


Apache Kafka — это распределенная платформа, которая передает и обрабатывает данные в режиме реального времени. Ее используют для логирования, передачи событий, потоковой аналитики и интеграции микросервисов.
Для работы с данными внутри Kafka есть Kafka Streams — библиотека, которая помогает строить потоковые приложения. С ее помощью можно обрабатывать события в реальном времени, например, выполнять ETL-процессы без использования внешних систем.
В статье рассказываем, как устроен Kafka Streams, и разбираем практические примеры его применения.
Как работает Kafka Streams
Kafka Streams помогает получать данные из Kafka, обрабатывать их и передавать дальше. Чтобы понять, как это работает, представьте конвейер на фабрике:
- Источник данных — сырье поступает на конвейер.
- Обработка данных — сырье превращается в готовый продукт.
- Запись данных — готовый продукт отправляется на склад.

В потоковой обработке данных процесс устроен аналогично:
- Данные поступают в систему (например, заказы интернет-магазина).
- Происходит их обработка (фильтрация, суммирование, объединение).
- Результат передается дальше (в другой топик, базу данных или отчетную систему).
Топик (topic) в Kafka — это хранилище сообщений, из которого данные могут читать одни приложения и записывать другие. Сообщения не удаляются сразу, а хранятся в течение заданного времени. Данные в топике распределяются по партициям — независимым частям, с помощью которых можно обрабатывать информацию параллельно.
В Kafka Streams этот процесс реализуется с помощью трех ключевых компонентов:
- Source Processor — читает данные из Kafka.
- Stream Processor — выполняет над ними операции (фильтрация, суммирование и т. д.).
- Sink Processor — записывает результат обратно в Kafka или в другую систему.
Теперь разберем каждый из этих компонентов подробнее.
Чтение данных (Source Processor)
Этот компонент читает поток событий из Kafka и передает его дальше.
Пример: в интернет-магазине есть сервис заказов. Когда пользователь оформляет покупку, информация о ней отправляется в Kafka:
{
"order_id": 123,
"user_id": 456,
"amount": 500,
"status": "paid"
}Эти данные хранятся в Kafka-топике orders-topic.
Приложение Kafka Streams может подписаться на этот топик и получать новые заказы:
StreamsBuilder builder = new StreamsBuilder();
// Читаем поток заказов из Kafka
KStream<String, String> ordersStream = builder.stream("orders-topic");
// Выводим входящие заказы в лог (для отладки)
ordersStream.peek((key, value) -> System.out.println("Received order: " + value));Source Processor читает поток данных из Kafka и передает его в Stream Processor для обработки.
Обработка данных (Stream Processor)
Теперь, когда у нас есть поток заказов, можно его обработать.
Фильтрация: допустим, нужно оставить только оплаченные заказы.
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
ObjectMapper objectMapper = new ObjectMapper();
// Поток заказов, представленный в виде пар ключ-значение (id заказа, JSON с информацией)
KStream<String, String> paidOrders = ordersStream
.filter((key, value) -> {
try {
// JSON в Kafka приходит как строка, парсим его в объект
JsonNode jsonNode = objectMapper.readTree(value);
// Извлекаем поле "status" и проверяем, равно ли оно "paid"
String status = jsonNode.get("status").asText();
return "paid".equalsIgnoreCase(status); // Только оплаченные заказы остаются в потоке
} catch (Exception e) {
// Если JSON некорректный или поле "status" отсутствует, игнорируем сообщение
return false;
}
});Агрегация: предположим, нам нужно подсчитать сумму покупок каждого пользователя.
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.kstream.KTable;
import org.apache.kafka.streams.kstream.Materialized;
// Перед агрегацией устанавливаем ключ user_id
KStream<String, String> keyedOrders = paidOrders
.selectKey((key, value) -> extractUserId(value)); // Теперь ключ = user_id
KTable<String, Long> totalAmountByUser = keyedOrders
.groupByKey() // Группируем по user_id
.aggregate(
() -> 0L, // Начальное значение суммы = 0
(userId, newValue, aggValue) -> aggValue + extractAmount(newValue), // Считаем сумму покупок
Materialized.with(Serdes.String(), Serdes.Long()) // Храним результат как строку и число
);Объединение потоков: иногда нужно добавить к заказу данные о пользователе.
Допустим, есть еще один топик users-topic, где хранится информация о клиентах. Мы хотим объединить эти данные с заказами:
// Читаем таблицу пользователей из Kafka (ключом является user_id)
KTable<String, String> usersTable = builder.table("users-topic");
// Перед объединением устанавливаем user_id как ключ
KStream<String, String> keyedOrdersForJoin = ordersStream
.selectKey((key, value) -> extractUserId(value)); // Устанавливаем user_id как ключ
// Объединяем заказы с пользователями по user_id
KStream<String, String> enrichedOrders = keyedOrdersForJoin.join(
usersTable, // Присоединяем таблицу пользователей
(order, user) -> order + " by " + (user != null ? user : "unknown") // Если данных нет, подставляем "unknown"
);Запись данных (Sink Processor)
После обработки данные надо записать обратно в Kafka или в другую систему.
Пример: сохраняем только оплаченные заказы в новый топик paid-orders-topic:
paidOrders.to("paid-orders-topic");Другие сервисы могут подписаться на paid-orders-topic, чтобы получать данные о подтвержденных заказах.
Kafka Streams также может отправлять данные в базы данных, REST API или файлы, если это необходимо.
Как все компоненты работают вместе
Теперь, когда мы разобрали каждый компонент, посмотрим, как они взаимодействуют в одном потоке данных.
Задача
Допустим, нам нужно анализировать заказы:
- Получать заказы из Kafka.
- Оставлять только оплаченные.
- Считать сумму покупок каждого клиента.
- Записывать результат в новый топик.
Шаг 1. Читаем заказы из Kafka:
// Конфигурация Kafka Streams
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-app");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
// Создаем билдер потоков
StreamsBuilder builder = new StreamsBuilder();
// Читаем поток заказов из Kafka
KStream<String, String> ordersStream = builder.stream("orders-topic");Шаг 2. Фильтруем только оплаченные заказы:
// Фильтруем только заказы со статусом "paid"
KStream<String, String> paidOrders = ordersStream
.filter((key, value) -> value.contains("\"status\":\"paid\""));Шаг 3. Группируем заказы по пользователям и считаем сумму покупок:
// Группируем заказы по user_id и считаем сумму всех покупок
KTable<String, Long> totalAmountByUser = paidOrders
.groupBy((key, value) -> extractUserId(value))
.aggregate(
() -> 0L, // Начальная сумма = 0
(key, newValue, aggValue) -> aggValue + extractAmount(newValue), // Считаем сумму покупок
Materialized.with(Serdes.String(), Serdes.Long()) // Храним результат как строку и число
);Шаг 4. Записываем результат в новый топик, чтобы другие сервисы могли его использовать:
// Записываем итоговую сумму покупок в Kafka
totalAmountByUser.toStream().to("aggregated-orders-topic");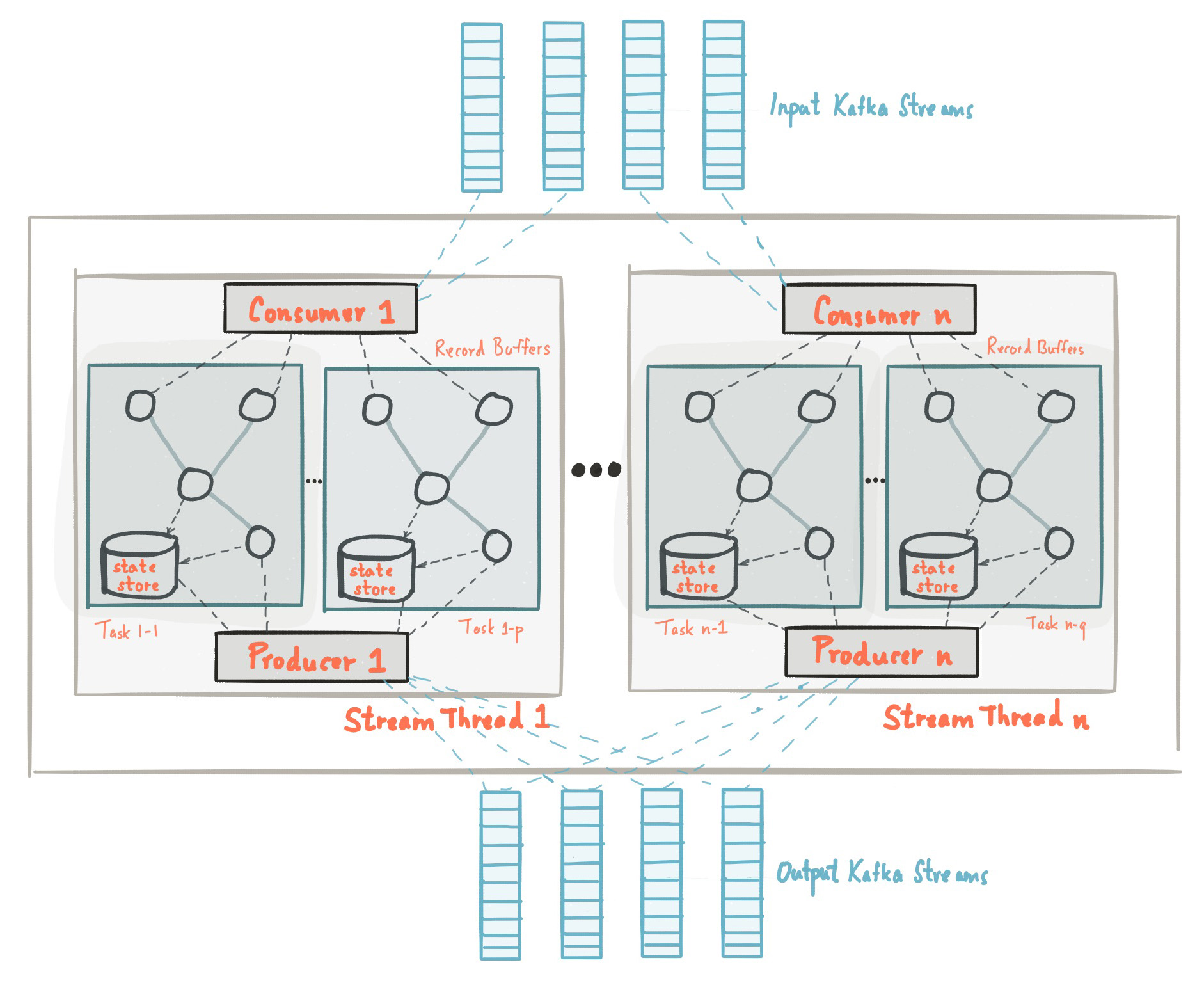
Каковы возможности библиотеки Kafka Streams
После того как мы разобрали основные компоненты Kafka Streams, рассмотрим три ключевые операции, которые можно выполнять с потоками данных:
- Фильтрация — отбор нужных событий.
- Агрегация — подсчет количества событий или вычисление суммарных значений.
- Объединение потоков — соединение данных из разных источников.
Фильтрация событий
Фильтрация помогает убрать ненужные данные из потока. Например, если у нас есть поток транзакций, мы можем оставить только успешные платежи, отбросив ошибки и отмененные заказы.
Пример: оставляем только транзакции со статусом «SUCCESS».
// Читаем поток данных из Kafka
KStream<String, String> transactions = builder.stream("transactions-topic");
// Фильтруем только успешные платежи
KStream<String, String> successfulPayments = transactions
.filter((key, value) -> value.contains("\"status\":\"SUCCESS\""));
// Записываем результат в новый топик
successfulPayments.to("successful-payments-topic");Теперь в successful-payments-topic содержатся только успешные транзакции, а ненужные данные отброшены.
Агрегация данных
Kafka Streams позволяет подсчитывать количество событий или суммировать их значения.
Пример: подсчитываем, сколько заказов сделал каждый пользователь.
// Читаем поток заказов из Kafka
KStream<String, String> orders = builder.stream("orders-topic");
// Перед агрегацией устанавливаем user_id как ключ
KStream<String, String> keyedOrders = orders
.selectKey((key, value) -> extractUserId(value));
// Группируем заказы по пользователям и считаем их количество
KTable<String, Long> orderCounts = keyedOrders
.groupByKey() // Группируем по user_id
.count(); // Подсчитываем количество заказов для каждого пользователя
// Записываем результат в новый топик
orderCounts.toStream().to("order-counts-topic");Теперь можно, например, отслеживать активность клиентов в реальном времени и видеть, сколько заказов они сделали.
Объединение потоков (Joins)
Часто данные о событиях распределены по разным источникам. Например, у нас может быть один топик с заказами, а другой — с информацией о пользователях.
Kafka Streams позволяет объединять эти данные, чтобы получить полную картину.
Пример: добавляем к заказам информацию о пользователях.
// Читаем поток заказов из Kafka
KStream<String, String> orders = builder.stream("orders-topic");
// Читаем таблицу пользователей из Kafka
KTable<String, String> users = builder.table("users-topic");
// Перед объединением устанавливаем user_id как ключ
KStream<String, String> keyedOrders = orders
.selectKey((key, value) -> extractUserId(value));
// Объединяем заказы с пользователями по user_id
KStream<String, String> enrichedOrders = keyedOrders
.join(users, (order, user) -> "{ \"order\": \"" + order + "\", \"user\": \"" + user + "\" }");
// Записываем результат в Kafka
enrichedOrders.to("enriched-orders-topic");Теперь вместо сухих данных о заказах мы получаем полную информацию: кто его сделал, на какую сумму и другие детали о клиенте.

Как Kafka Streams работает с данными
Масштабируемость и обработка больших объемов данных
Kafka Streams изначально разработан для работы с большими потоками данных. Он может обрабатывать миллионы событий в секунду и автоматически распределять нагрузку.
Когда данных мало, все сообщения можно обработать в одном экземпляре Kafka Streams. Но если поток увеличивается, например во время распродажи в интернет-магазине, одного сервиса уже недостаточно.
Библиотека решает эту проблему с помощью двух механизмов: горизонтального масштабирования и партиционирования данных.
Горизонтальное масштабирование — это способ увеличения производительности, при котором запускается несколько экземпляров Kafka Streams, и Kafka автоматически распределяет между ними обработку данных. Если один экземпляр выходит из строя, другие продолжают работу без потери данных.
Партиционирование данных — механизм, при котором данные в топиках Kafka разделяются на независимые части — партиции, каждая из которых обрабатывается отдельно. Например, заказы интернет-магазина могут быть разделены по регионам:
- Партиция 1 — заказы из Москвы.
- Партиция 2 — заказы из Санкт-Петербурга.
- Партиция 3 — заказы из остальных регионов.
С помощью такого подхода несколько экземпляров Kafka Streams могут работать с разными частями данных параллельно, увеличивая скорость обработки.
Хранение данных между обработками
Некоторые операции в Kafka Streams требуют запоминания прошлых данных. Например, если нужно посчитать сумму всех покупок пользователя или количество его заказов, система должна хранить промежуточные результаты.
Для этого Kafka Streams использует два механизма:
- State Store — локальное хранилище внутри Kafka Streams, где находятся текущие вычисления.
- Changelog Topic — специальный топик в Kafka, куда записываются изменения в State Store. Если приложение перезапускается, оно загружает данные из этого топика и продолжает работу с того же места.
По умолчанию Kafka Streams хранит состояние локально, но если обработанные данные нужны другим сервисам, их можно записывать во внешние базы данных или облачные хранилища. Это полезно, когда требуется передавать результаты в аналитические системы или отчеты.
Как Kafka Streams используется в микросервисах
Kafka Streams вписывается в микросервисную архитектуру. Вместо передачи данных через REST API системы подписываются на события в Kafka и работают независимо.
Например, когда клиент оформляет заказ, информация отправляется в Kafka. Система оплаты получает это событие, проверяет платеж и записывает результат. Модуль доставки отслеживает сообщения об успешных транзакциях и создает заявку на отправку товара.
Что это дает:
- Компоненты работают независимо. Если один из них временно недоступен, Kafka сохраняет события, и обработка продолжается после восстановления.
- Меньше нагрузки на API. Данные передаются через события, а не через синхронные запросы.
- Гибкость в обработке. Можно подключать новые модули без изменения уже работающих компонентов.
Kafka Streams не просто передает данные между частями системы, а еще и помогает подготовить их к использованию. Он фильтрует, агрегирует и объединяет потоки, чтобы конечные потребители получали только нужную информацию. Например, CRM может работать не просто с сырыми заказами, а с данными, дополненными сведениями о клиенте и его истории покупок.
Как начать использовать Kafka Streams
Kafka Streams работает внутри обычного Java-приложения и не требует сложной инфраструктуры. Чтобы использовать библиотеку, нужно установить Kafka, настроить среду разработки и написать код для обработки данных.
1. Установка Kafka
На Linux и macOS:
Скачайте и распакуйте Kafka.
wget https://downloads.apache.org/kafka/3.9.0/kafka_2.13-3.9.0.tgz
tar -xzf kafka_2.13-3.9.0.tgz
cd kafka_2.13-3.9.0Запустите Zookeeper — сервис, который отслеживает активные брокеры (серверы, обрабатывающие сообщения в Kafka) и координирует их работу в кластере Kafka.
bin/zookeeper-server-start.sh config/zookeeper.propertiesЗапустите Kafka-брокер.
bin/kafka-server-start.sh config/server.propertiesНа Windows:
Скачайте Kafka с официального сайта и распакуйте архив.
Добавьте путь к Kafka в переменные среды (kafka\bin\windows в PATH).
Запустите Zookeeper.
bin\windows\zookeeper-server-start.bat config\zookeeper.propertiesЗапустите Kafka-брокер.
bin\windows\kafka-server-start.bat config\server.propertiesПосле этих шагов Kafka будет работать и готова принимать сообщения.
2. Подключение Kafka Streams в Java
Чтобы использовать Kafka Streams, нужно добавить зависимость в проект.
Maven и Gradle — это инструменты, которые помогают управлять зависимостями и сборкой проекта. Они автоматически загружают нужные библиотеки и упрощают настройку Java-приложений.
Если используется Maven, добавьте в файл pom.xml:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>3.9.0</version>
</dependency>Если используется Gradle, добавьте в build.gradle:
implementation 'org.apache.kafka:kafka-streams:3.9.0'После этого можно использовать Kafka Streams в коде.
3. Создание топиков и отправка сообщений
Перед запуском приложения нужно создать входной (input-topic) и выходной (output-topic) топики.
bin/kafka-topics.sh --create --topic input-topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1
bin/kafka-topics.sh --create --topic output-topic --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1Для Windows в этих командах нужно заменить / на \.
Как отправить сообщение в Kafka
Чтобы протестировать работу Kafka Streams, можно вручную отправить сообщение в input-topic:
bin/kafka-console-producer.sh --topic input-topic --bootstrap-server localhost:9092После этого можно ввести сообщение, например:
Hello Kafka Streams!Как прочитать сообщение из Kafka
Проверить выходной топик (output-topic) можно с помощью команды:
bin/kafka-console-consumer.sh --topic output-topic --from-beginning --bootstrap-server localhost:9092Если Kafka Streams работает правильно, в консоли появится отправленное сообщение.
4. Запуск первого приложения
Kafka Streams позволяет работать с данными в потоках. Например, можно создать приложение, которое читает события из input-topic, фильтрует только нужные сообщения и записывает их в output-topic.
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-app");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> stream = builder.stream("input-topic");
KStream<String, String> processedStream = stream.filter((key, value) -> value.contains("SUCCESS"));
processedStream.to("output-topic");
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();Этот код выполняет три действия:
- Подключается к Kafka и читает данные из input-topic.
- Фильтрует сообщения, оставляя только те, в которых есть «SUCCESS».
- Записывает результат в output-topic.
После запуска этого кода Kafka Streams начнет автоматически обрабатывать новые сообщения.
Что делать дальше?
Этот пример показывает, как настроить Kafka Streams и выполнить базовую обработку данных. В реальных приложениях можно:
- Агрегировать данные — например, считать сумму всех покупок клиента.
- Объединять потоки — добавлять информацию о пользователях в заказы.
- Использовать временные окна — анализировать события, например, за последние 10 минут.
После настройки первого приложения можно добавлять новые функции и интегрировать его с другими сервисами.