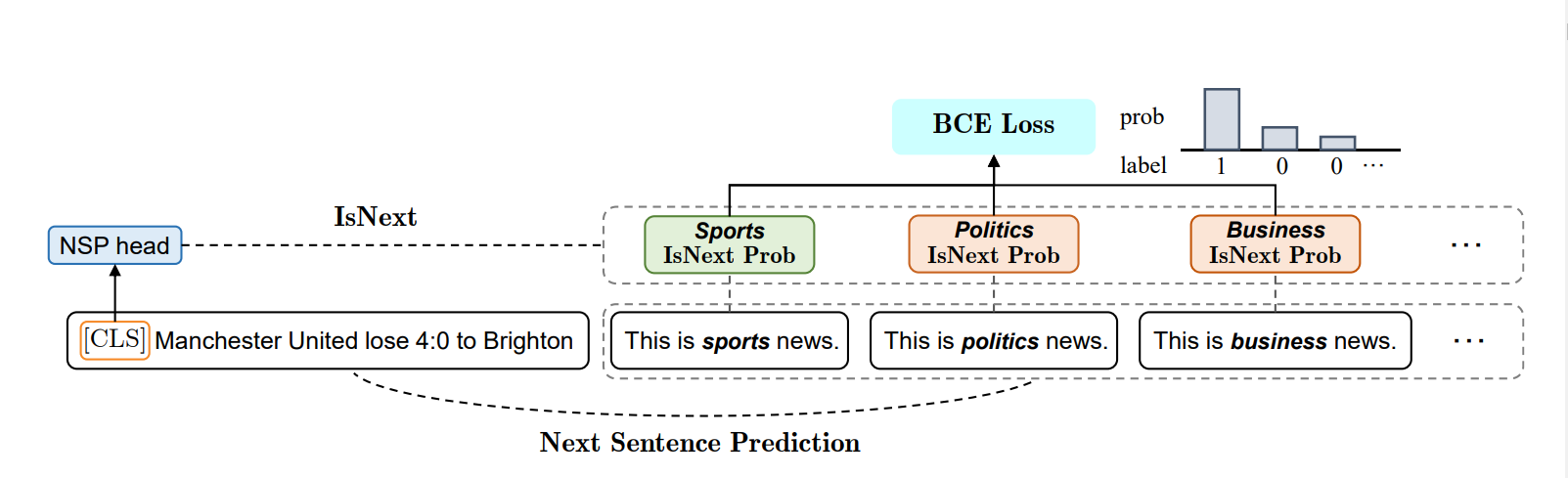
Предсказание порядка двух предложений (Next Sentence Prediction, NSP)
Еще одна задача, на которой BERT обучается, — это предсказание порядка двух предложений.
Модели передается пара предложений, а она должна определить, действительно ли второе следует за первым или это случайная фраза.
Пример:
- Предложения связаны.
«Я пошел в магазин» — «Там я купил хлеб».
Эти два предложения логически связаны, так как второе продолжает мысль первого.
- Предложения не связаны.
«Я пошел в магазин» — «Собака бежит по улице».
Эти предложения не имеют логической связи. Второе предложение не продолжает мысли первого и не соответствует контексту.
Как это работает
Во время обучения BERT используются пары предложений. Для каждой пары предложений модель получает две метки:
- «Истинная пара»: второе предложение логически продолжает первое.
- «Ложная пара»: второе предложение случайно выбрано и не имеет смысла как продолжение.
Пример реализации на Python
Возьмем предложения из прошлого примера.
- Не забудьте установить библиотеку transformers:
!pip install transformers
- Затем нужно импортировать модели BertTokenizer и BertForNextSentencePrediction из библиотеки transformers, а также torch:
from transformers import BertTokenizer, BertForNextSentencePrediction import torch
- Загружаем предобученный токенизатор и модель для задачи NSP:
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForNextSentencePrediction.from_pretrained('bert-base-uncased')
- Кладем связанные предложения «Я пошел в магазин» и «Там я купил хлеб» в переменные, токенизируем их:
# Связанные предложения sentence_A = "Я пошел в магазин." sentence_B = "Там я купил хлеб." # Токенизация предложений encoding = tokenizer.encode_plus(sentence_A, sentence_B, return_tensors='pt')
- Прогоняем токенизированные данные через модель:
outputs = model(**encoding)
- Получаем логиты и предсказания. Логиты — это непосредственные результаты работы модели:
# Извлекаем логиты logits = outputs.logits # Получаем предсказание (индекс с максимальной вероятностью) prediction = torch.argmax(logits)
- Выводим результаты:
if prediction.item() == 0:
print("Предложения не связаны")
else:
print("Предложения связаны")
Получим, что предложения связаны.
Настройка гиперпараметров
Гиперпараметры — это параметры, которые задаются до начала обучения модели и управляют его процессом.
В отличие от параметров модели, которые обучаются на данных (например, веса нейронных сетей), гиперпараметры остаются фиксированными во время обучения.
Основные гиперпараметры в BERT
- Скорость обучения (learning rate). То, насколько обновляются параметры модели на каждом шаге обучения.
- Батч (batch size). Количество примеров, обрабатываемых моделью за один шаг.
- Количество эпох (epochs). Число полных проходов через весь обучающий набор данных.
- Максимальная длина входной последовательности. Максимальное количество токенов в одном примере текста.
- Количество голов внимания (attention heads). Точки, которые параллельно вычисляют различные аспекты внимания, чтобы модель могла захватывать более разнообразные зависимости между словами.
- Количество слоев (layers). Число однообразных трансформерных блоков, которые модель будет применять для обработки текста.
- Размер скрытого состояния (hidden size). Величина вектора, который влияет на представление токенов внутри модели и определяет количество нейронов в скрытом слое каждой ее части.

Области применения BERT
Модели BERT используют для классификации текста, поиска именованных сущностей, анализа тональности текста и пользовательских намерений.
Классификация текста
Задача классификации текста заключается в отнесении текста к одной или нескольким категориям.
Примеры:
- Определение тематики текста (например, новости, спорт, технологии).
- Классификация писем как «спам» или «не спам».
- Выявление признаков текста, таких как наличие оскорбительных высказываний.
Анализ тональности
В этом случае задача — определить эмоциональную окраску текста: положительная, отрицательная или нейтральная.
Примеры:
- анализ отзывов на товары или услуги;
- оценка мнений в социальных сетях;
- оценка тональности публикаций в СМИ.
Распознавание именованных сущностей (Named-Entity Recognition, NER)
Задача заключается в выделении ключевых сущностей в тексте, таких как:
- имена людей, компаний, организаций;
- даты, числа, адреса;
- географические объекты (города, страны).
Анализ пользовательских намерений
Эта задача схожа с анализом тональности, но включает в себя понимание того, что именно пользователь пытается выразить.
Пример:
- ожидания от продукта;
- пожелания или недовольства в отзывах.
Разновидности моделей BERT
Для различных задач были созданы улучшенные и специализированные версии BERT.
BERT-base, BERT-large
BERT-base и BERT-large — это стандартные варианты BERT, отличающиеся размером и мощностью.
RoBERTa
RoBERTa — это улучшенная версия BERT, разработанная Facebook AI Research. RoBERTa была создана на основе BERT, но с некоторыми изменениями в процессе обучения.
- RoBERTa использует больше данных для обучения, чем стандартный BERT.
- Она обучается только на задаче маскирования токенов Masked Language Modeling (MLM), задача Next Sentence Prediction (NSP) отбрасывается.
- RoBERTa дольше обучается, с более точной настройкой гиперпараметров.
Используется в тех же областях, что и BERT, но с лучшей производительностью.
DistilBERT
DistilBERT — это легкая версия BERT, которая была создана с целью уменьшить размер модели, ускорить инференс и сохранить при этом высокую производительность.
- DistilBERT использует технику distillation, которая позволяет создавать компактную модель, которая по производительности близка к исходной модели BERT, но с меньшими вычислительными затратами.
- Количество слоев у DistilBERT уменьшено (6 слоев вместо 12 у BERT-base).
Библиотека Hugging Face
Эта библиотека на Python предоставляет инструменты для работы с моделями NLP. В ней есть предобученные модели BERT, токенизаторы и пайплайны для различных задач.
Токенизаторы
Например, BertTokenizer.
Превращают текст в формат, понятный модели. Они разбивают его на токены (слова или части слов) и преобразуют их в числовые значения, которые модель может обработать.
Пайплайны для предобработки текста
Предоставляют готовые функции для выполнения типичных задач NLP, таких как классификация текста и анализ тональности, с минимальным кодом.
Метрики оценки качества BERT
Accuracy и F1-score для задач классификации
Accuracy измеряет долю правильно классифицированных примеров.
Формула

Метрика F1-score учитывает точность (precision) и полноту (recall) предсказаний.
Формула
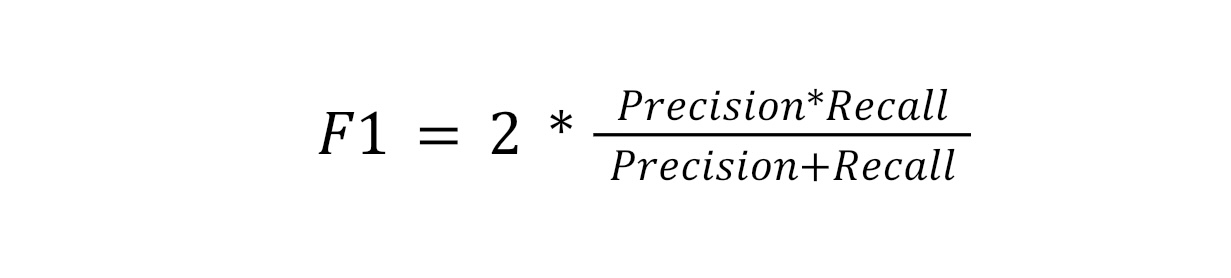
Где:
Precision (Точность) — доля правильных положительных предсказаний среди всех предсказанных положительных значений;
Recall (Полнота) — доля правильных положительных предсказаний среди всех реальных положительных значений.
BLEU для генерации текста
BLEU оценивает качество машинного перевода и других задач генерации текста. Она сравнивает, насколько сгенерированный текст совпадает с эталонным (референсным) на уровне n-грамм.
Формула
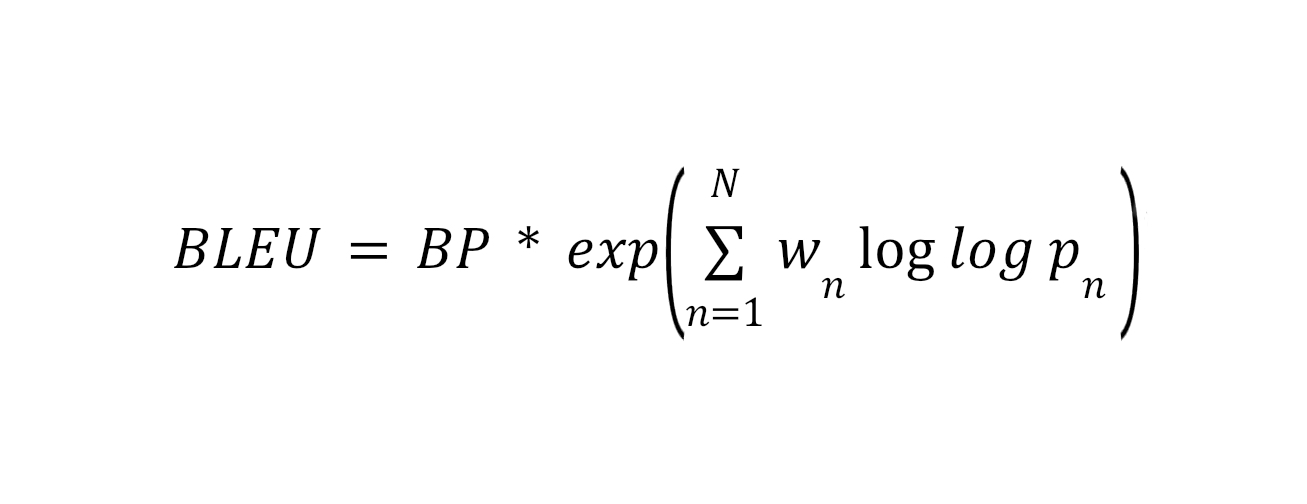
Где:
BP (Brevity Penalty) — штраф за сокращение длины сгенерированного текста относительно референсного.
Pn — точность n-грамм (например, 1-грамм, 2-грамм и так далее).
Wn — веса для разных n-грамм.
Рекомендации для изучения теории и практики работы с BERT
— Изучайте трансформеры. Начните с понимания механизма внимания (attention) и самовнимания (self-attention). Это основа работы BERT.
— Работайте с Hugging Face. Попробуйте предобученные модели BERT на реальных задачах (классификации, анализа тональности и т. д.). Это поможет быстрее понять, как применять модель на практике.
— Гиперпараметры. Экспериментируйте с гиперпараметрами (скорость обучения, размер батча, количество слоев и т. д.). Начинайте с общепринятых значений, затем подстраивайте под свою задачу.
— Выбор модели. Разные версии BERT (DistilBERT, RoBERTa) подходят для разных задач. Используйте легкие модели для скорости и большие — для точности.
— Дообучение. Учитесь дообучать модели на специфических данных для повышения точности.
