

Распределение вероятностей — это закон, который описывает, с какой вероятностью случайная величина окажется в том или ином диапазоне. В статье рассмотрим, что такое нормальное распределение, зачем оно нужно и как его рассчитывать.

Каким бывает распределение
Распределение бывает дискретным (когда величина принимает отдельные значения, например, число успехов в серии испытаний) и непрерывным (когда значения могут быть любыми в заданном диапазоне, например, рост человека).
К дискретным относятся:
- Биномиальное распределение. Определяет вероятность получения определенного числа успехов в серии независимых испытаний с двумя возможными исходами.
- Геометрическое распределение. Моделирует количество испытаний до первого успеха в серии независимых испытаний с двумя исходами.
- Распределение Пуассона. Описывает вероятность определенного числа событий, происходящих в фиксированный интервал времени или на фиксированной площади, при условии, что события происходят с постоянной средней частотой и независимо друг от друга.
- Гипергеометрическое распределение. Моделирует вероятность определенного числа успехов в выборке без возвращения из конечной совокупности, содержащей два типа объектов.
- Дискретное равномерное распределение. Каждое из конечного числа возможных значений случайной величины имеет одинаковую вероятность.
К непрерывным распределениям относятся:
- Нормальное распределение. Значения случайной величины распределены симметрично вокруг среднего.
- Непрерывное равномерное распределение. Все значения в заданном диапазоне имеют одинаковую вероятность; график плотности вероятности представляет собой прямую линию.
- Показательное распределение. Моделирует время между событиями в процессе, происходящем с постоянной средней частотой; часто используется для описания времени до первого события.
- Гамма-распределение. Обобщает показательное распределение; моделирует время до наступления k-го события в процессе с постоянной средней частотой.
- Бета-распределение. Описывает распределение вероятностей на интервале [0,1]; часто используется в байесовской статистике и для моделирования случайных переменных, ограниченных этим интервалом.
Что такое нормальное распределение
Нормальное распределение (распределение Гаусса или Гаусса — Лапласа) — это непрерывное распределение вероятностей, где значения симметрично сгруппированы вокруг среднего, а вероятность отклонений уменьшается по мере удаления от него. Форма нормального распределения является колоколообразной.
Нормальное распределение определяется двумя параметрами: матожиданием (μ) и стандартным отклонением (σ).
Плотность вероятности нормального распределения f(x) показывает, насколько вероятны разные значения случайной величины, и рассчитывается по формуле:
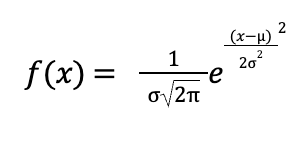
где:
x — значение случайной величины,
μ — математическое ожидание (среднее значение),
σ — стандартное отклонение,
π ≈ 3,14159,
e ≈ 2,71828 — основание натурального логарифма.
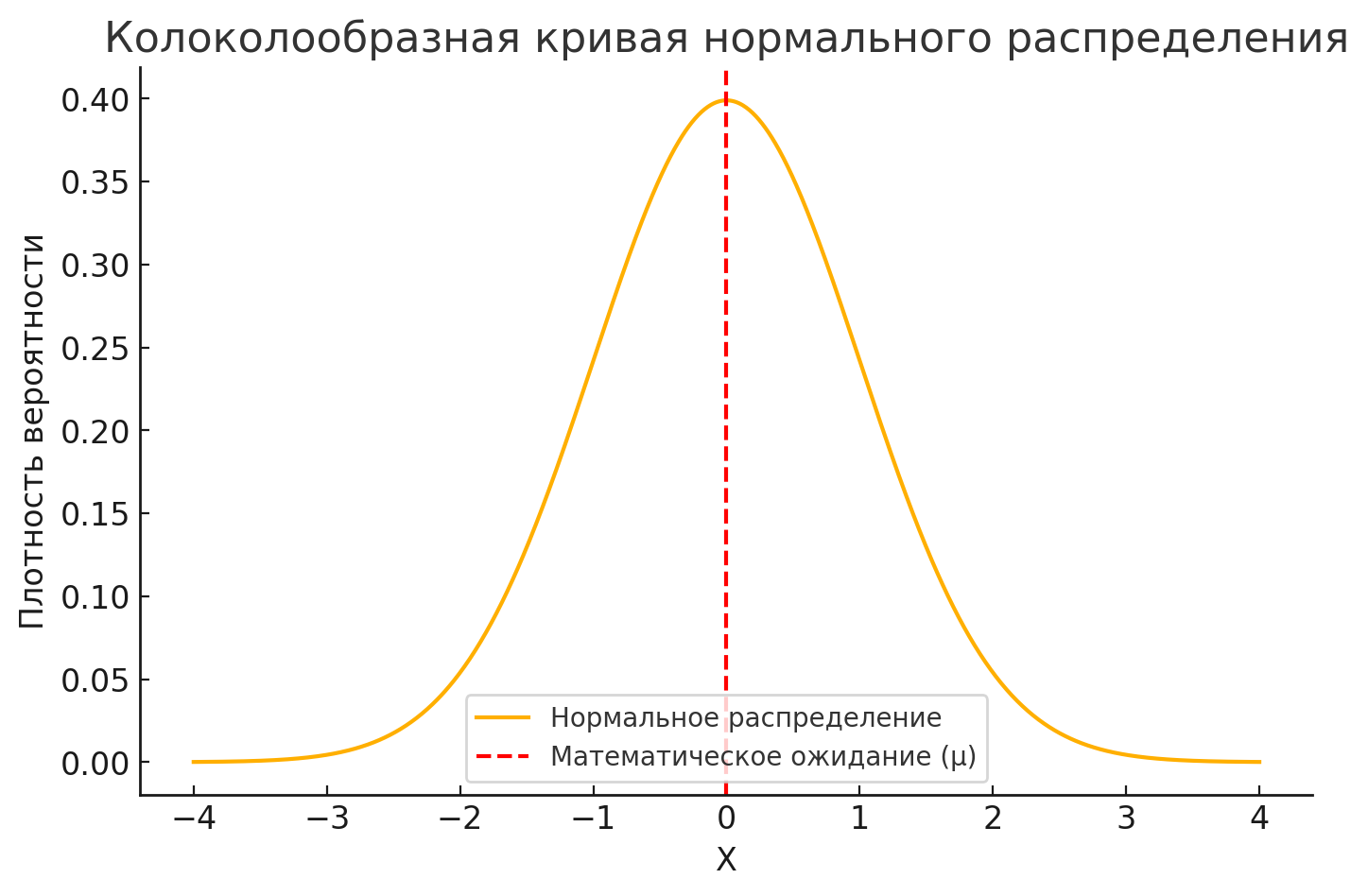
- Площадь под кривой плотности в интервале показывает вероятность попадания случайной величины в этот интервал.
- Чем выше значение функции плотности в точке x, тем больше вероятность встретить значение рядом с x.
Таким образом, плотность вероятности всегда максимальна в среднем значении (μ) и убывает по мере удаления от него.
Какие термины и формулы расчета важно знать
Математическое ожидание
Математическое ожидание (μ) — это среднее значение распределения, вокруг которого симметрично сгруппированы все значения. Оно определяет центр колоколообразной кривой.
Как найти матожидание
При выборке данных x1, x2, …, xn формула матожидания будет выглядеть так:
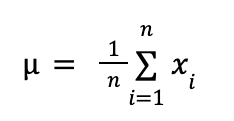
То есть μ — это среднее арифметическое всех наблюдений.
Стандартное отклонение и дисперсия
Стандартное отклонение (σ) — это мера разброса значений в нормальном распределении. Оно показывает, насколько сильно значения случайной величины отклоняются от среднего значения (математического ожидания).
Есть коэффициент (k), который показывает, на сколько стандартных отклонений (σ) мы отступаем от среднего (μ).
При нормальном распределении:
- Если k = 1, то мы рассматриваем интервал μ ± 1σ, где лежит 68% значений.
- Если k = 2, то интервал μ ± 2σ, где 95% значений.
- Если k = 3, то интервал μ ± 3σ, где 99,7% значений.
Эти проценты определяет эмпирическое правило (или правило 68–95–99,7), которое описывает, как данные распределяются в нормальном распределении.
Как найти стандартное отклонение
- Вычислить среднее (μ) всех значений.
- Для каждого значения вычислить разницу от среднего, возвести ее в квадрат.
- Найти среднее этих квадратов.
- Извлечь квадратный корень из полученного значения.
Формула для стандартного отклонения:
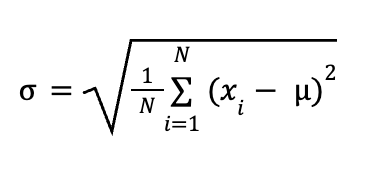
Где:
xi — значения выборки (подмножество данных для оценки),
μ — среднее значение,
N — количество значений.
Еще одна важная характеристика распределения данных — дисперсия (σ2). Она измеряет среднее значение квадратов отклонений от среднего.
В отличие от стандартного отклонения, которое выражается в тех же единицах, что и сами данные, дисперсия измеряется в квадрате этих единиц.
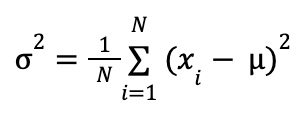
Дисперсия определяет, насколько «широкой» будет колоколообразная кривая (функция плотности) нормального распределения.
Чем больше дисперсия, тем шире будет распределение, а значит, данные будут более разрозненные. Чем меньше дисперсия, тем более «уплотненной» и узкой будет кривая.
Симметричность нормального распределения
Нормальное распределение называется симметричным, потому что его функция плотности f(x) одинаково изменяется влево и вправо от среднего значения μ.
Это значит, что вероятность встретить значение, отклоняющееся от μ на +kσ, такая же, как и на −kσ.
Если случайная величина x имеет нормальное распределение с параметрами μ и σ2, то выполняется:
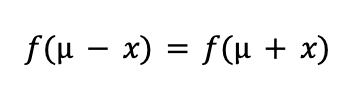
Это означает, что функция плотности f(x) зеркально симметрична относительно вертикальной линии x = μ.
Нормальное распределение симметрично: левый и правый «хвосты» кривой одинаковые, а среднее, медиана и мода совпадают (μ = Me = Mo).
Но в реальных данных часто встречаются асимметричные (скошенные) распределения. Это значит, что один «хвост» длиннее другого, а пик кривой смещен влево или вправо.
Что такое стандартное нормальное распределение
Стандартное нормальное распределение — это частный случай нормального распределения, когда математическое ожидание (μ) и стандартное отклонение (σ) строго определены:
μ = 0
σ = 1
Формула стандартного нормального распределения выглядит так:
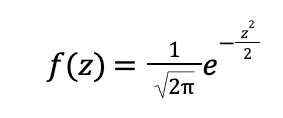
Где z — это стандартная величина, которая обозначает отклонение от среднего.
Стандартное нормальное распределение можно получить из обычного нормального распределения путем преобразования данных с использованием нормализации.
Нормализация — это процесс преобразования данных, при котором они приводятся к единой шкале, обычно с нулевым средним (μ) и единичным стандартным отклонением (σ). Это позволяет сравнивать данные, независимо от их первоначальных единиц измерения или масштаба.
Значения случайной величины x из нормального распределения преобразуют по следующей формуле:
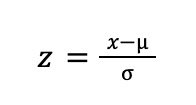
После нормализации все данные будут иметь среднее 0 и стандартное отклонение 1.
Что такое центральная предельная теорема и как она связана с нормальным распределением
Центральная предельная теорема (ЦПТ) объясняет, почему нормальное распределение так распространено в природе, науке и статистике.
Формулировка
Если взять много независимых случайных величин с любым (необязательно нормальным) распределением и сложить их, то их сумма (или среднее) будет приближаться к нормальному распределению при достаточно большом количестве слагаемых.
Доказательство
Пусть x1, x2, …, xn — независимые случайные величины с одинаковым распределением, имеющие математическое ожидание μ и дисперсию σ2.
Рассчитаем их среднее арифметическое:
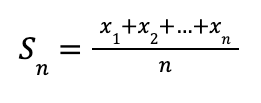
Тогда при n → ∞:
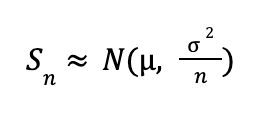
Это значит, что даже если исходные данные не были нормальными, их среднее значение будет нормально распределено при большом количестве наблюдений.
Когда ЦПТ работает лучше всего
- Если исходные данные не слишком скошены (если сильный сдвиг, потребуется больше наблюдений).
- Если размер выборки достаточно большой (n ≥ 30 должно быть достаточно).

Методы проверки нормальности распределения данных
Проверка данных на нормальность поможет выбрать правильные статистические методы для составления прогнозов и выводов. Проверить, что данные подчиняются нормальному распределению, можно с помощью различных подходов.
Графический подход
Визуальный анализ дает понять, как распределены данные, и сделать предварительные выводы. Помимо гистограммы, которая представляет из себя колокол при нормальном распределении, есть и другие методы проверки:
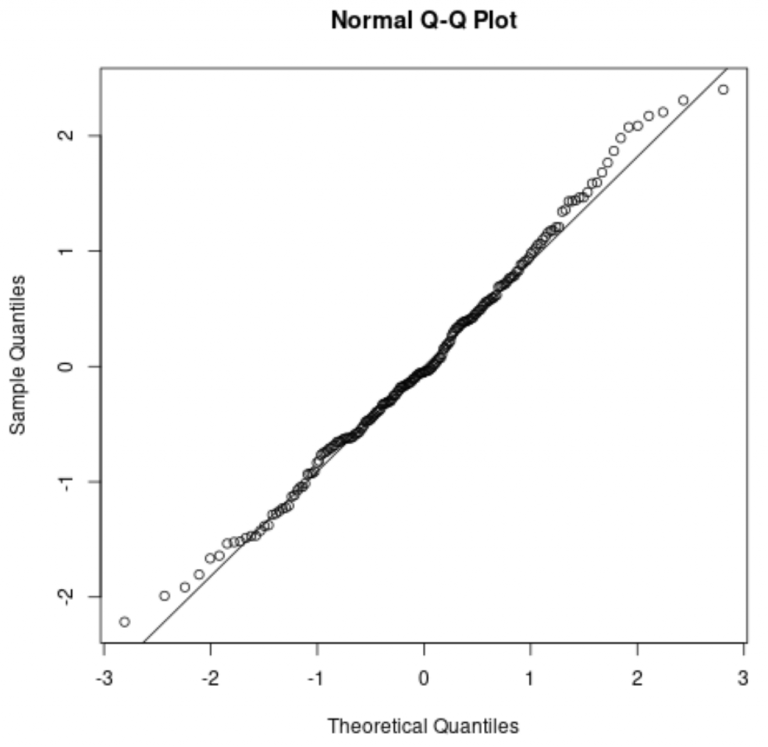
- Q-Q график (Quantile-Quantile plot)
Q-Q график — это инструмент для более точной визуализации нормальности данных. На его графике отображаются квантили выборки против теоретических квантилей нормального распределения.
Как это работает
Для каждого квантиля из выборки вычисляется теоретический квантиль нормального распределения (например, 10-й, 50-й, 90-й процентиль) и наносится точка на график.
Признак нормальности
Если данные нормально распределены, все точки на Q-Q графике будут располагаться вдоль прямой линии. Если есть отклонения, значит, данные не следуют нормальному распределению (например, кривые линии или отклонения в «хвостах»).
- Ящик с усами (Box plot)
Ящик с усами — это диаграмма, которая отображает распределение данных через квартильные значения (Q1, медиана, Q3) и диапазон данных с возможными выбросами.
Как это работает
Ящик: рисуется между первым квартилем (Q1) и третьим квартилем (Q3), внутри ящика находится медиана (Q2).
Усы: тянутся от верхней и нижней границы ящика до минимальных и максимальных значений, которые находятся в пределах 1.5 × IQR (где IQR — это межквартильный размах).
Выбросы: данные, которые находятся за пределами усов, считаются выбросами и отображаются как отдельные точки.
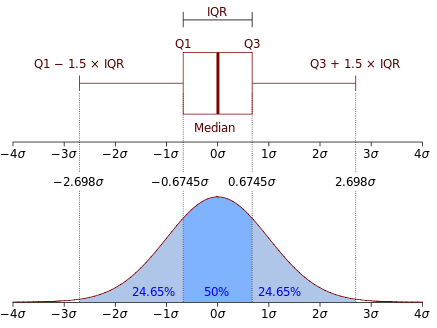
Признак нормальности
- Симметричный ящик.
- Усы одинаковой длины с обеих сторон.
- Медиана (внутри ящика) находится в центре.
- В диапазоне «усов» около 95% данных.
- Отсутствие выбросов (или их минимальное количество за пределами «усов»).
Статистические тесты
Статистические тесты дают более формальное и точное доказательство того, соответствуют ли данные нормальному распределению.
- Тест Шапиро-Уилка (Shapiro-Wilk test)
Один из самых точных тестов для проверки нормальности данных. Он проверяет нулевую гипотезу, что выборка из данных имеет нормальное распределение.
Как это работает
Анализирует отклонения от нормальности, сравнивая данные с идеальным нормальным распределением. Рассчитывается по формуле:
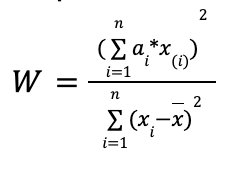
Где:
x(i) — это i-е порядковое статистическое значение (т.е. значение i после того, как данные отсортированы в порядке возрастания),
x — среднее (или математическое ожидание) выборки,
n — количество элементов в выборке,
a = [a1, a2, …, an] — вектор коэффициентов весов теста Шапиро-Уилка (берется из таблицы Шапиро-Уилка).
Коэффициенты a обладают следующими свойствами:
- Они антисимметричны: an+1−I = −ai для всех i,
- Для нечётных n выполняется a(n+1) / 2 = 0,
- Выполняется условие aT a = 1, что означает, что сумма квадратов этих коэффициентов равна 1.
Признак нормальности
После расчета полученное значение нужно сравнить с табличными значениями для заданного размера выборки. На основе этого сравнения вычисляется P-значение.
- Если P-значение меньше выбранного уровня значимости, то отвергается нулевая гипотеза, и делается вывод, что данные не подчиняются нормальному распределению.
- Если P-значение больше уровня значимости, то нулевая гипотеза не отвергается, и можно заключить, что нет статистически значимых доказательств того, что данные не подчиняются нормальному распределению.
- Тест Колмогорова-Смирнова
Тест Колмогорова-Смирнова проверяет гипотезу о том, что данные подчиняются определенному распределению. Тест основан на максимальном отклонении эмпирической функции распределения от теоретической функции распределения.
Как это работает
Рассчитывается максимальное абсолютное отклонение между эмпирической функцией распределения данных и теоретической функцией распределения. Это выражается формулой:
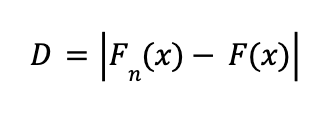
Где:
Fn(x) — эмпирическая функция распределения данных,
F(x) — теоретическая функция распределения (например, нормальная),
x — значение из выборки.
Признак нормальности
После вычисления значение D сравнивается с критическими значениями из таблицы Колмогорова-Смирнова для заданного уровня значимости и размера выборки.
- Если P-значение меньше выбранного уровня значимости, то нулевая гипотеза отвергается, и делается вывод, что данные не подчиняются предполагаемому распределению.
- Если P-значение больше уровня значимости, то нулевая гипотеза не отвергается, и можно заключить, что нет статистически значимых доказательств того, что данные не подчиняются предполагаемому распределению.
- Критерий χ² (Хи-квадрат)
Критерий χ² используется для проверки гипотезы о соответствии наблюдаемых данных определенному распределению. Он основан на сравнении наблюдаемых и ожидаемых частот в выборке.
Как это работает
Критерий χ² является результатом вычисления суммы квадратов отклонений между наблюдаемыми и ожидаемыми частотами. Формула выглядит так:
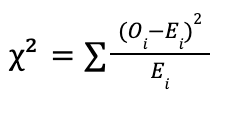
Где:
Oi — наблюдаемая частота для i-го интервала,
Ei — ожидаемая частота для i-го интервала (рассчитывается на основе теоретического распределения).
Признак нормальности
Полученное значение χ² сравнивается с критическими значениями из распределения χ² для заданного уровня значимости и количества степеней свободы, которые зависят от количества интервалов и параметров теста.
- Если P-значение меньше уровня значимости, отвергается нулевая гипотеза, и делается вывод, что данные не подчиняются предполагаемому распределению.
- Если P-значение больше уровня значимости, нулевая гипотеза не отвергается, и можно заключить, что нет статистически значимых доказательств того, что данные не подчиняются предполагаемому распределению.
Где используется нормальное распределение
Природные и социальные процессы
Время реакции человека на различные стимулы, температура тела, продолжительность жизни.
Промышленность и производство
Точность работы станков, размеры деталей, временные задержки в производственных процессах.
Финансы и экономика
Волатильность акций, изменение валютных курсов, процентные ставки по кредитам.
Наука и исследования
Погрешности в измерениях научных приборов, отклонения в результатах биологических экспериментов.
Подведем итог
- Нормальное распределение применяют а анализе случайных величин в статистике и других областях. Оно обладает симметричной колоколообразной формой.
- Главные параметры нормального распределения — математическое ожидание и стандартное отклонение. Они описывают среднее значение и плотность данных соответственно.
- Стандартное нормальное распределение используют для упрощения расчетов, так как данные в нем приведены к шкале с нулевым средним и стандартным отклонением, равным 1.
- Центральная предельная теорема объясняет, почему нормальное распределение так распространено в реальных данных.
- Для проверки нормальности данных используются графические методы (гистограммы, Q-Q графики, ящики с усами) и статистические тесты (тест Шапиро-Уилка, тест Колмогорова-Смирнова, критерий χ²).
