


Pandas DataFrame — инструмент, без которого не обходится ни один анализ данных в Data Science. Если вы только начинаете свой путь в ML, то знакомство с ним — ваш первый и самый важный шаг. Я сам прошел через множество проектов и соревнований, и поверьте, умение виртуозно владеть DataFrame’ами — это суперсила!
В статье рассказываем самое важное о Pandas DataFrame, чтобы вы могли уверенно использовать его в своих задачах.
Что такое DataFrame и зачем он нужен
Представьте себе обычную таблицу, как в Excel или Google Sheets. У нее есть строки и столбцы, у столбцов есть названия, а у строк — номера (или какие-то метки). DataFrame от библиотеки Pandas — это, по сути, такая же двумерная табличная структура данных, но живущая внутри вашего Python-кода.
- Столбцы (Columns): могут содержать данные разных типов (числа, строки, даты, булевы значения). У каждого столбца есть имя (метка).
- Строки (Rows): каждая строка — это одно наблюдение или запись. У строк тоже есть метки, которые называются индексом (Index). По умолчанию это просто целые числа от 0, но могут быть и осмысленные метки (например, даты или ID пользователей).

Зачем нужен DataFrame, если есть списки и словари Python?
Конечно, можно хранить данные и в стандартных структурах Python. Но как только данных становится больше, а задачи сложнее, DataFrame показывает свои сильные стороны:
- Удобная фильтрация и выборка. Легко выбрать нужные строки или столбцы по условиям, меткам или позициям.
- Мощные операции: агрегирование данных (подсчет среднего, суммы, группировка), слияние таблиц, работа с временными рядами — все это делается парой строк кода.
- Обработка пропусков. В реальных данных всегда есть пропуски. Pandas дает удобные инструменты, чтобы их искать и заполнять / удалять.
- Интеграция. DataFrame — стандарт де-факто для обмена данными между другими библиотеками Data Science (Scikit-learn, Matplotlib, Seaborn, etc.).
- Оптимизация. Многие операции в Pandas написаны на C или Cython, что делает их значительно быстрее, чем аналогичные операции на чистом Python в циклах.
Проще говоря, DataFrame — это швейцарский нож для работы с табличными данными в Python.
Как создать DataFrame в Pandas
Есть несколько способов создать свой первый DataFrame:
- Из словаря Python. Самый частый способ для небольших наборов данных. Ключи словаря становятся именами столбцов, а значения (списки или массивы NumPy) – данными этих столбцов. Важно, чтобы списки были одинаковой длины!
import pandas as pd
data_dict = {
'Имя': ['Алиса', 'Борис', 'Вера', 'Григорий'],
'Возраст': [25, 32, 21, 45],
'Город': ['Москва', 'СПб', 'Москва', 'Екатеринбург']
}
df_from_dict = pd.DataFrame(data_dict)
print(df_from_dict)
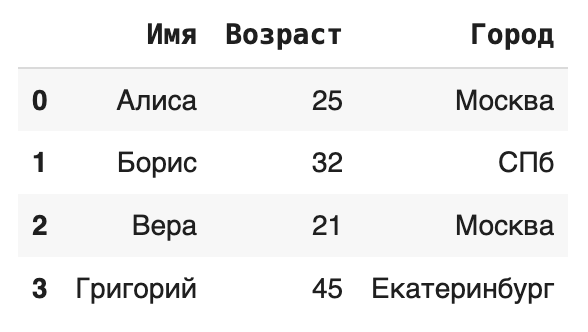
- Из списков / кортежей. Можно создать DataFrame из списка списков (или кортежей), где каждый вложенный список — это одна строка. В этом случае нужно явно указать имена столбцов.
data_list = [
('Алиса', 25, 'Москва'),
('Борис', 32, 'СПб'),
('Вера', 21, 'Москва'),
('Григорий', 45, 'Екатеринбург')
]
columns_names = ['Имя', 'Возраст', 'Город']
df_from_list = pd.DataFrame(data_list, columns=columns_names)
print(df_from_list)
# Вывод будет таким же, как в предыдущем приме
- Чтение из файлов: это самый реалистичный сценарий. Данные обычно хранятся во внешних файлах. Pandas умеет читать множество форматов:
- CSV (Comma Separated Values): df = pd.read_csv(‘путь/к/файлу.csv’)
- Excel: df = pd.read_excel(‘путь/к/файлу.xlsx’, sheet_name=’Лист1′) (можно указать имя листа)
- SQL: df = pd.read_sql(‘SELECT * FROM users’, connection_object) (нужно подключение к базе данных)
- И многие другие: JSON, HTML, HDF5, Parquet…
Первичный обзор структуры DataFrame
Итак, у нас есть DataFrame. Как быстро с ним познакомиться? Вот несколько команд для «экспресс-анализов»:
- df.head(n). Показывает первые n строк (по умолчанию 5). Полезно, чтобы увидеть структуру данных и примеры значений. df.tail(n) делает то же самое для последних строк.
print(df_from_dict.head(2))
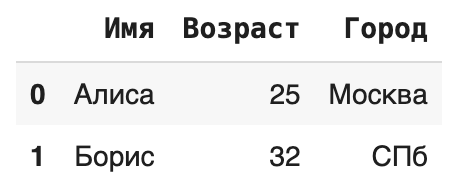
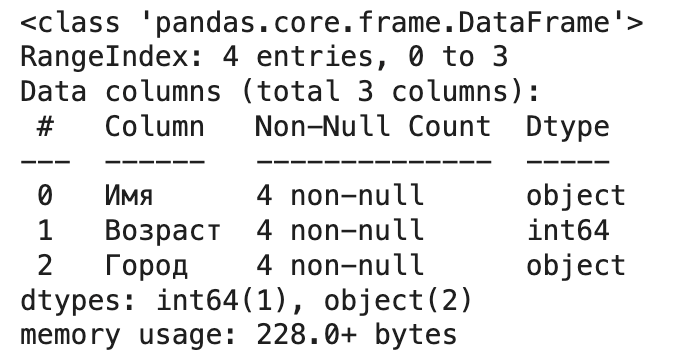
- df.info(). Выводит сводную информацию: количество строк, количество столбцов, имена столбцов, количество непустых значений в каждом столбце и тип данных каждого столбца, а также использование памяти. Критически важная команда для понимания типов данных и наличия пропусков.
df_from_dict.info()
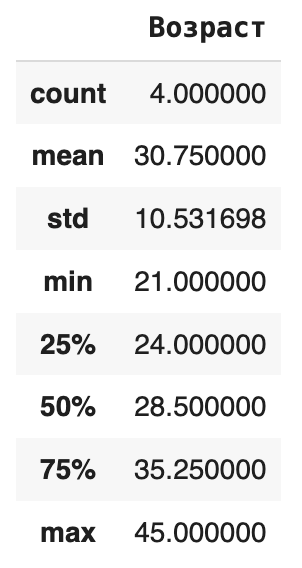
- df.describe(). Рассчитывает основные описательные статистики для числовых столбцов: количество, среднее, стандартное отклонение, минимум, максимум, медиану (50%) и квартили (25%, 75%). Дает быстрый взгляд на распределение числовых признаков.
print(df_from_dict.describe())
- Атрибуты: это не методы (без скобок ()), а свойства объекта DataFrame:
- df.shape: Возвращает кортеж (количество строк, количество столбцов).
- df.columns: Возвращает список имен столбцов.
- df.dtypes: Возвращает Series с типами данных каждого столбца.
- df.index: Возвращает объект Index с метками строк.

Выборка, фильтрация и сортировка в Pandas DataFrame
Одна из главных прелестей Pandas — гибкость в выборе нужных данных.
Индексация и доступ к данным
Есть два основных способа «достучаться» до ячеек, строк или столбцов:
- .loc[] (Location): использует МЕТКИ индекса и столбцов.
- df.loc[метка_строки, метка_столбца]: выбрать конкретную ячейку.
- df.loc[метка_строки] или df.loc[метка_строки, :]: выбрать всю строку по метке.
- df.loc[:, метка_столбца]: выбрать весь столбец по имени.
- df.loc[[метка1, метка2], [столбец1, столбец2]]: выбрать несколько строк и столбцов по их меткам.
- df.loc[метка_начала:метка_конца]: срез строк по меткам (включая конец!).
# Используем df_from_dict, где индекс по умолчанию - числа 0, 1, 2, 3
print("Строка с индексом 1:\n", df_from_dict.loc[1])
print("\nВозраст человека с индексом 0:", df_from_dict.loc[0, 'Возраст'])
print("\nСтолбец 'Город':\n", df_from_dict.loc[:, 'Город'])
print("\nСтроки 1 и 3, столбцы 'Имя' и 'Город':\n", df_from_dict.loc[[1, 3], ['Имя', 'Город']])
![loc[] (Location)](https://blog.skillfactory.ru/wp-content/uploads/2025/06/loc-location.png)
- .iloc[] (Integer Location): использует ЦЕЛОЧИСЛЕННЫЕ ПОЗИЦИИ (индексы, начиная с 0).
- df.iloc[индекс_строки, индекс_столбца]: выбрать ячейку по номеру строки и столбца.
- df.iloc[индекс_строки] или df.iloc[индекс_строки, :]: выбрать всю строку по ее номеру.
- df.iloc[:, индекс_столбца]: выбрать весь столбец по его номеру.
- df.iloc[[0, 2], [0, 1]]: выбрать строки 0 и 2, столбцы 0 и 1.
- df.iloc[0:2]: срез строк по позициям (НЕ включая конец, как в Python!).
print("Вторая строка (индекс 1):\n", df_from_dict.iloc[1])
print("\nЗначение в 1-й строке, 2-м столбце:", df_from_dict.iloc[0, 1]) # Возраст Алисы
print("\nПервый столбец (индекс 0):\n", df_from_dict.iloc[:, 0]) # Столбец 'Имя'
print("\nПервые две строки:\n", df_from_dict.iloc[0:2])
![iloc[] (Integer Location)](https://blog.skillfactory.ru/wp-content/uploads/2025/06/iloc-integer-location.png)
Важно: не путайте .loc[] и .iloc[]! .loc работает с именами (метками), .iloc – с номерами позиций.
Доступ к столбцам. самый простой способ выбрать один столбец — использовать квадратные скобки с именем столбца: df[‘имя_столбца’]. Это вернет объект Series. Можно также использовать атрибутный доступ df.имя_столбца, но это работает, только если имя столбца — валидный идентификатор Python (без пробелов, спецсимволов, не совпадает с методами DataFrame). Безопаснее использовать df[‘имя_столбца’].
print(df_from_dict['Имя']) # Рекомендуемый способ print(df_from_dict.Имя) # Работает, но менее надежно

Булева фильтрация
Создаем условие, которое для каждой строки возвращает True или False, а затем используем эту «маску» для фильтрации DataFrame.
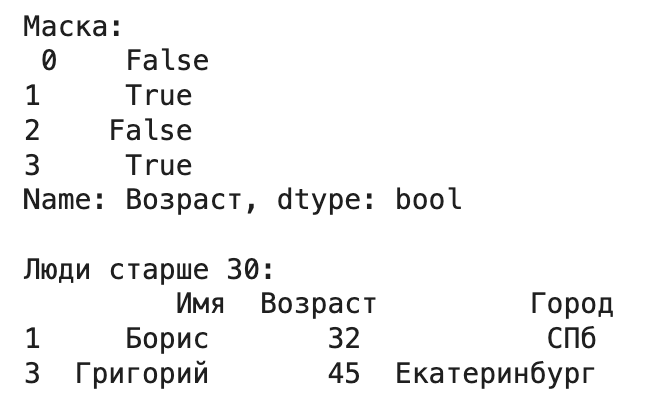
- Простое условие: выбрать всех, кто старше 30.
mask = df_from_dict['Возраст'] > 30
print("Маска:\n", mask)
print("\nЛюди старше 30:\n", df_from_dict[mask])
# Или короче:
print("\nЛюди старше 30 (короткая запись):\n", df_from_dict[df_from_dict['Возраст'] > 30])

- Комбинирование условий: используйте & (логическое И), | (логическое ИЛИ), ~ (логическое НЕ). Обязательно заключайте каждое условие в круглые скобки ()!
# Люди старше 30 ИЗ Москвы
filtered_df = df_from_dict[(df_from_dict['Возраст'] > 30) & (df_from_dict['Город'] == 'Москва')]
print(filtered_df) # Никого нет
# Люди младше 30 ИЛИ из СПб
filtered_df = df_from_dict[(df_from_dict['Возраст'] < 30) | (df_from_dict['Город'] == 'СПб')]
print("\nМладше 30 или из СПб:\n", filtered_df)

- Фильтрация по списку значений: метод .isin() проверяет, содержится ли значение в столбце в переданном списке.
# Люди из Москвы или СПб
cities_of_interest = ['Москва', 'СПб']
filtered_df = df_from_dict[df_from_dict['Город'].isin(cities_of_interest)]
print("\nЛюди из Москвы или СПб:\n", filtered_df)

Сортировка
Часто нужно упорядочить данные по значениям в одном или нескольких столбцах.
- df.sort_values(by=’имя_столбца’). Сортирует DataFrame по значениям указанного столбца (по умолчанию по возрастанию).
- ascending=False: сортировать по убыванию.
- by=[‘столбец1’, ‘столбец2’]. Сортировать сначала по столбец1, а затем внутри одинаковых значений столбец1 — по столбец2.
- inplace=True. Модифицировать DataFrame «на месте», не создавая копию (используйте с осторожностью). По умолчанию False.
- ignore_index=True: сбросить индекс отсортированного DataFrame (будет 0, 1, 2…).
# Сортировка по возрасту по убыванию
df_sorted_age = df_from_dict.sort_values(by='Возраст', ascending=False)
print("Сортировка по возрасту (убыв.):\n", df_sorted_age)
# Сортировка сначала по Городу (алфавитный порядок), потом по Возрасту (возрастание)
df_sorted_city_age = df_from_dict.sort_values(by=['Город', 'Возраст'])
print("\nСортировка по Городу, затем по Возрасту:\n", df_sorted_city_age)

Модификация: добавление строк и столбцов в Pandas DataFrame
Данные редко бывают статичными. Часто нужно добавлять новые вычисленные признаки (столбцы) или объединять данные из разных источников (добавлять строки).
Добавление столбцов
- Прямое присваивание — самый простой способ. Создаем новый столбец и присваиваем ему список, массив NumPy, объект Series или скалярное значение (которое будет продублировано для всех строк). Длина должна совпадать с количеством строк в DataFrame.
# Добавим столбец с годом рождения (примерно)
current_year = 2024
df_from_dict['Год Рождения'] = current_year - df_from_dict['Возраст']
# Добавим столбец со статусом (одинаковый для всех)
df_from_dict['Статус'] = 'Активен'
print("\nDataFrame с новыми столбцами:\n", df_from_dict)

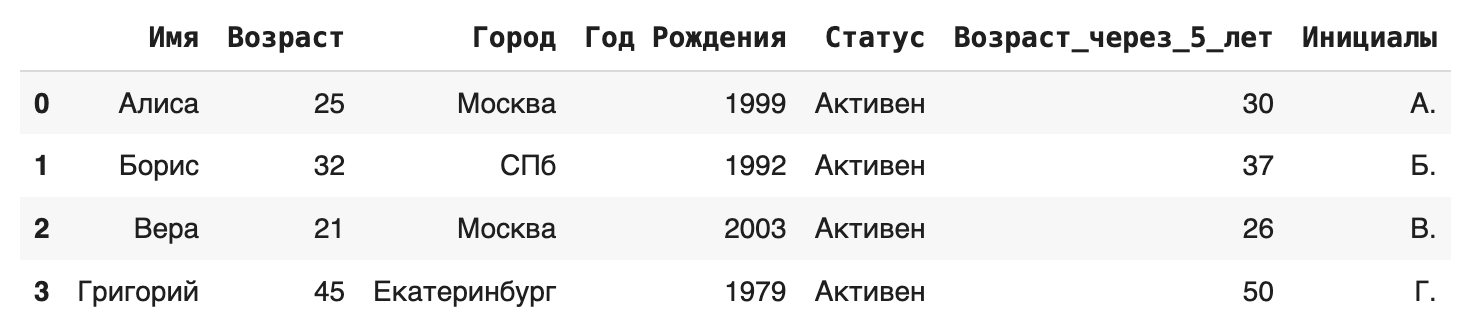
- Метод .assign() позволяет создавать один или несколько новых столбцов «на лету», возвращая новый DataFrame с добавленными столбцами. Особенно удобен в цепочках вызовов методов. Можно использовать lambda-функции для вычислений на основе существующих столбцов.
# Добавим столбец 'Возраст через 5 лет' и 'Инициалы'
df_assigned = df_from_dict.assign(
Возраст_через_5_лет = lambda x: x['Возраст'] + 5,
Инициалы = lambda x: x['Имя'].str[0] + '.'
)
# Исходный df_from_dict не изменился!
print("\nDataFrame созданный через assign:\n", df_assigned)
Добавление строк
- pd.concat() — рекомендуемый способ для объединения нескольких DataFrame’ов (или Series) вдоль одной из осей. Для добавления строк используем axis=0.
# Создадим новый DataFrame для добавления
new_data = pd.DataFrame({
'Имя': ['Дарья', 'Евгений'],
'Возраст': [29, 35],
'Город': ['Новосибирск', 'СПб'],
'Год Рождения': [1995, 1989], # Не забываем про все столбцы!
'Статус': ['Активен', 'Неактивен']
})
# Объединяем старый и новый DataFrame
df_combined = pd.concat([df_from_dict, new_data], axis=0, ignore_index=True)
# ignore_index=True нужен, чтобы создать новый непрерывный индекс (0, 1, 2, ...)
print("\nОбъединенный DataFrame:\n", df_combined)

- Метод .append() устарел с версии Pandas 1.4.0 и будет удален в будущем (а может, и уже удален — зависит от того, когда вы читаете эту статью). Раньше использовался для добавления строк из другого DataFrame или словаря, но он менее эффективен, чем concat. Лучше сразу привыкать к pd.concat().
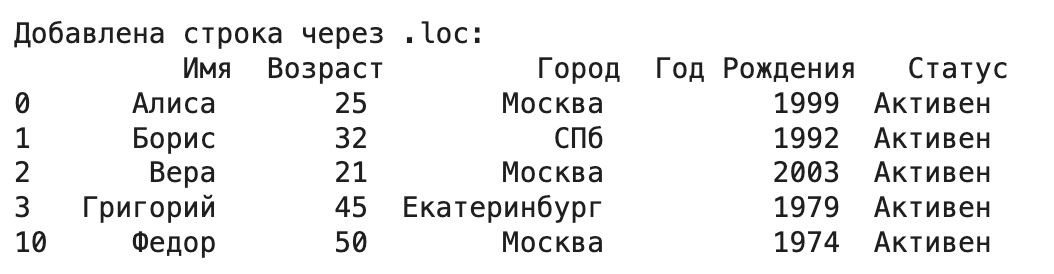
- Добавление по индексу (.loc). Можно добавить одну строку, присвоив список или словарь по новой метке индекса. Убедитесь, что новая метка уникальна.
df_temp = df_from_dict.copy() # Работаем с копией, чтобы не менять оригинал
new_index_label = 10 # Новая метка индекса
df_temp.loc[new_index_label] = ['Федор', 50, 'Москва', 1974, 'Активен']
print("\nДобавлена строка через .loc:\n", df_temp)
Изменение существующих значений
- Через .loc / .iloc. Самый прямой способ изменить значение в конкретной ячейке или целой строке/столбце.
# Изменить возраст Бориса
df_from_dict.loc[1, 'Возраст'] = 33
# Изменить город для всех, кто старше 40, на 'Неизвестен'
df_from_dict.loc[df_from_dict['Возраст'] > 40, 'Город'] = 'Неизвестен'
print("\nDataFrame после изменений:\n", df_from_dict)

- Метод df.replace() удобен для замены конкретных значений по всему DataFrame или в конкретном столбце.
# Заменим 'СПб' на 'Санкт-Петербург' в столбце 'Город'
df_from_dict['Город'] = df_from_dict['Город'].replace('СПб', 'Санкт-Петербург')
print("\nDataFrame после replace:\n", df_from_dict)

Работа с пропущенными данными в Pandas DataFrame
Реальные данные почти всегда содержат пропуски (обозначаются как NaN — Not a Number). Pandas предоставляет отличные инструменты для работы с ними.
Выявление пропусков
- .isnull() или .isna() возвращают DataFrame с булевыми значениями, где True означает пропуск.
- .notnull() — противоположность isnull(), True означает наличие данных.
- .isna().sum(). Самый частый способ — подсчитать количество пропусков в каждом столбце.
# Создадим DataFrame с пропусками для примера
data_nan = {
'A': [1, 2, None, 4],
'B': [5, None, None, 8],
'C': ['x', 'y', 'z', 'w']
}
df_nan = pd.DataFrame(data_nan)
print("Исходный DataFrame с NaN:\n", df_nan)
print("\nПроверка на NaN (isnull):\n", df_nan.isnull())
print("\nКоличество NaN в каждом столбце:\n", df_nan.isna().sum())

Удаление пропусков
Метод df.dropna() удаляет строки или столбцы с пропусками.
- axis=0 (по умолчанию): удалить строки, содержащие хотя бы один NaN.
- axis=1: удалить столбцы, содержащие хотя бы один NaN.
- how=’any’ (по умолчанию): удалить строку/столбец, если есть хотя бы один NaN.
- how=’all’: удалить строку/столбец, только если все значения в нем NaN.
- thresh=N: оставить только те строки/столбцы, которые имеют как минимум N непропущенных значений.
- subset=[‘col1’, ‘col2’]: применять удаление только на основе пропусков в указанных столбцах.
# Удалить строки с любым NaN
print("\nУдалены строки с NaN:\n", df_nan.dropna(axis=0))
# Удалить столбцы с любым NaN
print("\nУдалены столбцы с NaN:\n", df_nan.dropna(axis=1))
# Удалить строки, где NaN есть в столбце 'B'
print("\nУдалены строки с NaN в 'B':\n", df_nan.dropna(subset=['B']))

Заполнение пропусков
Часто удаление данных — не лучший вариант, так как мы теряем информацию. Вместо этого можно заполнить пропуски (NaN) значениями с помощью метода df.fillna().
- value=значение — заполнить все NaN указанным значением (числом, строкой, и т.д.). Часто используют среднее или медиану для числовых столбцов.
- value={‘col1’: val1, ‘col2’: val2} — заполнить пропуски разными значениями для разных столбцов.
- method=’ffill’ (forward fill) — заполнить NaN предыдущим непропущенным значением в столбце.
- method=’bfill’ (backward fill) — заполнить NaN следующим непропущенным значением в столбце.
# Заполнить все NaN нулями
print("\nЗаполнение NaN нулями:\n", df_nan.fillna(0))
# Заполнить NaN в 'A' средним значением 'A', в 'B' - медианой 'B'
mean_A = df_nan['A'].mean()
median_B = df_nan['B'].median() # Медиана устойчивее к выбросам
df_filled = df_nan.fillna({'A': mean_A, 'B': median_B})
print("\nЗаполнение средним/медианой:\n", df_filled)
# Заполнение методом ffill
print("\nЗаполнение методом ffill:\n", df_nan.fillna(method='ffill'))

- Интерполяция. Для числовых данных можно использовать df.interpolate(), который заполняет пропуски на основе соседних значений (например, линейная интерполяция method=’linear’).
print("\nЛинейная интерполяция:\n", df_nan['A'].interpolate(method='linear'))

Выбор способа заполнения пропусков сильно зависит от контекста задачи и природы данных!
Оптимизация производительности Pandas DataFrame
Когда данных становится много (сотни тысяч или миллионы строк), скорость выполнения операций становится критичной. Pandas быстр, но есть способы сделать его еще быстрее.
Векторизация vs циклы
Золотое правило Pandas: избегайте циклов for по строкам!
Внутренние операции Pandas (например, сложение двух столбцов df[‘col1’] + df[‘col2’]) выполняются как векторные операции. Они применяются ко всему столбцу сразу на низком уровне (часто в C). Это гораздо быстрее, чем итерация по каждой строке в Python и выполнение операции.
Плохо (медленно):
# НЕ ДЕЛАЙТЕ ТАК ДЛЯ БОЛЬШИХ ДАННЫХ! results = [] for i in range(len(df)): row = df.iloc[i] results.append(row['col1'] + row['col2']) df['sum_slow'] = results
Хорошо (быстро):
df['sum_fast'] = df['col1'] + df['col2']
Метод .apply() и его альтернативы
Метод df.apply(my_function, axis=1) позволяет применить произвольную функцию my_function к каждой строке (axis=1) или столбцу (axis=0). Это гибко, но часто очень медленно, особенно при axis=1, так как для каждой строки вызывается Python-функция.
Когда использовать .apply(). Только если нет встроенной векторизованной функции Pandas / NumPy для вашей задачи.
Альтернативы .apply():
- Встроенные методы: df.sum(), df.mean(), df.max(), df.idxmax(), строковые методы через .str (df[‘text’].str.lower()), методы дат через .dt (df[‘date’].dt.month) — они всегда быстрее.
- groupby().agg() / groupby().transform(): для операций внутри групп.
- Векторные операции NumPy: если нужна сложная математика, функции NumPy (np.log(), np.sin(), etc.) отлично работают с Pandas Series.
Оптимизация типов данных
По умолчанию Pandas может использовать больше памяти, чем необходимо.
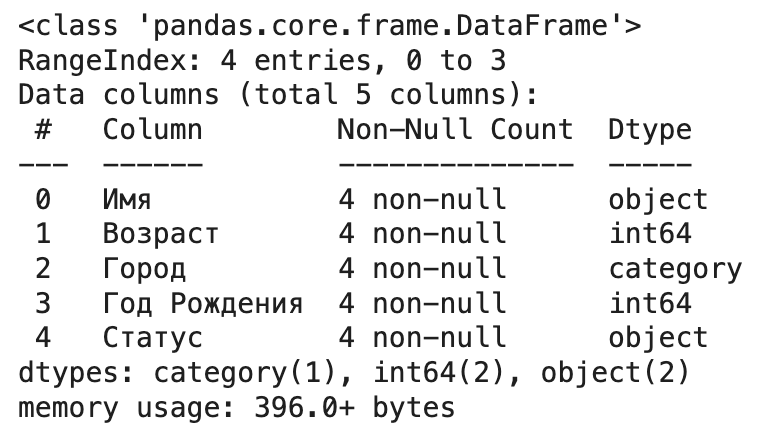
- Категориальный тип (pd.Categorical). Если в столбце много повторяющихся строковых значений (например, ‘страна’, ‘статус’, ‘категория товара’), преобразуйте его в тип category. Pandas будет хранить только уникальные значения и целочисленные коды для каждой строки. Это сильно экономит память и может ускорить операции типа groupby.
# Если в 'Город' мало уникальных значений
df_from_dict['Город'] = df_from_dict['Город'].astype('category')
df_from_dict.info() # Посмотрите на изменение использования памяти
- Числовые типы. Pandas часто использует int64 и float64. Если ваши числа помещаются в меньший диапазон, используйте int8, int16, int32 или float32. Это можно сделать при чтении файла (dtype={‘col’: np.int32}) или через метод .astype(). Используйте pd.to_numeric(df[‘col’], downcast=’integer’/’float’) для автоматического понижения типа.
Работа с большими данными
Если файл не помещается в оперативную память:
- Чтение чанками (кусками). При чтении больших CSV-файлов используйте параметр chunksize в pd.read_csv(). Это вернет итератор, который позволяет обрабатывать файл по частям.
chunk_iter = pd.read_csv('очень_большой_файл.csv', chunksize=100000) # Читаем по 100 000 строк
results = []
for chunk in chunk_iter:
# Обрабатываем chunk (это обычный DataFrame)
processed_chunk = chunk[chunk['value'] > 0] # Пример обработки
results.append(processed_chunk)
final_df = pd.concat(results) # Собираем результат
- Библиотеки Dask или Modin. Для по-настоящему больших данных, которые не помещаются в память одной машины или требуют параллельной обработки на нескольких ядрах/машинах, рассмотрите Dask или Modin. Они предоставляют API, очень похожий на Pandas, но распределяют вычисления.
Профилирование кода
Чтобы понять, какие части вашего кода работают медленно:
- %timeit: в Jupyter Notebook или IPython используйте “магическую” команду %timeit перед строкой кода, чтобы измерить среднее время ее выполнения.
- ydata-profiling (ранее pandas_profiling): эта библиотека генерирует подробный HTML-отчет о вашем DataFrame: типы данных, пропуски, статистики, распределения, корреляции, потенциальные проблемы. Очень полезно для первичного анализа и поиска узких мест.
Это основной набор знаний, который поможет вам начать работать с Pandas DataFrame. Конечно, это лишь верхушка айсберга, у Pandas еще много возможностей. Но освоив эти основы, вы уже сможете решать множество практических задач анализа данных.
Главное — не бойтесь экспериментировать, пробовать разные методы и читать документацию. Если есть вопросы — смело задавайте в комментариях!